






目录
目录
前言
本赛题由阿里天池官方举办,数据集我无法直接提供,如果感兴趣可以前往下面链接报名参赛:【教学赛】金融数据分析赛题2:保险反欺诈预测_学习赛_天池大赛-阿里云天池的排行榜
一、赛题简介
1.1、简介
本次教学赛是陈博士发起的数据分析系列赛事第2场 —— 保险反欺诈预测

赛题以保险风控为背景,保险是重要的金融体系,对社会发展,民生保障起到重要作用。保险欺诈近些年层出不穷,在某些险种上保险欺诈的金额已经占到了理赔金额的20%甚至更多。对保险欺诈的识别成为保险行业中的关键应用场景。
1.2、背景
赛题以保险风控为背景,保险是重要的金融体系,对社会发展,民生保障起到重要作用。保险欺诈近些年层出不穷,在某些险种上保险欺诈的金额已经占到了理赔金额的20%甚至更多。对保险欺诈的识别成为保险行业中的关键应用场景。
1.3、信息特征
参赛者将使用提供的车险数据集来开发模型,这些数据涵盖了客户的基本信息、保险条款、事故详情等。数据集包括以下主要字段:
个人信息:如年龄、性别、职业、学历等。
保险详情:如保险编号、保费、扣除额、保险责任上限等。
事故信息:如出险日期、出险类型、碰撞类型、事故严重程度等。
索赔信息:如总索赔金额、伤害索赔、财产索赔、车辆索赔等。
1.4、参赛报名

二、赛题任务
数据集提供了之前客户索赔的车险数据,希望你能开发模型帮助公司预测哪些索赔是欺诈行为
To DO:预测用户的车险是否为欺诈行为
| 字段 | 说明 |
|---|---|
| policy_id | 保险编号 |
| age | 年龄 |
| customer_months | 成为客户的时长,以月为单位 |
| policy_bind_date | 保险绑定日期 |
| policy_state | 上保险所在地区 |
| policy_csl | 组合单一限制Combined Single Limit |
| policy_deductable | 保险扣除额 |
| policy_annual_premium | 每年的保费 |
| umbrella_limit | 保险责任上限 |
| insured_zip | 被保人邮编 |
| insured_sex | 被保人姓名:FEMALE或者MALE |
| insured_education_level | 被保人学历 |
| insured_occupation | 被保人职业 |
| insured_hobbies | 被保人兴趣爱好 |
| insured_relationship | 被保人关系 |
| capital-gains | 资本收益 |
| capital-loss | 资本损失 |
| incident_date | 出险日期 |
| incident_type | 出险类型 |
| collision_type | 碰撞类型 |
| incident_severity | 事故严重程度 |
| authorities_contacted | 联系了当地的哪个机构 |
| incident_state | 出事所在的省份,已脱敏 |
| incident_city | 出事所在的城市,已脱敏 |
| incident_hour_of_the_day | 出事所在的小时(一天24小时的哪个时间) |
| number_of_vehicles_involved | 涉及的车辆数 |
| property_damage | 是否有财产损失 |
| bodily_injuries | 身体伤害 |
| witnesses | 目击证人 |
| police_report_available | 是否有警察记录的报告 |
| total_claim_amount | 整体索赔金额 |
| injury_claim | 伤害索赔金额 |
| property_claim | 财产索赔金额 |
| vehicle_claim | 汽车索赔金额 |
| auto_make | 汽车品牌,比如Audi, BMW, Toyota, Volkswagen |
| auto_model | 汽车型号,比如A3,X5,Camry,Passat等 |
| auto_year | 汽车购买的年份 |
| fraud | 是否欺诈,1或者0 |

2.1、评价标准
模型的性能将通过AUC(ROC曲线下的面积)来评估。AUC越高,模型区分正负类(即欺诈与非欺诈)的能力越强。
2.2、操作步骤
- 参赛者需要在阿里云天池平台注册并报名参赛。
- 参赛者可以通过“Fork”功能复制赛题提供的参考代码到自己的实验室进行编辑和测试。
- 参赛者需要处理和分析数据,建立预测模型,并使用提供的训练集和测试集进行模型训练和评估。
- 最终,参赛者需要将预测结果按照提交格式保存并提交以参与评分。

三、项目开展
3.1、打印数据集中的缺失值数量
代码打印训练集和测试集中各列的缺失值数量。这有助于了解数据的完整性,并在后续步骤中决定如何处理这些缺失值。
# 可视化缺失值数量
plt.figure(figsize=(12, 6))
# 训练集缺失值
plt.subplot(1, 2, 1)
missing_values_train[missing_values_train > 0].sort_values(ascending=False).plot(kind='bar')
plt.title('Missing Values in Training Data')
plt.xlabel('Columns')
plt.ylabel('Number of Missing Values')
# 测试集缺失值
plt.subplot(1, 2, 2)
missing_values_test[missing_values_test > 0].sort_values(ascending=False).plot(kind='bar')
plt.title('Missing Values in Test Data')
plt.xlabel('Columns')
plt.ylabel('Number of Missing Values')
plt.tight_layout()
plt.show()
3.2、合并数据集
将训练集和测试集合并为一个大的数据框架 data,以便统一进行数据预处理。这简化了需要同时在两个数据集上执行的操作。
# 可视化缺失值数量
plt.figure(figsize=(12, 6))
missing_values_combined[missing_values_combined > 0].sort_values(ascending=False).plot(kind='bar')
plt.title('Missing Values in Combined Data')
plt.xlabel('Columns')
plt.ylabel('Number of Missing Values')
plt.show()

3.3、数据探索
计算并展示每个字段的唯一值数量。这有助于理解数据的多样性和分布,是初步数据探索的重要部分。
# 数据探索:计算并展示每个字段的唯一值数量
unique_values = data.apply(pd.Series.nunique)
print(unique_values.sort_values(ascending=False))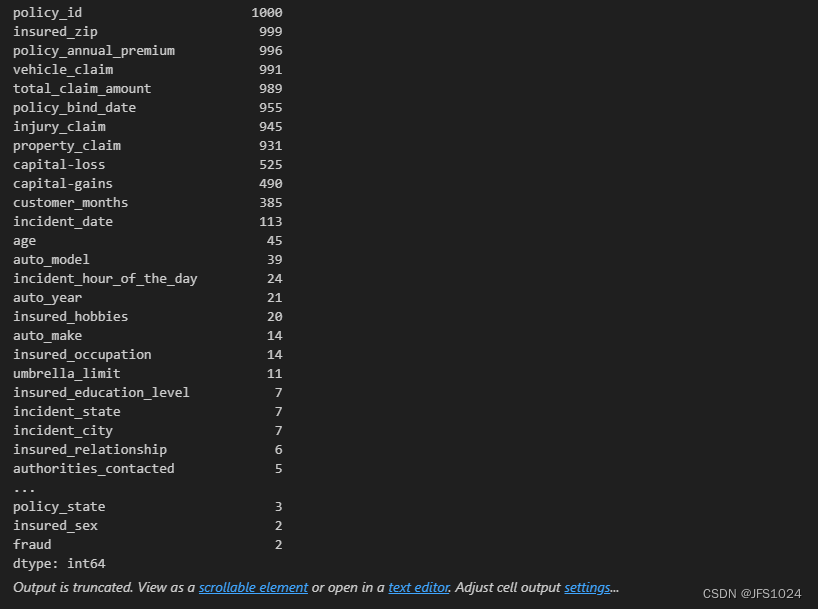
3.4、数据预处理
处理分类变量中的缺失标记:将 'property_damage' 和 'police_report_available' 中的 "?" 替换为 None,统一缺失值的表示。
日期字段的处理:将 'policy_bind_date' 和 'incident_date' 转换为日期格式,并计算它们与最早日期的天数差,以数值形式表达时间信息,然后删除原始的日期字段和 'policy_id' 字段。
# 添加标识列
train_data['dataset'] = 0
test_data['dataset'] = 1
# 合并数据集
combined_data = pd.concat([train_data, test_data], ignore_index=True)
# 处理缺失值(填充为-1)
combined_data.fillna(-1, inplace=True)
# 检查混合类型列
for column in combined_data.select_dtypes(include=['object', 'int', 'float']).columns:
unique_values = combined_data[column].unique()
if any(isinstance(val, str) for val in unique_values) and any(isinstance(val, (int, float)) for val in unique_values):
print(f"Column '{column}' contains mixed types: {unique_values}")
# 将混合类型列转换为字符串
for column in combined_data.select_dtypes(include=['object', 'int', 'float']).columns:
combined_data[column] = combined_data[column].astype(str)
# 标签编码
label_encoder = LabelEncoder()
for column in combined_data.select_dtypes(include=['object']).columns:
combined_data[column] = label_encoder.fit_transform(combined_data[column])
# 分离训练集和测试集
train_data = combined_data[combined_data['dataset'] == 0].drop(['dataset'], axis=1)
test_data = combined_data[combined_data['dataset'] == 1].drop(['dataset', 'fraud'], axis=1)
# 删除policy_id列
train_data = train_data.drop(['policy_id'], axis=1)
test_data = test_data.drop(['policy_id'], axis=1)
# 特征和标签分离
X = train_data.drop(['fraud'], axis=1)
y = train_data['fraud']
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
test_data_scaled = scaler.transform(test_data)
# 可视化部分特征的分布
plt.figure(figsize=(20, 12))
plt.subplot(3, 2, 1)
sns.histplot(combined_data['age'], kde=True, bins=30)
plt.title('Age Distribution')
plt.subplot(3, 2, 2)
sns.histplot(combined_data['policy_deductable'], kde=True, bins=30)
plt.title('Policy Deductible Distribution')
plt.subplot(3, 2, 3)
sns.histplot(combined_data['policy_annual_premium'], kde=True, bins=30)
plt.title('Policy Annual Premium Distribution')
plt.subplot(3, 2, 4)
sns.countplot(x='incident_type', data=combined_data)
plt.title('Incident Type Distribution')
plt.subplot(3, 2, 5)
sns.countplot(x='incident_severity', data=combined_data)
plt.title('Incident Severity Distribution')
plt.subplot(3, 2, 6)
sns.countplot(x='fraud', data=train_data)
plt.title('Fraud Distribution in Training Data')
plt.tight_layout()
plt.show()
3.5、数据集切分
根据 'fraud' 字段是否为空,重新切分合并后的数据集为训练集和测试集。训练集包含 'fraud' 字段非空的记录,而测试集则包含该字段为空的记录。
# 数据集切分
train = data[data['fraud'].notna()]
test = data[data['fraud'].isna()]3.6、模型初始化与训练
初始化 LGBMClassifier 并设置相关参数,然后使用训练集的特征和标签进行模型训练。
# 初始化并训练模型
model = LGBMClassifier(
num_leaves=31, reg_alpha=0.25, reg_lambda=0.25, objective='binary',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2022,
n_estimators=2000, subsample=1, colsample_bytree=1
)
model.fit(train.drop(['fraud'], axis=1), train['fraud'])3.7、模型评估
使用训练集的数据评估模型的性能,计算 AUC 分数,这是衡量二分类模型性能的重要指标。
# 模型评估
y_pred_proba = model.predict_proba(train.drop(['fraud'], axis=1))[:, 1]
print("Train AUC Score:", roc_auc_score(train['fraud'], y_pred_proba))四、总结
4.1、项目总代码
# 导入所需的包
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from lightgbm import LGBMClassifier
from sklearn.metrics import roc_auc_score
# 读取数据
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
submission = pd.read_csv("data/submission.csv")
# 打印数据集中缺失值的数量
print("Train data missing values:")
print(train.isnull().sum())
print("\nTest data missing values:")
print(test.isnull().sum())
# 合并数据集,方便一起处理
data = pd.concat([train, test], ignore_index=True)
# 数据探索:计算并展示每个字段的唯一值数量
unique_values = data.apply(pd.Series.nunique)
print(unique_values.sort_values(ascending=False))
# 处理"property_damage"和"police_report_available"中的"?"
for col in ['property_damage', 'police_report_available']:
data[col] = data[col].replace({'NO': 0, 'YES': 1, '?': None})
# 将日期字段转换为距离最早日期的天数
data['policy_bind_date'] = pd.to_datetime(data['policy_bind_date'])
data['incident_date'] = pd.to_datetime(data['incident_date'])
base_date = data['policy_bind_date'].min()
data['policy_bind_date_diff'] = (data['policy_bind_date'] - base_date).dt.days
data['incident_date_diff'] = (data['incident_date'] - base_date).dt.days
data.drop(['policy_bind_date', 'incident_date', 'policy_id'], axis=1, inplace=True)
# 对所有类别型特征进行标签编码
cat_columns = data.select_dtypes(include='object').columns
for col in cat_columns:
le = LabelEncoder()
data[col] = le.fit_transform(data[col].astype(str))
# 数据集切分
train = data[data['fraud'].notna()]
test = data[data['fraud'].isna()]
# 初始化并训练模型
model = LGBMClassifier(
num_leaves=31, reg_alpha=0.25, reg_lambda=0.25, objective='binary',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2022,
n_estimators=2000, subsample=1, colsample_bytree=1
)
model.fit(train.drop(['fraud'], axis=1), train['fraud'])
# 模型评估
y_pred_proba = model.predict_proba(train.drop(['fraud'], axis=1))[:, 1]
print("Train AUC Score:", roc_auc_score(train['fraud'], y_pred_proba))
# 准备提交文件
test_proba = model.predict_proba(test.drop(['fraud'], axis=1))[:, 1]
submission['fraud'] = test_proba
submission.to_csv('submission.csv', index=False)4.1、学习总结
参加保险欺诈检测比赛不仅让我深入了解保险行业中的欺诈挑战及其应对策略,还通过数据处理、模型建立和结果分析提升了我的数据科学技能。与其他参赛者的交流和分享让我意识到团队合作的重要性,这次经历不仅是技能的提升,更是对实际项目应用能力的重要积累。
4.2、成绩查询
模型的性能将通过AUC(ROC曲线下的面积)来评估。AUC越高,模型区分正负类(即欺诈与非欺诈)的能力越强。最后的提交的结果阿里天池的成绩来到0.97,继续优化代码成绩还会更高。

这个赛题围绕保险风控展开,具体聚焦于车险领域中的保险欺诈问题。保险欺诈是一个严重影响保险业务和金融安全的问题,有数据显示,在某些险种上,欺诈金额可能高达理赔金额的20%或更多。因此,开发能够有效预测和识别保险欺诈行为的模型,对于降低损失、提高行业效率具有重要意义。
4.3、拓展
如果想要继续学习参加比赛请前往:https://tianchi.aliyun.com/?spm=a2c22.12281925.J_3941670930.3.62657137VL6MZq
配套学习资源地址:https://tianchi.aliyun.com/course/?spm=a2c22.12281976.0.0.3da77f76fjyyqs















 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









