







本节重点:
1.学会线程同步。
2. 学会使用互斥量,条件变量,posix信号量,以及读写锁。
3. 理解基于读写锁的读者写者问题。
Linux线程互斥
相关概念:
临界资源:多线程执行流共享的资源就叫做临界资源
临界区:每个线程内部,访问临界资源的代码,就叫做临界区
互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
原子性(后面讨论如何实现):不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完 成
大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。 但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。 多个线程并发的操作共享变量,会带来一些问题。
#include<iostream>
#include<pthread.h>
#include<vector>
#include<string>
#include<unistd.h>
using namespace std;
int ticket = 1000;
class threadDate
{
public:
threadDate(const string& name)
:_name(name)
{}
string _name;
};
void* getTicket(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(ticket > 0)
{
usleep(100);
--ticket;
cout << td->_name << " : " << ticket << endl;
}
delete td;
return nullptr;
}
int main()
{
vector<pthread_t> tid(5);
int cnt = 0;
for(auto& e : tid)
{
threadDate* td = new threadDate("thread ");
++cnt;
td->_name += to_string(cnt);
int n = pthread_create(&e, nullptr, getTicket, td);
}
//等待线程
for(auto& e : tid)
{
pthread_join(e, nullptr);
}
return 0;
}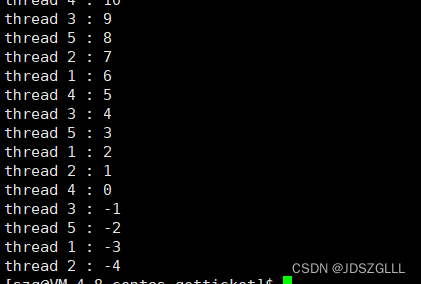
出现了比较奇怪的现象,票居然抢到了复数, usleep是为了模拟++过程被打断,由于++时间很短,不好出结果,所以用休眠延长这个过程。
上述结果出现的原因有 :
if 语句判断条件为真以后,代码可以并发的切换到其他线程
usleep 这个模拟漫长业务的过程,在这个漫长的业务过程中,可能有很多个线程会进入该代码段
--ticket 操作本身就不是一个原子操作

-- 操作并不是原子操作,而是对应三条汇编指令:
load :将共享变量ticket从内存加载到寄存器中
update : 更新寄存器里面的值,执行-1操作
store :将新值,从寄存器写回共享变量ticket的内存地址
要解决以上问题,需要做到三点:
代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临 界区。
如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
要做到这三点,本质上就是需要一把锁。Linux上提供的这把锁叫互斥量。
互斥量的初始化和销毁
初始化和销毁互斥量有两种方法:
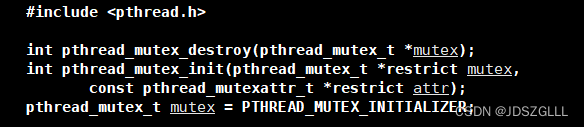
方法1,静态分配:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER方法2,动态分配:
int pthread_mutex_init(pthread_mutex_t *restrict mutex
, const pthread_mutexattr_t *restrict attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
互斥量加锁和解锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值:成功返回0,失败返回错误信号
抢票小程序的改进
#include<iostream>
#include<pthread.h>
#include<vector>
#include<string>
#include<unistd.h>
using namespace std;
int ticket = 1000;
class threadDate
{
public:
threadDate(const string& name, pthread_mutex_t* pmutex)
:_name(name)
,_pmutex(pmutex)
{}
string _name;
pthread_mutex_t* _pmutex;
};
void* getTicket(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(ticket > 0)
{
//lock
pthread_mutex_lock(td->_pmutex);
if(ticket > 0)
{
usleep(100);
--ticket;
cout << td->_name << " : " << ticket << endl;
}
//unlock
pthread_mutex_unlock(td->_pmutex);
}
delete td;
return nullptr;
}
int main()
{
vector<pthread_t> tid(5);
int cnt = 0;
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
for(auto& e : tid)
{
threadDate* td = new threadDate("thread ", &mutex);
++cnt;
td->_name += to_string(cnt);
int n = pthread_create(&e, nullptr, getTicket, td);
}
//等待线程
for(auto& e : tid)
{
pthread_join(e, nullptr);
}
//销毁锁
pthread_mutex_destroy(&mutex);
return 0;
}加锁解锁的原理解析
经过上面的例子,大家已经意识到单纯的 i++ 或者 ++i 都不是原子的,有可能会有数据一致性问题
为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单 元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的 总线周期也有先后,一 个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。
现在我们把lock和unlock的伪 代码改一下

总结:
锁本身就就是一个共享资源,但是加锁和解锁是原子的,所以数据是安全的。
谁持有锁,谁进入临界区,如果申请锁没成功会阻塞。
非阻塞申请锁:pthread_mutex_trylock.
一个线程进入临界区,其他线程绝对不在这个临界区内。
一个线程进入临界区,可以被切换,但仍然占有锁。
要保证临界区的粒度尽量小。
常见不可重入的情况
调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的
调用了标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构
可重入函数体内使用了静态的数据结构
加锁的函数都是不可重入的。
常见可重入的情况
不使用全局变量或静态变量
不使用用malloc或者new开辟出的空间
不调用不可重入函数
不返回静态或全局数据,所有数据都有函数的调用者提供
使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据
可重入函数一定是线程安全的,线程安全的不一定是可重入的,两者是不同的概念。
死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资 源而处于的一种永久等待状态。
死锁四个必要条件
互斥(锁的特点)
请求保持(加了锁之后,又申请新的锁)
不剥夺(一个执行流已获得的资源,在末使用完之前,不能强行剥夺)
循环等待条件(若干执行流之间形成一种头尾相接的循环等待资源的关系)
避免死锁
破坏死锁的四个必要条件
加锁顺序一致
避免锁未释放的场景
资源一次性分配(尽量在一个临界区之内把事都办了)
在实际工程中要尽量避免使用锁。
RAII方式封装一个锁
class mutexGuard
{
public:
mutexGuard(pthread_mutex_t* pmutex)
{
_pmutex = pmutex;
pthread_mutex_lock(_pmutex);
}
~mutexGuard()
{
pthread_mutex_unlock(_pmutex);
}
private:
pthread_mutex_t* _pmutex;
};
void* getTicket(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(ticket > 0)
{
{
mutexGuard mg = mutexGuard(td->_pmutex);
if(ticket > 0)
{
usleep(1000);
--ticket;
cout << td->_name << " : " << ticket << endl;
}
}
}
delete td;
return nullptr;
}竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解。
在抢票过程中我们即使加了锁,仍然会有一个进程竞争能力非常强,几乎所有票都是一个进程抢的,使得其他进程处于饥饿状态。
Linux线程同步(条件变量)
当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。这种情 况就需要用到条件变量。
同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问 题,叫做同步。
竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解。
生产者消费者模型
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而 通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者 要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队 列就是用来给生产者和消费者解耦的。
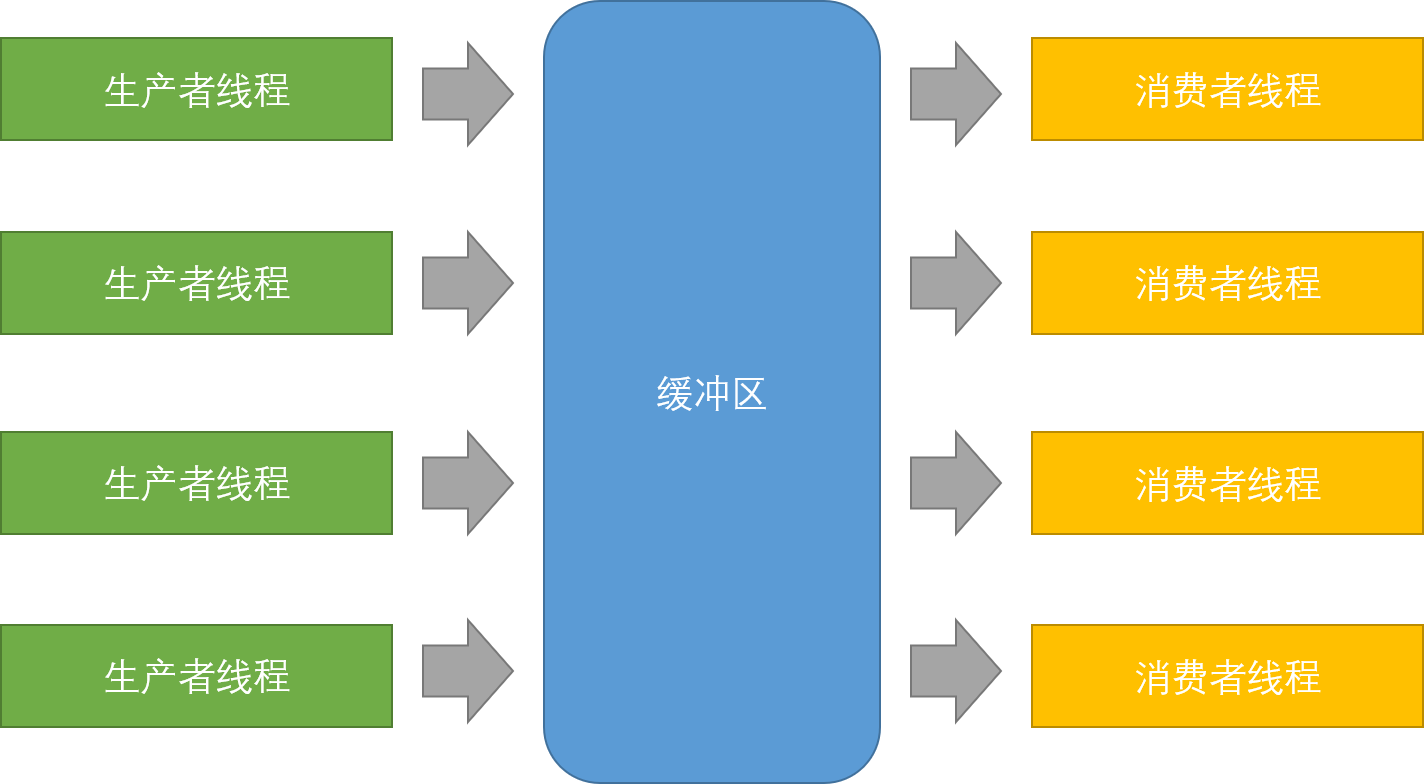
生产与消费的过程解耦。
函数调用是生产与消费的强耦合。
特点(“321”原则):
3种关系:生产者与生产者互斥、消费者和消费者互斥、生产者和消费者不一定互斥,但一定同步
2种角色:生产者与消费者
1个交易场所:缓冲区
条件变量初始化和销毁
方法1,静态分配:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;方法2,动态分配:
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);int pthread_cond_destroy(pthread_cond_t *cond)
等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
pthread_cond_timewait//在设定时间内阻塞等待
唤醒等待
int pthread_cond_broadcast(pthread_cond_t *cond);//在指定条件变量下,唤醒全部线程
int pthread_cond_signal(pthread_cond_t *cond);//唤醒一个线程

条件变量自带队列
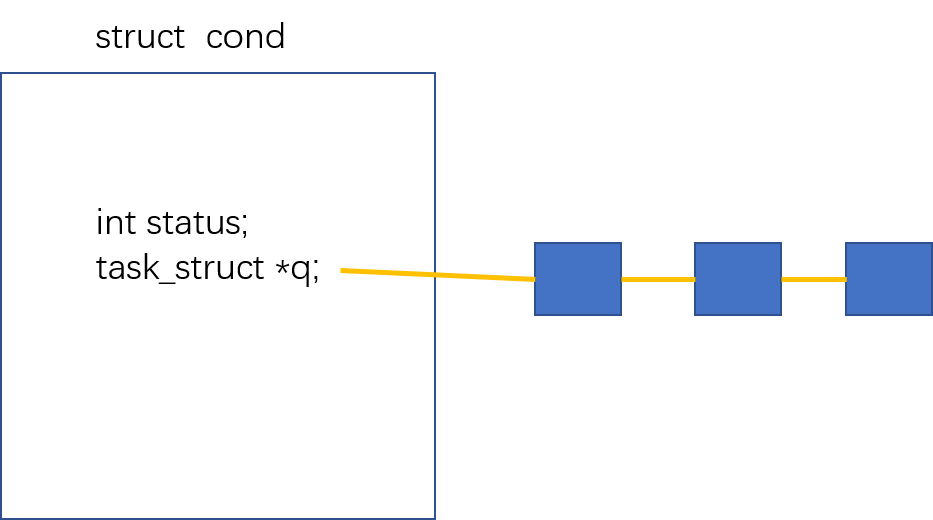
基于BlockingQueue(阻塞队列)的生产者消费者模型
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别 在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元 素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程 操作时会被阻塞)
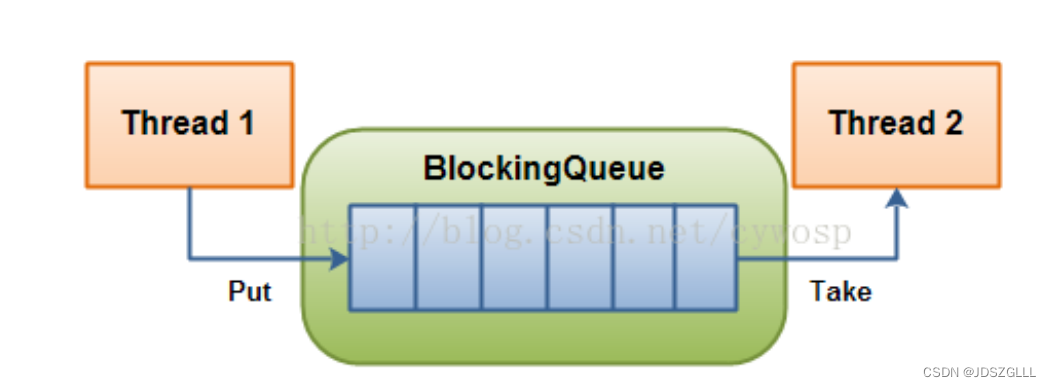
我们来实现一个加深难度的生产消费者模型的代码: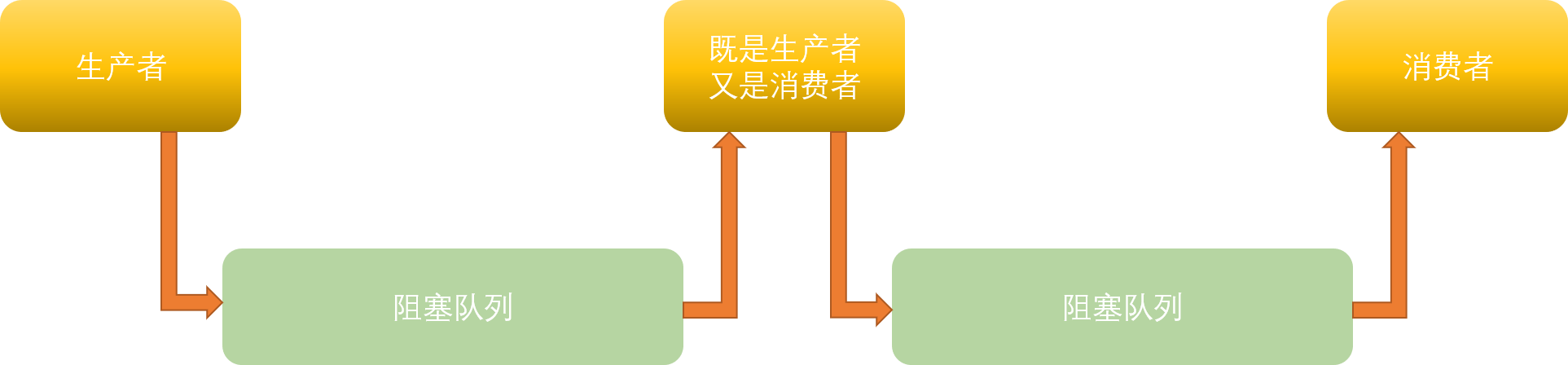
blockqueue.hpp
#include<iostream>
#include<queue>
#include<pthread.h>
#include<string>
using namespace std;
const size_t max_cap = 5;
template<class T>
class blockqueue
{
public:
blockqueue()
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_pcond, nullptr);
pthread_cond_init(&_ccond, nullptr);
}
void push(const T& t)
{
pthread_mutex_lock(&_mutex);
//如果队列满了,阻塞等待
while(max_cap == _q.size())
pthread_cond_wait(&_pcond, &_mutex);
_q.push(t);
//此时队列中必有数据,唤醒消费线程
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}
void pop(T* t)
{
pthread_mutex_lock(&_mutex);
//如果队列空了,阻塞等待
while(_q.empty())
pthread_cond_wait(&_ccond, &_mutex);
*t = _q.front();
_q.pop();
//此时队列中必有空位,唤醒生产线程
pthread_cond_signal(&_pcond);
pthread_mutex_unlock(&_mutex);
}
~blockqueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_pcond);
pthread_cond_destroy(&_ccond);
}
private:
pthread_mutex_t _mutex;
pthread_cond_t _pcond;
pthread_cond_t _ccond;
queue<T> _q;
};mian.cc
#include<iostream>
#include<vector>
#include<map>
#include<functional>
#include<unistd.h>
#include<time.h>
#include"blockqueue.hpp"
using namespace std;
char cal[] = "+-*/%";
//匹配符号和算法
map<char, function<int(int, int)>> match{
{'+', [](int a, int b){return a + b;}},
{'-', [](int a, int b){return a - b;}},
{'*', [](int a, int b){return a * b;}},
{'/', [](int a, int b){return a / b;}},
{'%', [](int a, int b){return a % b;}},
};
//给计算队列使用的数据包
class caltask
{
public:
caltask(int a = 0, int b = 0, char ch = '+')
:_a(a),_b(b),_ch(ch)
{}
int _a;
int _b;
char _ch;
};
//传递给线程的数据包
//c计算
//s保存
class threadDate
{
public:
threadDate(const string& name, blockqueue<caltask>* cq, blockqueue<string>* sq)
:_name(name)
,_cq(cq)
,_sq(sq)
{}
string _name;
blockqueue<caltask>* _cq;
blockqueue<string>* _sq;
};
void* productor_route(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(1)
{
int a = rand() % 10;
int b = rand() % 10;
char ch = cal[rand() % 5];
caltask tmp(a, b, ch);
cout << td->_name << " : " << a << " " << ch << " " << b << " = ? " << endl;
td->_cq->push(tmp);
sleep(1);
}
return nullptr;
}
void* consumer_route(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(1)
{
caltask tmp;
td->_cq->pop(&tmp);
char buffer[1024];
if((tmp._ch == '/' || tmp._ch == '%') && tmp._b == 0)
{
sprintf(buffer, "div or mod zero !! %d %c %d = %d\n", tmp._a, tmp._ch, tmp._b, -1);
}
else
{
sprintf(buffer, "%d %c %d = %d\n", tmp._a, tmp._ch, tmp._b, match[tmp._ch](tmp._a, tmp._b));
}
cout << td->_name << " : " << buffer;
td->_sq->push(buffer);
}
return nullptr;
}
void* saver_route(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(1)
{
string s;
td->_sq->pop(&s);
FILE *fp = fopen("./log.txt", "a+");
if(!fp)
{
std::cerr << "fopen error" << std::endl;
continue;
}
fputs(s.c_str(), fp);
fclose(fp);
}
return nullptr;
}
int main()
{
srand((unsigned long)time(nullptr) * 0x8298328947);
//创建线程
vector<pthread_t> productors(1);
vector<pthread_t> consumers(1);
vector<pthread_t> savers(1);
//创建阻塞队列
blockqueue<caltask>* cq = new blockqueue<caltask>();
blockqueue<string>* sq = new blockqueue<string>();
int cnt = 0;
for(auto& e : productors)
{
++cnt;
string name = "productor ";
name += to_string(cnt);
threadDate* td = new threadDate(name, cq, sq);
pthread_create(&e, nullptr, productor_route, td);
}
cnt = 0;
for(auto& e : consumers)
{
++cnt;
string name = "consumer ";
name += to_string(cnt);
threadDate* td = new threadDate(name, cq, sq);
pthread_create(&e, nullptr, consumer_route, td);
}
cnt = 0;
for(auto& e : savers)
{
++cnt;
string name = "saver ";
name += to_string(cnt);
threadDate* td = new threadDate(name, cq, sq);
pthread_create(&e, nullptr, saver_route, td);
}
for(auto& e : productors)
{
pthread_join(e, nullptr);
}
for(auto& e : consumers)
{
pthread_join(e, nullptr);
}
for(auto& e : savers)
{
pthread_join(e, nullptr);
}
return 0;
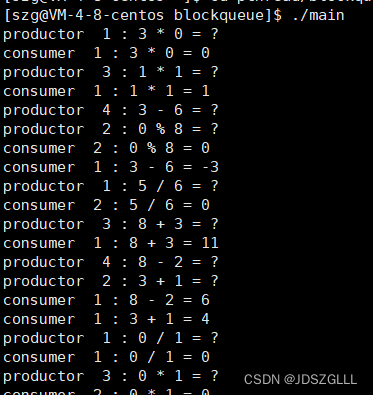
}

POSIX信号量
之前的生产消费只能先加锁,再检测,再操作,再解锁。
对资源的整体加锁,默认了对资源的整体使用,而一份公共资源允许访问不同区域。
而信号量就是用于提前得知资源状况,本质是计数器,衡量资源数目。
在使用资源之前先申请信号量,在访问临界资源之前提前知道使用情况。
所有线程都要申请信号量,信号量必须是公共资源。
信号量的操作是原子的(PV原语)
申请资源 sem_wait -- //P
释放资源 sem_post ++ //V
信号量使用接口

接下来使用信号量实现一个基于环形队列的生产者消费者模型:
ringqueue.hpp
#include<iostream>
#include<queue>
#include<pthread.h>
#include<string>
#include<semaphore.h>
using namespace std;
const int maxcap = 10;
template<class T>
class ringqueue
{
public:
ringqueue(int cap = maxcap)
:_cap(cap)
,_task(_cap)
{
pthread_mutex_init(&_pmutex, nullptr);
pthread_mutex_init(&_cmutex, nullptr);
sem_init(&_spacesem,0, _cap);
sem_init(&_datesem,0, 0);
}
void push(const T& t)
{
sem_wait(&_spacesem);
pthread_mutex_lock(&_pmutex);
_task[_p_index++] = t;
_p_index %= _cap;
pthread_mutex_unlock(&_pmutex);
sem_post(&_datesem);
}
void pop(T& t)
{
sem_wait(&_datesem);
pthread_mutex_lock(&_cmutex);
t = _task[_c_index++];
_c_index %= _cap;
pthread_mutex_unlock(&_cmutex);
sem_post(&_spacesem);
}
~ringqueue()
{
pthread_mutex_destroy(&_pmutex);
pthread_mutex_destroy(&_cmutex);
sem_destroy(&_spacesem);
sem_destroy(&_datesem);
}
private:
int _cap;
vector<T> _task;
pthread_mutex_t _pmutex;
pthread_mutex_t _cmutex;
sem_t _spacesem;
sem_t _datesem;
int _p_index = 0;
int _c_index = 0;
};mian.cc
#include<iostream>
#include<vector>
#include<map>
#include<functional>
#include<unistd.h>
#include<time.h>
#include"ringqueue.hpp"
using namespace std;
char cal[] = "+-*/%";
//匹配符号和算法
map<char, function<int(int, int)>> match{
{'+', [](int a, int b){return a + b;}},
{'-', [](int a, int b){return a - b;}},
{'*', [](int a, int b){return a * b;}},
{'/', [](int a, int b){return a / b;}},
{'%', [](int a, int b){return a % b;}},
};
//给计算队列使用的数据包
class caltask
{
public:
caltask(int a = 0, int b = 0, char ch = '+')
:_a(a),_b(b),_ch(ch)
{}
int _a;
int _b;
char _ch;
};
//传递给线程的数据包
//c计算
//s保存
class threadDate
{
public:
threadDate(const string &name, ringqueue<caltask> *rq)
: _name(name), _rq(rq)
{}
string _name;
ringqueue<caltask>* _rq;
};
void* productor_route(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(1)
{
int a = rand() % 10;
int b = rand() % 10;
char ch = cal[rand() % 5];
caltask tmp(a, b, ch);
cout << td->_name << " : " << a << " " << ch << " " << b << " = ? " << endl;
td->_rq->push(tmp);
sleep(1);
}
return nullptr;
}
void* consumer_route(void* args)
{
threadDate* td = static_cast<threadDate*>(args);
while(1)
{
caltask tmp;
td->_rq->pop(tmp);
char buffer[1024];
if((tmp._ch == '/' || tmp._ch == '%') && tmp._b == 0)
{
sprintf(buffer, "div or mod zero !! %d %c %d = %d\n", tmp._a, tmp._ch, tmp._b, -1);
}
else
{
sprintf(buffer, "%d %c %d = %d\n", tmp._a, tmp._ch, tmp._b, match[tmp._ch](tmp._a, tmp._b));
}
cout << td->_name << " : " << buffer;
}
return nullptr;
}
int main()
{
srand((unsigned long)time(nullptr) * 0x8298328947);
//创建线程
vector<pthread_t> productors(4);
vector<pthread_t> consumers(2);
//创建环形队列
ringqueue<caltask>* rq = new ringqueue<caltask>();
int cnt = 0;
for(auto& e : productors)
{
++cnt;
string name = "productor ";
name += to_string(cnt);
threadDate* td = new threadDate(name, rq);
pthread_create(&e, nullptr, productor_route, td);
}
cnt = 0;
for(auto& e : consumers)
{
++cnt;
string name = "consumer ";
name += to_string(cnt);
threadDate* td = new threadDate(name, rq);
pthread_create(&e, nullptr, consumer_route, td);
}
for(auto& e : productors)
{
pthread_join(e, nullptr);
}
for(auto& e : consumers)
{
pthread_join(e, nullptr);
}
return 0;
}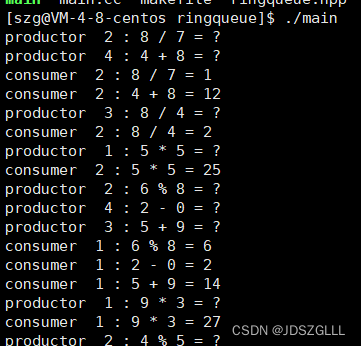
在环形队列中,大部分情况可以并发执行,只有空或者满时互斥和同步。
对于生产者,空间资源定义一个信号量。
对于消费者,数据资源定义一个信号量。
环形队列空或者满时,阻塞消费或者生产线程。
生产者中只能一个进临界区(生产者互斥),消费者中只有一个能进临界区(消费者互斥)。
线程池
线程池类似于生产者消费者:
代码如下:
MutexGuard.hpp
#pragma once
#include<pthread.h>
class MutexGuard
{
public:
MutexGuard(pthread_mutex_t* pmutex)
:_pmutex(pmutex)
{
pthread_mutex_lock(_pmutex);
}
~MutexGuard()
{
pthread_mutex_unlock(_pmutex);
}
private:
pthread_mutex_t* _pmutex;
};
mythread.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <cassert>
#include <functional>
#include <pthread.h>
class Thread;
//context传递对象的地址,帮助静态成员函数可以使用类内成员变量
class context
{
public:
context(Thread* t = nullptr, void* args = nullptr)
:_this(t)
,_args(args)
{}
Thread* _this;
void* _args;
};
class Thread
{
public:
Thread(const std::function<void*(void*)>& f, void* args = nullptr, const std::string& name = "")
:_func(f)
,_args(args)
,_name(name)
{
++_num;
if(_name.size() == 0)
{
_name += "thread ";
_name += std::to_string(_num);
}
//创建上下文结构体
context* pcon = new context(this, _args);
int n = pthread_create(&_tid, nullptr, route_start, pcon);
assert(0 == n);
(void)n;
}
static void* route_start(void* pcon)
{
context* cont = static_cast<context*>(pcon);
void* ret = cont->_this->run(cont->_args);
delete cont;
return ret;
}
void* run(void* args)
{
return _func(args);
}
void join()
{
int n = pthread_join(_tid, nullptr);
assert(n == 0);
(void)n;
}
std::string name()
{
return _name;
}
~Thread()
{
--_num;
}
private:
pthread_t _tid;
std::string _name;
void* _args;
std::function<void*(void*)> _func;
static int _num;
};
int Thread::_num = 0;mythreadpool.hpp
#pragma once
#include<vector>
#include<queue>
#include"mythread.hpp"
#include"MutexGuard.hpp"
const int maxnum = 5;
template<class T>
class threadpool;
//上下文
template<class T>
class condate
{
public:
condate(T* t, int num)
:_this(t), _num(num)
{}
T* _this;
int _num;
};
template<class T>
class threadpool
{
private:
static void* task_handler(void* args)
{
condate<threadpool<T>>* pcondate = static_cast<condate<threadpool<T>>* >(args);
threadpool<T>* tp = pcondate->_this;
while(true)
{
T t;
tp->pop(t);
std::cout << tp->_threads[pcondate->_num]->name() << " : ";
t();
}
delete pcondate;
}
public:
threadpool(int num = maxnum)
:_num(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
for(int i = 0; i < _num; ++i)
{
condate<threadpool<T>>* ct = new condate<threadpool<T>>(this, i);
_threads.push_back(new Thread(task_handler, ct));
}
}
void pop(T& t)
{
MutexGuard mg(&_mutex);
while(_task.empty())
pthread_cond_wait(&_cond, &_mutex);
t = _task.front();
_task.pop();
}
void push(const T& t)
{
MutexGuard mg(&_mutex);
_task.push(t);
pthread_cond_signal(&_cond);
}
~threadpool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
for(auto& t : _threads)
{
delete t;
}
}
private:
int _num;
std::vector<Thread*> _threads;
std::queue<T> _task;
pthread_mutex_t _mutex;
pthread_cond_t _cond;
};main.cc
#include<map>
#include<functional>
#include<unistd.h>
#include<time.h>
#include"mythreadpool.hpp"
using namespace std;
char cal[] = "+-*/%";
//匹配符号和算法
map<char, function<int(int, int)>> match{
{'+', [](int a, int b){return a + b;}},
{'-', [](int a, int b){return a - b;}},
{'*', [](int a, int b){return a * b;}},
{'/', [](int a, int b){return a / b;}},
{'%', [](int a, int b){return a % b;}},
};
//给计算队列使用的数据包
class caltask
{
public:
caltask(int a = 0, int b = 0, char ch = '+')
:_a(a),_b(b),_ch(ch)
{}
void operator()()
{
char buffer[1024];
if((_ch == '%' || _ch == '/') && 0 == _b)
{
sprintf(buffer, "div or mod zero !! %d %c %d = %d\n", _a, _ch, _b, -1);
}
else
{
sprintf(buffer, "%d %c %d = %d\n", _a, _ch, _b, match[_ch](_a, _b));
}
cout << buffer << endl;
}
int _a;
int _b;
char _ch;
};
int main()
{
srand((unsigned long)time(nullptr) * 0x8298328947);
threadpool<caltask>* td = new threadpool<caltask>();
while(true)
{
sleep(1);
int a = rand() % 10;
int b = rand() % 10;
char ch = cal[rand() % 5];
caltask tmp(a, b, ch);
td->push(tmp);
}
return 0;
}
单例模式

懒汉模式版的线程池代码
只要修改mythreadpool.hpp文件中的内容即可:
#pragma once
#include<vector>
#include<queue>
#include<mutex>
#include"mythread.hpp"
#include"MutexGuard.hpp"
const int maxnum = 5;
template<class T>
class threadpool;
//上下文
template<class T>
class condate
{
public:
condate(T* t, int num)
:_this(t), _num(num)
{}
T* _this;
int _num;
};
template<class T>
class threadpool
{
private:
static void* task_handler(void* args)
{
condate<threadpool<T>>* pcondate = static_cast<condate<threadpool<T>>* >(args);
threadpool<T>* tp = pcondate->_this;
while(true)
{
T t;
tp->pop(t);
std::cout << tp->_threads[pcondate->_num]->name() << " : ";
t();
}
delete pcondate;
}
threadpool(int num = maxnum)
:_num(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
for(int i = 0; i < _num; ++i)
{
condate<threadpool<T>>* ct = new condate<threadpool<T>>(this, i);
_threads.push_back(new Thread(task_handler, ct));
}
}
public:
void pop(T& t)
{
MutexGuard mg(&_mutex);
while(_task.empty())
pthread_cond_wait(&_cond, &_mutex);
t = _task.front();
_task.pop();
}
void push(const T& t)
{
MutexGuard mg(&_mutex);
_task.push(t);
pthread_cond_signal(&_cond);
}
~threadpool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
for(auto& t : _threads)
{
delete t;
}
}
static threadpool<T>* getinstance()
{
if(nullptr == _singleton)
{
_singletonlock.lock();
if(nullptr == _singleton)
{
_singleton = new threadpool();
}
_singletonlock.unlock();
}
return _singleton;
}
private:
int _num;
std::vector<Thread*> _threads;
std::queue<T> _task;
pthread_mutex_t _mutex;
pthread_cond_t _cond;
static std::mutex _singletonlock;
static threadpool<T>* _singleton;
};
template<class T>
std::mutex threadpool<T>::_singletonlock;
template<class T>
threadpool<T>* threadpool<T>::_singleton = nullptr;改变main中的调用方式:
int main()
{
srand((unsigned long)time(nullptr) * 0x8298328947);
while(true)
{
sleep(1);
int a = rand() % 10;
int b = rand() % 10;
char ch = cal[rand() % 5];
caltask tmp(a, b, ch);
threadpool<caltask>::getinstance()->push(tmp);
}
return 0;
}
运行结果与普通线程池相同。
点赞加关注,收藏不迷路!!!
















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











