






MAPF相关交流欢迎添加v:s1624570336
这篇文章发表在2023年的IROS上,是在这个领域中比较有名的工作PRIMAL/PRIMAL2的基础上做的创新,主要思路就是说以往的分布式系统,由于每个agent只有局部视野,没法得到足够的信息,所以通过增加agent之间的交流机制来增加agent的观测信息以获得更好的规划。之前也有一些其他的基于communication learning的方法,但是那些方法都受限于agent的规模(基本无法解决64个agent以上的任务)。所以说他的优势就是建立了一个交流机制能用在大规模agent任务上。
主要创新点
1.增加了基于Transformer的全局的交流机制,以帮助agent获得更好的观测
2.提出了一种基于学习的随机平局破解方法
环境
没啥特别的还是网格图,和之前的工作区别在于现在环境中行动时同步的,agent行动是同步的,通过联合动作向量来检查碰撞
观测
这边的视野只有3*3也就是说除了agent本身以外额外一格的区域,作者在文中说明扩大视野并不会影响性能因为通过communication已经可以提供足够的信息了。
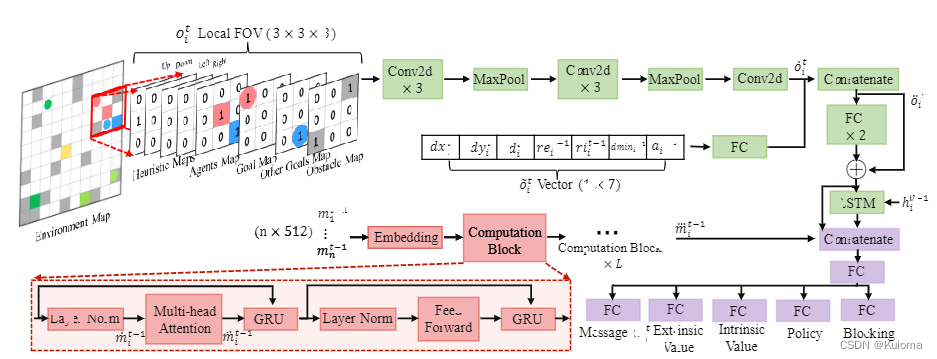
下图是网络结构,可以看到输入的矩阵是8个2维的矩阵和7个标量,前者分别是4个启发式图,外加视野内障碍,视野内其他agent位置,视野内目标位置,目标位置指向。后者分别是自身和目标位置的dx,dy和欧几里得位置,外部奖励,内部奖励,之前agent和目标间的最小欧几里得距离以及上一个位置。
交流机制
利用Transformer的encoder,对上一时刻各agent的message进行处理,这些message在被送入前会增强他们的唯一的ID信息通过正弦位置嵌入。网络结构如下所示也没啥好讲的
平局破解方法
通过让agent检查他们是否会在下个时间步上发生碰撞,如果会发生碰撞,那么根据一个学习到的优先级概率选择的agent执行最佳行动,其余的agent重新选择动作。
优先级概率计算中第一个部分是一个对团队状态价值预测性差异,来保障长期的利益避免短视,具体来说就是计算一个碰撞前的所有agent的value的和与预测可能发生碰撞后重新选择行动后的所有agent的value的一个差。
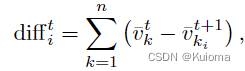
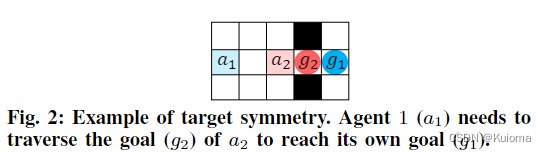
第二部分是为了解决下图这种情况,a1需要通过g2到达自己的位置,由于a2很接近自己的目标所以就容易产生自私行为,也就是呆在g2阻塞a1.所以需要在优先级概率中添加额外的部分来降低a2的优先级概率,也就是式6中的第二项依赖于每个代理当前位置与其目标之间的归一化欧式距离。
这两部分相加就能得到优先级概率
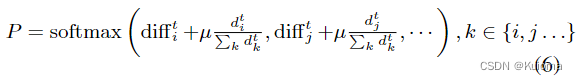
我认为比较值得注意的点就这些















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









