







数据库的四个基本概念
1、数据(Data)
2、数据库(Database)
3、数据库管理系统(DBMS)
4、数据库系统(DBS)
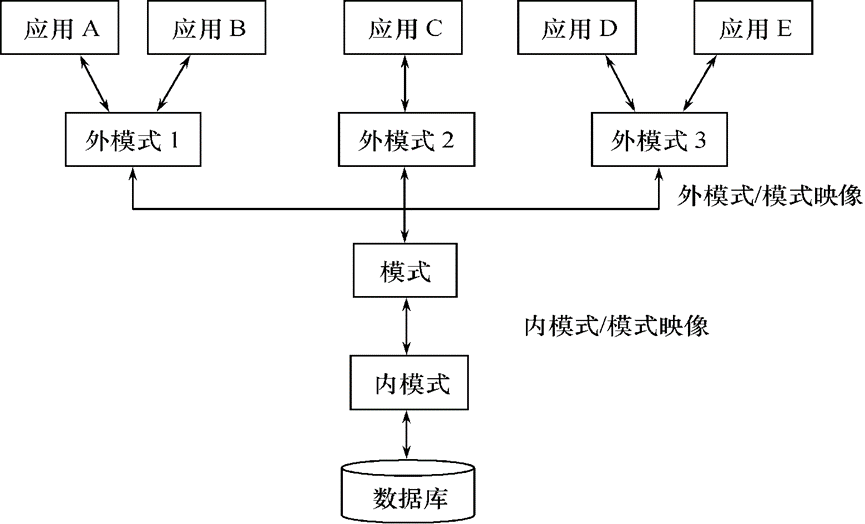
数据库系统的三级模式结构(模式、外模式、内模式),二级映像功能(外模式/模式映像、模式/内模式映像):
关系数据库
信息世界中的基本概念
(1)实体(Entity):可以是具体的人、事、物或抽象的概念。
(2)属性(Attribute):实体所具有的某一特性称为属性。
(3)码(Key):唯一标识实体的属性集称为码。
(4)实体型(Entity Type):用实体名及其属性名集合来抽象和刻画同类实体称为实体型。
(5)实体集(Entity Set):同一类型实体的集合称为实体集。
(6)联系(Relationship):
1、实体内部的联系通常是指组成实体的各属性之间的联系
2、实体之间的联系通常是指不同实体集之间的联系
3、实体之间的联系有一对一、一对多和多对多等多种类型
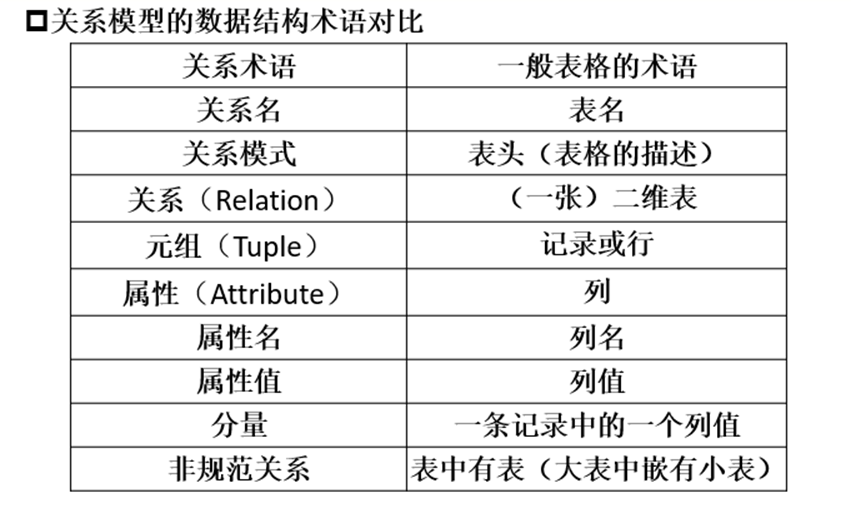
关系模型
在用户观点下,关系模型中数据的逻辑结构是一张二维表,它由行和列组成。
几个重点概念
1、域(Domain)是一组具有相同数据类型的值的集合。例:整数、实数、介于某个取值范围的整数。
2、候选码(Candidate key)。若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码
3、主码
若一个关系有多个候选码,则选定其中一个为主码(Primary key)
每个关系的主码在定义关系时被选择和声明。一旦被选中,就无法改变。
为了提高存储效率和查询处理效率,通常选择属性数最少的候选键为主码。
定义了主码后,当插入新元组时,只需要检查主码属性下的值以识别重复项。
4、主属性
候选码的诸属性称为主属性(Prime attribute)
不包含在任何侯选码中的属性称为非主属性(Non-Prime attribute)或非码属性(Non-key attribute)
基本关系的性质
① 列是同质的(Homogeneous)
② 不同的列可出自同一个域,不同的属性要给予不同的属性名
③ 任意两个元组的候选码不能相同
④ 列的顺序无所谓,,列的次序可以任意交换
⑤ 行的顺序无所谓,行的次序可以任意交换
给一个元组t 和属性 A, 当插入 t 到关系R中时,如有下属情况:
t[A] is unknown (未知).
t[A] is yet to be assigned (未分配).
t[A] is inapplicable (不适用).
设置为空值,即 t[A]: t[A] = null.
注意:空值与0或空格不同!在SQL中,任何涉及null的算术表达式都将被计算为null。

设F是基本关系R的一个或一组属性,但不是关系R的码。如果F与基本关系S的主码Ks相对应,则称F是R的外码。
基本关系R称为参照关系(Referencing Relation)
基本关系S称为被参照关系(Referenced Relation)或目标关系(Target Relation)
若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应,则对于R中每个元组在F上的值必须为:
1、取空值(F的每个属性值均为空值)
2、等于S中某个元组的主码值

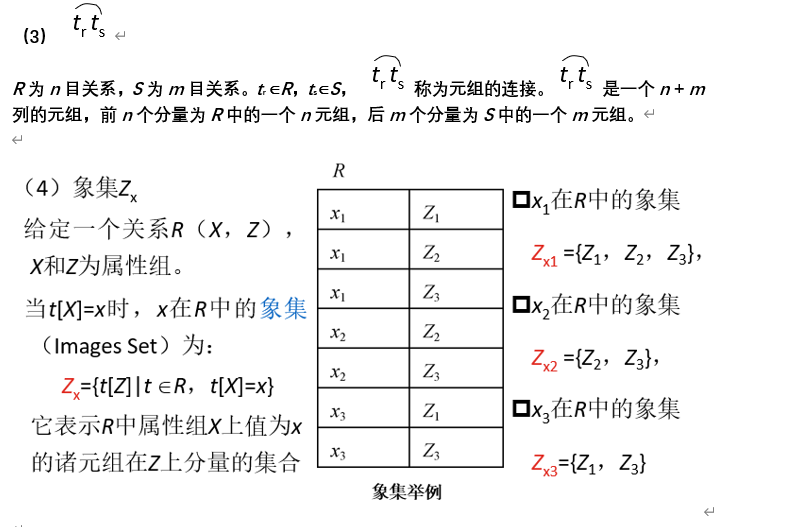
关系代数
传统的集合运算:并、差、交、笛卡尔积
专门的关系运算:选择、投影、连接、除运算


专门的关系运算
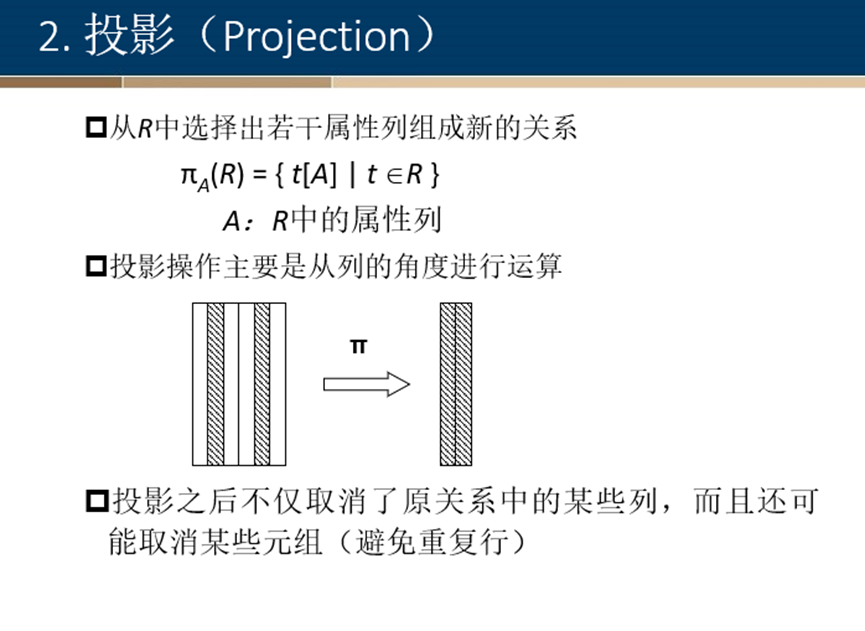
选择

投影
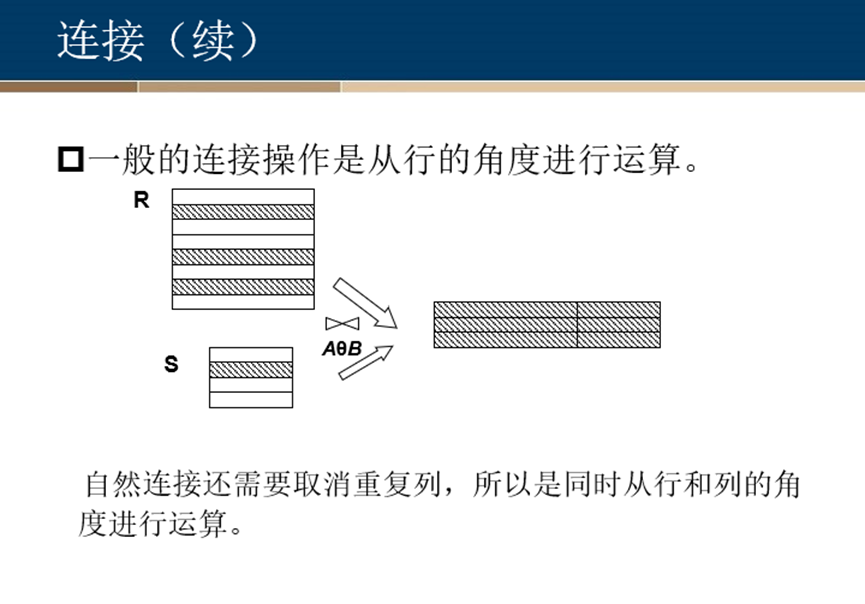
连接
等值连接与自然连接



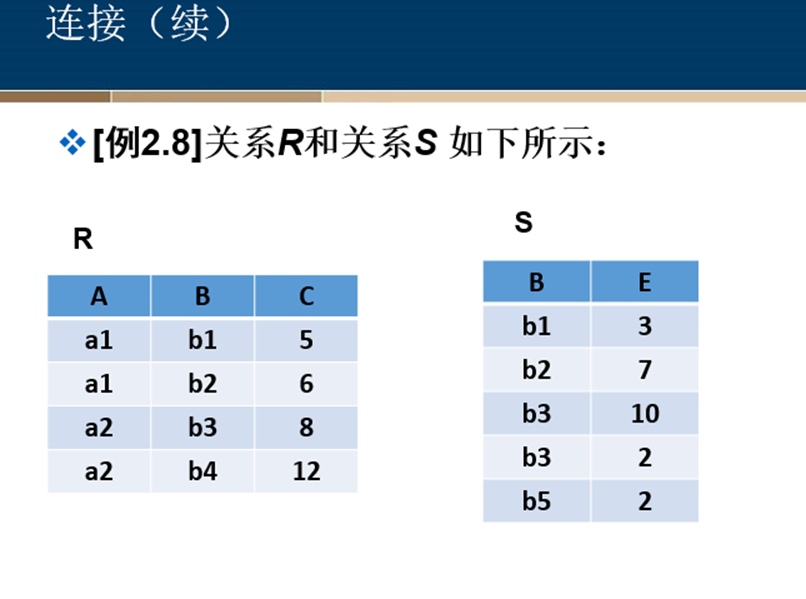
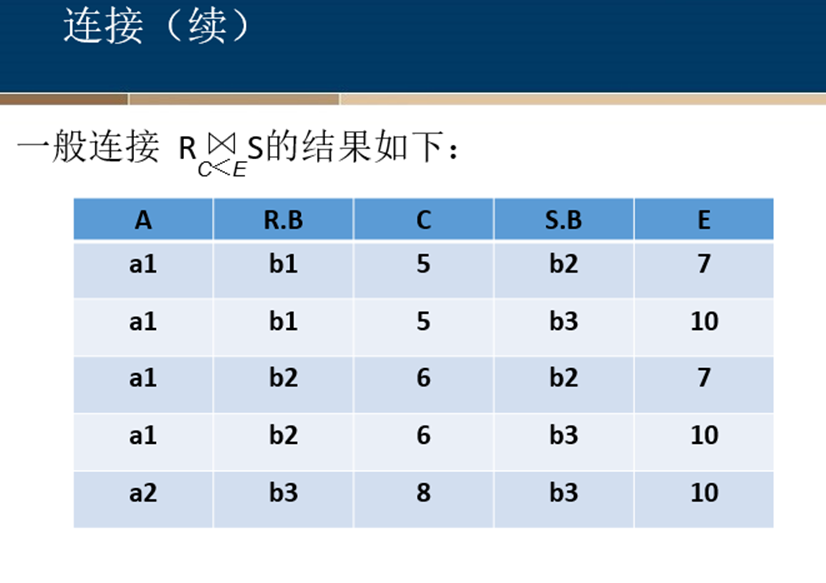
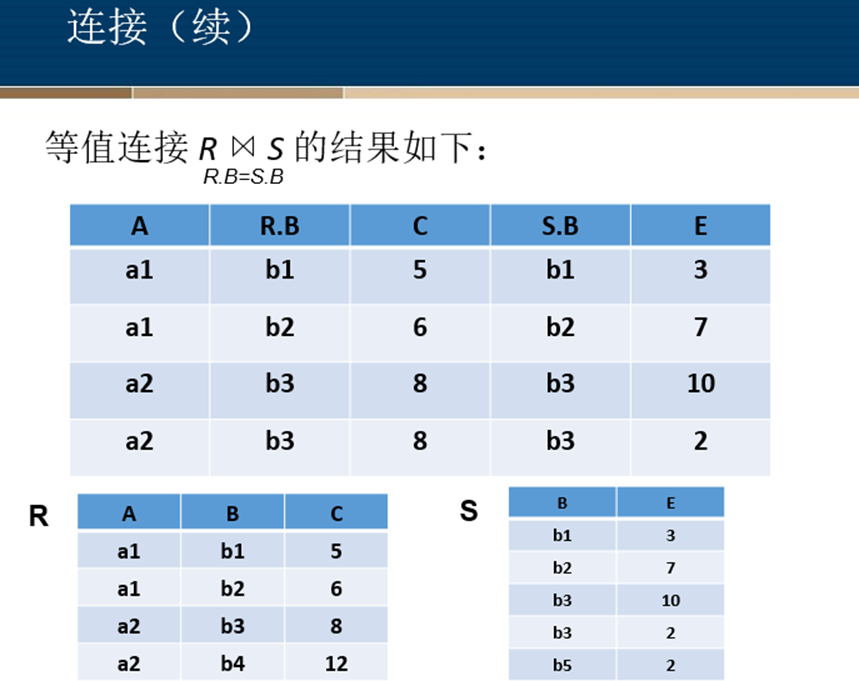

悬浮元组
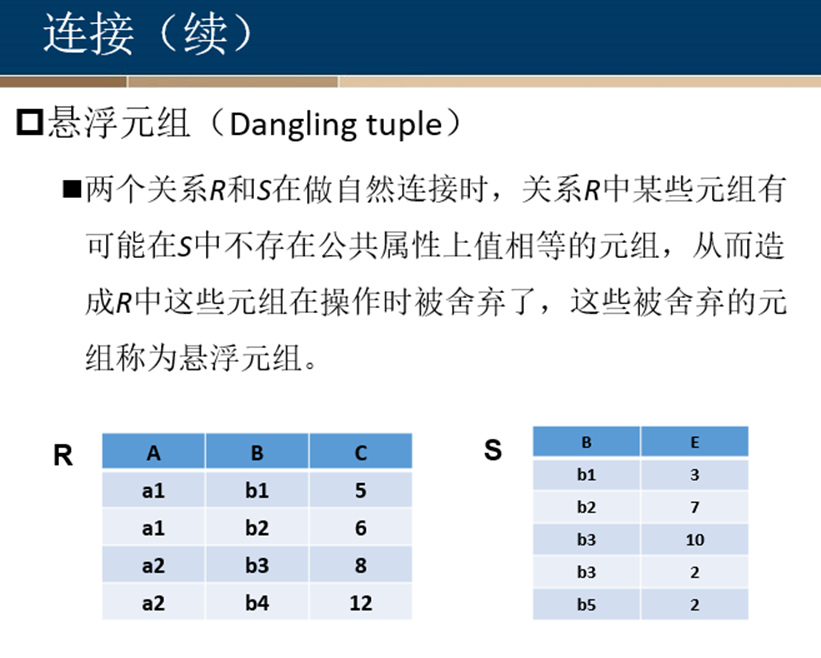
外连接

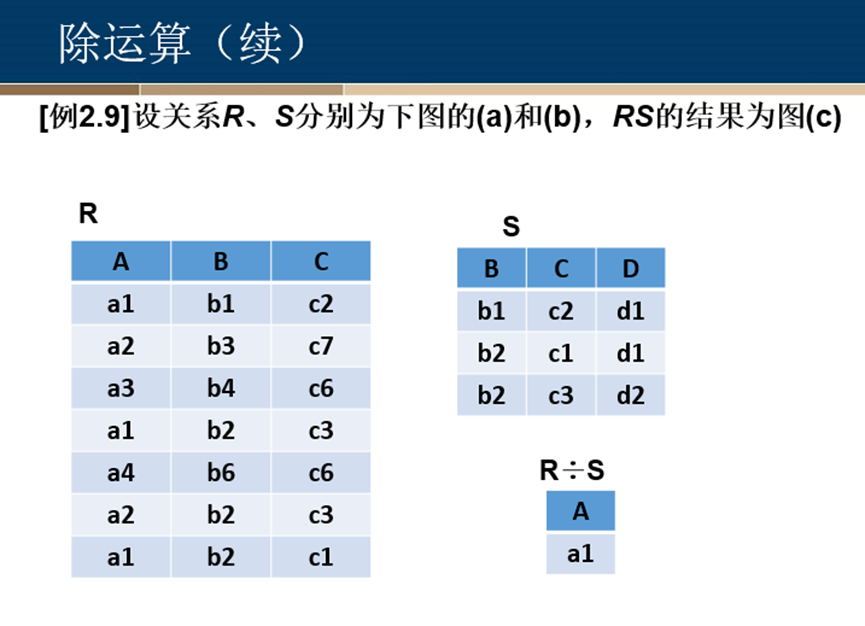
除运算
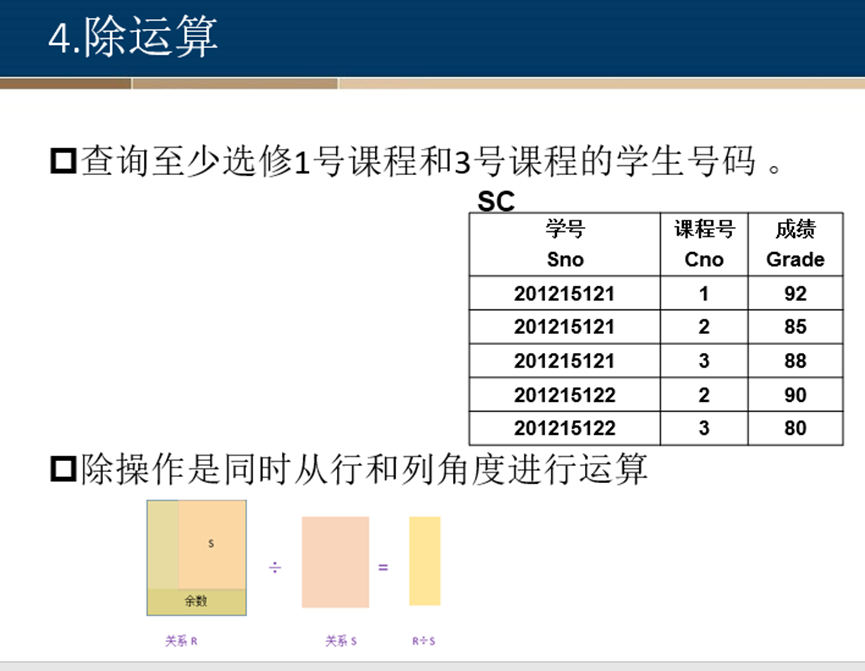
除运算比较难理解,先找出满足关系S的行,再将包含关系S中属性的列去掉。

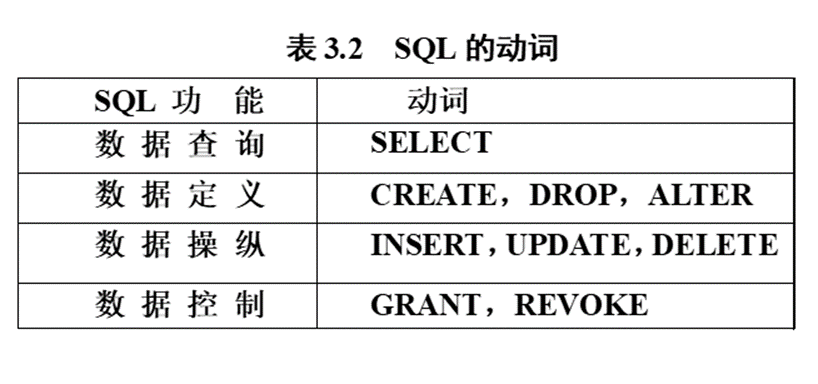
SQL语言
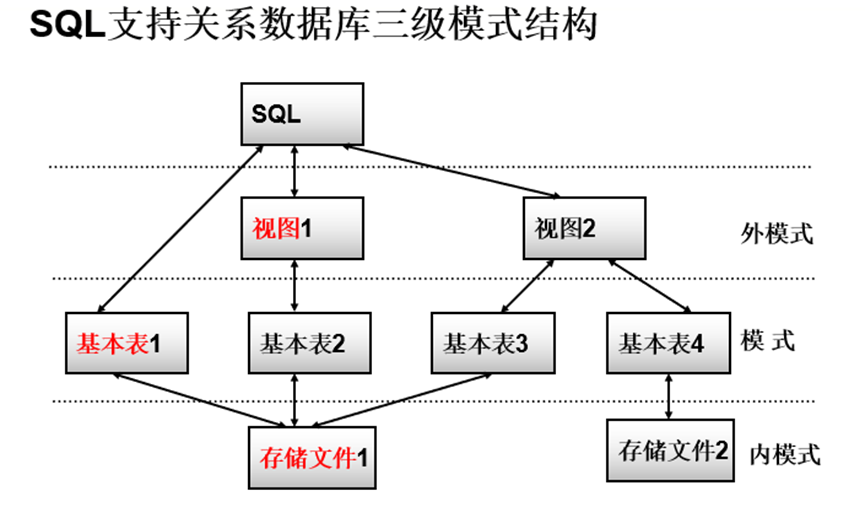
基本表
1、本身独立存在的表
2、SQL中一个关系就对应一个基本表
3、一个(或多个)基本表对应一个存储文件
4、一个表可以带若干索引
存储文件
1、逻辑结构组成了关系数据库的内模式
2、物理结构对用户是隐蔽的
视图
1、从一个或几个基本表导出的表
2、数据库中只存放视图的定义而不存放视图对应的数据
3、视图是一个虚表
4、用户可以在视图上再定义视图
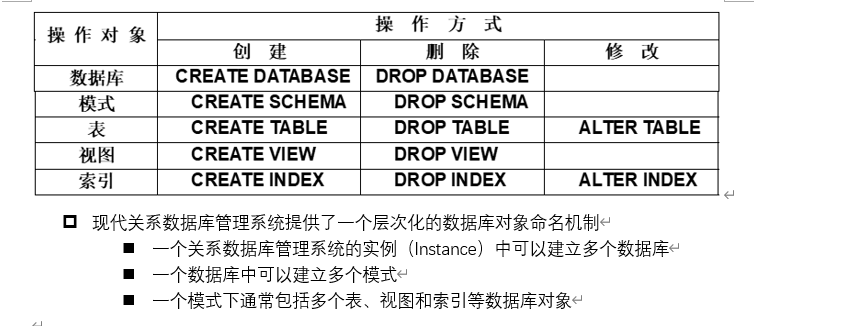
DDL(Data Definition Language)数据定义语言
一、操作库
创建库
create database db1;
– 创建库是否存在,不存在则创建
create database if not exists db1;
– 查看所有数据库
show databases;
– 查看某个数据库的定义信息
show create database db1;
– 修改数据库字符信息
alter database db1 character set utf8;
– 删除数据库
drop database db1;
二、操作表
创建表
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
– 查看表结构
desc 表名;
– 查看创建表的SQL语句
show create table 表名;
– 修改表名
alter table 表名 rename to 新的表名;
– 添加一列
alter table 表名 add 列名 数据类型;
– 删除列
alter table 表名 drop 列名;
– 删除表
drop table 表名;
drop table if exists 表名 ;
DML(Data Manipulation Language)数据操作语言
增加 insert into
写全所有列名
insert into 表名(列名1,列名2,…列名n) values(值1,值2,…值n);
– 不写列名(所有列全部添加)
insert into 表名 values(值1,值2,…值n);
– 插入部分数据
insert into 表名(列名1,列名2) values(值1,值2);
删除 delete
– 删除表中数据
delete from 表名 where 列名 = 值;
– 删除表中所有数据
delete from 表名;
– 删除表中所有数据(高效 先删除表,然后再创建一张一样的表。)
truncate table 表名;
修改 update
不带条件的修改(会修改所有行)
update 表名 set 列名 = 值;
– 带条件的修改
update 表名 set 列名 = 值 where 列名=值;
DQL(Data Query Language)数据查询语言
关于查询语句有很多,这里基础的不再介绍。主要介绍排序查询、聚合函数、模糊查询、分组查询、分页查询、内连接、外连接、子查询
一、基础关键字
BETWEEN…AND (在什么之间)和 IN( 集合)
– 查询年龄大于等于20 小于等于30
SELECT * FROM student WHERE age >= 20 && age <=30;
SELECT * FROM student WHERE age >= 20 AND age <=30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;
– 查询年龄22岁,18岁,25岁的信息
SELECT * FROM student WHERE age = 22 OR age = 18 OR age = 25
SELECT * FROM student WHERE age IN (22,18,25);
is null(不为null值) 与 like(模糊查询)、distinct(去除重复值)
– 查询英语成绩不为null
SELECT * FROM student WHERE english IS NOT NULL;
:单个任意字符
%:多个任意字符
– 查询姓马的有哪些? like
SELECT * FROM student WHERE NAME LIKE ‘马%’;
– 查询姓名第二个字是化的人
SELECT * FROM student WHERE NAME LIKE "化%";
– 查询姓名是3个字的人
SELECT * FROM student WHERE NAME LIKE '_';
– 查询姓名中包含德的人
SELECT * FROM student WHERE NAME LIKE ‘%德%’;
– 关键词 DISTINCT 用于返回唯一不同的值。
– 语法:SELECT DISTINCT 列名称 FROM 表名称
SELECT DISTINCT NAME FROM student ;
二、排序查询 order by
语法:order by 子句
order by 排序字段1 排序方式1 , 排序字段2 排序方式2...
注意:
如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
– 例子
SELECT * FROM person ORDER BY math; --默认升序
SELECT * FROM person ORDER BY math desc; --降序
三、 聚合函数
聚合函数:将一列数据作为一个整体,进行纵向的计算
1.count:计算个数
2.max:计算最大值
3.min:计算最小值
4.sum:计算和
5.avg:计算平均数
四、 分组查询 group by
语法:group by 分组字段;
注意:分组之后查询的字段:分组字段、聚合函数
– 按照性别分组。分别查询男、女同学的平均分
SELECT sex , AVG(math) FROM student GROUP BY sex;
– 按照性别分组。分别查询男、女同学的平均分,人数
SELECT sex , AVG(math),COUNT(id) FROM student GROUP BY sex;
– 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex;
– 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT(id) > 2;
SELECT sex , AVG(math),COUNT(id) 人数 FROM student WHERE math > 70 GROUP BY sex HAVING 人数 > 2;
五、 分页查询
1. 语法:limit 开始的索引,每页查询的条数;
2. 公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
3. limit 是一个MySQL"方言"
– 每页显示3条记录
SELECT * FROM student LIMIT 0,3; – 第1页
SELECT * FROM student LIMIT 3,3; – 第2页
SELECT * FROM student LIMIT 6,3; – 第3页
六、内连接查询
- 从哪些表中查询数据
2.条件是什么
- 查询哪些字段
1.隐式内连接:使用where条件消除无用数据
– 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.dept_id = dept.id;
SELECT
t1.name, – 员工表的姓名
t1.gender,-- 员工表的性别
t2.name – 部门表的名称
FROM
emp t1,
dept t2
WHERE
t1.dept_id = t2.id;
2.显式内连接
– 语法:
select 字段列表 from 表名1 [inner] join 表名2 on 条件
– 例如:
SELECT * FROM emp INNER JOIN dept ON emp.dept_id = dept.id;
SELECT * FROM emp JOIN dept ON emp.dept_id = dept.id;
七、外连接查询
1.左外连接 – 查询的是左表所有数据以及其交集部分。
– 语法:select 字段列表 from 表1 left [outer] join 表2 on 条件;
– 例子:
– 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.*,t2.name FROM emp t1 LEFT JOIN dept t2 ON t1.dept_id = t2.id;
2.右外连接 – 查询的是右表所有数据以及其交集部分。
– 语法:
select 字段列表 from 表1 right [outer] join 表2 on 条件;
– 例子:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.dept_id = t2.id;
八、子查询:查询中嵌套查询
查询工资最高的员工信息
– 1 查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;
– 2 查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.salary = 9000;
– 一条sql就完成这个操作。这就是子查询
SELECT * FROM emp WHERE emp.salary = (SELECT MAX(salary) FROM emp);
1.子查询的结果是单行单列的
子查询可以作为条件,使用运算符去判断。 运算符: > >= < <= =
– 查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);
2. 子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断
– 查询’财务部’和’市场部’所有的员工信息
SELECT id FROM dept WHERE NAME = ‘财务部’ OR NAME = ‘市场部’;
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
– 子查询
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = ‘财务部’ OR NAME = ‘市场部’);
3. 子查询的结果是多行多列的:
子查询可以作为一张虚拟表参与查询
– 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
– 子查询
SELECT * FROM dept t1 ,(SELECT * FROM emp WHERE emp.join_date > ‘2011-11-11’) t2 WHERE t1.id = t2.dept_id;
– 普通内连接
SELECT * FROM emp t1,dept t2 WHERE t1.dept_id = t2.id AND t1.join_date > ‘2011-11-11’
DCL(Data Control Language)数据控制语言
管理用户
添加用户
语法:CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
删除用户
语法:DROP USER ‘用户名’@‘主机名’;
权限管理
查询权限
– 查询权限
SHOW GRANTS FOR ‘用户名’@‘主机名’;
SHOW GRANTS FOR ‘lisi’@‘%’;
授予权限
– 授予权限
grant 权限列表 on 数据库名.表名 to ‘用户名’@‘主机名’;
– 给张三用户授予所有权限,在任意数据库任意表上
GRANT ALL ON *.*TO ‘zhangsan’@‘localhost’;
撤销权限
– 撤销权限:
revoke 权限列表 on 数据库名.表名 from ‘用户名’@‘主机名’;
REVOKE UPDATE ON db3.account FROM ‘lisi’@‘%’;
sql语句顺序和执行顺序
(8)SELECT (9)DISTINCT
(1)FROM
(3)JOIN(2)ON
(4)WHERE
(5)GROUP BY <group_by_list>
(6)WITH {CUBE|ROLLUP}
(7)HAVING
(10)ORDER BY <order_by_list>
(11)LIMIT <limit_number>
关系数据理论
基本概念




Armstrong公理系统




模式的分解




数据库设计的基本步骤
数据库设计分6个阶段
1、需求分析
2、概念结构设计
3、逻辑结构设计
4、物理结构设计
5、数据库实施
6、数据库运行和维护

概念结构:E-R模型的设计;
逻辑结构:E-R模型转换为关系模型。
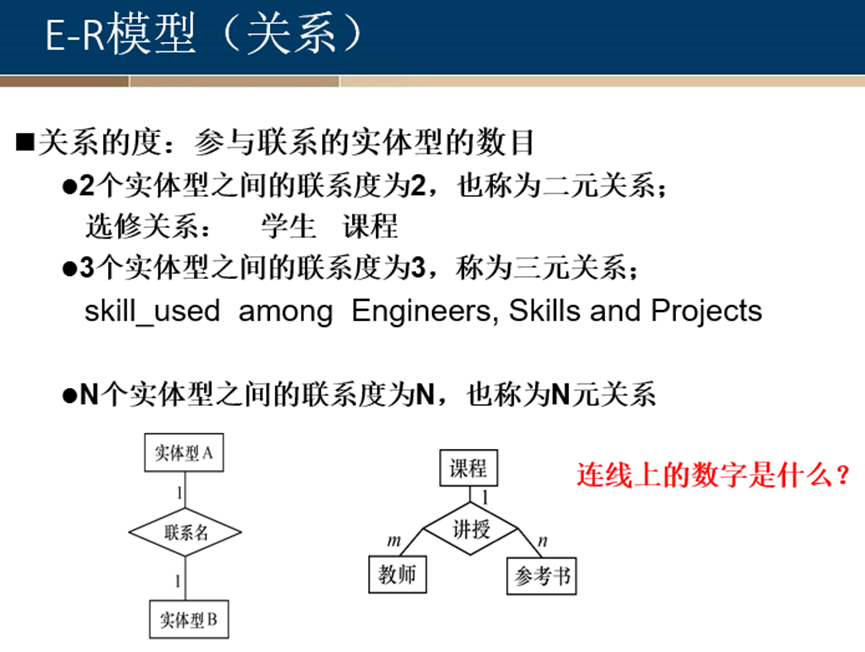
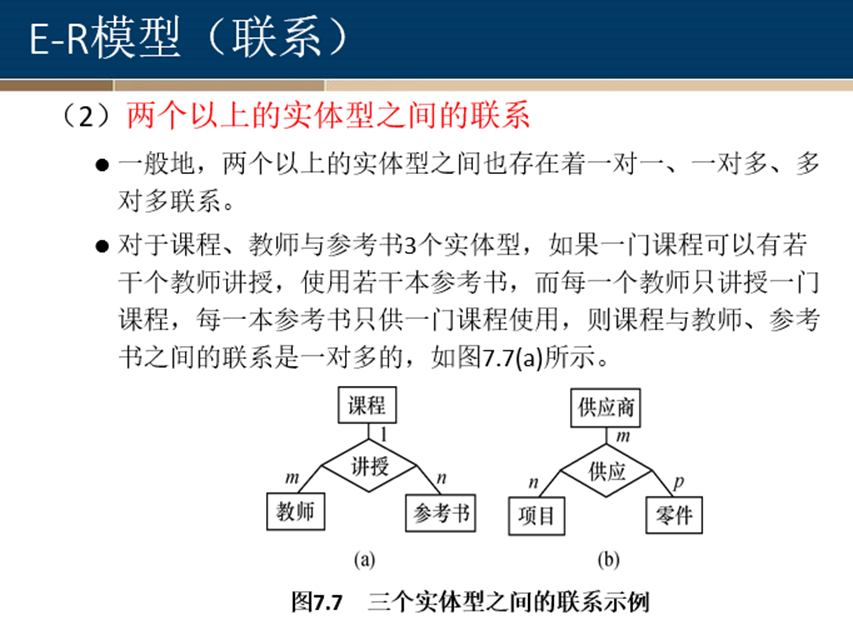
E-R模型




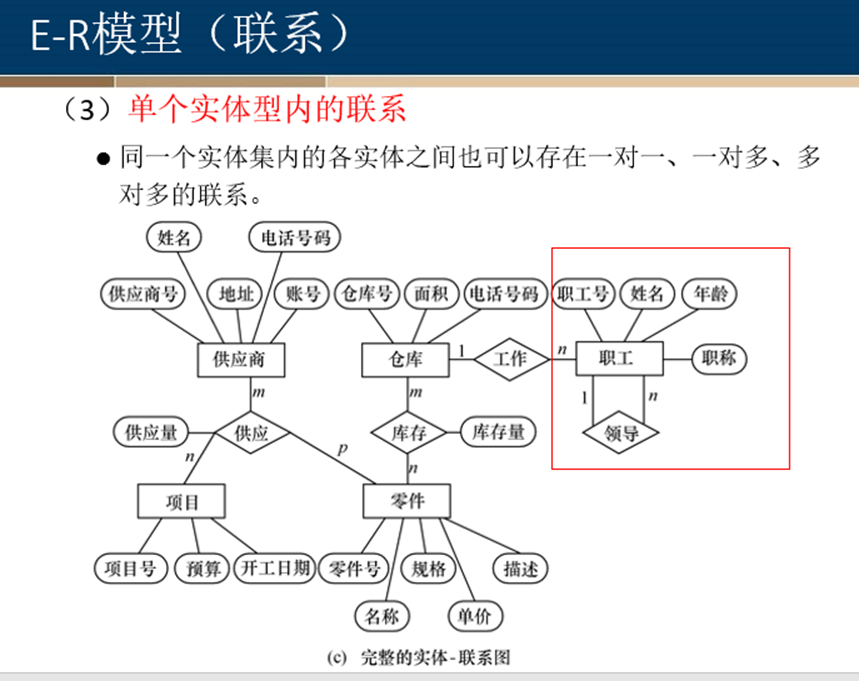
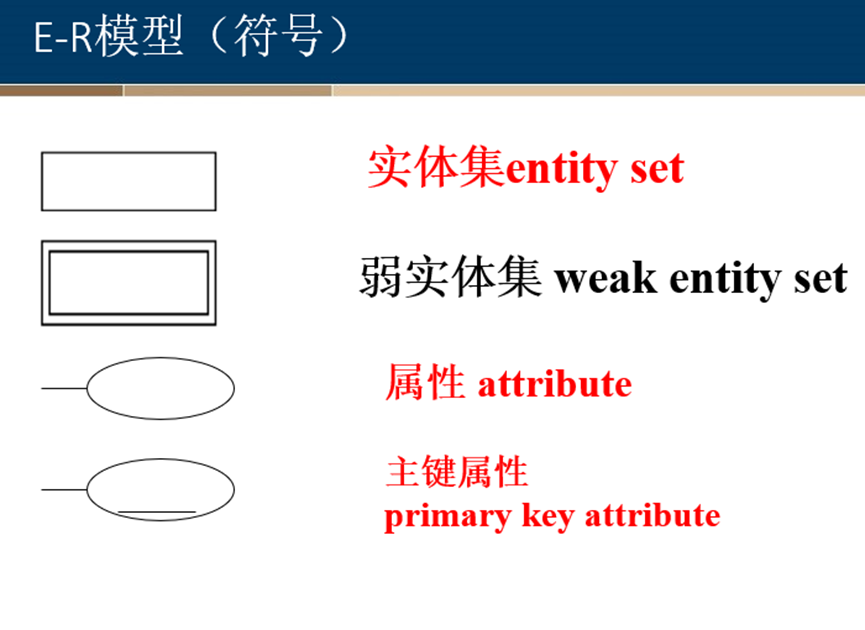
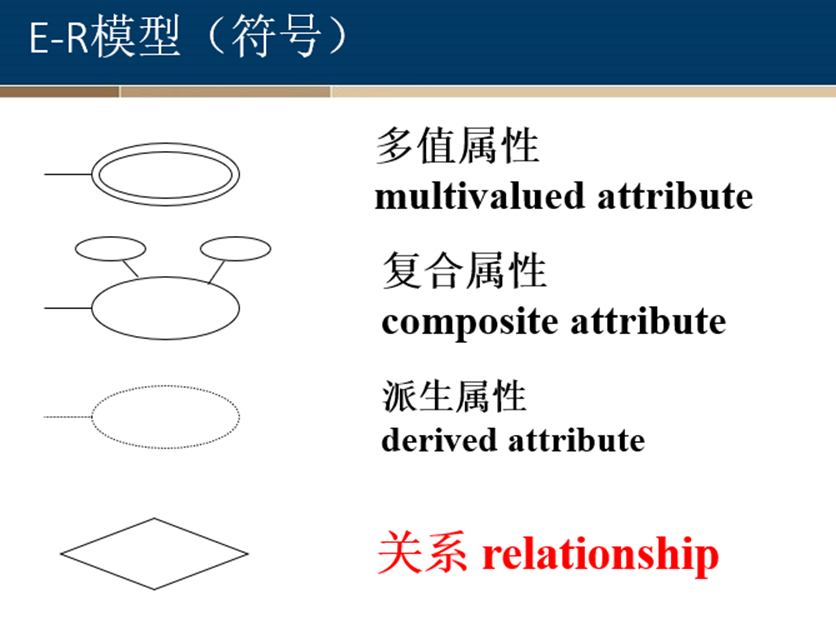
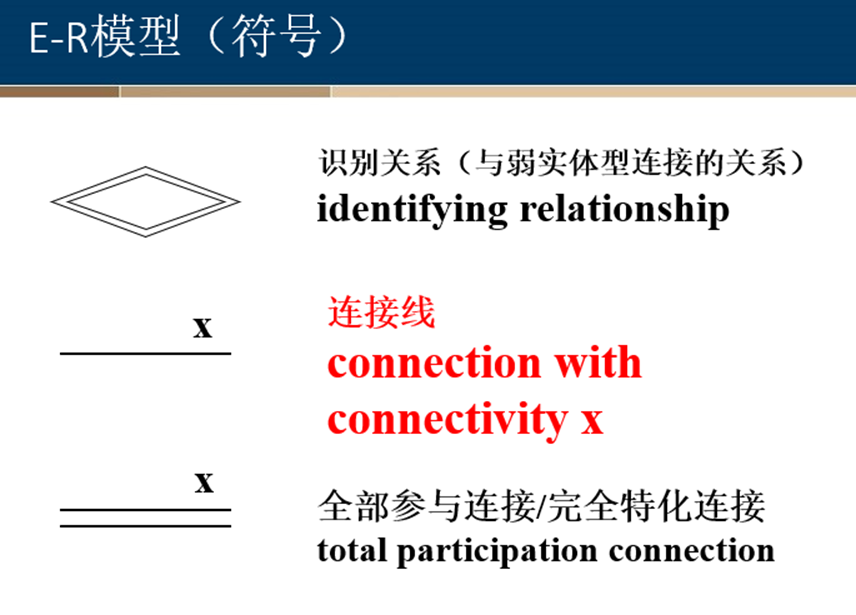
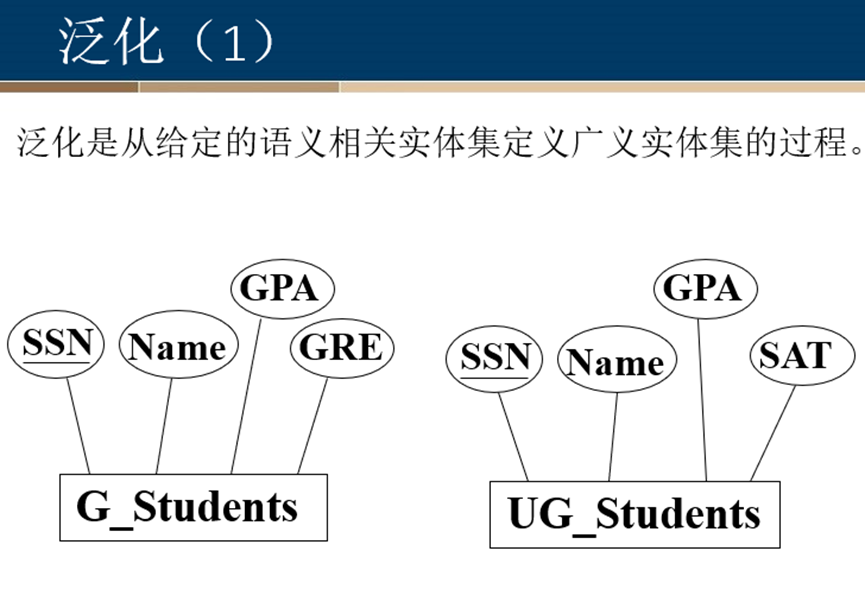
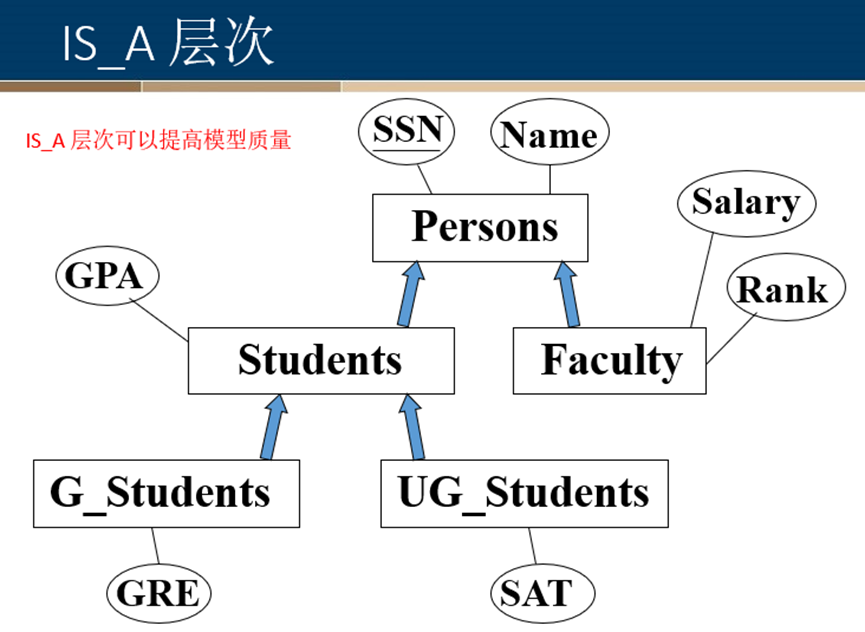
定义:有些实体集的所有属性都不足以形成主码,这样的实体集称为弱实体集。 与此相对,其属性可以形成主码的实体集称为强实体集。
扩展ER 模型 (EER 模型)
介绍两种扩展:
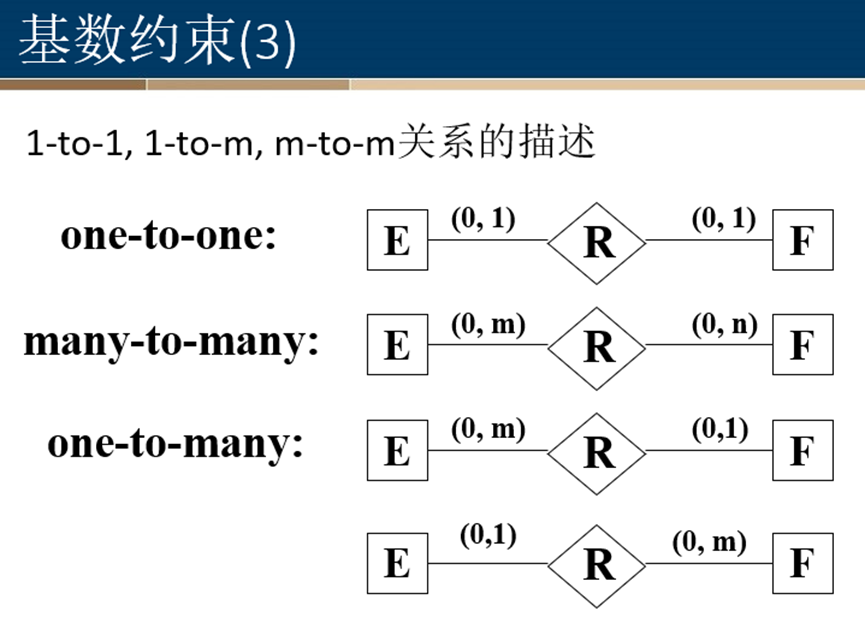
1、更精确的连接描述,基数约束
2、泛化/特化层次


IS_A层次


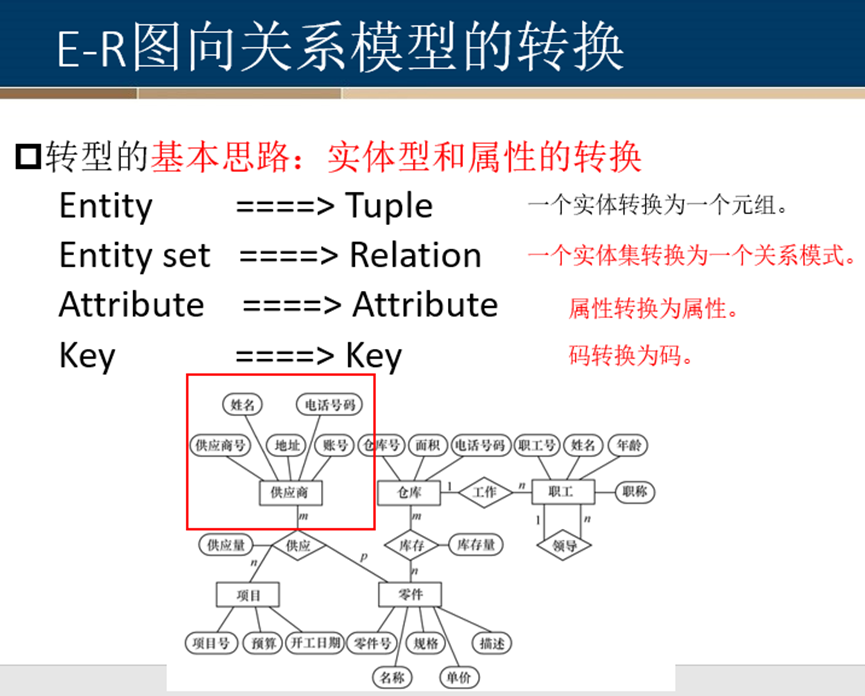
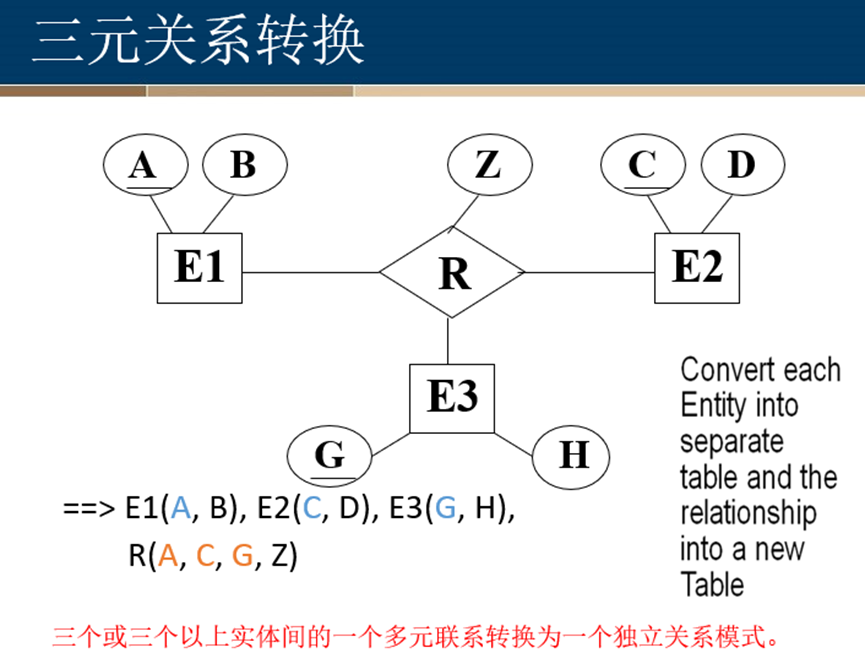
E-R图向关系模型的转换
基本思路
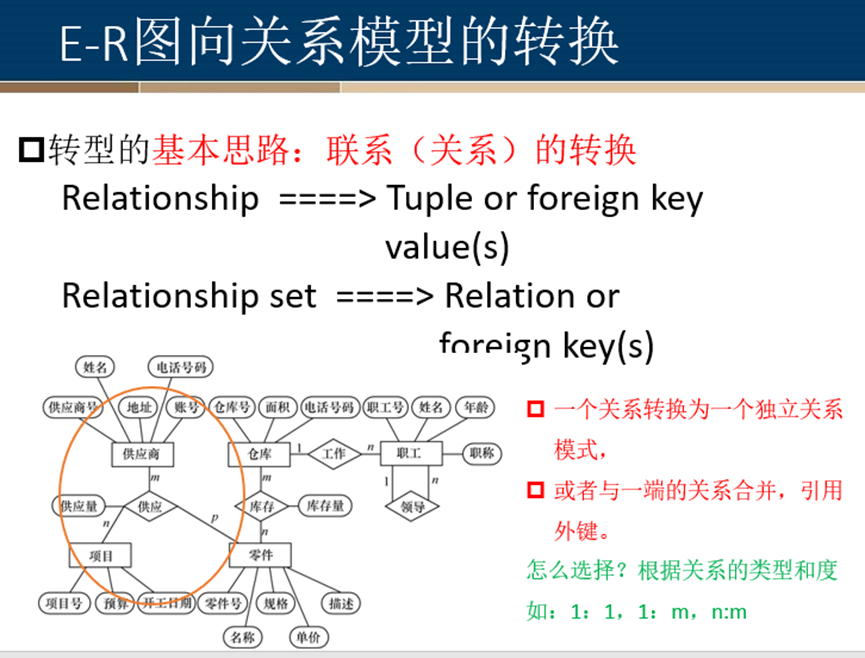
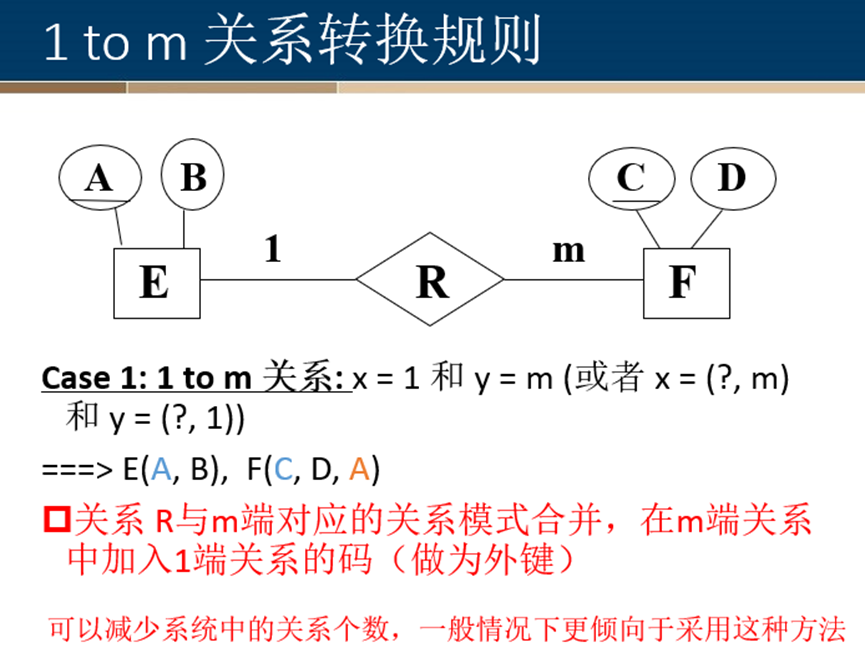
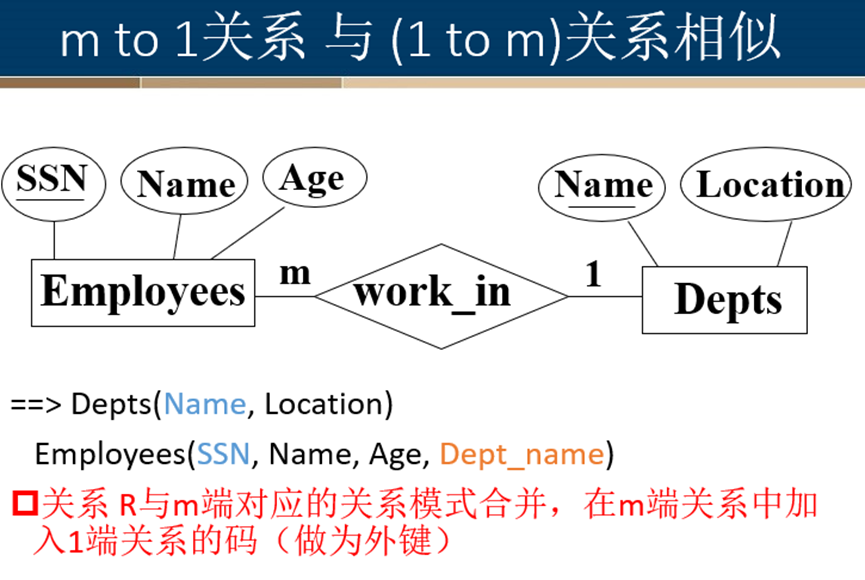
一对多关系转换
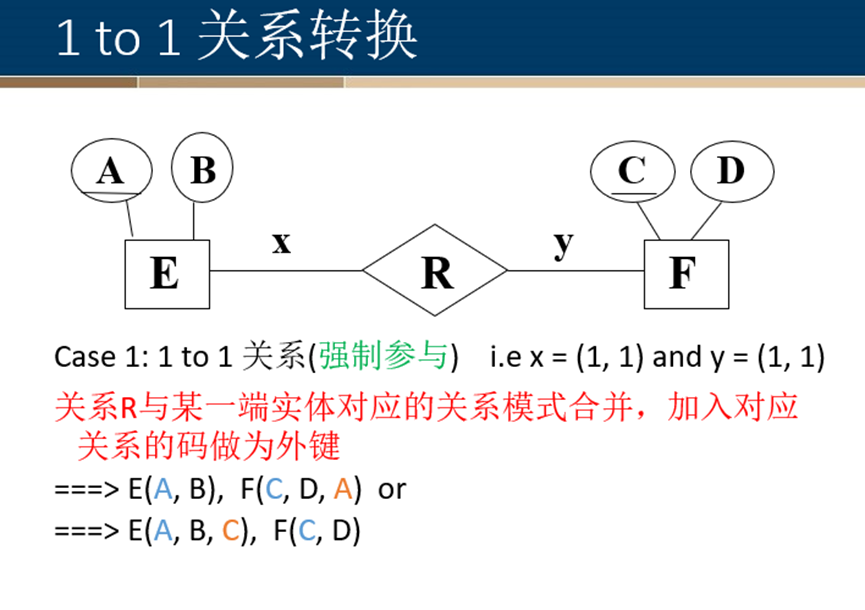
一对一关系转换
多对多关系转换
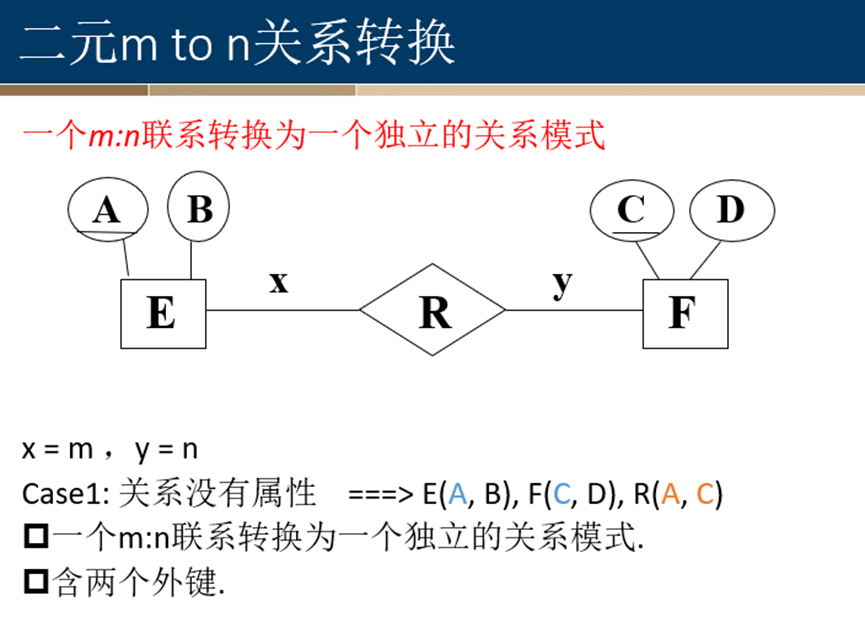
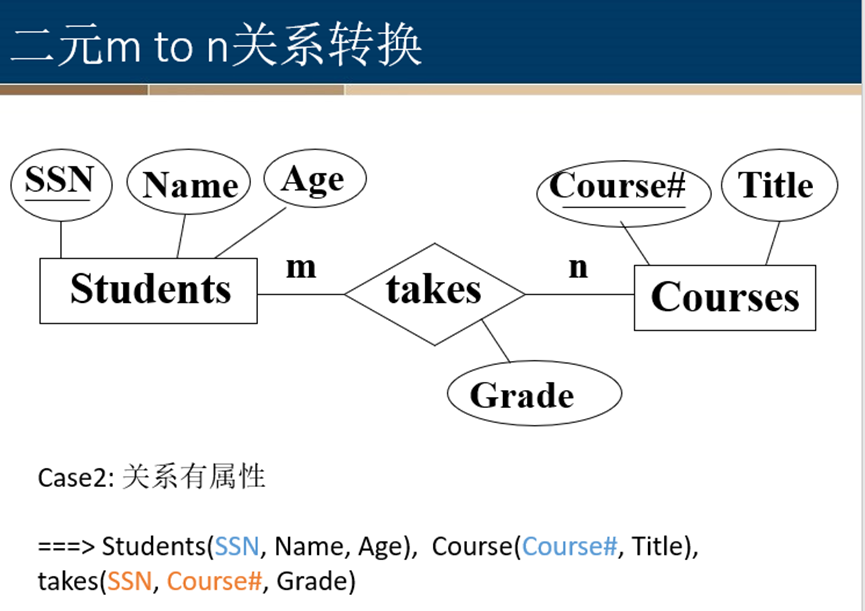
一元关系转换


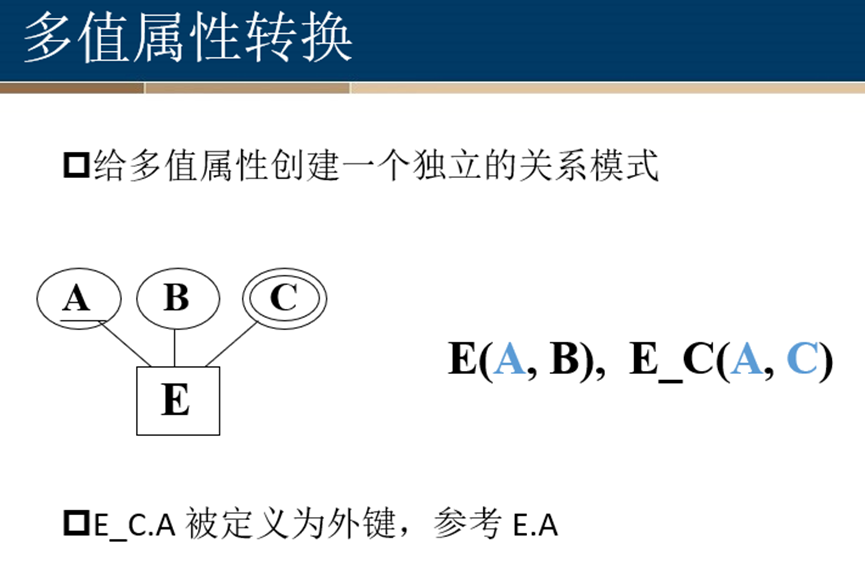
多值属性转换

复合属性转换
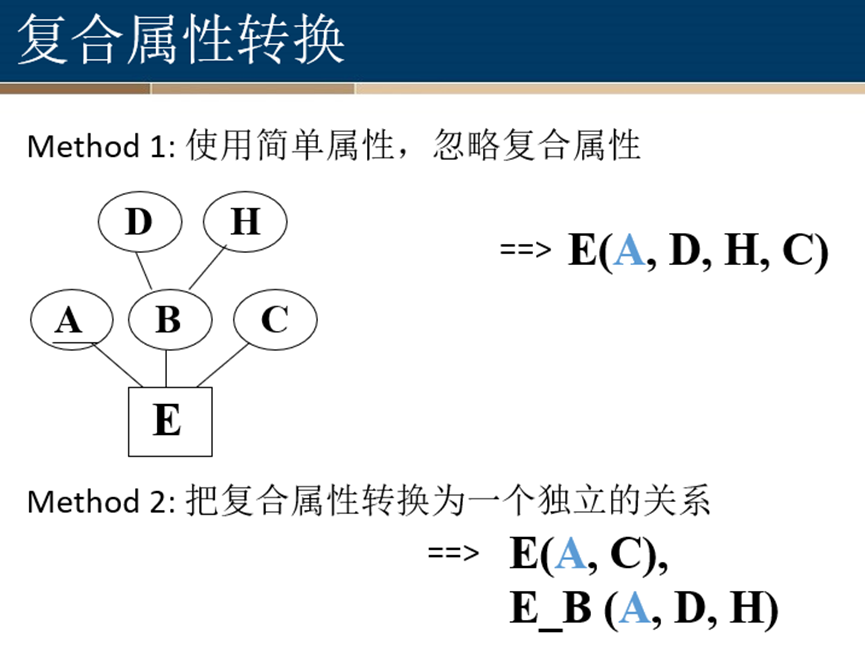
弱实体集转换

IS_A 层次结构转换

复杂EER 图转换

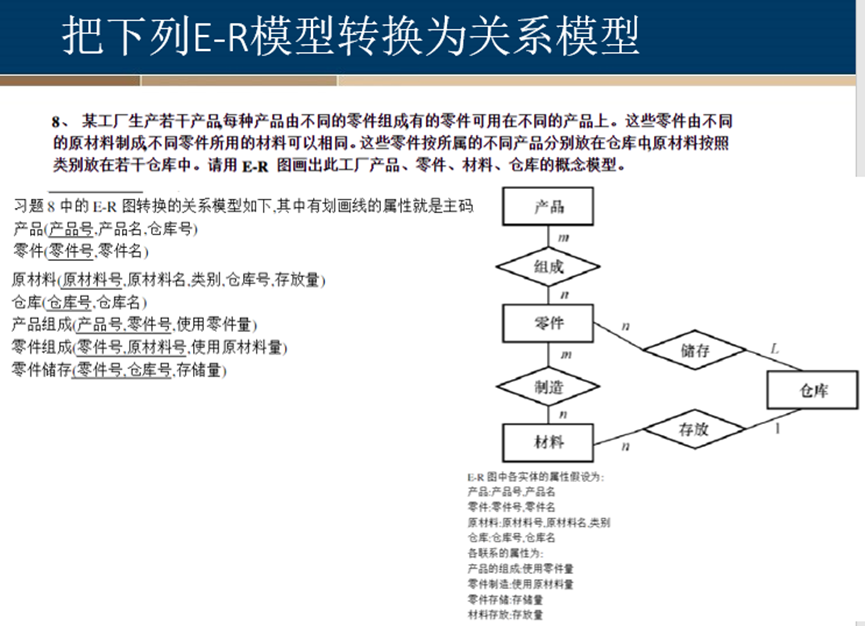
例子
1、
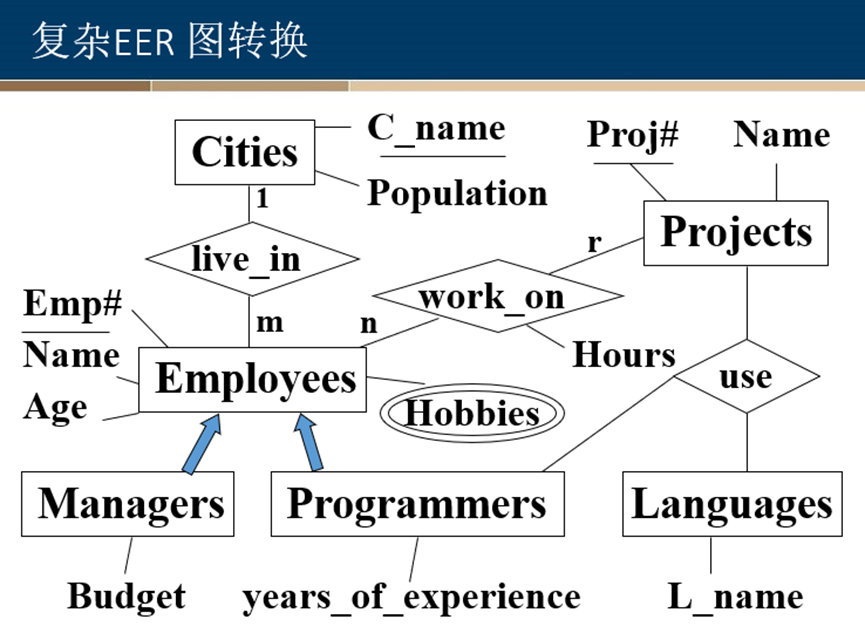
Use method 1:
Employees(Emp#, Name, Age, C_name)
Employee-Hobby(Emp#, Hobby)
Managers(Emp#, Budget)
Programmers(Emp#, Years_of_experience)
Cities(C_name, Population)
Projects(Proj#, Name)
Languages(L_name)
Work_on(Emp#, Proj#, Hours)
Use(Emp#, Proj#, L_name)
Use method 2:
Employees(Emp#, Name, Age, C_name)
Employee-Hobby(Emp#, Hobby)
Managers(Manager-Emp#, Name, Age, Budget, C_name)
Manager-Hobby(Manager-Emp#, Hobby)
Programmers(Programmer-Emp#, Name, Age, Years_of_experience, C_name)
Programmer-Hobby(Programmer-Emp#, Hobby)
Cities(C_name, Population)
Projects(Proj#, Name)
Languages(L_name)
Work_on(Emp#, Proj#, Hours)
Manager-Work_on(Manager-Emp#, Proj#, Hours)
Programmer-Work_on(Programmer-Emp#, Proj#, Hours)
Use(Programmer-Emp#, Proj#, L_name)
2、
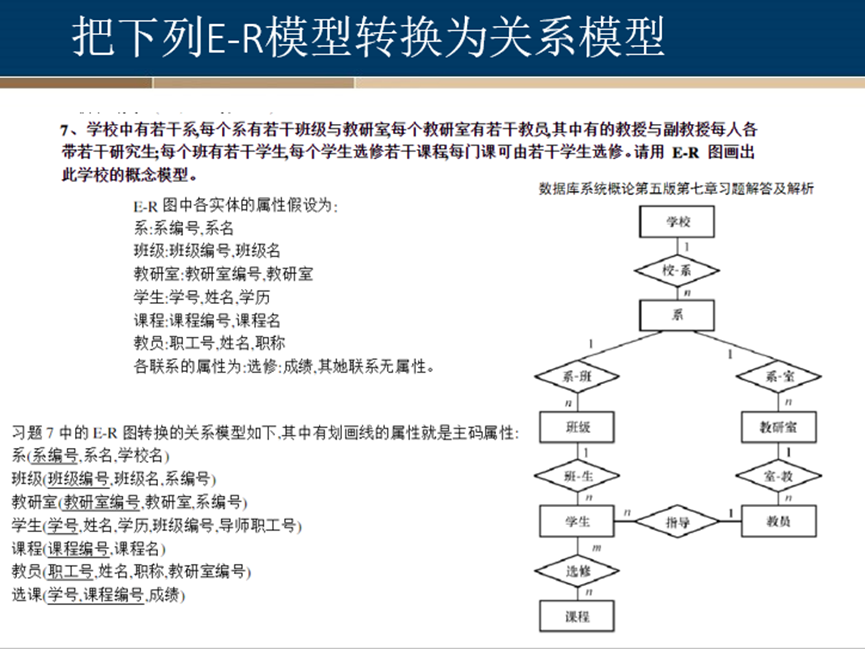
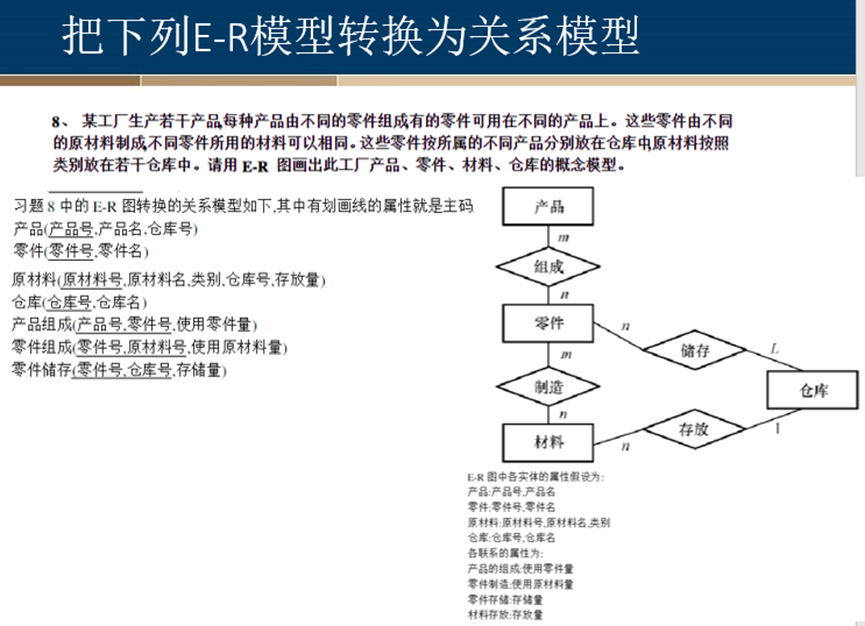
3、
并发控制
并发操作带来的数据不一致性
丢失修改(Lost Update)
不可重复读(Non-repeatable Read)
读“脏”数据(Dirty Read)



基本封锁类型
排它锁(Exclusive Locks,简记为X锁)
共享锁(Share Locks,简记为S锁)
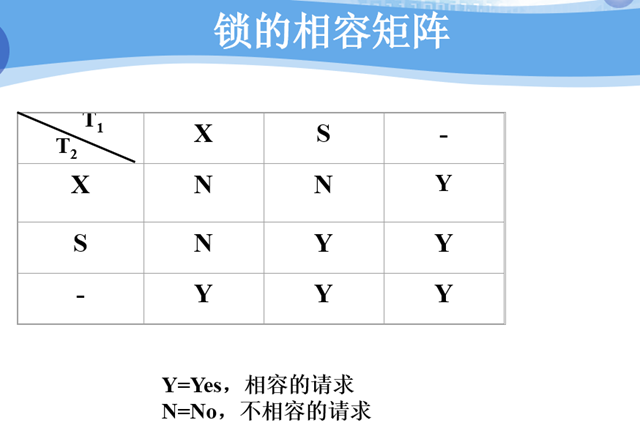
两段封锁协议(Two-Phase Locking,简称2PL)
两段封锁协议(Two-Phase Locking,简称2PL)是最常用的一种封锁协议,理论上证明使用两段封锁协议产生的是可串行化调度
活锁与死锁
活锁: 先来先服务
死锁:1、预防方法 2、一次封锁法 3、顺序封锁法
死锁的诊断与解除:1、超时法 2、等待图法
















 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











