







(本文转自小蚊子数据分析公众号)
开机时显示的时间排名是如何设计的呢?下面以此为例一起学下R语言与正态分布。
首先,你可能会觉得它是这样子实现的:
1、收集所有用户的开机时间的数据,排好序放在一个数据库中;
2、然后根据你的开机时间,找出你的排名,除以总用户数,就是你击败电脑占比。
是的,这样子设计排名算法是非常合理,但是有以下几个问题:
1、你电脑开机的时候,没有连接网络怎么办呢?那就无法请求到所有的用户的数据了对吧。
2、就算所有的用户的数据,已经下载到你本地,根据不完全统计,360的用户数,估计也超过10亿了吧,上10亿行的数据进行比较统计,放在开机这个地方,恐怕不妥。
下面是一种设计思路,首先,收集尽量多的用户的开机时间,然后,查看时间的分布如何。(开机时间数据链接: http://pan.baidu.com/s/1jGu8ZXk 密码: epah)
data <- read.csv("D:\\data\\20150930\\startTime.csv")
mean(data[, 1])
sd(data[, 1])
hist(
data[, 1], prob=TRUE,
main="开机时间频率直方图",
ylab="频率", xlab="开机时间(秒)"
)
lines(density(data[, 1]), col="red")
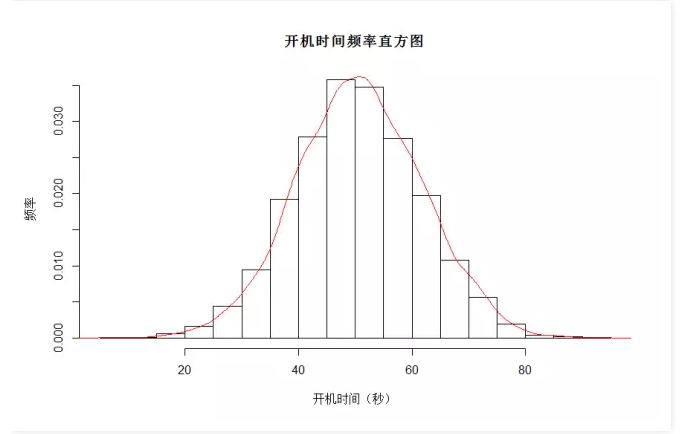
从这个图中,我们可以看到,开机时间貌似符合正态分布,有戏!对吧,但是我只能用貌似,因为我还没有检测数据的正态性,好,我们使用R来检测一下开机时间是否符合正态分布。
检测正态分布的方法:
绘制QQ图,QQ图判断法:查看我们的数据,是否绝大部分落在中间直线的附近。
qqnorm(
data[, 1],
main="QQ图",
ylab="y", xlab="x"
);
qqline(data[, 1]);
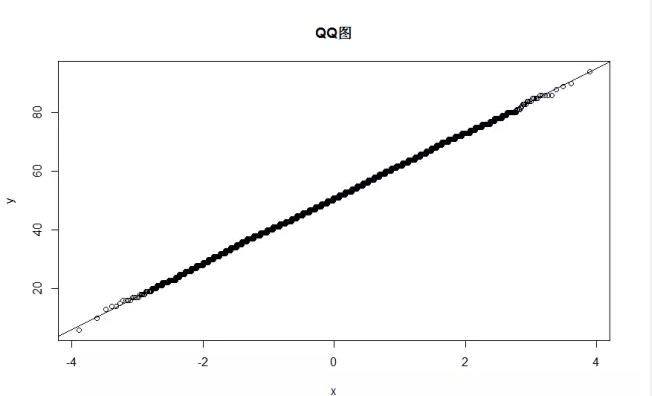
可以看到,QQ图中,所有的点都落在了中间的直线上,直观上我们就可以判断这个数据的分布符合正态分布了。
验证了数据是正态分布的之后,事情就变得非常简单了,下面我们来看看如何进行建模。
一、建立正态分布的模型,只需要求出正态分布的均值和标准差即可,也就是:
data_mean <- mean(data[, 1])
data_sd <- sd(data[, 1])
> data_mean
[1] 50.7848
> data_sd
[1] 11.10776
二、然后保存这个数据在软件中,有一个用户开机时间为38秒,那么他的排名是多少呢?
> 1 - pnorm(38, mean=data_mean, sd=data_sd)
[1] 0.8751295
也就是说,我们使用pnorm函数,根据正态分布的性质,就可以求出这个用户的排名是87.5%了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









