






前言
Hive是我们大数据领域常用的数据仓库组件,在平时设计和查询的时候要特别注意效率。
影响Hive效率的几乎从不是数据量过大,而是数据倾斜、数据冗余、Job或I/O过多、MapReduce分配不合理等等。对Hive的调优一般包含以下几个方面,对HQL语句的优化,Hive参数的优化,建表时的优化,下面我就从这几个方面来浅略说明一下
建表层面
hive有哪些表呢?
1.分区表
2.分桶表
分区表是在某一个或者几个维度上对数据进行分类存储,一个分区表对应一个目录。如果筛选条件里面有分区字段,那么Hive只需要遍历对应分区目录下的文件就可以了,不需要全局遍历,使得处理的数据量大大减少,从而提高我们的执行效率
分区表
1.创建含有分区的表
CREATE DATABASE tableName(
view INT,
userid BIGINT,
page_url STRING,
refer STRING,
ip STRING COMMENT '这是一个ip字段'
)PARTITIONED BY (date STRING,country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '1' STORED AS orc
tblproperties ('orc.compress' = 'SNAPPY');
# partitioned by 后面跟我们要建立的分区字段
# '说明这里采用的是orc存储格式,没有采用TextFile ' 我们在建表层面可以采用列式存储,不用采用textfile存储 , 在压缩格式上我们采用的是snappy格式 一般我们ods层的表可以采用zlip格式,后面我们会说到
2.载入内容,并指定分区标志
load data local inpath '/home/bigdata/pv_2022_us.txt' into table tableName partition(date='2022-07-12',country='us')3.查询指定标志的分区内容
SELECT
tableName.*
FROM tableName
WHERE
tableName.date>='2019-09-10'
AND tableName.date <='2020-01-01'那什么时候用这个分区表呢?
1.当我们意识到一个字段经常用来做where查询,就可以使用分区表,使用这个字段当作分区字段
使用分区字段的好处?
2.在查询的时候,使用分区字段进行过滤,就可以避免进行全表扫描,提升我们的查询效率,节省查询时间
分桶表
分桶与分区的概念很相似,都是把数据分成不同的的类别,区别就是规则不一样!
1.分区:按照字段来进行:一个分区,就是包含这个这一个值的所有记录,不是当前分区的数据一定不在当前分区当前分区也只会包含当前这个分区值的数据
2.分桶:默认规则:Hash散列 一个分桶中会有多个不同的值 如果一个分桶中,包含了某个值,这个值的所有记录,必然都在这个分桶
那分桶表有什么应用场景呢?
1.采样
2.join
1.创建分桶表用userid这个字段来进行分桶演示
CREATE DATABASE tableName(
view INT,
userid BIGINT,
page_url STRING,
refer STRING,
ip STRING COMMENT '这是一个ip字段'
)
COMMENT '这是一张展示表 '
PARTITIONED BY (date STRING,country STRING)
CLUSTERED BY (userid)
SORTED BY (view)
INTO 32 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '1' COLLECION ITEMS TERMINIATED
BY '2' MAP KEYS STORED AS SEQUENCEFILE;语法说明
CLUSTERED BY (userid) SORTED BY (view)
INTO 32 BUCKETSCLUSTERED BY (userid) 表示按照userid 来进行分组
SORTED BY (view) 表示按照 view来进行桶内排序
INTO 32 BUCKETS 表示分成多少个桶
选择适合的文件存储格式
在HQL语句中的create table 语句中,可以使用stored as ... 这样的格式来指定表的存储格式
目前Apache Hive 支持 Apache Hadoop 中使用的几种熟悉的文件格式, 比如 TextFile 、SequenceFile、RCFile、Avro、ORC、ParquetFile等。
下面我们来说下常见的几种存储格式的区别
1.TextFile
- 存储方式:行存储,默认格式,如果建表时不指定存储格式,默认采用这种格式进行存储
- 每一行都是一条记录,每行默认都已换行符"\n"结尾,数据不做压缩时,磁盘开销会比较大,数据解析开销也比较大
2.SequenceFile
- 一种Hadoop API 提供的二进制文件,使用方便,可分割压缩的特点。
3.RCFile
- 存储方式:数据按行分块,每块按照列存储。① 首先,将数据按照行进行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。② 其次,块数据列式存储,有利于数据压缩和快速的列存取。
- 相对来说,RCFile对于提升任务执行性能提升不大,但是能节省一些存储空间,当然还有更好的选择 RC-pro版 => ORC
4.ORCFile
- 存储方式:数据按行进行分块,每块按照列存储
- Hive提供的新格式,属于RCFile-pro版 ,性能有大幅提升
- ORCFile 会基于列创建索引,当查询的时候会很快
5.ParquetFile
- 存储方式:列式存储
- Parquet对于大查询的类型是高效的,对于扫描特定表格中的特定列查询Parquet特别有用,一般使用snappy压缩
- Parque支持Impala查询引擎
- 表的文件存储格式尽量采用Parquet 或者ORC ,不仅降低存储量,还优化了查询,压缩,表关联等性能
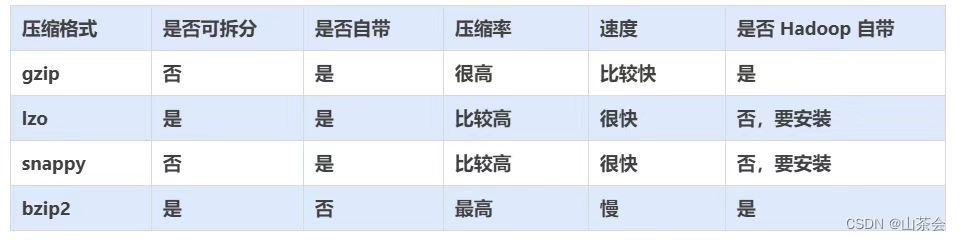
选择合适的压缩格式
基于业务选择 压缩格式 考虑我们数仓的实际作用选择合适的压缩格式
基于压缩比与解压缩效率,来选择数仓层次的压缩格式















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









