






金十数据是一个提供7X24小时全球财经资讯的网站,除了新闻资讯,金十数据也提供不同国家的经济数据,可视化图表和总结每天的财经热点。金十数据每天在中港股市开市前会有一则叫金十早餐的推文,主要使用一张图表总结前一天全球主要指数的表现。

本文要讲述的就是如何自动化每天把这张图片抓下来,储存在自己的电脑中。至于为什么要储存起来,可以是自己把图片推送到社交平台, 可以图像识别,提链数据。又或者推送给自己,毕竟金十的订阅推送是把整篇文章推送,没有单独只推送股市表现图片。
首先先打开某一篇金十早餐文章,查看图片的url
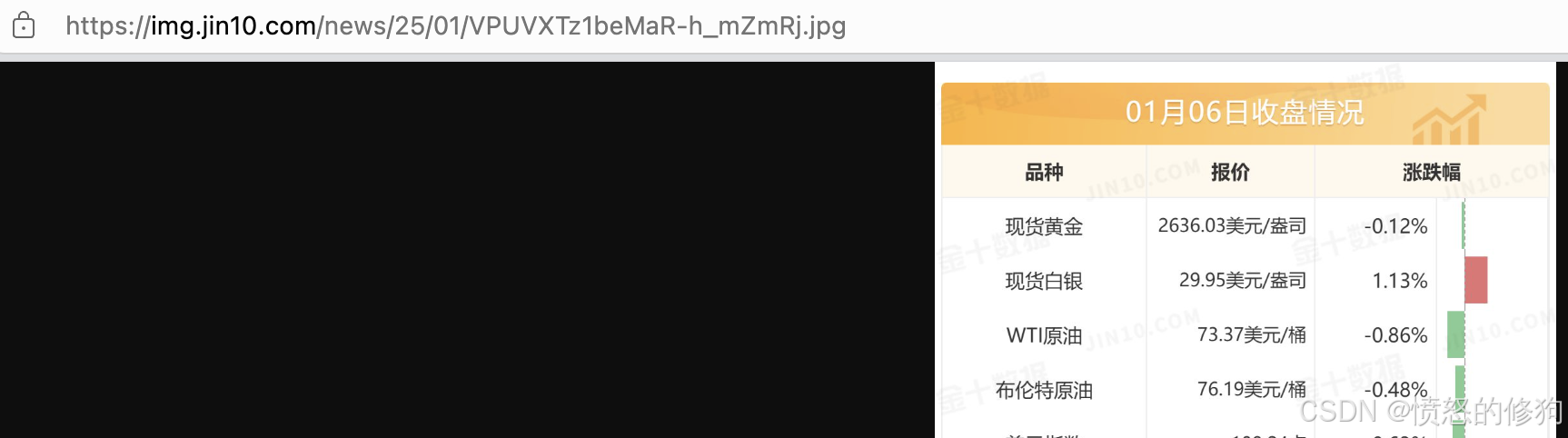
这个url 看似应该是没有模式的,猜想不出下一天或前一天图片的url。
那再分析一下文章的排版结构,对比了几篇金十早餐文章,发觉总结上一天全球指数表现的图通常排jin10vip-image-viewer DIV 的第二个figure 中,那我们可以通过拆解html 拿到图片的url
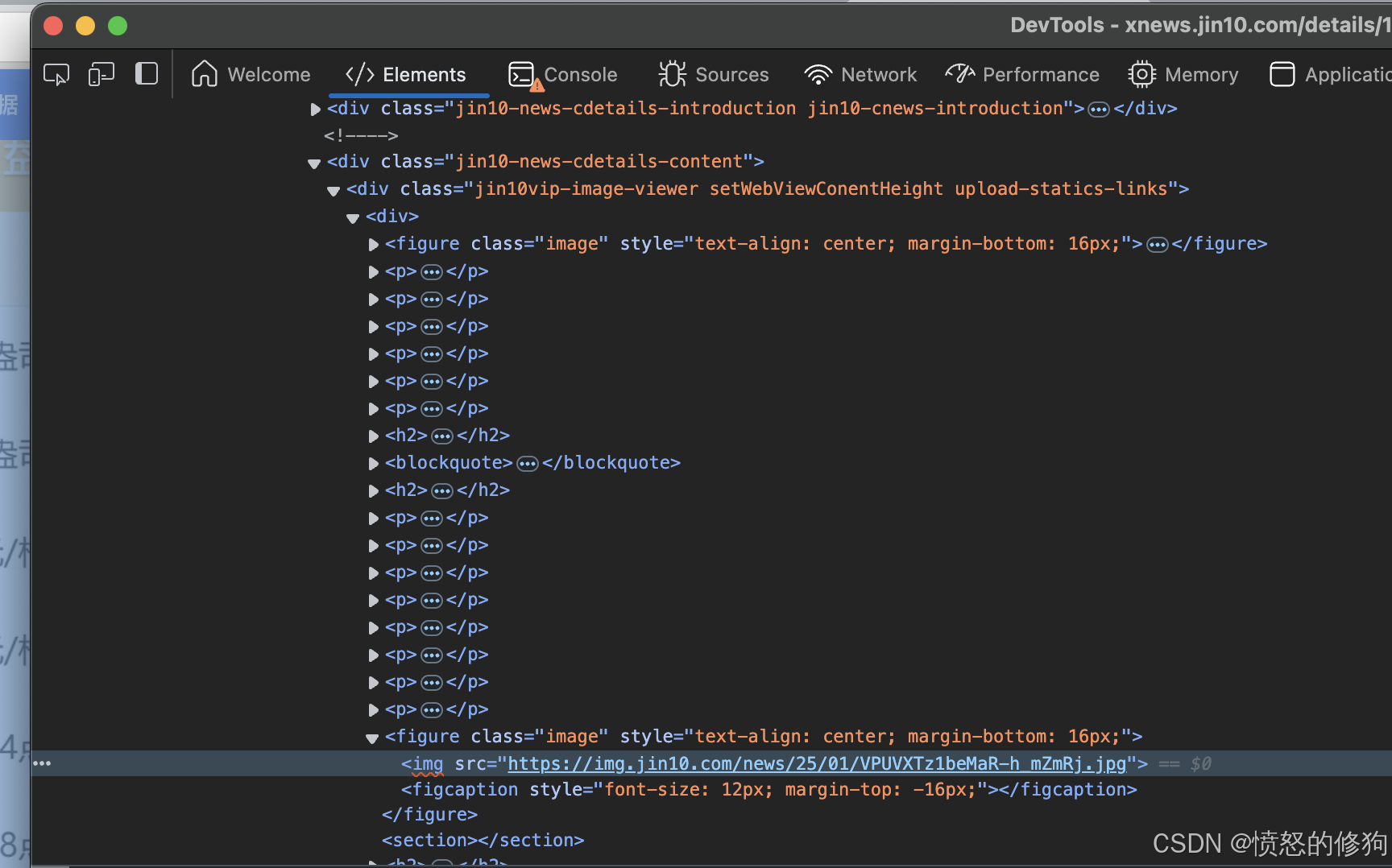
解决了这个问题后,那我们要如何知道每篇金十早餐的url 呢? 没有这个是成事不了。 很简单,我们能在网页版的金十早餐专栏中找到所有金十早餐文章的连结。与指数表现总结图同样道理,是需要拆解html 结构抓取。
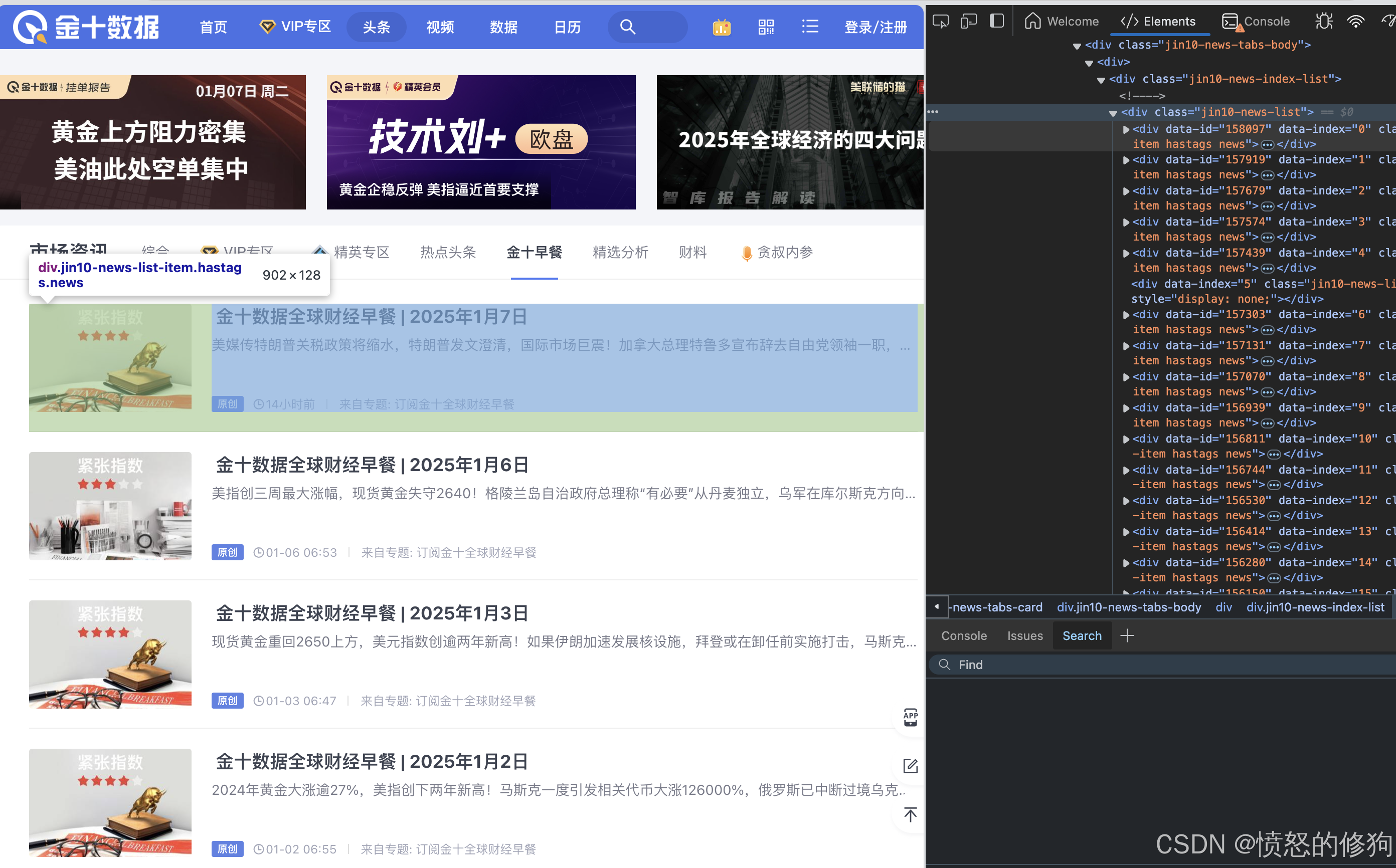
有了以上所有的资讯,便可以开始编写以下的代码了。
import requests
import pandas as pd
from datetime import datetime
from bs4 import BeautifulSoup
import time
import os
response = requests.get('https://xnews.jin10.com/30')
if(response.status_code == 200):
html = response.content
soup = BeautifulSoup(html, 'lxml')
news_area = soup.find('div', attrs = { 'class': 'jin10-news-list'})
news = news_area.find_all('div', attrs = {'class':'jin10-news-list-item hastags news'})
results = []
for n in news:
div = n.find('div', attrs= {'class':'jin10-news-list-item-info'})
a_element = div.a
link = a_element['href']
title= a_element.p.text.replace('\n','').replace('|','_').strip()
introduction = a_element.find('div', attrs={'class':'jin10-news-list-item-introduction'}).text.replace('\n','').strip()
results.append([title, introduction, link])
df = pd.DataFrame(results, columns=['Title', 'Introduction', 'Link'])
df.to_csv(f'j10_breakfastlink_{datetime.now().strftime('%Y%m%d')}.csv', encoding='utf-8', index=False)代码是先爬取第一页金十早餐专栏的所有金十早餐文章有连结,然后把所有连结以CSV档案形式储存在档案目录,方便之后可以在不同的场景下使用。
import requests
import pandas as pd
from datetime import datetime
from bs4 import BeautifulSoup
import time
import os
def download_picture(target_dir,filename,p_link):
response = requests.get(p_link)
with open(os.path.join(target_dir, filename), 'wb') as f:
f.write(response.content)
def get_summary_picture_links(titles, links):
picture_links = []
summary_titles = []
for i in range(0, len(links)):
response = requests.get(links[i])
if(response.status_code == 200):
html = response.content
soup = BeautifulSoup(html, 'lxml')
figures = soup.find_all('figure', attrs={'class': 'image'})
if(figures != []):
picture_links.append(figures[1].img['src'])
summary_titles.append(titles[i])
time.sleep(2)
return summary_titles, picture_links
csv_file_name = f'j10_breakfastlink_{datetime.now().strftime('%Y%m%d')}.csv'
df= pd.read_csv(csv_file_name)
links = df['Link'].to_numpy()
titles = df['Title'].to_numpy()
aggregate_items = get_summary_picture_links(titles, links)
summary_titles = aggregate_items[0]
picture_links = aggregate_items[1]
target_dir = './summary_picts'
for i in range(0, len(picture_links)):
filename = f'{summary_titles[i]}.jpg'
download_picture(target_dir, filename, picture_links[i])第二段代码是读取CSV档案中金十早餐连结,然后再前往页面抓取全球指数收盘情况的图片连结,存到串列变数中。最后透过for 语句抓取图片,储存到档案目录中。
如果只想抓取最新的全球收盘情况图片,最新的文章每天都是放在金十早餐专栏并置顶的,换言之你只需修改少少代码,便可以只取最新的全球指数收盘情况总结图了。 这部分我就不再作说明,相信大家一定能实现的。
总结:爬虫的思路还是万变不离其宗,在没有API接口的情况下
1.抓取连结
2.前往页面拆分html 结构
3.抓取资源

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









