







Redis 提供了丰富的数据类型,常见的有五种:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合) 。
随着 Redis 版本的更新,后面又支持了四种数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增) 。

本次整理前5种数据类型,底层实现共有 9 种数据结构:SDS、双向链表(list)、压缩列表(ziplist)、哈希表(hash)、跳表(zskiplist)、整数集合(inset)、quicklist、listpack,分上下篇进行整理。
上篇讲:String(字符串)、List(列表)、Hash(哈希)
下篇讲:Set(集合)、Zset(有序集合)
1 Set(集合)
常用命令

内部实现
- 在
Redis7.2之前,set使用的是intset和hashtable - 在
Redis7.2之后,set使用的是intset、hashtable、listpack
Redis Set类型的内部编码有两种:
- intset(整数集合):当Set类型只包含整数类型的数据,并且元素数量较少(小于512个)时,Redis会使用intset作为Set类型的内部编码。intset是一种紧凑的、压缩的整数集合结构,可以节省内存空间,并且支持快速的查找、插入和删除操作。在intset中,所有元素都按照从小到大的顺序排列,并且可以使用不同的编码方式(16位、32位、64位)存储不同大小范围内的整数。
- hashtable(哈希表):当Set类型包含字符串类型或者元素数量较多时,Redis会使用hashtable作为Set类型的内部编码。hashtable是一种基于链表的哈希表结构,可以快速地进行随机访问、插入和删除操作。在hashtable中,每个元素都被存储为一个字符串,并且使用哈希函数将字符串映射到一个桶中,然后在桶中进行查找、插入和删除操作。
在实际使用中,当Set类型的元素全部为整数类型且元素个数小于 512时(默认值,set-maxintset-entries配置),Redis 会使用整数集合作为 Set 类型的底层数据结构;如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
intset最大元素数量可在redis.conf配置
set-max-intset-entries 512
为什么加入了listpack
在redis7.2之前,sds类型的数据会直接放入到编码结构式为hashtable的set中。其中,sds其实就是redis中的string类型。
而在redis7.2之后,sds类型的数据,首先会使用listpack结构当 set 达到一定的阈值时,才会自动转换为hashtable。
添加listpack结构是为了提高内存利用率和操作效率,因为 hashtable 的空间开销和碰撞概率都比较高。
hashtable 的空间开销高
hashtable 的空间开销高是因为它需要预先分配一个固定大小的数组来存储键值对,而这个数组的大小通常要大于实际存储的元素个数,以保证较低的装载因子。装载因子是指 hashtable 中已经存储的元素个数和数组大小的比值,它反映了 hashtable 的空间利用率
- 如果装载因子过高,那么 hashtable 的性能会下降,因为碰撞的概率会增加
- 如果装载因子过低,那么 hashtable 的空间利用率会下降,因为数组中会有很多空闲的位置
因此,hashtable 需要在装载因子和空间利用率之间做一个平衡,通常装载因子的推荐值是 0.75
hashtable 的碰撞概率高
hashtable 的碰撞概率高是因为它使用了一个散列函数来将任意长度的键映射到一个有限范围内的整数,作为数组的索引
散列函数的设计很重要,它应该尽可能地保证不同的键能够均匀地分布在数组中,避免出现某些位置过于拥挤,而其他位置过于稀疏的情况。然而,由于散列函数的输出范围是有限的,而键的取值范围是无限的,所以不可能完全避免两个不同的键被散列到同一个位置上,这就产生了碰撞。碰撞会影响 hashtable 的性能,因为它需要额外的处理方式来解决冲突,比如开放寻址法或者链地址法
举例说明,假设有一个大小为8的hashtable,使用取模运算作为散列函数,即h(k) = k mod 8。现在有四个键:5,13,21,29,它们都被散列到索引1处
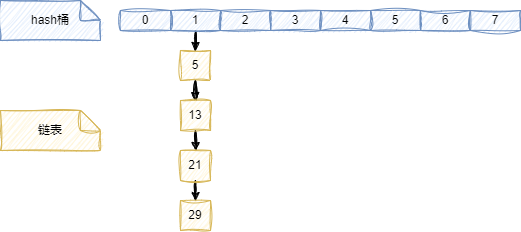
这就是一个碰撞的例子,因为四个键都映射到了同一个索引。这种情况可能是由于以下原因造成的:
- 散列函数的选择不合适,没有充分利用hashtable的空间。
- 键的分布不均匀,有些区间的键出现的频率更高。
- hashtable的大小太小,不能容纳所有的键。
为了解决碰撞,redis采用了链地址法。就是在每个索引处维护一个链表,存储所有散列到该索引的键。但是,如果链表过长,查找效率会降低。因此,一般建议保持hashtable的负载因子(即键的数量除以hashtable的大小)在一定范围内,比如0.5到0.75之间。如果负载因子过高或过低,可以通过扩容或缩容来调整hashtable的大小
intset 、listpack和hashtable的转换
intset 、listpack和hashtable这三者的转换时根据要添加的数据、当前set的编码和阈值决定的。
-
如果要添加的数据是整型,且当前
set的编码为intset,如果超过阈值由intset直接转为hashtable阈值条件为:
set-max-intset-entries,intset最大元素个数,默认512 -
如果要添加的数据是字符串,分为三种情况
- 当前
set的编码为intset:如果没有超过阈值,转换为listpack;否则,直接转换为hashtable - 当前
set的编码为listpack:如果超过阈值,就转换为hashtable - 当前
set的编码为hashtable:直接插入,编码不会进行转换
阈值条件为:
set-max-listpack-entries:最大元素个数,默认128set_max_listpack_value:最大元素大小,默认64
以上两个条件需要同时满足才能进行编码转换 - 当前
使用场景
Redis Set类型的使用场景包括:
- 标签系统:使用Set类型存储每个标签对应的对象列表,以便快速查找包含特定标签的对象。可以使用SADD、SREM、SISMEMBER、SMEMBERS等命令实现。
- 好友关系:将每个用户的好友列表作为一个集合,可以使用SADD、SREM、SISMEMBER、SDIFF、SINTER、SUNION等命令实现。
- 共同好友:使用SINTER命令计算出两个用户的共同好友,可以使用SADD、SINTER、SUNION等命令实现。
- 排名系统:将每个用户的得分作为元素值插入到集合中,使用ZADD、ZREM、ZRANK、ZSCORE等命令进行排名操作,使用ZREVRANGE命令查询排名前几的用户,可以使用ZADD、ZREM、ZRANK、ZSCORE、ZREVRANGE等命令实现。
- 订阅关系:使用Set类型存储用户订阅的内容,以便快速获取用户订阅的内容。
总的来说,Set类型适用于需要存储一组不重复的数据,并支持集合操作的场景。
点赞
Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。
uid:1 、uid:2、uid:3 三个用户分别对 article:1 文章点赞了。
# uid:1 用户对文章 article:1 点赞
> SADD article:1 uid:1
(integer) 1
# uid:2 用户对文章 article:1 点赞
> SADD article:1 uid:2
(integer) 1
# uid:3 用户对文章 article:1 点赞
> SADD article:1 uid:3
(integer) 1
uid:1 取消了对 article:1 文章点赞。
> SREM article:1 uid:1
(integer) 1
获取 article:1 文章所有点赞用户 :
> SMEMBERS article:1
1) "uid:3"
2) "uid:2"
获取 article:1 文章的点赞用户数量:
> SCARD article:1
(integer) 2
判断用户 uid:1 是否对文章 article:1 点赞了:
> SISMEMBER article:1 uid:1
(integer) 0 # 返回0说明没点赞,返回1则说明点赞了
共同关注
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
key 可以是用户id,value 则是已关注的公众号的id。
uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11。
# uid:1 用户关注公众号 id 为 5、6、7、8、9
> SADD uid:1 5 6 7 8 9
(integer) 5
# uid:2 用户关注公众号 id 为 7、8、9、10、11
> SADD uid:2 7 8 9 10 11
(integer) 5
uid:1 和 uid:2 共同关注的公众号:
# 获取共同关注
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"
给 uid:2 推荐 uid:1 关注的公众号:
> SDIFF uid:1 uid:2
1) "5"
2) "6"
验证某个公众号是否同时被 uid:1 或 uid:2 关注:
> SISMEMBER uid:1 5
(integer) 1 # 返回0,说明关注了
> SISMEMBER uid:2 5
(integer) 0 # 返回0,说明没关注
抽奖活动
存储某活动中中奖的用户名 ,Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。
key为抽奖活动名,value为员工名称,把所有员工名称放入抽奖箱 :
>SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
(integer) 5
如果允许重复中奖,可以使用 SRANDMEMBER 命令。
# 抽取 1 个一等奖:
> SRANDMEMBER lucky 1
1) "Tom"
# 抽取 2 个二等奖:
> SRANDMEMBER lucky 2
1) "Mark"
2) "Jerry"
# 抽取 3 个三等奖:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Jerry"
如果不允许重复中奖,可以使用 SPOP 命令。
# 抽取一等奖1个
> SPOP lucky 1
1) "Sary"
# 抽取二等奖2个
> SPOP lucky 2
1) "Jerry"
2) "Mark"
# 抽取三等奖3个
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"
源码分析
集合源码在 t_set.c 文件中,核心源码如下:
/*
* 添加元素到集合
* 如果当前值已经存在,则返回 0 不作任何处理,否则就添加该元素,并返回 1。
*/
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) { // 字典类型
dict *ht = subject->ptr;
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
// 把 value 作为字典到 key,将 Null 作为字典到 value,将元素存入到字典
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL);
return 1;
}
} else if (subject->encoding == OBJ_ENCODING_INTSET) { // inset 数据类型
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
// 超过 inset 的最大存储数量,则使用字典类型存储
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
// 转化为整数类型失败,使用字典类型存储
setTypeConvert(subject,OBJ_ENCODING_HT);
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
// 未知编码(类型)
serverPanic("Unknown set encoding");
}
return 0;
}
以上这些代码验证了,我们上面所说的内容,当元素都为整数并且元素的个数没有到达设置的最大值时,键值的存储使用的是 intset 的数据结构,反之到元素超过了一定的范围,又或者是存储的元素为非整数时,集合会选择使用 hashtable 的数据结构进行存储。
2 Zset(有序集合)
常用命令

内部实现
Redis Zset的内部编码有两种:
- ziplist编码(压缩列表):当有序集合中元素个数小于128个,并且所有元素的长度都小于64字节时,Redis会使用ziplist编码存储Zset。这种编码方式可以节省内存空间,并且可以提高存取效率,但是不支持随机访问和范围查询。
- skiplist编码(跳表):当Zset中元素个数大于等于128个,或者有一个元素的长度大于64字节时,Redis会使用skiplist编码存储Zset。这种编码方式支持高效的随机访问和范围查询,但是需要占用更多的内存空间。
Redis在存储zset结构的数据,为了达到内存和性能的平衡,针对少量存储和大量存储分别设计了两种结构,分别为:
ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)skiplist
当 zset 中的元素个数和元素值的长度比较小的时候,Redis 使用ziplist/listpack来节省内存空间。当 zset 中的元素个数和元素值的长度达到一定阈值时,Redis 会自动将ziplist/listpack转换为skiplist,以提高操作效率
具体来说,当 zset 同时满足以下两个条件时,会使用 listpack作为底层结构:
- 元素个数小于
zset_max_listpack_entries,默认值为 128 - 元素值的长度小于
zset_max_listpack_value,默认值为 64
当 zset 中不满足以上两个条件时,会使用 skiplist 作为底层结构。
skiplist
跳跃表是一种随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳跃表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳跃表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能
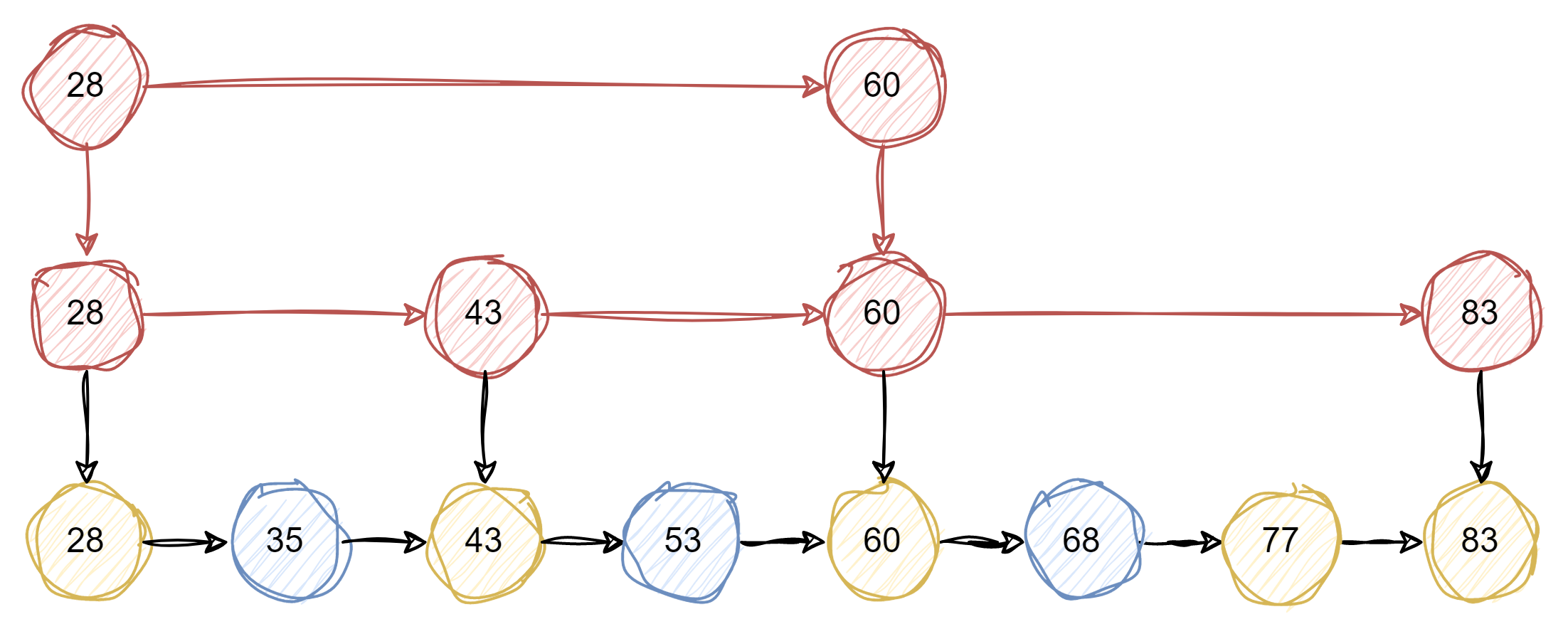
跳跃表相比于其他平衡树结构,有以下几个优点和缺点:
优点:
- 实现简单,易于理解和调试
- 插入和删除操作只需要修改局部节点的指针,不需要像平衡树那样进行全局调整
- 可以利用空间换时间,通过增加索引层来提高查找效率
- 支持快速的范围查询,可以方便地返回指定区间内的所有元素
缺点:
- 空间复杂度较高,需要额外存储多级索引
- 随机性太强,性能不稳定,最坏情况下可能退化成链表
- 不支持快速的倒序遍历,需要额外的指针来实现
redis的skiplist
skiplist有一个层数上的问题,当层数过多,会影响查询效率。而Redis 使用了一个随机函数来决定每个节点的层数,这个随机函数的期望值是 1/(1-p) ,其中 p 是一个概率常数,Redis 中默认为 0.25。这样可以保证跳跃表的平均高度为 log (1/p) n ,其中 n 是节点数。Redis 还限制了跳跃表的最大层数为 32 ,这样可以避免过高的索引层造成空间浪费
使用场景
Redis Zset是一种有序集合,其使用场景主要包括以下几个方面:
- 排行榜:使用Zset类型可以实现排行榜功能,将每个用户的得分作为元素值插入到集合中,使用ZADD、ZINCRBY、ZREM等命令进行排名操作,使用ZRANGE、ZREVRANGE命令查询排名前几的用户。
- 最近访问记录:使用Zset类型可以用于记录最近访问的记录,将最新的访问记录插入集合中,使用ZREMRANGEBYRANK命令删除最旧的记录,使用ZRANGE命令查询最近访问的记录。
- 计数器:Redis Zset可以用于实现计数器功能,比如统计某个页面的访问次数、统计某个广告的点击量等。将页面ID或广告ID作为成员(member)存储在Zset中,以访问次数或点击量作为分数(score)存储。
- 好友关系:Redis Zset可以用于存储用户之间的关注关系以及用户之间的互动,比如点赞、评论等。可以将用户ID作为成员(member)存储在Zset中,将时间戳或者其他标识作为分数(score)存储,以此记录用户之间的互动情况。
排行榜
有序集合比较典型的使用场景就是排行榜。例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等。
我们以博文点赞排名为例,小林发表了五篇博文,分别获得赞为 200、40、100、50、150。
# arcticle:1 文章获得了200个赞
> ZADD user:xiaolin:ranking 200 arcticle:1
(integer) 1
# arcticle:2 文章获得了40个赞
> ZADD user:xiaolin:ranking 40 arcticle:2
(integer) 1
# arcticle:3 文章获得了100个赞
> ZADD user:xiaolin:ranking 100 arcticle:3
(integer) 1
# arcticle:4 文章获得了50个赞
> ZADD user:xiaolin:ranking 50 arcticle:4
(integer) 1
# arcticle:5 文章获得了150个赞
> ZADD user:xiaolin:ranking 150 arcticle:5
(integer) 1
文章 arcticle:4 新增一个赞,可以使用 ZINCRBY 命令(为有序集合key中元素member的分值加上increment):
> ZINCRBY user:xiaolin:ranking 1 arcticle:4
"51"
查看某篇文章的赞数,可以使用 ZSCORE 命令(返回有序集合key中元素个数):
> ZSCORE user:xiaolin:ranking arcticle:4
"50"
获取小林文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从start下标到stop下标的元素):
# WITHSCORES 表示把 score 也显示出来
> ZREVRANGE user:xiaolin:ranking 0 2 WITHSCORES
1) "arcticle:1"
2) "200"
3) "arcticle:5"
4) "150"
5) "arcticle:3"
6) "100"
获取小林 100 赞到 200 赞的文章,可以使用 ZRANGEBYSCORE 命令(返回有序集合中指定分数区间内的成员,分数由低到高排序):
> ZRANGEBYSCORE user:xiaolin:ranking 100 200 WITHSCORES
1) "arcticle:3"
2) "100"
3) "arcticle:5"
4) "150"
5) "arcticle:1"
6) "200"
电话、姓名排序
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 可以帮助我们实现电话号码或姓名的排序,我们以 ZRANGEBYLEX (返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
注意:不要在分数不一致的 SortSet 集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确。
1、电话排序
我们可以将电话号码存储到 SortSet 中,然后根据需要来获取号段:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3
获取所有号码:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"
获取 132 号段的号码:
> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"
获取132、133号段的号码:
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"
2、姓名排序
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6
获取所有人的名字:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"
获取名字中大写字母A开头的所有人:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"
获取名字中大写字母 C 到 Z 的所有人:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"
源码分析
有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
1)ziplist
当数据比较少时,有序集合使用的是 ziplist 存储的,如下代码所示:
127.0.0.1:6379> zadd myzset 1 db 2 redis 3 mysql
(integer) 3
127.0.0.1:6379> object encoding myzset
"ziplist"
从结果可以看出,有序集合把 myset 键值对存储在 ziplist 结构中了。 有序集合使用 ziplist 格式存储必须满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用 skiplist 结构进行存储。 接下来我们来测试以下,当有序集合中某个元素长度大于 64 字节时会发生什么情况? 代码如下:
127.0.0.1:6379> zadd zmaxleng 1.0 redis
(integer) 1
127.0.0.1:6379> object encoding zmaxleng
"ziplist"
127.0.0.1:6379> zadd zmaxleng 2.0 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
(integer) 1
127.0.0.1:6379> object encoding zmaxleng
"skiplist"
通过以上代码可以看出,当有序集合保存的所有元素成员的长度大于 64 字节时,有序集合就会从 ziplist 转换成为 skiplist。
小贴士:可以通过配置文件中的 zset-max-ziplist-entries(默认 128)和 zset-max-ziplist-value(默认 64)来设置有序集合使用 ziplist 存储的临界值。
2)skiplist
skiplist 数据编码底层是使用 zset 结构实现的,而 zset 结构中包含了一个字典和一个跳跃表,源码如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
更多关于跳跃表的源码实现,会在后面的章节详细介绍。
① 跳跃表实现原理
跳跃表的结构如下图所示:

根据以上图片展示,当我们在跳跃表中查询值 32 时,执行流程如下:
- 从最上层开始找,1 比 32 小,在当前层移动到下一个节点进行比较;
- 7 比 32 小,当前层移动下一个节点比较,由于下一个节点指向 Null,所以以 7 为目标,移动到下一层继续向后比较;
- 18 小于 32,继续向后移动查找,对比 77 大于 32,以 18 为目标,移动到下一层继续向后比较;
- 对比 32 等于 32,值被顺利找到。
从上面的流程可以看出,跳跃表会想从最上层开始找起,依次向后查找,如果本层的节点大于要找的值,或者本层的节点为 Null 时,以上一个节点为目标,往下移一层继续向后查找并循环此流程,直到找到该节点并返回,如果对比到最后一个元素仍未找到,则返回 Null。
② 为什么是跳跃表?而非红黑树?
因为跳跃表的性能和红黑树基本相近,但却比红黑树更好实现,所有 Redis 的有序集合会选用跳跃表来实现存储。
参考文献
[1] https://www.cnblogs.com/Leo_wl/p/17524414.html















 3449
3449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









