






 本文详细介绍了马尔可夫决策过程(MDP)中有限状态和动作集的特性,探讨了动力学方程、回报的量化方法、价值函数(state-value和action-value)以及贝尔曼方程的应用。重点阐述了如何通过最优策略最大化长期累计奖励,包括状态值函数和动作值函数的计算及其在不确定环境中的应用。
本文详细介绍了马尔可夫决策过程(MDP)中有限状态和动作集的特性,探讨了动力学方程、回报的量化方法、价值函数(state-value和action-value)以及贝尔曼方程的应用。重点阐述了如何通过最优策略最大化长期累计奖励,包括状态值函数和动作值函数的计算及其在不确定环境中的应用。
Finite Markov Decision Processes(MDPs)
马尔可夫决策过程:
有限MDP中,state,reward,action 集合中的元素数都是有限的
MDP的动力学方程:
p
(
s
′
,
r
∣
s
,
a
)
=
P
r
(
S
t
=
s
′
,
R
t
=
r
∣
S
t
−
1
=
s
,
A
t
−
1
=
a
)
p(s^{'},r|s,a) = Pr(S_t = s^{'} ,R_t = r | S_{t-1} = s , A_{t-1} = a)
p(s′,r∣s,a)=Pr(St=s′,Rt=r∣St−1=s,At−1=a)
这个式子表示,当前时刻的状态和奖励仅和之前一刻的状态和行动有关于再之前的状态和行动都无关。

这个过程中的agent代表的是进行决策部分而environment 代表的是 agent的外部,这与现实意义上的概念又区别,比如以人为例子,当我们想举手时,大脑是我们的agent来控制这个行为,而我们的手臂是environment。
MDP的目标是最大化一个长期的累计奖励,或者说最大的长期累计奖励就是我们要实现的目标,那么如何量化长期获得的奖励的累计,我们以奖励序列组成的特殊函数来定义return(回报),最简单的形式就是累加:
G
t
=
R
t
+
1
+
R
t
+
2
+
.
.
.
.
+
R
T
G_t = R_{t+1} +R_{t+2}+....+R_{T}
Gt=Rt+1+Rt+2+....+RT
G代表回报,T代表着终止time step
我们将从开始到终止的整个过程叫做一个episode,每个episode 都会以一个终止状态来结尾,然后后面会再接一个开始状态来开始一个新的episode。就好比我们打LOL开始选英雄就是开始状态,基地爆炸就是终止状态,一局就算一个episode。每个episode相互独立。针对于这种有始有终的任务叫做 episode task,但是有很多任务无法分辨何时算是开始何时算是结束,我们称这种为continuing task。针对这种任务如果继续使用上面的公式会使得G趋于无穷,因为T趋于无穷。所以会再每个reward上加一个折扣率
δ
∈
(
0
,
1
)
\delta \in (0,1)
δ∈(0,1)。
G
t
=
R
t
+
1
+
δ
R
t
+
2
+
δ
2
R
t
+
3
+
.
.
.
+
δ
k
R
t
+
k
+
1
G_t = R_{t+1} + \delta R_{t+2}+ \delta ^2 R_{t+3} + ...+ \delta ^ k R_{t+k+1}
Gt=Rt+1+δRt+2+δ2Rt+3+...+δkRt+k+1
由于在后面两者都会用到,所以用一种表达方式来表示这两种task,核心思想就是把episode task 看成是
R
T
R_T
RT后奖励为0的序列。所以可以统一表示为
G
t
=
∑
k
=
t
+
1
T
δ
k
−
t
−
1
R
k
G_t = \sum_{k=t+1}^T\delta^{k-t-1}R^k
Gt=k=t+1∑Tδk−t−1Rk
value function就是在给定状态下,G的期望。用来估计一个策略的好坏。我一开始看的时候有点混乱没搞懂两者的区别在哪里,后来想了想明白了:return是已经发生了的,就是说state,action已经定下来的情况下计算reward 的和,而value function 是给定首个状态,由于后续动作(动作是依据状态相关的概率分布选择)状态都未知所以计算出来的是一个期望。用公式来表示就是
v
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
v_\pi(s) = E_\pi[G_t|S_t = s]
vπ(s)=Eπ[Gt∣St=s]
v
π
v_\pi
vπ表示的是策略
π
(
a
∣
s
)
\pi(a|s)
π(a∣s)下的value function,这种只给初始状态的叫做state-value function
q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
q_\pi(s,a) = E_\pi[G_t|S_t = s,A_t =a]
qπ(s,a)=Eπ[Gt∣St=s,At=a]
这种给定初始状态和初始行动的叫做action-value function。
Bellman equation
value function 具有一个很重要的迭代性,下面进行推导
v
π
=
E
(
G
t
∣
S
t
=
s
)
=
E
(
R
t
+
1
+
δ
G
t
+
1
∣
S
t
=
s
)
=
E
(
R
t
+
1
∣
S
t
=
s
)
+
δ
E
(
G
t
+
1
∣
S
t
=
s
)
\begin{aligned} v_\pi &= E(G_t | S_t =s) \\ &= E(R_{t+1} + \delta G_{t+1} | S_t =s) \\ &= E(R_{t+1} | S_t =s) + \delta E(G_{t+1} | S_t =s) \end{aligned}
vπ=E(Gt∣St=s)=E(Rt+1+δGt+1∣St=s)=E(Rt+1∣St=s)+δE(Gt+1∣St=s)
分别计算左右两部分
E ( R t + 1 ∣ S t = s ) = ∑ r r ⋅ P ( r ∣ s ) = ∑ r r ⋅ ( ∑ a P ( r ∣ s , a ) ⋅ P ( a ∣ s ) ) = ∑ r r ⋅ ( ∑ a ∑ s ′ P ( r , s ′ ∣ s , a ) ⋅ π ( a ∣ s ) ) \begin{aligned} E(R{_t+1} | S_t =s) = \sum_r r\cdot P(r|s) =\sum_r r \cdot(\sum_a P(r|s,a)\cdot P(a|s)) = \sum_r r\cdot(\sum_a\sum_{s'}P(r,s'|s,a)\cdot \pi(a|s)) \end{aligned} E(Rt+1∣St=s)=r∑r⋅P(r∣s)=r∑r⋅(a∑P(r∣s,a)⋅P(a∣s))=r∑r⋅(a∑s′∑P(r,s′∣s,a)⋅π(a∣s))
E
(
G
t
+
1
∣
S
t
=
s
)
=
∑
g
G
t
+
1
⋅
P
(
G
t
+
1
∣
S
t
=
s
)
=
∑
g
G
t
+
1
⋅
∑
s
′
P
(
G
t
+
1
∣
s
,
s
′
)
⋅
P
(
s
′
∣
s
)
=
∑
s
′
∑
g
G
t
+
1
⋅
P
(
G
t
+
1
∣
s
′
)
⋅
P
(
s
′
∣
s
)
)
=
∑
s
′
E
[
G
t
+
1
∣
S
t
+
1
=
s
′
]
∑
a
∑
r
P
(
r
,
s
′
∣
s
,
a
)
⋅
π
(
a
∣
s
)
\begin{aligned} E(G_{t+1}|S_t =s) &= \sum_g G_{t+1} \cdot P(G_{t+1} |S_t =s) =\sum_g G_{t+1} \cdot \sum _{s'}P(G_{t+1}|s,s')\cdot P(s'|s)\\ &=\sum_{s'}\sum_g G_{t+1}\cdot P(G_{t+1}|s')\cdot P(s'|s)) \\ &=\sum_{s'}E[G_{t+1}|S_{t+1}=s']\sum_a\sum_{r}P(r,s'|s,a)\cdot \pi(a|s) \end{aligned}
E(Gt+1∣St=s)=g∑Gt+1⋅P(Gt+1∣St=s)=g∑Gt+1⋅s′∑P(Gt+1∣s,s′)⋅P(s′∣s)=s′∑g∑Gt+1⋅P(Gt+1∣s′)⋅P(s′∣s))=s′∑E[Gt+1∣St+1=s′]a∑r∑P(r,s′∣s,a)⋅π(a∣s)
把这两个在带回去得到:
v
π
(
s
)
=
∑
a
π
(
a
∣
s
)
∑
s
′
,
r
P
(
s
′
,
r
∣
s
,
a
)
[
r
+
δ
E
[
G
t
+
1
∣
S
t
+
1
=
s
′
]
]
=
∑
a
π
(
a
∣
s
)
∑
s
′
,
r
P
(
s
′
,
r
∣
s
,
a
)
[
r
+
δ
v
π
(
s
′
)
]
\begin{aligned} v_\pi(s) &= \sum_a \pi(a|s) \sum_{s',r}P(s',r | s, a)[r+\delta E[G_{t+1 }| S_{t+1}=s']] \\ &= \sum_a \pi(a|s) \sum_{s',r}P(s',r | s, a)[r+\delta v_\pi(s')] \end{aligned}
vπ(s)=a∑π(a∣s)s′,r∑P(s′,r∣s,a)[r+δE[Gt+1∣St+1=s′]]=a∑π(a∣s)s′,r∑P(s′,r∣s,a)[r+δvπ(s′)]
action-value function也差不多
q
π
(
s
,
a
)
=
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
δ
∑
a
′
π
(
a
′
∣
s
′
)
q
π
(
s
′
,
a
′
)
]
q_\pi(s,a)=\sum_{s',r}p(s',r|s,a)[r+\delta\sum_{a'}\pi(a'|s')q_\pi(s',a')]
qπ(s,a)=s′,r∑p(s′,r∣s,a)[r+δa′∑π(a′∣s′)qπ(s′,a′)]
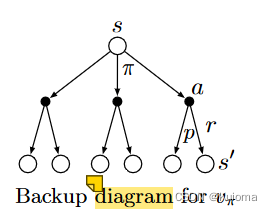
配合这幅图更好理解这个公式,图中的空心点代表状态,实心点代表行动。
最优策略
对于两个策略 π \pi π, π ′ \pi' π′,如果对于任意状态存在 v π ( s ) > = v π ′ v_\pi(s)>=v_{\pi'} vπ(s)>=vπ′,那么就认为 π > = π ′ \pi>=\pi' π>=π′,也就是 π \pi π优于或等于 π ′ \pi' π′。必然存在一个策略优于或等于所有其他策略,则称这个策略为最优策略,这个策略表示为 π ∗ \pi^* π∗。存在 v π ∗ = m a x ( v π ) v_{\pi^*} = max(v_{\pi}) vπ∗=max(vπ), q π ∗ = m a x ( q π ) q_{\pi^*} = max(q_{\pi}) qπ∗=max(qπ)。
q
π
∗
(
s
,
a
)
=
E
[
R
t
+
1
+
δ
v
π
∗
(
s
′
)
∣
S
t
=
s
,
A
t
=
a
]
=
E
[
R
t
+
1
+
δ
m
a
x
a
′
q
π
∗
(
S
t
+
1
,
a
′
)
∣
S
t
=
s
,
A
t
=
a
]
=
∑
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
δ
m
a
x
a
′
q
π
∗
(
s
′
,
a
′
)
]
\begin{aligned} q_{\pi^*}(s,a) &= E[R_{t+1}+\delta v_{\pi^*}(s')|S_t=s,A_t=a]=E[R_{t+1}+\delta max_{a'}q_{\pi^*}(S_{t+1},a')|S_t=s,A_t=a] \\ &= \sum p(s',r|s,a)[r+\delta max_{a'}q_{\pi^*}(s',a')] \end{aligned}
qπ∗(s,a)=E[Rt+1+δvπ∗(s′)∣St=s,At=a]=E[Rt+1+δmaxa′qπ∗(St+1,a′)∣St=s,At=a]=∑p(s′,r∣s,a)[r+δmaxa′qπ∗(s′,a′)]
v
π
∗
(
s
)
=
m
a
x
a
q
π
∗
(
a
,
s
)
=
m
a
x
a
∑
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
δ
v
∗
(
s
′
)
]
v_{\pi^*}(s)=max_aq_{\pi^*}(a,s)=max_a\sum p(s',r|s,a)[r+\delta v_*(s')]
vπ∗(s)=maxaqπ∗(a,s)=maxa∑p(s′,r∣s,a)[r+δv∗(s′)]
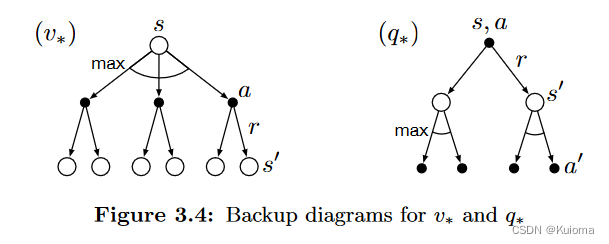
这两个公式根据上面的节点图就很好理解。
一开始对于这边还有个疑惑:就是如果全都是最优操作的话那么为什么还需要计算期望,直接全都加起来不就可以了。其实是这个environment的不确定性导致的,也就是说相同的行动在坏境中得到不同的状态,所得到的后续return也就不同,所以说还是需要计算期望
π
∗
(
a
∣
s
)
=
{
1
,
a
=
a
r
g
m
a
x
(
q
∗
(
s
,
a
)
)
0
,
o
t
h
e
r
w
i
s
e
\pi_*(a|s)= \begin{cases} 1 ,a=argmax(q_*(s,a)) \\ 0,otherwise \end{cases}
π∗(a∣s)={1,a=argmax(q∗(s,a))0,otherwise
也就是说最优化的策略是一个在固定状态下的固定选择,而不是一个概率分布















 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









