






Q-learning 算法中以矩阵的方式建立了一张存储每个状态下所有动作值的表格,这种用表格存储动作价值的做法只用在环境的状态和动作都是离散的情况。当状态或者动作数量非常大的时候,这种做法并不适用。需要用函数拟合的方法来估计Q值。
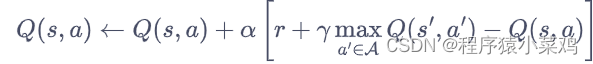
DQN 算法可以用来解决连续状态下离散动作的问题:
CartPole 环境的状态值就是连续的,动作值是离散的。
当状态每一维度的值都是连续的,无法使用表格记录时,一个常见的解决方法是使用函数拟合的思想。神经网络具有强大的表达能力,可以用一个神经网络来表示函数Q。若动作是连续(无限)的,神经网络的输入是状态和动作,然后输出一个标量,表示在状态下采取动作能获得的价值。若动作是离散(有限)的,除了可以采取动作连续情况下的做法,还可以只将状态输入到神经网络中,使其同时输出每一个动作的Q值.
由于 DQN 是离线策略算法,在收集数据的时候可以使用一个-贪婪策略来平衡探索与利用,将收集到的数据存储起来,在后续的训练中使用。DQN 中还有两个非常重要的模块——经验回放和目标网络,它们能够帮助 DQN 取得稳定、出色的性能。
agent.py
import random
import numpy as np
import torch
import torch.nn as nn
class Replaymemory:
def __init__(self,n_s,n_a): #观测状态以及观测动作有多少个
self.n_s = n_s
self.n_a = n_a
self.MEMORY_SIZE = 1000
self.BATCH_SIZE = 64 #每次取64
self.all_s = np.empty(shape=(self.MEMORY_SIZE,self.n_s),dtype=np.float32)
self.all_a = np.random.randint(low=0,high=n_a,size=self.MEMORY_SIZE,dtype=np.uint8)
self.all_r = np.empty(self.MEMORY_SIZE,dtype=np.float32)
self.all_done = np.random.randint(low=0,high=2,size=self.MEMORY_SIZE,dtype=np.uint8)
self.all_s_ = np.empty(shape=(self.MEMORY_SIZE,self.n_s),dtype=np.float32)
self.t_memo = 0
self.t_max = 0
def add_memo(self,s,a,r,done,s_):
self.all_s[self.t_memo] = s
self.all_a[self.t_memo] = a
self.all_r[self.t_memo] = r
self.all_done[self.t_memo] = done
self.all_s_[self.t_memo] = s_
self.t_max = max(self.t_memo,self.t_memo+1)
self.t_memo = (self.t_memo + 1)%self.MEMORY_SIZE
def sample(self):
if self.t_max > self.BATCH_SIZE:
idxes = random.sample(range(self.t_max),self.BATCH_SIZE)#从range(self.t_max)这么多数里边取self.BATCH_SIZE个数存放在列表idxes中,到了t_max步来取,t_max最大为一千
else:
idxes = range(0,self.t_max)
batch_s = []
batch_a = []
batch_r = []
batch_done = []
batch_s_ = []
for idx in idxes:
batch_s.append(self.all_s[idx])
batch_a.append(self.all_a[idx])
batch_r.append(self.all_r[idx])
batch_done.append(self.all_done[idx])
batch_s_.append(self.all_s_[idx])
batch_s_tensor = torch.as_tensor(np.asarray(batch_s),dtype=torch.float32)
batch_a_tensor = torch.as_tensor(np.asarray(batch_a),dtype=torch.int64).unsqueeze(-1)
batch_r_tensor = torch.as_tensor(np.asarray(batch_r),dtype=torch.float32).unsqueeze(-1)
batch_done_tensor = torch.as_tensor(np.asarray(batch_done),dtype=torch.float32).unsqueeze(-1)
batch_s__tensor = torch.as_tensor(np.asarray(batch_s_),dtype=torch.float32)
return batch_s_tensor, batch_a_tensor, batch_r_tensor, batch_done_tensor, batch_s__tensor
class DQN(nn.Module):
def __init__(self,n_input,n_output):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_features=n_input,out_features=88),
nn.Tanh(),
nn.Linear(in_features=88,out_features=n_output)
)
def forward(self,x): #前向传播
return self.net(x)
def act(self,obs):
obs_tensor = torch.as_tensor(obs,dtype=torch.float32)
q_value = self(obs_tensor.unsqueeze(0))#转化为行向量
max_q_idx = torch.argmax(input=q_value)
action = max_q_idx.detach().item()
return action
class Agent:
def __init__(self,n_input,n_output):
self.n_input = n_input
self.n_output = n_output
self.GAMMA = 0.99 #衰减因子
self.learning_rate = 1e-3
self.memo = Replaymemory(self.n_input,self.n_output) #TODO
self.online_net = DQN(self.n_input,self.n_output) #TODO
self.target_net = DQN(self.n_input,self.n_output) #TODO
self.optimizer = torch.optim.Adam(self.online_net.parameters(),lr=self.learning_rate) #TODO
2:rl.py
import random
import gym
import numpy as np
import torch
from torch import nn
from agent import Agent
env = gym.make("CartPole-v1")
s = env.reset()
EPSILON_DECAY = 10000
EPSILON_START = 1.0
EPSILON_END = 0.02
TARGET_UPDATE_FREQUENCY = 10 #每10局更新一次
n_episode = 5000 #玩五千局
n_time_step = 1000 #每局玩一千步
n_state = len(s)
n_action = env.action_space.n
agent = Agent(n_input=n_state,n_output=n_action)
REWARD_BUFFER = np.empty(shape=n_episode) #为每回合需要记录的总奖励开辟空间用于存放
for episode_i in range(n_episode):
episode_reward = 0
for step_i in range(n_time_step):
epsilon = np.interp(episode_i * n_time_step + step_i,[0,EPSILON_DECAY],[EPSILON_START,EPSILON_END])
random_sample = random.random()
if random_sample <= epsilon:
a = env.action_space.sample()
else:
a = agent.online_net.act(s) #TODO
s_, r, done, info = env.step(a)
agent.memo.add_memo(s,a,r,done,s_)#TODO 将信息存放至经验池
s = s_ #将下个观测的状态赋给当前状态
episode_reward += r #将每个回合的reward值进行相加
if done:
s = env.reset()#重置状态
REWARD_BUFFER[episode_i] = episode_reward
break
batch_s, batch_a, batch_r, batch_done, batch_s_ = agent.memo.sample()#TODO 从经验池中进行采样
#computer targets
target_q_values = agent.target_net(batch_s_)#TODO 从下一个状态获取target_q_values
max_target_q_values = target_q_values.max(dim=1,keepdim=True)[0]#获取最大的target_q_values
targets = batch_r + agent.GAMMA * (1-batch_done) * max_target_q_values#TODO 分情况求targets
#computer q_values
q_values = agent.online_net(batch_s)#TODO
a_q_values = torch.gather(input=q_values,dim=1,index=batch_a)#找最大q值
#computer loss
loss = nn.functional.smooth_l1_loss(targets,a_q_values)
#Gradient descent
agent.optimizer.zero_grad()#TODO
loss.backward()
agent.optimizer.step()#TODO
if episode_i % TARGET_UPDATE_FREQUENCY == 0: #每TARGET_UPDATE_FREQUENCY更新一次target_net
agent.target_net.load_state_dict(agent.online_net.state_dict())#TODO
#show the training process
print("Episode:{}".format(episode_i))
print("Avg. Reward:{}".format(np.mean(REWARD_BUFFER[:episode_i])))
gym==0.25.0















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









