







目前,普遍认为,机器学习(Machine Learning,ML)是人工智能领域中的一个方向,主要是研究如何通过计算的手段,改进系统自身的性能,说到底是通过分析足够量的数据,不断改进已有的算法,从而使得算法更加的智能,进一步地提高了其泛化的能力。
所谓的泛化能力简单地讲就是通过算法训练得到的模型对新的数据预测的准确性有很大的提高与改进。
模型泛指从数据中学习到的结果,也可以理解为潜在的一种规律。
机器学习已经广泛应用于日常的生活中,如智能手机的语言识别,人脸识别等,目前最广为报道的自动驾驶,都应用了大量的机器学习算法。
机器学习背后的原理则是数学知识的应用,比如线性代数和概率论等。
机器学习现在普遍应用的编程语言是Python。
现在,以《Programming Machine Learning From Coding to Deep Learning》一书中的程序为例。
- 需要解决的问题:在一家比萨店中,从预定的座位数量判断比萨的销量,二者之间的关系。
- 解决的思路:
- 首先,我们可以将两者之间的已有的数据绘制在二维坐标上,我们可以自己在网上寻找到一些座位数量和比萨的销量的相关数据。
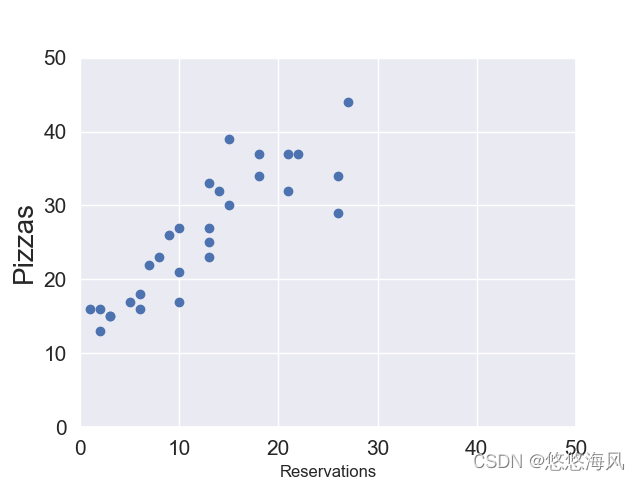
- 接着,需要对这些数据进行拟合,所谓的拟合就是找到一条直线,看这些点是否较好地散落在这条直线的周围,那么这条直线是代表预定的座位数与比萨销量的数学模型,这里我们以测试预定座位数量为20个时,比萨的销售量是多少。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns # 美化图像
X, Y = np.loadtxt("pizza.txt", skiprows=1, unpack=True) # skiprows是跳过第几行,unpack是指会把每一列当成一个向量输出, 而不是合并在一起
# print(X[0:5], Y[0:5])
# w为权重
def predict(X, w):
return X * w
# 采用均方误差法计算误差
def loss(X, Y, w):
return np.average((predict(X, w) - Y) ** 2)
# 训练
def train(X, Y, iterations, lr):
w = 0
for i in range(iterations):
current_loss = loss(X, Y, w)
print("Iterations %4d => Loss: %.6f" % (i, current_loss))
if loss(X, Y, w + lr) < current_loss:
w += lr
elif loss(X, Y, w - lr) < current_loss:
w -= lr
else:
return w
raise Exception("Couldn't converge within %d iterations" % iterations)
w = train(X, Y, iterations=10000, lr=0.01)
print("\nw=%.3f" % w)
print("Prediction: x=%d => y=%.2f" % (20, predict(20, w)))
# 画图
sns.set()
plt.plot(X, Y, "bo")
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.xlabel("Reservations", fontsize=15)
plt.ylabel("Pizzas", fontsize=20)
x_edge, y_edge = 50, 50
plt.axis([0, x_edge, 0, y_edge])
plt.plot([0, x_edge], [0, predict(x_edge, w)], linewidth=1.0, color="g")
plt.show()
- 进一步地改善这个模型,增加一个参数b,就是截距,在ML中被称为偏置。接下来,修改上述的代码。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
X, Y = np.loadtxt("pizza.txt", skiprows=1, unpack=True)
# b是y轴的截距,在机器学习中称之为偏置
def predict(X, w, b):
return X * w + b
def loss(X, Y, w, b):
return np.average((predict(X, w, b) - Y) ** 2)
def train(X, Y, iterations, lr):
w = b = 0
for i in range(iterations):
current_loss = loss(X, Y, w, b)
print("Iterations %4d => Loss: %.6f" % (i, current_loss))
if loss(X, Y, w + lr, b) < current_loss:
w += lr
elif loss(X, Y, w - lr, b) < current_loss:
w -= lr
elif loss(X, Y, w, b + lr) < current_loss:
b += lr
elif loss(X, Y, w, b - lr) < current_loss:
b -= lr
else:
return w, b
raise Exception("Couldn't converge within %d iterations" % iterations)
w, b = train(X, Y, iterations=10000, lr=0.01)
print("\nw=%.3f, b=%.3f" % (w, b))
print("Prediction: x=%d => y=%.2f" % (20, predict(20, w, b)))
sns.set()
plt.plot(X, Y, "bo")
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.xlabel("Reservations", fontsize=15)
plt.ylabel("Pizzas", fontsize=20)
x_edge, y_edge = 50, 50
plt.axis([0, x_edge, 0, y_edge])
plt.plot([0, x_edge], [b, predict(x_edge, w, b)], linewidth=1.0, color="g")
plt.show()
预测后的图像 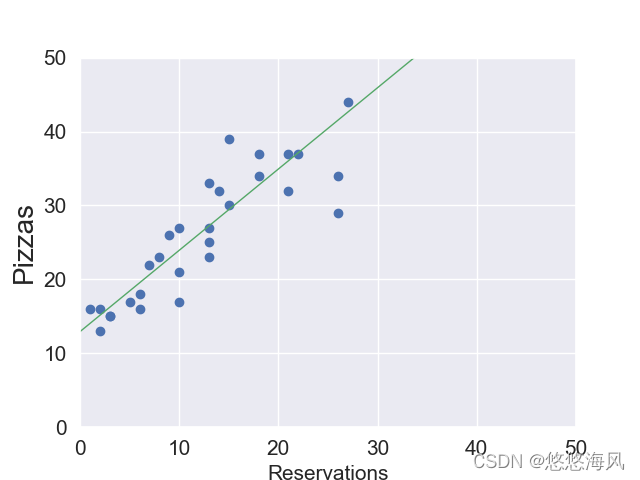
可以对上述的算法做进一步地改进,使得预测的结果更加接近于实际值!















 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









