







 本文详细介绍了 PyTorch 的核心模块,包括张量计算、自动求导和神经网络高层库,并重点讲解如何自定义 Module,包括 Function 和 Module 的使用,以及自定义循环神经网络 RNN 的过程。PyTorch 的动态图机制和模块化设计使其成为易于理解和定制的深度学习框架。
本文详细介绍了 PyTorch 的核心模块,包括张量计算、自动求导和神经网络高层库,并重点讲解如何自定义 Module,包括 Function 和 Module 的使用,以及自定义循环神经网络 RNN 的过程。PyTorch 的动态图机制和模块化设计使其成为易于理解和定制的深度学习框架。
pytorch 是一个基于 python 的深度学习库。pytorch 源码库的抽象层次少,结构清晰,代码量适中。相比于非常工程化的 tensorflow,pytorch 是一个更易入手的,非常棒的深度学习框架。
对于系统学习 pytorch,官方提供了非常好的入门教程 ,同时还提供了面向深度学习的示例,同时热心网友分享了更简洁的示例。
1. overview
不同于 theano,tensorflow 等低层程序库,或者 keras、sonnet 等高层 wrapper,pytorch 是一种自成体系的深度学习库(图1)。

图1. 几种深度学习程序库对比
如图2所示,pytorch 由低层到上层主要有三大块功能模块。
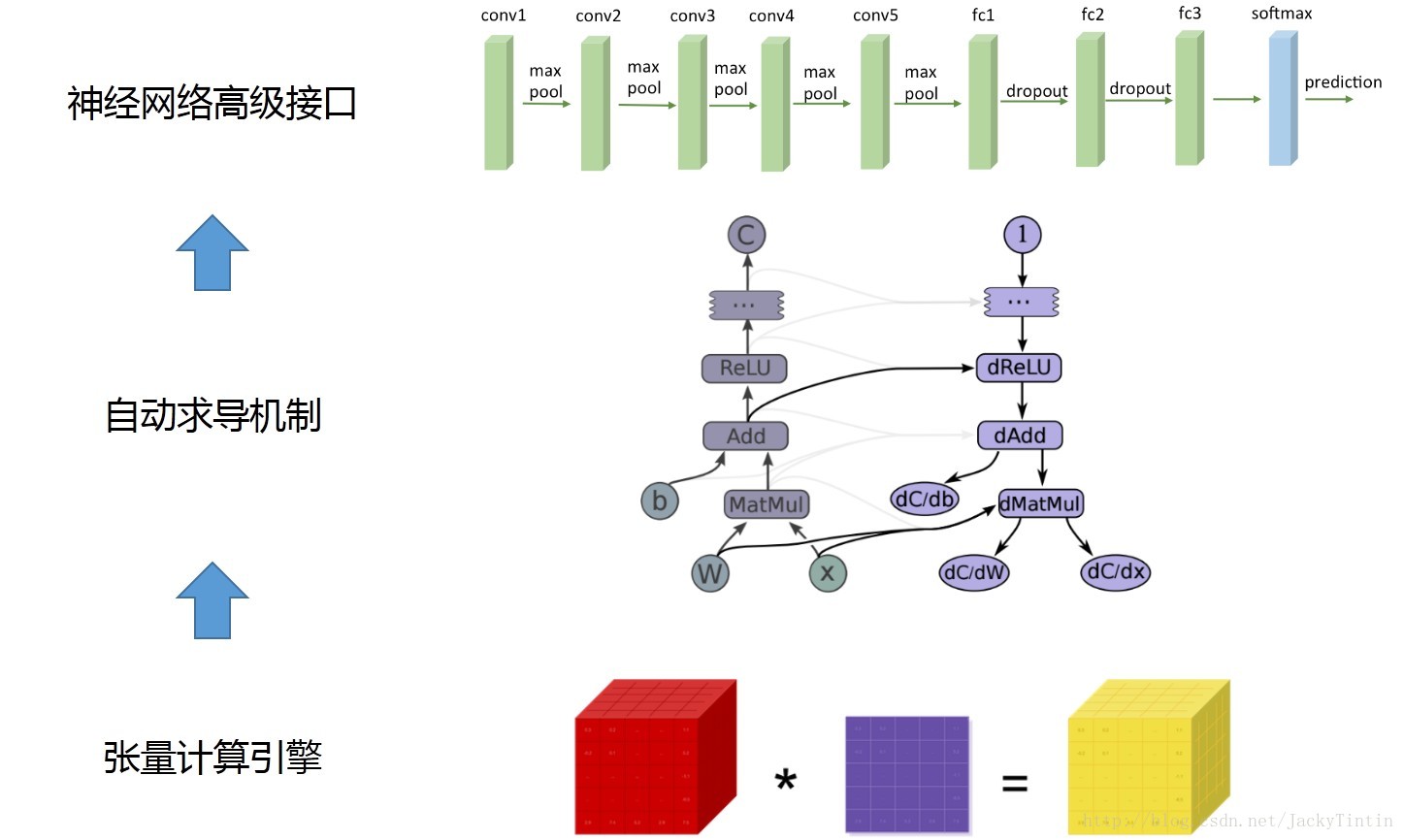
图2. pytorch 主要功能模块
1.1 张量计算引擎(tensor computation)
Tensor 计算引擎,类似 numpy 和 matlab,基本对象是tensor(类比 numpy 中的 ndarray 或 matlab 中的 array)。除提供基于 CPU 的常用操作的实现外,pytorch 还提供了高效的 GPU 实现,这对于深度学习至关重要。
1.2 自动求导机制(autograd)
由于深度学习模型日趋复杂,因此,对自动求导的支持对于学习框架变得必不可少。pytorch 采用了动态求导机制,使用类似方法的框架包括: chainer,dynet。作为对比,theano,tensorflow 采用静态自动求导机制。
1.3 神经网络的高层库(NN)
pytorch 还提供了高层的神经网络模块。对于常用的网络结构,如全连接、卷积、RNN 等。同时,pytorch 还提供了常用的目标函数、optimizer 及参数初始化方法。
这里,我们重点关注如何自定义神经网络结构。
2. 自定义 Module
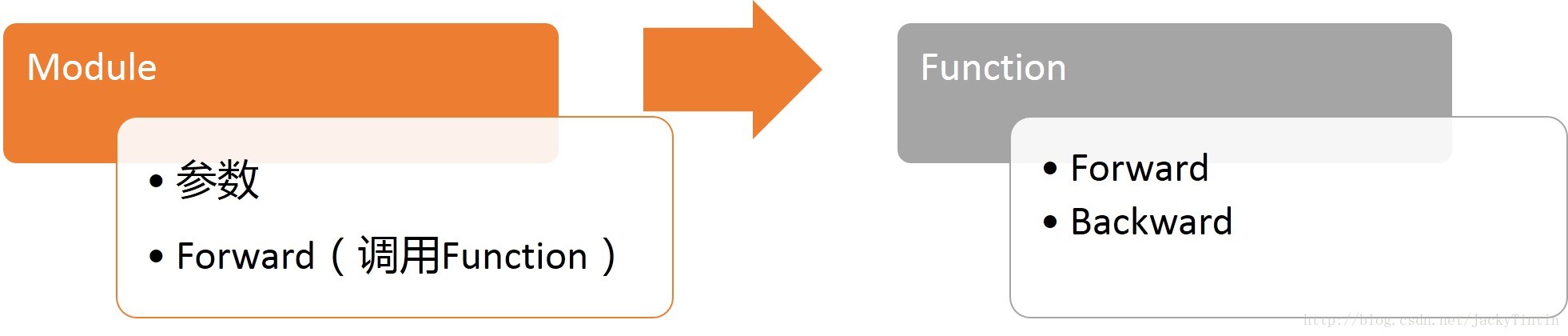
图3. pytorch Module
module 是 pytorch 组织神经网络的基本方式。Module 包含了模型的参数以及计算逻辑。Function 承载了实际的功能,定义了前向和后向的计算逻辑。
Module 是任何神经网络的基类,pytorch 中所有模型都必需是 Module 的子类。 Module 可以套嵌,构成树状结构。一个 Module 可以通过将其他 Module 做为属性的方式,完成套嵌。
注意:真到目前(04/2018),pytorch 这部分的接口都没稳定下来,下面的阐述已经和最新版本不一致,甚至不正确。在接口最终稳定之前,内容不再更新,请直接查阅 pytorch 的最新源码。
下面以最简单的 MLP 网络结构为例,介绍下如何实现自定义网络结构。完整代码可以参见repo。
2.1 Function
注:为支持高阶导数(i.e. 梯度的梯度),pytorch 0.2 收入新的定义 Function 的机制。如果不考虑高阶,旧的方法依然 work。
Function 是 pytorch 自动求导机制的核心类。Function 是无参数或者说无状态的,它只负责接收输入,返回相应的输出;对于反向,它接收输出相应的梯度,返回输入相应的梯度。
这里我们只关注如何自定义 Function。Function 的定义见源码。下面是简化的代码段:
class Function(object):
def forward(self, *input):
raise NotImplementedError
def backward(self, *g 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8083
8083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









