







以前常用Python的requests包做一些比较基本的东西,很少遇到中文乱码的问题。
requests也有自己对应解码方式,但是有时候不太好使。
比如
>> import requests
>> url = 'http://internet.baidu.com/'
>> rsp = requests.get(url)大家查看该url源码可以看到 charset=gb2312
如果此时用 rsp.text,那么就会出现一堆乱码
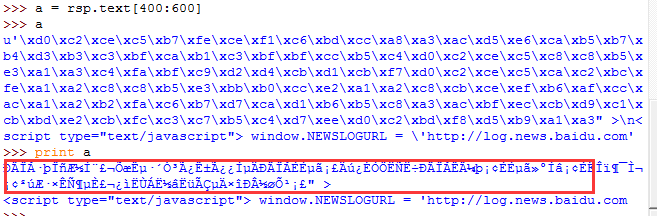
但是我们可以强制指定
>> rsp.encoding = 'gb2312'
此时再rsp.text就是熟悉的unicode编码了。
但是如果有的url不是gb2312编码怎么办?我们可以通过
>> rsp = requests.get(url)
>> rsp.apparent_encoding
'gb2312'
>> rsp.encoding = rsp.apparent_encoding这样来先识别,再赋值, 就没有问题了。
就可以直接使用rsp.text















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









