






目录
1.赛题介绍
本次教学赛是陈博士发起的数据分析系列赛事第2场 —— 保险反欺诈预测
赛题以保险风控为背景,保险是重要的金融体系,对社会发展,民生保障起到重要作用。保险欺诈近些年层出不穷,在某些险种上保险欺诈的金额已经占到了理赔金额的20%甚至更多。对保险欺诈的识别成为保险行业中的关键应用场景。
金融数据分析比赛的目的是为了更好地带动数据科学初学者一起玩起来,因此我们鼓励所有选手,基于赛题发表notebook分享,内容包含但不限于对赛题的理解、数据分析及可视化、算法模型的分析以及数据分析思路等内容。
2.赛题背景
赛题以保险风控为背景,保险是重要的金融体系,对社会发展,民生保障起到重要作用。保险欺诈近些年层出不穷,在某些险种上保险欺诈的金额已经占到了理赔金额的20%甚至更多。对保险欺诈的识别成为保险行业中的关键应用场景。
2.1赛题任务
数据集提供了之前客户索赔的车险数据,希望你能开发模型帮助公司预测哪些索赔是欺诈行为
To DO:预测用户的车险是否为欺诈行为
| 字段 | 说明 |
|---|---|
| policy_id | 保险编号 |
| age | 年龄 |
| customer_months | 成为客户的时长,以月为单位 |
| policy_bind_date | 保险绑定日期 |
| policy_state | 上保险所在地区 |
| policy_csl | 组合单一限制Combined Single Limit |
| policy_deductable | 保险扣除额 |
| policy_annual_premium | 每年的保费 |
| umbrella_limit | 保险责任上限 |
| insured_zip | 被保人邮编 |
| insured_sex | 被保人姓名:FEMALE或者MALE |
| insured_education_level | 被保人学历 |
| insured_occupation | 被保人职业 |
| insured_hobbies | 被保人兴趣爱好 |
| insured_relationship | 被保人关系 |
| capital-gains | 资本收益 |
| capital-loss | 资本损失 |
| incident_date | 出险日期 |
| incident_type | 出险类型 |
| collision_type | 碰撞类型 |
| incident_severity | 事故严重程度 |
| authorities_contacted | 联系了当地的哪个机构 |
| incident_state | 出事所在的省份,已脱敏 |
| incident_city | 出事所在的城市,已脱敏 |
| incident_hour_of_the_day | 出事所在的小时(一天24小时的哪个时间) |
| number_of_vehicles_involved | 涉及的车辆数 |
| property_damage | 是否有财产损失 |
| bodily_injuries | 身体伤害 |
| witnesses | 目击证人 |
| police_report_available | 是否有警察记录的报告 |
| total_claim_amount | 整体索赔金额 |
| injury_claim | 伤害索赔金额 |
| property_claim | 财产索赔金额 |
| vehicle_claim | 汽车索赔金额 |
| auto_make | 汽车品牌,比如Audi, BMW, Toyota, Volkswagen |
| auto_model | 汽车型号,比如A3,X5,Camry,Passat等 |
| auto_year | 汽车购买的年份 |
| fraud | 是否欺诈,1或者0 |
评价标准: AUC, 即ROC曲线下面的面积 (Area under the Curve of ROC)
3.详细代码
3.1 导入包
# 导入包
from igraph import *
import pandas as pd
# 读取数据
test = pd.read_csv('test.csv')
train = pd.read_csv('train.csv')
data_submission = pd.read_csv("submission.csv")我们先导入包,然后读取相关数据。
3.2进行数据清洗和探索
# 打印train数据集中缺失值的数量
print("Train data missing values:")
print(train.isnull().sum())
# 打印test数据集中缺失值的数量
print("\nTest data missing values:")
print(test.isnull().sum())
#合并代码
data.index = range(len(data))
data
#索引
data.index = range(len(data))
#进行数据探索
data.isnull().sum()
# 唯一值个数
for col in data.columns:
print(col, data[col].nunique())
3.3初始化代码
# 初始化两个空列表,用于存储列名和对应的唯一值数量
column_name = [] # 存放列名的列表
unique_value = [] # 存放每列唯一值数量的列表
# 遍历DataFrame的每一列
for col in data.columns:
# 将当前列名添加到column_name列表中
column_name.append(col)
# 计算当前列的唯一值数量,并将结果添加到unique_value列表中
unique_value.append(data[col].nunique())
# 创建一个空的DataFrame,用于存放结果
df = pd.DataFrame()
# 将column_name列表作为'col_name'列添加到df中
df['col_name'] = column_name
# 将unique_value列表作为'value'列添加到df中
df['value'] = unique_value
# 根据'value'列的值对df进行降序排序
df = df.sort_values('value', ascending=False)
# 此时df包含了所有列的列名以及对应的唯一值数量,并按唯一值数量降序排列
df
#返回的是DataFrame data 的列标签
data[data.columns]3.4对包含?符号的进行处理
# 单独看某个字段
data['property_damage'].value_counts()
data['property_damage'] = data['property_damage'].map({'NO': 0, 'YES': 1, '?': 2})
data['property_damage'].value_counts()
data
#对包含?符号的进行处理
data['police_report_available'].value_counts()
data['police_report_available'] = data['police_report_available'].map({'NO': 0, 'YES': 1, '?': 2})
data['police_report_available'].value_counts()
data
这段代码的目的是对Pandas DataFrame中的两个字段(property_damage 和 police_report_available)进行处理,主要是将字段中的文本值(如'NO', 'YES', '?')映射为数值(如0, 1, 2)
3.5查看日期
# data的描述
data.describe()
# policy_bind_date, incident_date
data['policy_bind_date'] = pd.to_datetime(data['policy_bind_date'])
data['incident_date'] = pd.to_datetime(data['incident_date'])
# 查看最大日期,最小日期
data['policy_bind_date'].min() # 1990-01-08
data['policy_bind_date'].max() # 2015-02-22
data['incident_date'].min() # 2015-01-01
data['incident_date'].max() # 2015-03-01
data
base_date = data['policy_bind_date'].min()
# 转换为date_diff
data['policy_bind_date_diff'] = (data['policy_bind_date'] - base_date).dt.days
data['incident_date_diff'] = (data['incident_date'] - base_date).dt.days
#去掉原始日期字段 policy_bind_date incident_date
data.drop(['policy_bind_date', 'incident_date'], axis=1, inplace=True)
data
#删除列名
data.drop(['policy_id'], axis=1, inplace=True)
data.columns
#标签编码
from sklearn.preprocessing import LabelEncoder
cat_columns = data.select_dtypes(include='O').columns
for col in cat_columns:
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
data[cat_columns]3.6数据集切分和模型训练
# 数据集切分
train = data[data['fraud'].notnull()]
test = data[data['fraud'].isnull()]
# 模型训练
import lightgbm as lgb
model_lgb = lgb.LGBMClassifier(
num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25, objective='binary',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2022,
n_estimators=2000, subsample=1, colsample_bytree=1,
)
# 模型训练
model_lgb.fit(train.drop(['fraud'], axis=1), train['fraud'])
# AUC评测: 以proba进行提交,结果会更好
y_pred = model_lgb.predict_proba(test.drop(['fraud'], axis=1))
y_pred
这段代码主要做了以下几步操作来训练一个基于LightGBM的二分类模型,并对测试数据进行预测以得到预测概率。
3.7测评分数
# 测评分数
train['fraud'].mean()
y_pred[:, 1]3.8绘制饼形图
import matplotlib.pyplot as plt
# 计算欺诈与非欺诈的数量
fraud_counts = train['fraud'].value_counts()
# 绘制饼形图
plt.figure(figsize=(6, 6))
plt.pie(fraud_counts, labels=['Non-Fraud', 'Fraud'], autopct='%1.1f%%', colors=['skyblue', 'salmon'])
plt.title('Fraud Distribution')
plt.show()结果展示:
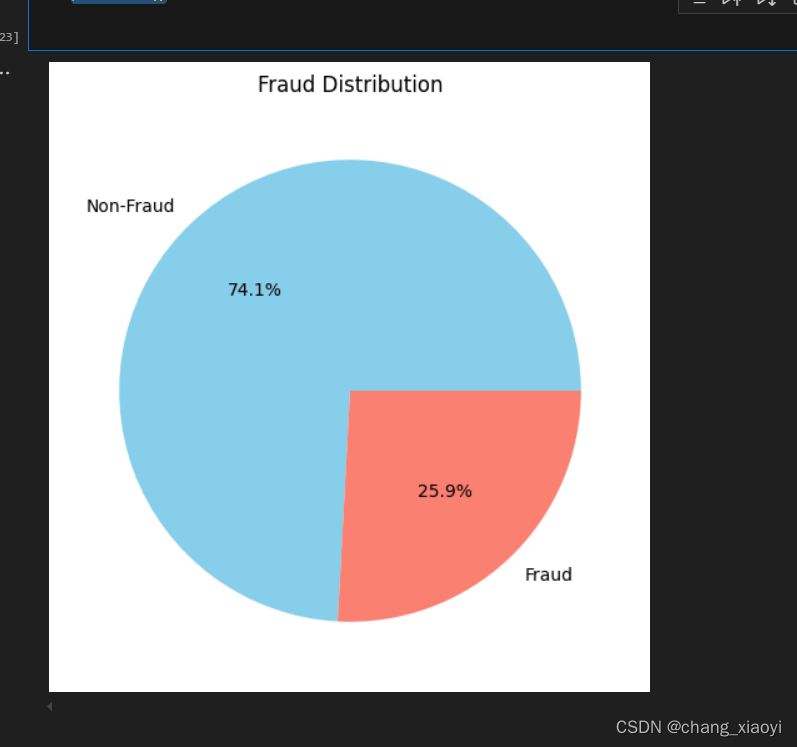
3.9保存文件
result = pd.read_csv('submission.csv')
result['fraud'] = y_pred[:, 1]
result.to_csv('insurance_fraud_predict0.csv', index=False)4.赛项总结
4.1赛项背景与意义
在保险行业中,欺诈行为一直是一个严重的挑战。随着数据分析和机器学习技术的快速发展,利用这些技术来预测和预防保险欺诈成为了可能。本次教学赛以“保险反欺诈预测”为主题,旨在通过数据分析手段,帮助保险公司更准确地识别潜在的欺诈行为,降低欺诈损失,提升保险行业的整体风险防控能力。
4.2赛项内容与过程
本次赛项以真实的保险数据为基础,参赛者需要利用数据分析、数据挖掘和机器学习等技术,构建有效的保险反欺诈预测模型。赛项过程主要包括以下几个阶段:
- 数据预处理:参赛者需要对原始数据进行清洗、转换和特征工程等操作,以获取高质量的输入数据。
- 模型构建:参赛者需要根据数据特点选择合适的机器学习算法,如逻辑回归、决策树、随机森林、梯度提升机等,构建保险反欺诈预测模型。
- 模型训练与优化:参赛者需要使用训练数据对模型进行训练,并通过交叉验证等方法对模型进行优化,提高模型的预测性能。
- 结果提交与评估:参赛者需要将预测结果提交给主办方,主办方将根据评价标准对参赛作品进行评分和排名。
4.3总结自己的学习成果
- 在处理数据预处理是构建高效模型的关键步骤,需要认真对待并投入足够的时间和精力。
- 选择合适的机器学习算法和参数设置对模型性能有重要影响,需要根据数据特点和业务需求进行充分的尝试和调整。
- 交叉验证等优化方法可以有效提高模型的预测性能,但也需要注意计算成本和时间效率等问题















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









