






文章目录
1 mxnet转caffe
参考这篇文章:https://blog.csdn.net/u012101561/article/details/89329130
github工程建议使用:https://github.com/Laulian/MxNet2Caffe-mobilefacenet
此工程有包含上面文章提到的一些修改
如果你使用的是python3,工程里面一些python2语法需要修改,如
1.1
mxnet2caffe过程,报错如下
TypeError: unsupported operand type(s) for +: 'dict_keys' and 'dict_keys'
这是由于python3不支持dict_keys,需要改为list类型
all_keys = list(arg_params.keys()) + list(aux_params.keys())
1.2
报错
AttributeError: 'dict' object has no attribute 'has_key'
修改
比如:if dict.has_key(word): 改为:if word in dict:'
1.3
json2prototxt过程,由于跳过了对_minus_scalar和_mul_scalar这两个op的处理,所以最后生成出来的.prototxt文件的conv_1_conv2d层,需要把bottom由_mulscalar0改为data。不然后面mxnet2caffe.py运行会报错

2 caffe中间层结果输出
caffe中间层结果输出比较简单,如下
out = mobilefacenet.forward(end='fc1_scale')
end=后面加模型的节点
3 mxnet中间层结果输出
mxnet的比较麻烦,参考文章:https://blog.csdn.net/disen10/article/details/79376631
我的代码:
sym, arg_params, aux_params = mx.model.load_checkpoint('./model/model',0)#载入模型
model = mx.mod.Module(symbol=sym, context=mx.cpu())
########################################################################
args = sym.get_internals().list_outputs() #获得所有中间输出
print('args=',args)
internals = model.symbol.get_internals()
lay22 = internals['_mulscalar0_output']
group = mx.symbol.Group([lay22, sym]) #把需要输出的结果按group方式组合起来,这样就可以得到中间层的输出
#########################################################################
mod = mx.mod.Module(symbol=group,context=mx.cpu()) #创建Module
mod.bind(for_training=False,data_shapes=[('data',(1,3,112,112))]) #绑定,此代码为预测代码,所以training参数设为False
mod.set_params(arg_params,aux_params)
img1_path = "./aligned_face.jpg"
array1 = single_input(img1_path)
Batch = namedtuple("batch", ['data'])
mod.forward(Batch([array1]))
其中mx.symbol.Group([lay22, sym]),其中lay22就是我们要读的中间节点,sym是原来整个模型的输出,在我这个模型也就是fc1_output,这就把两个节点输出结果都输出,foward之后

通过如下读取结果:
for i in range(len(mod.output_names)):
print('output name=',mod.output_names[i])
print(np.squeeze((mod.get_outputs()[i].asnumpy())))
4 两个模型结果差异分析
通过上述读取中间结果输出,我发现mxnet和caffe的数据输入层就有差异
1.归一化动作
要注意第一点,mxnet的归一化动作是放在模型里面_minusscalar0,_mulscalar0两层做的,而caffe没有这两层,所以caffe的数据输出data时候代码里面就需要做归一化动作

2.就算我caffe 图片输入前做了归一化动作,可是caffe data层输出对比mxnet的_mulscalar0_output层输出还是不一样。
mxnet读取图片用的方法:
img = cv2.imread(path)
# mxnet三通道输入是严格的RGB格式,而cv2.imread的默认是BGR格式,因此需要做一个转换
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (112, 112))
# 重塑数组的形态,从(图片高度, 图片宽度, 3)重塑为(3, 图片高度, 图片宽度)
img = np.swapaxes(img, 0, 2)
img = np.swapaxes(img, 1, 2)
# 添加一个第四维度并构建NDArray
img = img[np.newaxis, :]
array = mx.nd.array(img)
Batch = namedtuple("batch", ['data'])
mod.forward(Batch([array]))
caffe读取图片的方式
image_file="./aligned_face.jpg"
transformer = caffe.io.Transformer({'data': mobilefacenet.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1)) #改变维度的顺序,由原始图片(112,112,3)变为(3,112,112)
#transformer.set_raw_scale('data', 255) #caffe.io.load_image将图片存储为[0, 1],设置缩放到[0, 255]
transformer.set_channel_swap('data', (2, 1, 0)) #RGB设置为BGR
#transformer.set_mean('data',127.5)
im = caffe.io.load_image(image_file)
mobilefacenet.blobs['data'].reshape(1, 3, 112, 112)
mobilefacenet.blobs['data'].data[...] = transformer.preprocess('data', (im * 255 - 127.5) * 0.0078125)
一个用的是cv.imread,一个用的是caffe.io.load_image,网上说后者只是前者缩放到0~1,我做了如下实验,可以看出c不全是0,说明a*255不完全等于b,为了模型输入一致性,所以两边改为都采用cv.imread的方式

最后模型某些层输出对比如下,还是存在不小的差异,这些差异需要继续分析

5 分析第一层batchnorm差异原因
由于第一层batchnorm输出结果就存在小数点后第4位的差异,所以需要分析这一层差异的原因。
首先要了解batchnorm层的作用:https://blog.csdn.net/zhuiqiuk/article/details/88089500
Caffe中BatchNorm层的计算


所以要分析batchnorm层的差异,就要分析它的参数是否一致。
5.1 mxnet读取中间层参数
mod.forward(Batch([array1]))
#查看中间层参数
keys1 = mod.get_params()[0].keys() # 列出所有权重名称
keys2 = mod.get_params()[1].keys() # 列出所有权重名称
key='conv_1_batchnorm_beta'
if key in keys1:
conv_w = mod.get_params()[0][key] # 获取想要查看的权重信息,如conv_weight
print(key,' _arg_params=',conv_w.asnumpy()) # 查看具体数值
if key in keys2:
conv_w = mod.get_params()[1][key] # 获取想要查看的权重信息,如conv_weight
print(key,' _aux_params=',conv_w.asnumpy()) # 查看具体数值
- 读取参数需要执行forward()之后
- mxnet把能读的blob分了两组,arg/aux,所以需要读的key需要在两组里面找
下图左边是mxnet读到的参数。

5.2 caffe读取中间层参数
mobilefacenet = caffe.Net(pretrained,model_file,caffe.TEST)
#中间层参数
for param_name in mobilefacenet.params.keys():
if param_name=='conv_1_batchnorm':
for i in range(len(mobilefacenet.params[param_name])):
if i==0:
print(param_name,'weight=',mobilefacenet.params[param_name][i].data.shape,)
if i==1:
print(param_name,'bias=',mobilefacenet.params[param_name][i].data.shape,)
if i==2:
print(param_name,'other=',mobilefacenet.params[param_name][i].data.shape,)
print(mobilefacenet.params[param_name][i].data)
- caffe的参数不同层数量会不一样,有些有3个参数,所以代码做了一个循环打印
- 能获取参数的blob都在mobilefacenet.params.keys()
下图右边是caffe读到的参数。
综上图,batchnorm的下面几个参数都是一样的
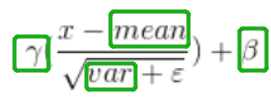
就剩下ε,也就是eps了
6 差异原因
mxnet的batchnorm层
{
"op": "BatchNorm",
"name": "conv_1_batchnorm",
"attrs": {
"fix_gamma": "False",
"momentum": "0.9"
},
"inputs": [[4, 0, 0], [5, 0, 0], [6, 0, 0], [7, 0, 1], [8, 0, 1]]
},
caffe的batchnorm层
layer {
bottom: "conv_1_conv2d"
top: "conv_1_batchnorm"
name: "conv_1_batchnorm"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
moving_average_fraction: 0.9
eps: 2e-05
}
}
可以看到,caffe的eps=2e-05,mxnet没有定义,查看mxnet文档:https://mxnet.apache.org/api/python/docs/api/symbol/contrib/index.html

我们把mxnet转caffe的代码改一下eps默认值,改成0.0010000000474974513

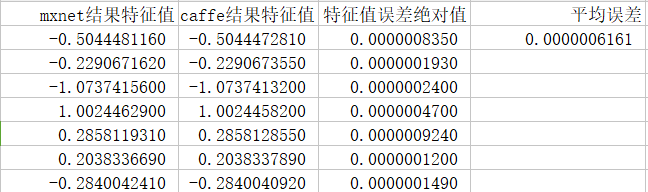
最后模型之间的误差减小到0.0000006161
















 5435
5435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









