







【1】NIO和IO
Java NIO(New IO)是从Java 1.4版本(以JSR-51身份)开始引入的一个新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作(IO是基于流的,单向操作)。NIO将以更加高效的方式进行文件的读写操作。
NIO和IO区别
| IO | NIO |
|---|---|
| 面向流(Stream Oriented) | 面向缓冲区(Buffer Oriented) |
| 阻塞IO(Blocking IO) | 非阻塞IO(NonBlocking IO) |
| (无) | 选择器(Selectors) |
阻塞和非阻塞
- 传统的IO 流都是阻塞式的。
也就是说,当一个线程调用read() 或write() 时,该线程被阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务。因此,在完成网络通信进行IO 操作时,由于线程会阻塞,所以服务器端必须为每个客户端都提供一个独立的线程进行处理,当服务器端需要处理大量客户端时,性能急剧下降。
- Java NIO 是非阻塞模式的。
当线程从某通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞IO 的空闲时间用于在其他通道上执行IO 操作,所以单独的线程可以管理多个输入和输出通道。因此,NIO 可以让服务器端使用一个或有限几个线程来同时处理连接到服务器端的所有客户端。
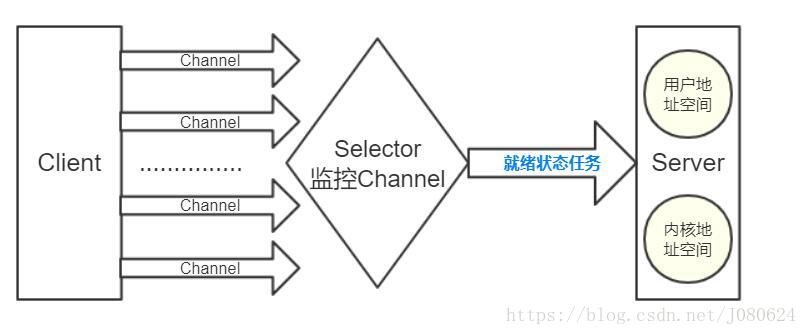
通道和缓冲区
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。
通道表示打开到IO 设备(例如:文件、套接字)的连接。若需要使用NIO 系统,需要获取用于连接IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理。
简而言之,Channel 负责传输Buffer,Buffer 负责数据存储。
主要类和接口
- 进行异步IO操作的缓冲区ByteBuffer等;
- 进行异步IO操作的管道Pipe;
- 进行各种IO操作的(异步或者同步)Channel,包括ServerSocketChannel和SocketChannel;
- 多种字符集的编码能力和解码能力;
- 实现非阻塞IO操作的多路复用器selector;
- 基于流行的Perl实现的正则表达式库;
- 文件通道FileChannel。
新的NIO类库的提供,极大地促进了基于Java的异步非阻塞编程的发展和应用,但是它依然有不完善的地方,特别是对文件系统的处理能力仍显不足,主要问题如下:
- 没有统一的文件属性(例如读写权限);
- API能力比较弱,例如目录的级联创建和递归遍历需要自己实现;
- 底层存储系统的一些高级API无法使用;
- 所有的文件操作都是同步阻塞调用,不支持异步文件读写操作。
2011.7.28日,jdk1.7正式发布。它的一个比较大的亮点就是将原来的NIO类库进行了升级,被称为NIO2.0(也就是AIO)。NIO2.0由JSR-203演进而来,它主要提供了如下三个方面的改进。
- 提供能够批量获取文件属性的API,这些API具有平台无关性,不与特性的文件系统耦合。另外它还提供了标准文件系统的SPI,供各个服务提供商扩展实现。
- 提供AIO功能,支持基于文件的异步IO操作和针对网络套接字的异步操作;
- 完成JSR-51定义的通道功能,包括对配置和多播数据报的支持等。
【2】缓冲区
缓冲区(Buffer)是一个用于特定基本数据类型的容器。由java.nio 包定义的,所有缓冲区都是Buffer 抽象类的子类。
Java NIO中的Buffer 主要用于与NIO 通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的(可以理解为乘坐火车出差:要先到火车站-轨道-channel,然后坐上火车–Buffer,然后火车载着你–数据 到目的地)。
① 缓冲区类型
Buffer 就像一个数组,可以保存多个相同类型的数据。根据数据类型不同(boolean 除外) ,有以下Buffer 常用子类:
- ByteBuffer 字节缓冲区
- CharBuffer 字符缓冲区
- ShortBuffer 短整型缓冲区
- IntBuffer 整形缓冲区
- LongBuffer 长整形缓冲区
- FloatBuffer 浮点型缓冲区
- DoubleBuffer 双精度浮点型缓冲区

上述Buffer 类他们都采用相似的方法进行管理数据,只是各自管理的数据类型不同而已。都是通过如下方法获取一个Buffer 对象:
//创建一个容量为capacity 的XxxBuffer 对象
static XxxBuffer allocate(int capacity) ;
e.g :
ByteBuffer byteBuffer = ByteBuffer.allocate(1000);
CharBuffer charBuffer = CharBuffer.allocate(1000);
② 缓冲区的基本属性
Buffer 中的重要概念:
-
容量(capacity) :表示Buffer 最大数据容量,缓冲区容量不能为负,并且创建后不能更改。
-
限制(limit):第一个不应该读取或写入的数据的索引,即位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量。
-
位置(position):下一个要读取或写入的数据的索引。缓冲区的位置不能为负,并且不能大于其限制。
-
标记(mark)与重置(reset):标记是一个索引,通过Buffer 中的mark() 方法指定Buffer 中一个特定的position,之后可以通过调用reset() 方法恢复到这个position。
标记、位置、限制、容量遵守以下不变式:0<=mark<=position<=limit<=capacity
示意图如下:
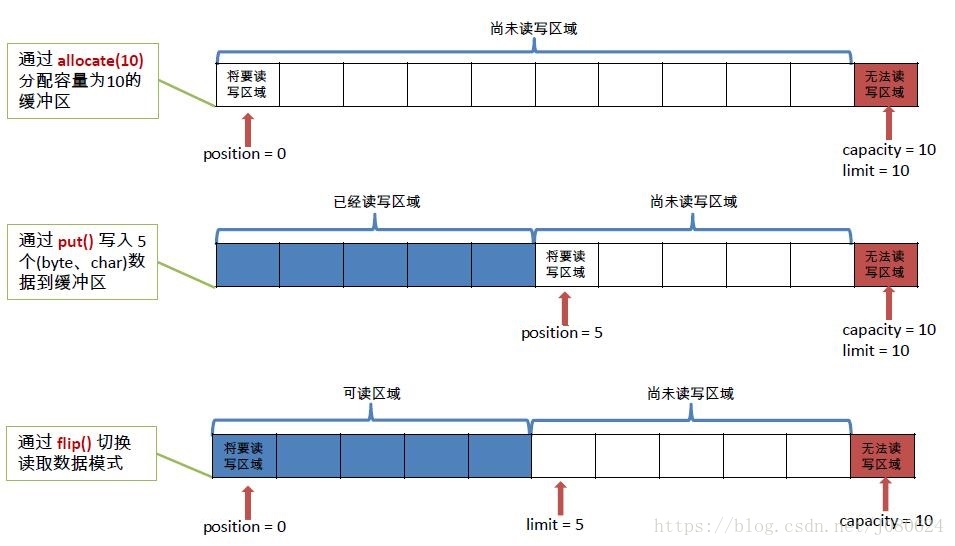
③ 缓冲区数据操作核心方法
Buffer 所有子类提供了两个用于数据操作的方法:get() 与put() 方法。
获取Buffer 中的数据:
- get() :读取当前位置的单个字节
- get(byte[] dst):批量读取多个字节到dst 中
- get(int index):读取指定索引位置的字节(不会移动position)
放入数据到Buffer 中:
- put(byte b):将给定单个字节写入缓冲区的当前位置
- put(byte[] src):将src 中的字节写入缓冲区的当前位置
- put(int index, byte b):将指定字节写入缓冲区的索引位置(不会移动position)
④ Buffer 的常用方法
如下表所示:
| 方法 | 描述 |
|---|---|
| Bufferclear() | 清空缓冲区并返回对缓冲区的引用 |
| Buffer flip() | 将缓冲区的界限设置为当前位置,并将当前位置充值为0 |
| int capacity() | 返回Buffer 的capacity大小 |
| boolean hasRemaining() | 判断缓冲区中是否还有元素 |
| int limit() | 返回Buffer 的界限(limit) 的位置 |
| Buffer limit(int n) | 将设置缓冲区界限为n, 并返回一个具有新limit 的缓冲区对象 |
| Buffer mark() | 对缓冲区设置标记 |
| int position() | 返回缓冲区的当前位置position |
| Buffer position(int n) | 将设置缓冲区的当前位置为n , 并返回修改后的Buffer 对象 |
| int remaining() | 返回position 和limit 之间的元素个数 |
| Buffer reset() | 将位置position 转到以前设置的mark 所在的位置 |
| Buffer rewind() | 将位置设为0,取消设置的mark |
代码示例如下:
@Test
public void test1(){
String str = "abcde";
//1. 分配一个指定大小的缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
System.out.println("-----------------allocate()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//2. 利用 put() 存入数据到缓冲区中
buf.put(str.getBytes());
System.out.println("-----------------put()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//3. 切换读取数据模式
buf.flip();
System.out.println("-----------------flip()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//4. 利用 get() 读取缓冲区中的数据
byte[] dst = new byte[buf.limit()];
buf.get(dst);
System.out.println("-----------------get()----------------");
System.out.println(new String(dst, 0, dst.length));
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//5. rewind() : 可重复读
buf.rewind();
System.out.println("-----------------rewind()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
//6. clear() : 清空缓冲区. 但是缓冲区中的数据依然存在,但是处于“被遗忘”状态
buf.clear();
System.out.println("-----------------clear()----------------");
System.out.println(buf.position());
System.out.println(buf.limit());
System.out.println(buf.capacity());
System.out.println((char)buf.get());
}
测试结果如下:
-----------------allocate()----------------
0 //position
1024 //limit
1024 //capacity
-----------------put()----------------
5
1024
1024
-----------------flip()----------------
0
5
1024
-----------------get()----------------
abcde
5
5
1024
-----------------rewind()----------------
0
5
1024
-----------------clear()----------------
0
1024
1024
a
测试mark 和 reset
@Test
public void test2(){
String str = "abcde";
ByteBuffer buf = ByteBuffer.allocate(1024);
buf.put(str.getBytes());
//position:5 limit:1024 capacity:1024
buf.flip();
//position:0 limit:5 capacity:1024
byte[] dst = new byte[buf.limit()];
buf.get(dst, 0, 2);
System.out.println(new String(dst, 0, 2));
System.out.println(buf.position());
//position:2 limit:5 capacity:1024
//mark() : 标记
buf.mark();
//position:2 limit:5 capacity:1024
buf.get(dst, 2, 2);
System.out.println(new String(dst, 2, 2));
System.out.println(buf.position());
//position:4 limit:5 capacity:1024
//reset() : 恢复到 mark 的位置
buf.reset();
System.out.println(buf.position());
//position:2 limit:5 capacity:1024
//判断缓冲区中是否还有剩余数据
if(buf.hasRemaining()){
//Returns the number of elements between the current position and the limit.
//获取缓冲区中可以操作的数量
System.out.println(buf.remaining());
}
}
测试结果如下:
ab
2
cd
4
2
3
flip()和rewind()源码分析
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
可以看到rewind方法可以让你从头开始读取数据,直到limit;而flip方法则是重新读取从0到当前position的数据。
⑤ 直接和非直接缓冲区
非直接缓冲区
通过 allocate() 方法分配缓冲区,将缓冲区建立在 JVM 的内存中。
数据传输示意图如下:
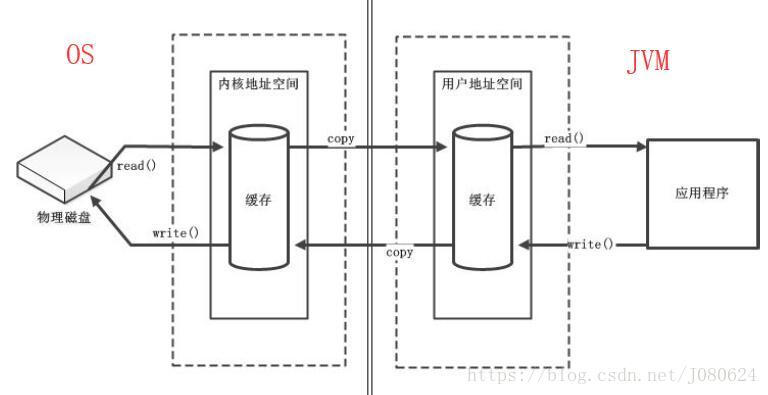
数据在用户地址空间和内核地址空间copy是比较耗费资源的,普通IO即是这种方式。但是缓冲区建立在了JVM中,则数据相对比较安全,且有较强控制性。
非直接缓冲区建立源码:
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
//创建了堆字节缓冲区
return new HeapByteBuffer(capacity, capacity);
}
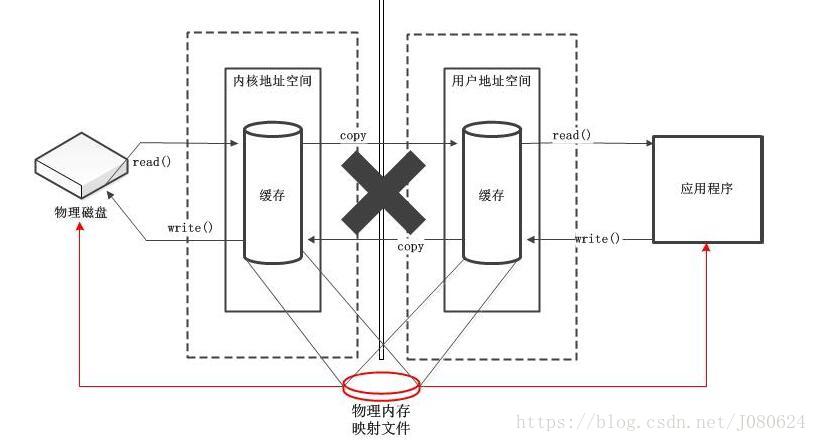
直接缓冲区
直接字节缓冲区,Java 虚拟机会尽最大努力直接在此缓冲区上执行本机I/O 操作。也就是说,在每次调用基础操作系统的一个本机I/O 操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
直接字节缓冲区可以通过调用此类的allocateDirect() 工厂方法来创建:
//分配直接缓冲区
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
需要注意的是,此方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。
直接缓冲区的内容可以驻留在常规的垃圾回收堆之外 :
因此,它们对应用程序的内存需求量造成的影响可能并不明显。所以,建议将直接缓冲区主要分配给那些易受基础系统的本机I/O 操作影响的大型、持久的缓冲区。
一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处时分配它们。
直接字节缓冲区还可以通过FileChannel 的map() 方法(该方法返回MappedByteBuffer)将文件区域直接映射到内存中来创建。
FileChannel inChannel = FileChannel.open(Paths.get("1.jpg"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("2.jpg"), StandardOpenOption.WRITE, StandardOpenOption.READ, StandardOpenOption.CREATE);
MappedByteBuffer inMappedBuf = inChannel.map(MapMode.READ_ONLY, 0, inChannel.size());
MappedByteBuffer outMappedBuf = outChannel.map(MapMode.READ_WRITE, 0, inChannel.size());
Java 平台的实现有助于通过JNI 从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且将会在访问期间或稍后的某个时间导致抛出不确定的异常。
字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其isDirect()方法来确定。提供此方法是为了能够在性能关键型代码中执行显式缓冲区管理。
//分配直接缓冲区
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
System.out.println(buf.isDirect());//true
直接缓冲区数据传输示意图如下:
【3】通道
① 什么是通道
通道(Channel):由java.nio.channels 包定义的。Channel 表示IO 源与目标打开的连接。Channel 类似于传统的“流”。只不过Channel 本身不能直接访问数据,Channel 只能与Buffer 进行交互。通道与流的不同之处在于通道是双向的,流只是在一个方向上移动(一个流必须是InputStream或者Outputstream的子类),而通道可以用于读、写或者二者同时进行。
因为Channel是全双工的,所以它可以比流更好地映射底层操作系统的api。特别是在UNIX网络编程模型中,底层操作系统的通道都是全双工的,同时支持读写操作。
从计算机操作系统来讲,Channel是一种专门负责执行IO任务的处理机/处理器。具有执行I/O指令的能力,并通过执行通道程序来完成I/O操作。它的作用是建立独立的IO操作,将CPU从繁多的低速IO操作中解脱。
硬件示意图如下:
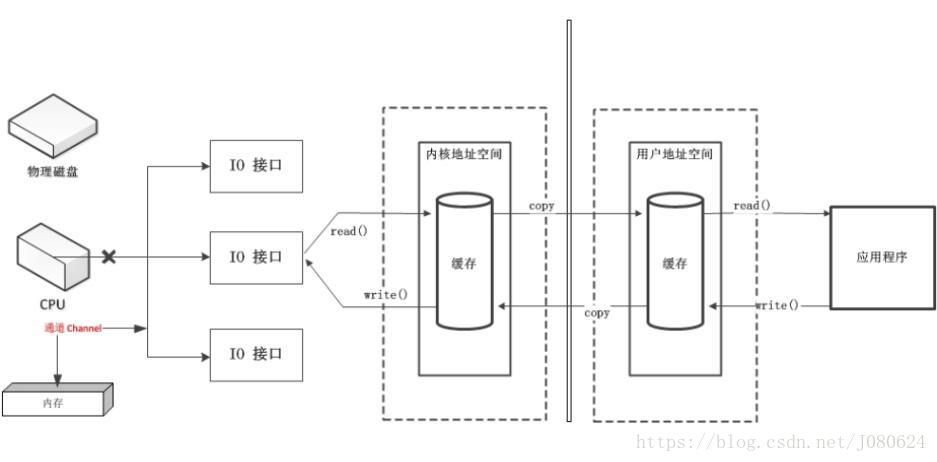
- 当CPU和I/O设备之间增加设备控制器(DMA)后,已经可以大大减少IO对CPU的依赖,而IO通道的出现是为了建立独立的IO操作,从而进一步减轻CPU的负担。
- 通道管理设备控制器,而这些控制器控制着IO设备(如磁盘驱动器、终端、LAN端口),同时通道具有执行I/O指令的能力,与CPU交互。
- 当需要执行IO操作时,CPU只需向通道发一条IO指令,通道执行通道处理程序,通过和设备控制器交互,开始IO操作;当IO操作完成后,通道向CPU发送信号;CPU在发送IO指令至接收到IO完成的信号期间可以运行和该IO操作无关的任务,使得CPU可以专门负责处理高速任务,低速的IO任务交给通道完成,整体任务处理效率得到提高。
- 对于Java的nio,通道的意义在于对异步IO的支持,是nio的关键对象。
② Java 为Channel 接口提供的最主要实现类
Channel的类图继承关系如图所示,自顶向下看,前三层主要是Channel接口,用于定义它的功能,后面是一些具体的功能类(抽象类)。从类图可以看出,实际上Channel可以分为两大类:用于网络读写的SelectableChannel和用于文件操作的FileChannel。
ServerSocketChannel和SocketChannel都是SelectableChannle的子类。
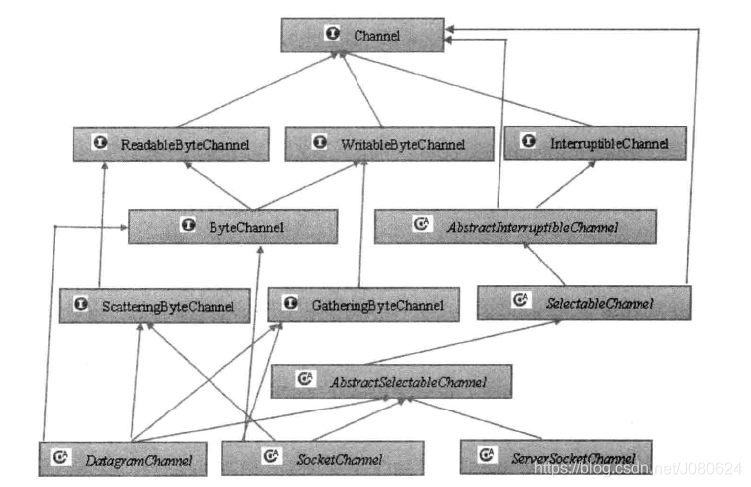
- FileChannel:用于读取、写入、映射和操作文件的通道。
- DatagramChannel:通过UDP 读写网络中的数据通道。
- SocketChannel:通过TCP 读写网络中的数据。
- ServerSocketChannel:可以监听新进来的TCP 连接,对每一个新进来的连接都会创建一个SocketChannel。
FileChannel 的常用方法如下表所示:
| 方法 | 描述 |
|---|---|
| int read(ByteBuffer dst) | 从Channel 中读取数据到ByteBuffer |
| long read(ByteBuffer[] dsts) | 将Channel 中的数据“分散”到ByteBuffer[] |
| int write(ByteBuffer src) | 将ByteBuffer 中的数据写入到Channel |
| long write(ByteBuffer[] srcs) | 将ByteBuffer[] 中的数据“聚集”到Channel |
| long position() | 返回此通道的文件位置 |
| FileChannel position(long p) | 设置此通道的文件位置 |
| long size() | 返回此通道的文件的当前大小 |
| FileChannel truncate(long s) | 将此通道的文件截取为给定大小 |
| void force(boolean metaData) | 强制将所有对此通道的文件更新写入到存储设备中 |
③ 获取通道的三种方式
第一种,对支持通道的对象调用getChannel() 方法。
- 本地IO
FileInputStream
FileOutputStream
RandomAccessFile - 网络IO
DatagramSocket
Socket
ServerSocket
第二种,在JDK1.7中的NIO.2针对各个通道提供了静态方法open()。
第三种,在JDK1.7中的NIO.2的Files工具类提供了newByteChannel()方法。
④ 利用通道完成文件的复制(非直接缓冲区)
实例如下:
@Test
public void test1(){
long start = System.currentTimeMillis();
FileInputStream fis = null;
FileOutputStream fos = null;
//①获取通道
FileChannel inChannel = null;
FileChannel outChannel = null;
try {
//拿到输入流和输出流
fis = new FileInputStream("1.jpg");
fos = new FileOutputStream("2.jpg");
//拿到对应的通道
inChannel = fis.getChannel();
outChannel = fos.getChannel();
//②分配指定大小的缓冲区--非直接缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
//③通过输入通道,将文件数据存入缓冲区中
while(inChannel.read(buf) != -1){
//切换读取数据的模式
buf.flip();
//④将缓冲区中的数据通过输出通道写到目标文件
outChannel.write(buf);
buf.clear();
//清空缓冲区
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(outChannel != null){
try {
outChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(inChannel != null){
try {
inChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
long end = System.currentTimeMillis();
System.out.println("耗费时间为:" + (end - start));//11
}
⑤ 使用直接缓冲区完成文件的复制(内存映射文件)
代码实例如下:
@Test
public void test2() throws IOException{//2127-1902-1777
long start = System.currentTimeMillis();
//获取FileChannel
FileChannel inChannel = FileChannel.open(Paths.get("1.jpg"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("2.jpg"), StandardOpenOption.WRITE, StandardOpenOption.READ, StandardOpenOption.CREATE);
//内存映射文件
MappedByteBuffer inMappedBuf = inChannel.map(MapMode.READ_ONLY, 0, inChannel.size());
MappedByteBuffer outMappedBuf = outChannel.map(MapMode.READ_WRITE, 0, inChannel.size());
//直接对缓冲区进行数据的读写操作
byte[] dst = new byte[inMappedBuf.limit()];
//从inMappedBuf读取数据到dst
inMappedBuf.get(dst);
//把dst中的数据写入outMappedBuf
outMappedBuf.put(dst);
inChannel.close();
outChannel.close();
long end = System.currentTimeMillis();
System.out.println("耗费时间为:" + (end - start));
}
⑥ 通道之间的数据传输(直接缓冲区)
transferFrom():将数据从源通道传输到其他Channel 中。
transferTo():将数据从源通道传输到其他Channel 中。
实例代码如下:
@Test
public void test3() throws IOException{
FileChannel inChannel = FileChannel.open(Paths.get("1.jpg"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("2.jpg"), StandardOpenOption.WRITE, StandardOpenOption.READ, StandardOpenOption.CREATE);
// inChannel.transferTo(0, inChannel.size(), outChannel);
outChannel.transferFrom(inChannel, 0, inChannel.size());
inChannel.close();
outChannel.close();
}
⑦ 分散(Scatter)和聚集(Gather)
分散读取(Scattering Reads)是指从Channel 中读取的数据“分散”到多个Buffer 中。
如下图所示:
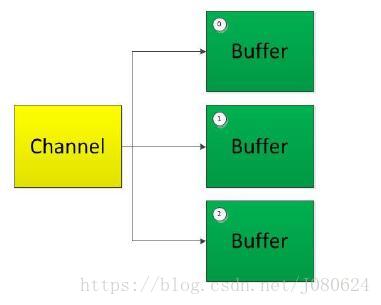
注意:按照缓冲区的顺序,从Channel 中读取的数据依次将Buffer 填满。
聚集写入(Gathering Writes)是指将多个Buffer 中的数据“聚集”到Channel。
如下图所示:
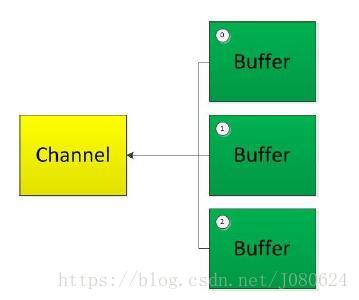
注意:按照缓冲区的顺序,写入position 和limit 之间的数据到Channel
代码示例如下:
@Test
public void test4() throws IOException{
RandomAccessFile raf1 = new RandomAccessFile("1.txt", "rw");
//1. 获取通道
FileChannel channel1 = raf1.getChannel();
//2. 分配指定大小的缓冲区--非直接缓冲区
ByteBuffer buf1 = ByteBuffer.allocate(100);
ByteBuffer buf2 = ByteBuffer.allocate(1024);
//3. 分散读取
ByteBuffer[] bufs = {buf1, buf2};
//通过channel将文件数据读取到buf
channel1.read(bufs);
for (ByteBuffer byteBuffer : bufs) {
//切换为读取模式
byteBuffer.flip();
}
System.out.println(new String(bufs[0].array(), 0, bufs[0].limit()));
System.out.println("-----------------");
System.out.println(new String(bufs[1].array(), 0, bufs[1].limit()));
//4. 聚集写入
RandomAccessFile raf2 = new RandomAccessFile("2.txt", "rw");
FileChannel channel2 = raf2.getChannel();
//将多个buf中的数据通过channel写入到目标文件
channel2.write(bufs);
}
【4】字符集和编码解码
虽然现在字符集和编码解码对于程序员来说很容易就解决,而且在项目中一般都有字符编码过滤器,不会再轻易地遇到乱码现象。但是,字符集和编码解码在大多知识点当中都是一个永恒的话题,是绕不过去的。
不多说,代码示例测试。
① 查看系统中的字符集
示例代码如下:
@Test
public void test5(){
Map<String, Charset> map = Charset.availableCharsets();
Set<Entry<String, Charset>> set = map.entrySet();
for (Entry<String, Charset> entry : set) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
测试结果如下:
Big5=Big5
Big5-HKSCS=Big5-HKSCS
CESU-8=CESU-8
EUC-JP=EUC-JP
EUC-KR=EUC-KR
GB18030=GB18030
GB2312=GB2312
GBK=GBK
IBM-Thai=IBM-Thai
IBM00858=IBM00858
IBM01140=IBM01140
IBM01141=IBM01141
IBM01142=IBM01142
IBM01143=IBM01143
IBM01144=IBM01144
IBM01145=IBM01145
IBM01146=IBM01146
IBM01147=IBM01147
IBM01148=IBM01148
IBM01149=IBM01149
IBM037=IBM037
IBM1026=IBM1026
IBM1047=IBM1047
IBM273=IBM273
IBM277=IBM277
IBM278=IBM278
IBM280=IBM280
IBM284=IBM284
IBM285=IBM285
IBM290=IBM290
IBM297=IBM297
IBM420=IBM420
IBM424=IBM424
IBM437=IBM437
IBM500=IBM500
IBM775=IBM775
IBM850=IBM850
IBM852=IBM852
IBM855=IBM855
IBM857=IBM857
IBM860=IBM860
IBM861=IBM861
IBM862=IBM862
IBM863=IBM863
IBM864=IBM864
IBM865=IBM865
IBM866=IBM866
IBM868=IBM868
IBM869=IBM869
IBM870=IBM870
IBM871=IBM871
IBM918=IBM918
ISO-2022-CN=ISO-2022-CN
ISO-2022-JP=ISO-2022-JP
ISO-2022-JP-2=ISO-2022-JP-2
ISO-2022-KR=ISO-2022-KR
ISO-8859-1=ISO-8859-1
ISO-8859-13=ISO-8859-13
ISO-8859-15=ISO-8859-15
ISO-8859-2=ISO-8859-2
ISO-8859-3=ISO-8859-3
ISO-8859-4=ISO-8859-4
ISO-8859-5=ISO-8859-5
ISO-8859-6=ISO-8859-6
ISO-8859-7=ISO-8859-7
ISO-8859-8=ISO-8859-8
ISO-8859-9=ISO-8859-9
JIS_X0201=JIS_X0201
JIS_X0212-1990=JIS_X0212-1990
KOI8-R=KOI8-R
KOI8-U=KOI8-U
Shift_JIS=Shift_JIS
TIS-620=TIS-620
US-ASCII=US-ASCII
UTF-16=UTF-16
UTF-16BE=UTF-16BE
UTF-16LE=UTF-16LE
UTF-32=UTF-32
UTF-32BE=UTF-32BE
UTF-32LE=UTF-32LE
UTF-8=UTF-8
windows-1250=windows-1250
windows-1251=windows-1251
windows-1252=windows-1252
windows-1253=windows-1253
windows-1254=windows-1254
windows-1255=windows-1255
windows-1256=windows-1256
windows-1257=windows-1257
windows-1258=windows-1258
windows-31j=windows-31j
x-Big5-HKSCS-2001=x-Big5-HKSCS-2001
x-Big5-Solaris=x-Big5-Solaris
x-euc-jp-linux=x-euc-jp-linux
x-EUC-TW=x-EUC-TW
x-eucJP-Open=x-eucJP-Open
x-IBM1006=x-IBM1006
x-IBM1025=x-IBM1025
x-IBM1046=x-IBM1046
x-IBM1097=x-IBM1097
x-IBM1098=x-IBM1098
x-IBM1112=x-IBM1112
x-IBM1122=x-IBM1122
x-IBM1123=x-IBM1123
x-IBM1124=x-IBM1124
x-IBM1166=x-IBM1166
x-IBM1364=x-IBM1364
x-IBM1381=x-IBM1381
x-IBM1383=x-IBM1383
x-IBM300=x-IBM300
x-IBM33722=x-IBM33722
x-IBM737=x-IBM737
x-IBM833=x-IBM833
x-IBM834=x-IBM834
x-IBM856=x-IBM856
x-IBM874=x-IBM874
x-IBM875=x-IBM875
x-IBM921=x-IBM921
x-IBM922=x-IBM922
x-IBM930=x-IBM930
x-IBM933=x-IBM933
x-IBM935=x-IBM935
x-IBM937=x-IBM937
x-IBM939=x-IBM939
x-IBM942=x-IBM942
x-IBM942C=x-IBM942C
x-IBM943=x-IBM943
x-IBM943C=x-IBM943C
x-IBM948=x-IBM948
x-IBM949=x-IBM949
x-IBM949C=x-IBM949C
x-IBM950=x-IBM950
x-IBM964=x-IBM964
x-IBM970=x-IBM970
x-ISCII91=x-ISCII91
x-ISO-2022-CN-CNS=x-ISO-2022-CN-CNS
x-ISO-2022-CN-GB=x-ISO-2022-CN-GB
x-iso-8859-11=x-iso-8859-11
x-JIS0208=x-JIS0208
x-JISAutoDetect=x-JISAutoDetect
x-Johab=x-Johab
x-MacArabic=x-MacArabic
x-MacCentralEurope=x-MacCentralEurope
x-MacCroatian=x-MacCroatian
x-MacCyrillic=x-MacCyrillic
x-MacDingbat=x-MacDingbat
x-MacGreek=x-MacGreek
x-MacHebrew=x-MacHebrew
x-MacIceland=x-MacIceland
x-MacRoman=x-MacRoman
x-MacRomania=x-MacRomania
x-MacSymbol=x-MacSymbol
x-MacThai=x-MacThai
x-MacTurkish=x-MacTurkish
x-MacUkraine=x-MacUkraine
x-MS932_0213=x-MS932_0213
x-MS950-HKSCS=x-MS950-HKSCS
x-MS950-HKSCS-XP=x-MS950-HKSCS-XP
x-mswin-936=x-mswin-936
x-PCK=x-PCK
x-SJIS_0213=x-SJIS_0213
x-UTF-16LE-BOM=x-UTF-16LE-BOM
X-UTF-32BE-BOM=X-UTF-32BE-BOM
X-UTF-32LE-BOM=X-UTF-32LE-BOM
x-windows-50220=x-windows-50220
x-windows-50221=x-windows-50221
x-windows-874=x-windows-874
x-windows-949=x-windows-949
x-windows-950=x-windows-950
x-windows-iso2022jp=x-windows-iso2022jp
//共170个
简直是承上启下,继往开来啊!
② 编码解码测试示例
代码如下:
@Test
public void test6() throws IOException{
Charset cs1 = Charset.forName("GBK");
//获取编码器
CharsetEncoder ce = cs1.newEncoder();
//获取解码器
CharsetDecoder cd = cs1.newDecoder();
CharBuffer cBuf = CharBuffer.allocate(1024);
// GBK下一个汉字和中文字符分别占两个字节
cBuf.put("祖国节日快乐!");
//切换为读取 模式
cBuf.flip();
//编码
ByteBuffer bBuf = ce.encode(cBuf);
System.out.println("bBuf capacity : "+bBuf.capacity()+" ,limit :"+bBuf.limit()+" , position : "+bBuf.position());
//bBuf capacity : 14 ,limit :14 , position : 0
for (int i = 0; i < 12; i++) {
System.out.println("编码后 :"+bBuf.get());
//将会修改bBuf的position为12
}
//解码--切换为读取模式
bBuf.flip();
//filp修改limit为当前position--12,修改position为0--丢失了字符 !
System.out.println("bBuf capacity : "+bBuf.capacity()+" ,limit :"+bBuf.limit()+" , position : "+bBuf.position());
//bBuf capacity : 14 ,limit :12 , position : 0
//解码为字符数组
CharBuffer cBuf2 = cd.decode(bBuf);
System.out.println("解码后 :"+cBuf2.toString());
System.out.println("bBuf capacity : "+bBuf.capacity()+" ,limit :"+bBuf.limit()+" , position : "+bBuf.position());
//bBuf capacity : 14 ,limit :12 , position : 12
System.out.println("------------------------------------------------------");
Charset cs2 = Charset.forName("GBK");
// Charset cs2 = Charset.forName("UTF-8");
//rewind 修改了position,并不会修改limit。
bBuf.rewind();
//flip将limit修改为当前position,position修改为0
// bBuf.flip();
System.out.println("bBuf capacity : "+bBuf.capacity()+" ,limit :"+bBuf.limit()+" , position : "+bBuf.position());
//bBuf capacity : 14 ,limit :12 , position : 0
CharBuffer cBuf3 = cs2.decode(bBuf);
System.out.println("cbuf3 length :" +cBuf3.length());
System.out.println(cBuf3.toString());
}
核心思想,同一种字符集下,编码解码是不会出现乱码现象的。页面或者系统某个地方之所有乱码,无非是编码解码所用的字符集不同,或者使用不恰当的字符集(比如中文和ISO-8859-1)。
③ 测试当前环境字符集
代码示例如下:
@Test
public void test7() throws UnsupportedEncodingException {
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
String str = "祖国节日快乐!";
byteBuffer.put(str.getBytes());
System.out.println("数组大小 : "+byteBuffer.position()+" , Charset : "+Charset.defaultCharset());//21
//切换为读取 模式
byteBuffer.flip();
byte[] dst = new byte[byteBuffer.limit()];
byteBuffer.get(dst, 0, byteBuffer.limit());
System.out.println(new String(dst,0,byteBuffer.limit()));
}
测试结果如下:
//UTF-8下,一个汉字或中文字符各占三个字节
数组大小 : 21 , Charset : UTF-8
祖国节日快乐!
【5】BIO,NIO,AIO
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:Non IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO,异步 IO 的操作基于事件和回调机制。
① BIO
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
② NIO
NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio包,提供了 Channel , Selector,Buffer等抽象。NIO中的 N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。
NIO提供了与传统BIO模型中的 Socket 和ServerSocket 相对应的 SocketChannel 和ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
③ AIO
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。


















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











