









程序中文本的编码,是一个很烦人的问题。多掌握一些编码方面的知识,在写程序的时候,可以少走一些弯路。
在使用.NET应用程序读文本文件的时候,我们很少注意文件编码的问题。因为在大部分情况下,它自己会识别出文件的编码。最简单也是最常用的读文本文件的语句: System.IO.File.ReadAllText(filePath)(默认采用utf-8编码),只要传入文件的路径,基本上可以正确的读出文本的内容。偶尔出现乱码的时候,只要传入默认编码System.Text.Encoding.Default,就可以解决问题。通常.NET程序员(包括我)很少会去关心编码的问题。这里System.Text.Encoding是.NET基类库中表示编码的基类,所有的编码类型都继承它,如:UTF8Encoding, UnicodeEncoding等等。而Default是Encoding类的一个属性,表示操作系统的当前 ANSI 代码页的编码。针对不同语言,不同文化,不同区域的操作系统,该属性值是也是不同的。在我的电脑上,Default表示的是:System.Text.DBCSCodePageEncoding。只要一条很简单的语句就可以获知Default的类型,在IronPython中:print System.Text.Encoding.Default;而在C#中,可以使用Console.WriteLine(System.Text.Encoding.Default)。关于System.Text.DBCSCodePageEncoding,我并没有在MSDN上找到它的定义,但通过google我了解到它是一种表示亚洲地区语言的编码。既然如此,它应该可以识别如:gb2312或gbk编码的文本,而对于unicode或者其他编码的文本,它应该无能为力。但情况“似乎”并不是这样的。下面来试验一下:
打开记事本,输入“中国”二字,然后分别另存为不同编码类型的文件。如:utf-8编码的保存为utf-8.txt,ansi编码的保存为ansi.txt,unicode编码的保存为nicode.txt。现在通过System.IO.File来分别读取这三个文件的内容。下面是IronPython的代码:
运行结果为:
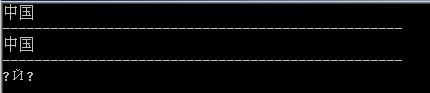
System.IO.File.ReadAllText默认采用utf-8来解码文件,它能够正确的解码utf-8格式保存的文件,对于ansi文件,出现乱码,这些都在意料之中,但对于unicode格式保存的文本,它竟然也正确的读出了内容,这一点很让人疑憾。
现在继续我的试验,在读文件的时候,显式的提供文件编码类型:System.Text.Encoding.Default,代码为:
运行结果为:
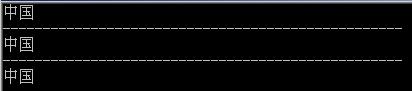
程序正确的识别出了所有的文本编码。System.Text.Encoding.Default在上面这段程序中是System.Text.DBCSCodePageEncoding类型,它可以识别ansi,那是理所当然,但为什么可以识别utf-8与unicode呢?
原因其实很简单:Notepad在保存文件的时候,做了一些手脚,添加了一些附加信息。如:保存为utf-8格式的文件时,notepad会向文本中添加: 0xef, 0xbb, 0xbf,即BOM,而保存为Unicode格式的文件时,会添加0xFE, 0xFF。

.NET程序在读文本的时候,它首先 会检查一下文本的头,看是否有类似0xef0xbb0xbf的标识,如果有,则按照这些标识所表示的编码格式来解码文本;如果没有这些头信息,则根据传入的编码类型来解码文本。 下面来验证一下:
去掉文件头的文本:
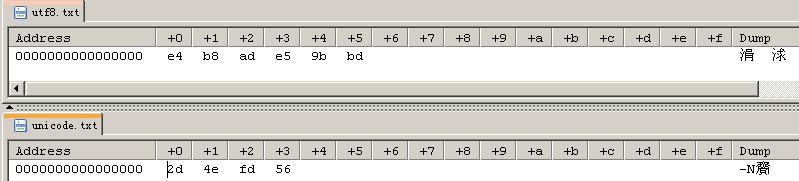
用系统默认编码方法来读文本:
运行结果:
![]()
在没有文件头的情况下,用DBCSCodePageEncoding来解码utf-8与unicode的文本,结果当然是乱码。修改一下程序:
结果:
![]()
这下结果正确了。















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









