







python数据抓取
一、页面分析
所谓的分析网页,就是理解一个网页的结构如何,了解需要字段的位置和形式。方便后期提取。了解页面最好的方法就是查看源代码。在大多数浏览器中,都可以使用开发者工具或者直接按F12,获取网页的源代码,下面以之前的文章做个示例:

上面例子中,很容易找到我们想要的阅读数和收藏数,只有这样分析清楚了,你才在后面通过class="read-count"和class="get-collection"获得想要的数据。当然,实际中的数据肯定是相对复杂的,不像例子这个简单。
二、网页抓取方法
现在我们已经了解了该网页的结构,下面将会介绍 3 种抓取其中数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1、正则表达式方法
在通过正则表达式进行示例之前,假设你已经知道并且会使用python的正则表达式进行简单的提取,当然,你不会也没关系,请查看笔者之前的文章python的正则表达式进行学习。
好嘛,相信你又温习了一下正则的使用,下面通过一个例子了解正则表达式在数据抓取时的方法。
例子:抓取文章的阅读数
url = 'https://blog.csdn.net/Itsme_MrJJ/article/details/124836797'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'}
res = requests.get(url, headers=headers)
pattern = re.compile(r'class="read-count">(.*?)<')
read_count = re.findall(pattern,res.text)
read_count
['60']
可以看到,我们需要的数据已经获取到了,但是需要说明已下几个问题;
- 上例使用的时findall,其他也可以获得结果,但实际中的抓取数据不止一个,所以都用findall
- 实际中,网页页面会变化,导致数据抓取不到,需要重新修改正则匹配规则
- 正则找规律相对复杂,尤其是页面复杂、提取的数据很多时
2、BeautifulSoup 模块
Beautiful Soup 是一个非常流行的 Python 库,它可以解析网页,并提供了定位内容的便捷接口。当然,如果你还不知道,那么请看笔者之前的文章BeautifulSoup解析网页,当然也可以直接查看其官方文档。
好的,假设你已经安装、了解BeautifulSoup 模块了,并通过里面的讲解,知道了大概的html的结构释义,那么请接着看下面通过BeautifulSoup 模块获取阅读数的例子。
url = 'https://blog.csdn.net/Itsme_MrJJ/article/details/124836797'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text,features="lxml")
soup.find_all(class_='read-count')[0].string
'60'
同样的,我们通过上面的例子也得到了想要的数据,而且比之前的正则表达式简洁了很多且抗干扰能力(前端编写时乱用的空格等)强了很多。但它也有一些需要注意的地方。
- 该模块可以使用多个解析内核,之间又些许差异,使用时需要注意
- soup的定位又多种,也时根据哪种得心应手用哪种,其中遍历树最麻烦,且往往得不到想要的
- 改模块会补充、规范不规整的前端页面
3、lxml 模块
Lxml 是基于 libxml2 这一 XML 解析库构建的 Python 库,它使用 C 语言编写,解析速度比 Beautiful Soup 更快,不过安装过程也更为复杂,尤其是在 Windows中。若是安装未成功,可以使用 Anaconda 。
当然,也许你可能对 Anaconda 不太熟悉,它是由 Continuum Analytics 公司员工创建的主要专注于开源数据科学包的包和环境管理器。可以直接去其官网下载安装。
和 Beautiful Soup 一样,使用 lxml 模块的第一步也是将有可能不合法的HTML 解析为统一格式。然后接着才是需求数据的抓取,对于数据的抓取,lxml 有几种不同的方法,比如 XPath 选择器和类似 Beautiful Soup 的 find()方法。但这里我们使用CSS 选择器。
from lxml.html import fromstring, tostring
tree = fromstring(res.text) # parse the HTML
td = tree.cssselect('.read-count')[0]
td.text
'60'
由于 cssselect 返回的是一个列表,我们需要获取其中的第一个结果,并调用 text方法,以迭代所有子元素并返回每个元素的相关文本。在本例中,尽管我们只有一个元素,但是该功能对于更加复杂的抽取示例来说非常有用。
4、各方法的对比总结
关于每种抓取方法的优缺点。如下图:

如果对你来说速度不是问题,并且更希望只使用 pip 安装库的话,那么使用较慢的方法(如 Beautiful Soup)也不成问题,但其实也没那么慢。如果只需抓取少量数据,并且想要避免额外依赖的话,那么正则表达式可能更加适合。不过,通常情况下,lxml 是抓取数据的最佳选择,这是因为该方法既快速又健壮,而正则表达式和 Beautiful Soup 或是速度不快,或是修改不易。
三、Xpath选择器
原本写到这里是要结束的,但是考虑涉及到的CSS选择器和Xpath选择器知识没涉及到,且我之前也没写相关的东西,所以,作为补充的知识点再写点。在开始之前,先看看常用的页面属性。
| 属性 | 示例 | 说明 |
|---|---|---|
| id | id=“MathJax_Message” | id 属性在 HTML 文档中必须是唯一的,这类似于公民的身份证号,具有很强的唯一性 |
| name | name=“keywords” | name 来指定元素的名称,像是人的姓名,不唯一 |
| class | class=“read-count” | class 来指定元素的类名。其用法与 id、name 类似 |
| tag | <div> | 类似<div>、<input>、<a>等 ,一样的标签会很多,所以通过标签定位需要注意 |
| link | <link> | link 定位与前面介绍的几种定位方法有所不同,它专门用来定位文本链接 |
XPath 是一种在 XML 文档中定位元素的语言。因为 HTML 可以看作 XML 的一种实现,所以我们可以通过Xpath定位抓取数据。
相比BeautifulSoup,xpath所需要的依赖更少,只需要lxml这个解析器就可。并且xpath也可以在java,c++等多种语言中使用,使得爬虫不再局限于python语言。而Xpath处理的对象是一个etree对象,该对象由lxml生成。有两种生成方式:
# 本地文件
from lxml import etree
# 实例化好了一个etree对象,且将被解析的源码加载到了该对象中
tree = etree.parse('alice.html')
# 网络文件
import requests
from lxml import etree
url = 'https://blog.csdn.net/Itsme_MrJJ/article/details/124836797'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'}
res = requests.get(url, headers=headers)
# 实例化好了一个etree对象,且将被解析的源码加载到了该对象中
tree = etree.HTML(res.text)
生成之后就是提取,xpath的常用规则及基本方法如下:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点(标签)选取且必须从根节点开始 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
from lxml import etree
import requests
url = 'https://blog.csdn.net/Itsme_MrJJ/article/details/124836797'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'}
res = requests.get(url, headers=headers)
tree = etree.HTML(res.text)
tree.xpath('//span[@class="read-count"]/text()')
['61']
说明:
//span[@class=“read-count”]:从class属性等于read-count的span节点开始的所有text
因为使用的是//,所以不必指出前面的层级,这也是Xpath的强大之处,不需要一层层的找
四、CSS选择器
CSS(Cascading Style Sheets)是一种语言,它用来描述 HTML 和 XML 文档的表现。CSS 使用选择器来为页面元素绑定属性。
CSS 可以较为灵活地选择控件的任意属性,一般情况下定位速度要比 XPath 快,但对于初学者来说学习起来稍微有点难度,我们这里只介绍 CSS 在BeautifulSoup中的语法与使用。
使用CSS选择器,只需要调用select()方法,并结合CSS选择器语法就可以定位元素的位置。具体语法规则如下表:
| 类型 | 表示 | 示例 | 说明 |
|---|---|---|---|
| id选择器 | # | soup.select(‘#content_views’) | 选择id值为content_views的所有内容 |
| 类选择器 | . | soup.select(‘.read-count’) | 选择class值为read-count的所有内容 |
| 标签选择器 | tag | soup.select(‘h1’) | 选择所有h1标签的内容 |
| 混合选择器 | 综上 | soup.select(‘span.read-count’) | 选择class值为read-count的所有span标签数据 |
我们以已经了解了Xpath和CSS选择器,那两者关于定位的区别如下:

五、数据抓取总结
写了这么多,总感觉有些乱,做一个图来整理思绪。
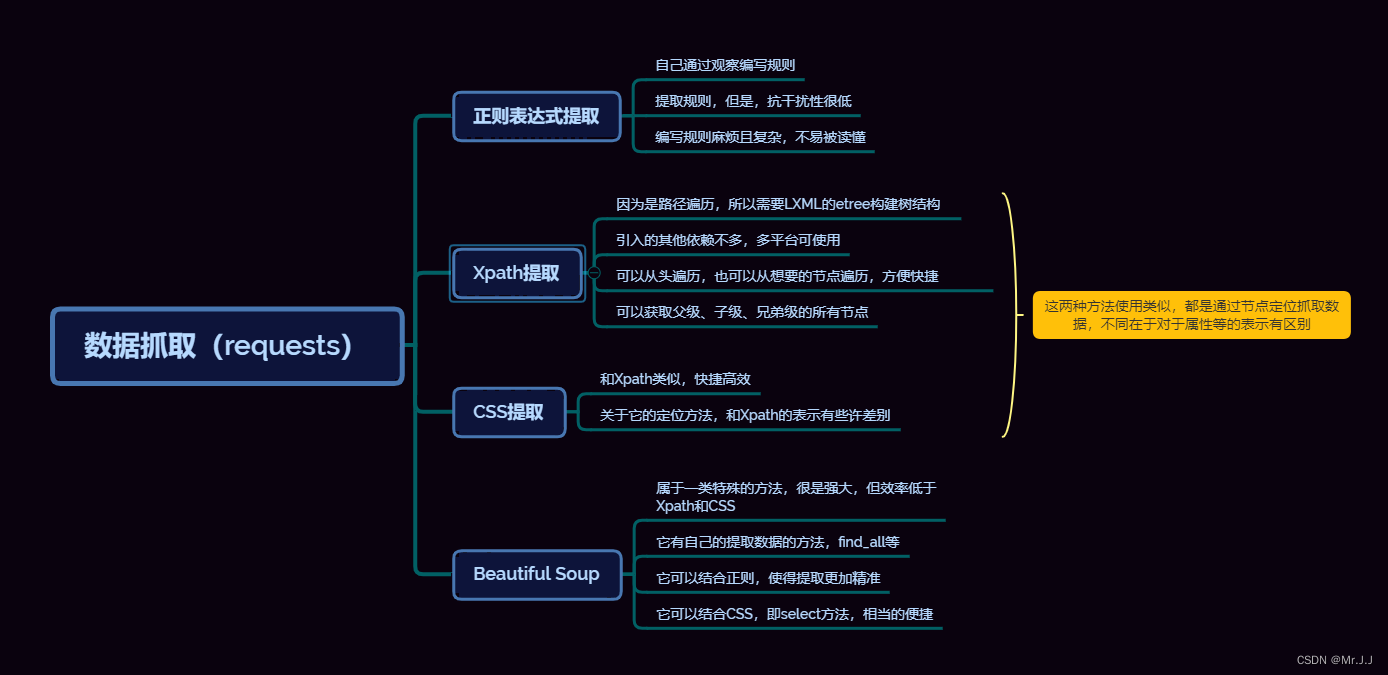
六、性能测试源码
import re
import requests
from bs4 import BeautifulSoup
import lxml.html
import time
#
#
#
#获取网页内容
def download(url,user_agent='wswp',proxy=None,num_retries=2):
print ('Downloading:',url)
headers = {'User-Agent': user_agent}
try:
resp = requests.get(url, headers=headers, proxies=proxy)
html = resp.text
if resp.status_code >= 400:
print('Download error:', resp.text)
html = None
if num_retries and 500 <= resp.status_code < 600:
# recursively retry 5xx HTTP errors
return download(url, num_retries - 1)
except requests.exceptions.RequestException as e:
print('Download error:', e.reason)
html = None
return html
#使用正则表达式匹配
def re_scraper(html):
results={}
results['area']=re.search('<tr id="places_area__row">.*?<td class="w2p_fw">(.*?)</td>',html).groups()[0]
return results
#使用BeautifulSoup匹配
def bs_scraper(html):
soup=BeautifulSoup(html)
results={}
results['area']=soup.find('table').find('tr',id='places_area__row').find('td', class_='w2p_fw').string
return results
#使用cssselect选择器匹配
def lxml_scraper(html):
tree=lxml.html.fromstring(html)
results={}
conf=tree.cssselect('table > tr#places_area__row > td.w2p_fw')[0].text_content()
results['area']=conf
return results
#计算获取时间
#每个网站爬取的次数
NUM_ITERATIONS=1000
html=download('http://example.python-scraping.com/view/-1')
for name,scraper in [('Re',re_scraper),('Bs',bs_scraper),('Lxml',lxml_scraper)]:
#开始的时间
start=time.time()
for i in range(NUM_ITERATIONS):
if scraper==re_scraper:
#默认情况下,正则表达式模块会缓存搜索结果,为了使对比条件更一致,re.purge()方法清除缓存
re.purge()
result=scraper(html)
#检查结果
assert(result['area']=='647,500 square kilometres')
#结束时间
end=time.time()
print('%s: %.2f seconds' %(name,end-start))















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









