







各位在学习时最好亲自手敲一遍代码,慎用CV大法。
编写一个简单爬虫
- 爬取网站:www.santostang.com
- 先准备一会儿会用到的包,已经安装的朋友可以跳过这一步
# JupyterNotebook
!pip install requests
!pip install bs4
在安装包过程中遇到困难的朋友可以看看这一篇教程:https://blog.csdn.net/sinat_23619409/article/details/79961836
下面进入正题
第一步 获取页面
- 目标功能:爬取首页HTML代码
在这里我们将要用到 requests.get() 函数,给大家介绍一个使用不熟悉的函数的技巧,可以通过JupyterNotebook查看函数文档
import requests
requests.get? #在函数后面打个问号,运行以后就会弹出函数文档

由此可知,requests.get()函数至少需要两个参数,网址和浏览器请求头。
关于浏览器请求头,可参考这两篇文章,有了他们,就可以把我们的爬虫伪装成各种浏览器:Python爬虫:常用的浏览器请求头User-Agent;时下流行的浏览器User-Agent大全
import requests #导入包,requests在网络爬虫中应用非常多
#定义link为目标网页地址
link = "http://www.santostang.com/"
#定义请求头的浏览器代理,把爬虫伪装成浏览器
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0"}
#请求网页
r = requests.get(link,headers=headers)
#输出获取的网页内容代码
print(r.text)
看看会输出什么吧?

这就是网页的HTML源码了
第二步 提取所需数据
- 在这里我们使用beautifulsoup解析数据(个人认为正则表达式也挺好用,大家可以去bilibili看看陈光老师的课程去了解一下)
import requests
from bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSoup包,在后边会有关于他的详细教程
#定义link为目标网页地址
link = "http://www.santostang.com/"
#定义请求头的浏览器代理,把爬虫伪装成浏览器
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0"}
#请求网页
r = requests.get(link,headers=headers)
#使用BeautifulSoup解析
soup = BeautifulSoup(r.text,"html.parser")
#找到第一篇文章的标题 h1 ,定位到class是“post-title”的 h1 元素,提取a和a里的字符串,再用strip()去掉空格
title = soup.find("h1",class_="post-title").a.text.strip()
#打印一下看看有没有成功提取标题
print(title)

- 这样我们就成功提取出了一个标题,但是我们如何在长代码中定位所需元素呢?
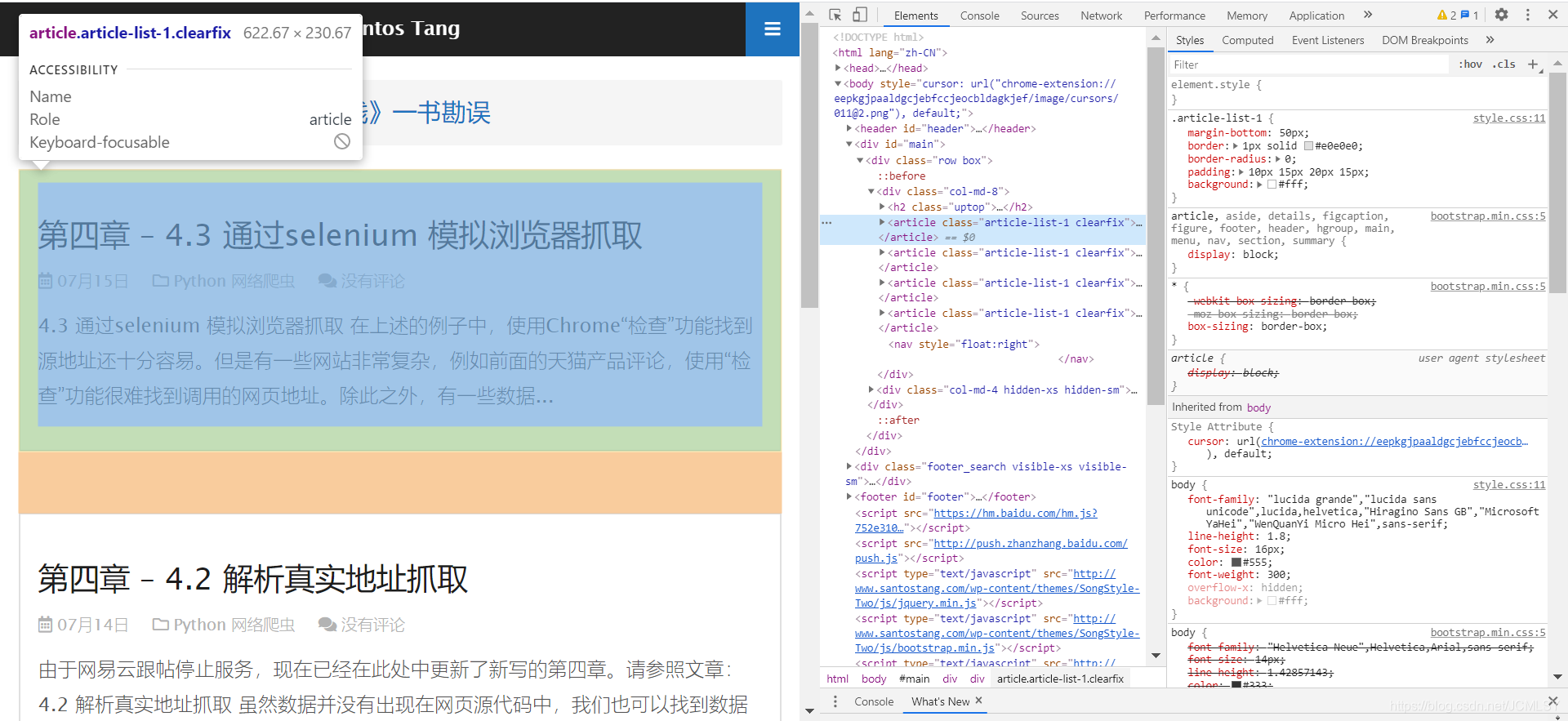
使用Chrome的好处就来了,我们可以使用他的“检查(审查元素)”功能
- 使用Chrome浏览器打开网页http://www.santostang.com,右键单击,点击“检查”,英文版的是Inspect
- 点击左上角的小箭头,然后再点击页面中想要的数据,在Element中就会出现相应code的位置
- 找到标蓝色的地方,看看数据的相关参数,就可以拿来使用了。(此处需要大家掌握一丢丢HTML的简单知识,起码要知道各种参数的意义,实在不行,就问搜索引擎)
第三步 存储数据
这一步的实现比较简单,只要用两行代码写入文件就可以了。
- 首先,在python文件所在的目录新建一个txt文件。如果你跟我一样使用的是JupyterNotebook,可以直接去Notebook主页新建一个txt。

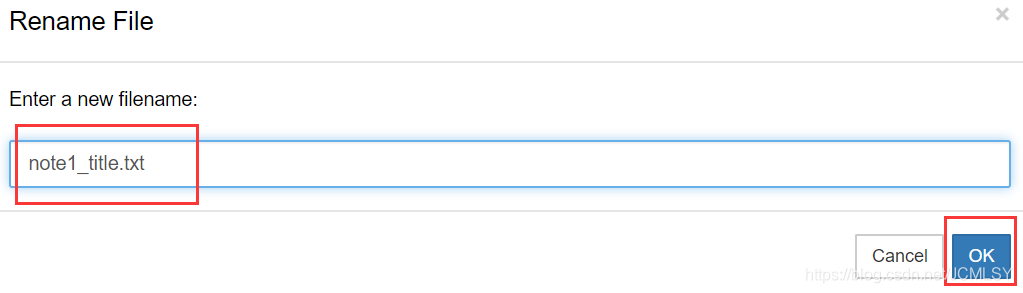
记得更改文件名
import requests
from bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSoup包,在后边会有关于他的详细教程
#定义link为目标网页地址
link = "http://www.santostang.com/"
#定义请求头的浏览器代理,把爬虫伪装成浏览器
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0"}
#请求网页
r = requests.get(link,headers=headers)
#使用BeautifulSoup解析
soup = BeautifulSoup(r.text,"html.parser")
#找到第一篇文章的标题 h1 ,定位到class是“post-title”的 h1 元素,提取a和a里的字符串,再用strip()去掉空格
title = soup.find("h1",class_="post-title").a.text.strip()
#打开刚刚新建的txt文件,用f.write写入文件
with open("note1_title.txt","a+") as f:
f.write(title)
打开文件看看有没有写进去吧
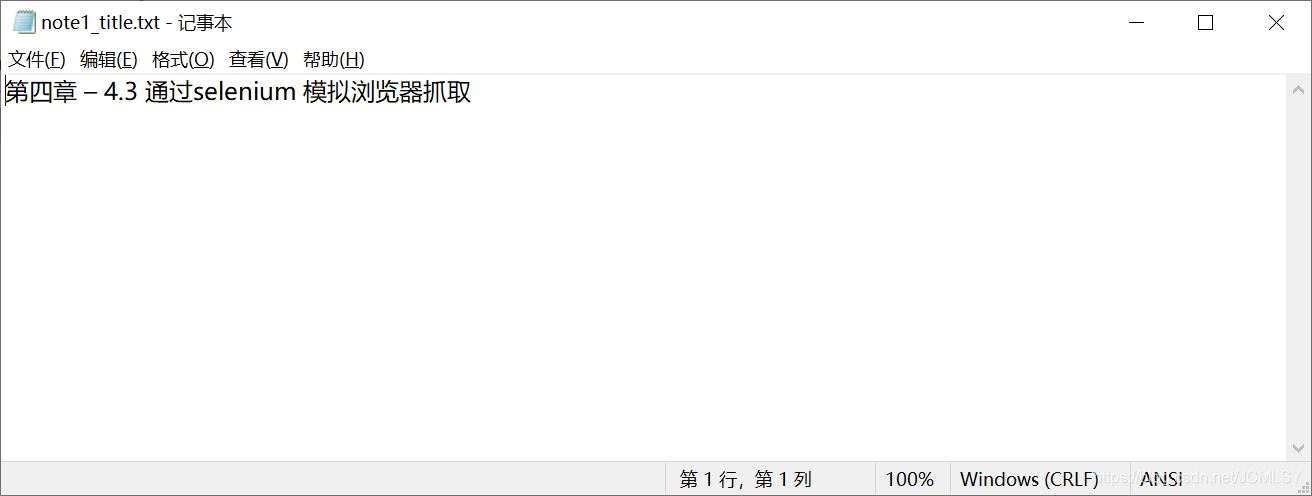
- 成功啦,这就是我们大家一起学习的第一个爬虫了。
- 这一篇文章主要是带大家实现爬虫的功能,并没有很详细的讲解各种库和函数的使用。在下一篇学习笔记中,我们将学习如何用requests抓取静态网页。
- 如果你有任何疑问、建议,欢迎评论或私聊















 5764
5764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









