







简介
Dapper 是谷歌内部使用的分布式链路追踪系统。谷歌技术人员于 2010 年将 Dapper 的设计思想以及工程实践作为论文发表,后续大量分布式链路系统例如 Zipkin、Jeager、Tempo、Pinpoint、CAT,均能看到 Dapper 的影子。
1 为什么需要分布式链路追踪
现代互联网系统多运行在成千上万机器支撑的分布式系统之上,一个复杂的业务请求往往需要多个服务共同配合完成。如果系统异常或者响应特别慢,定位问题往往需要查看所有请求经过服务的日志,如同大海捞针非常耗费人力,并且只有经验丰富且对系统非常熟悉的开发人员才能够快速定位到问题。互联网项目分秒必争,快人一步就能击败竞争对手,而如果系统出现线上故障,故障每延续一秒都会造成巨大的经济损失并且极大的危害公司的声誉。
因此通过分布式链路追踪定位故障原因以及分析性能瓶颈是非常有必要的。Dapper在谷歌内部起初是一个纯粹的链路追踪工具,后期功能逐渐丰富成为了一个强大的监控平台。
2 Dapper 设计目标与实现思路
Dapper 的三大核心设计目标:
- 全面部署:只有全系统覆盖才能保证调用链路的完整性
- 低延迟:链路追踪无可避免会增加系统开销,影响系统性能,因此链路追踪应该尽量少的影响性能
- 应用级别透明(最困难):依赖业务代码串联链路是不切实际的,为了能高效快速的落地,一定要应用级别透明,减少集成的开发工作量
此外 Dapper 还希望能够以最快的速度收集到整条链路,并且提供可视化效果优秀的 UI 界面
Dapper 针对上述目标的核心实现思路:
- 通过控制采样率可以极大的减少延迟
- 通过将链路追踪的代码汇集到公告基础库,与业务系统无关联。前提是架构层面的统一,例如所有服务都使用同一套 RPC 框架
3 Dapper 总体设计
来看图1从而对链路追踪有个直观的了解,首先链路是一个树形结构。图中用户从前端 A 发起两个 RPC 调用后端服务 B 和服务 C,其中后端服务 C 又调用了服务 D 和服务E。图一示例中仅有 RPC 调用,根据实际情况 HTTP 、数据库、缓存、消息队列或者异步方法等调用都可以加入到链路中来。
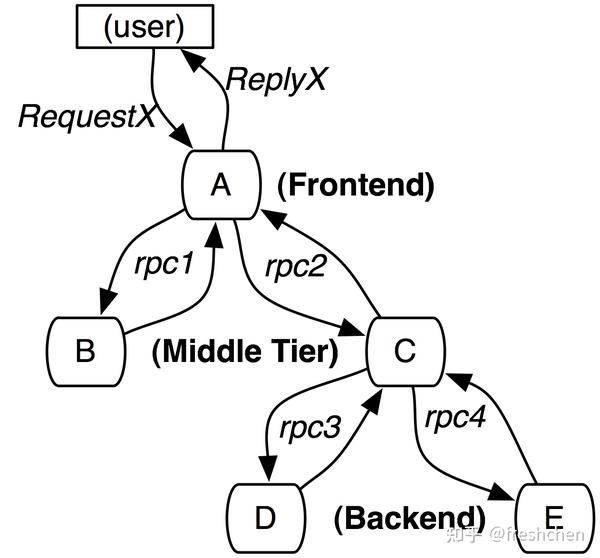

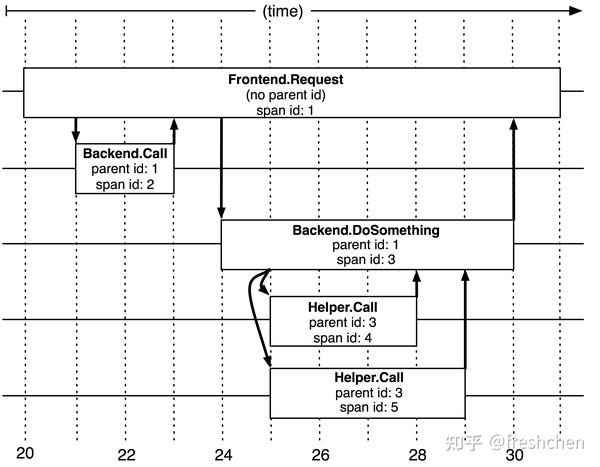
图1描述了服务调用的依赖关系,为了更好地分析性能还需要记录所有请求耗时等信息。此外图一是更利于理解,我们把调用链树称为 Trace。Trace 拥有全局唯一 traceId。Trace 上的每个节点也就是一次调用称为一个跨度Span,Span 也拥有全局唯一 spanId,Trace 的每条边表示 Span 之间的关系,每个 Span 需要将其父节点的 spanId 保存在 parentId 字段中,并且保存统一的 traceId。如图二所示更贴近计算机实现。并且从图二已经能很好的看出系统的耗时情况,也指导了追踪系统 UI 的设计。

3.1 跨度 Span
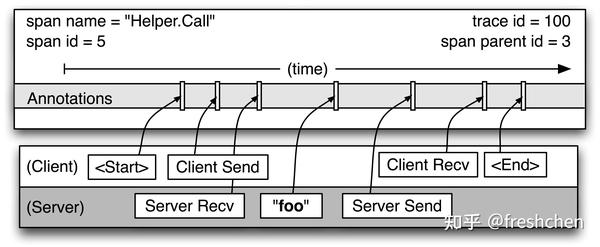
每个 Span 其实就是调用的一段精简的记录,如图三所示 Span 中保存的信息应该包含
- 上文中提到的 traceId,spanId 和 parentId。Dapper 中所有 ID 字段是全局唯一的 64 位整数
- 开始和结束的时间戳
- 一眼就能定位到调用的 Span 名
- 便于定位分析问题的特定应用注解补充信息
此外每个 Span 可能被提交两次,例如 A 调用 B,B 完成请求后会对进行上报,A 收到 B 的响应之后也会上报一次。根据 A 和 B 的角色我们把 A 上报的称为 client kind 的 span,B 上报的是 server kind 的span,且遵循客户端发起调用 happens before 服务端 server 接受请求的原则,以客户端上报的耗时为准。

3.2 仪表点 Instrumentation point
上面介绍了 span 的相关概念,那么谁来生成 span呢?仪表点就是 span 的生成器。仪表点往往实现在一个个业务无入侵的公共基础库中,例如 rpc-Instrumentation、http-Instrumentation、mysql-Instrumentation、redis-Instrumentation 等等。
公告基础库除了包含 span 的生成,还包含 span 信息的串联。
以服务调用为例,Dapper 会将 trace 相关信息的上下文记录在一个线程局部变量中,线程局部变量例如 Java 中的 ThreadLocal,对于 golang 来说就是 goroutine 的 context。 在服务调用时从 trace 上下文中取出数据通过 rpc 元数据,或者 http 请求头发送给服务接受方,如果时异步请求在回调的过程中,服务的接受方要将接收到的 trace 上下文与响应结果一起发送回服务调用方。
3.3 注解 Annotations
仪表点作为公告库类负责 span 核心数据的串联,有时业务接入方对于链路追踪有特殊需求,例如在 span 中增加用户ID这个条目来帮助快速定位问题。因此公共基础库中需要对 span 灵活方便的进行业务注解,但为了保证链路的正确性,如果业务方设置的注解和公共基础库中已有注解重复,仍然以公告基础库为准。
3.4 采样 Sampling
采样是分布式链路中非常重要的一环,如果接入了链路追踪,系统的性能,稳定性大幅下降,那么是很难得到业务方支持并落地的。因此需要支持由业务方指定接入哪些仪表点以及采样的比例,或者其他更灵活的采样控制方式。
3.5 链路的收集和存储
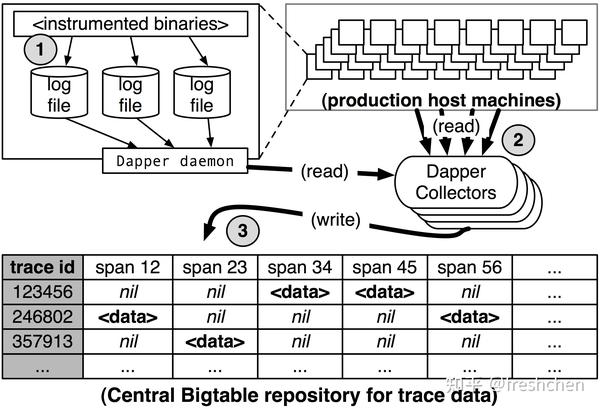
如图四所示:
- Dapper 所有的 span 统一形式记录到固定的日志文件中
- 每台机器上有守护进程负责将 span 推送到 Dapper 的收集器
- 收集器处理 span 信息,最后存储到 bigtable 中,一条行记录就是一个 trace,每一个字段表示一个 span,依赖 bigtable 的稀疏表功能,实际存储会对空的 span 进行压缩

3.6 安全性
Dapper 还被用于追踪服务是否安全,例如包含敏感数据信息的接口是否具有必要的鉴权,及时发现未经授权的系统调用。
4 Dapper 线上部署状态
- 上线后尽量减少变更:Dapper 最关键最核心的 Instrumentation 基础库代码量控制在千行内
- 简化部署:Instrumentation 被打在机器基础镜像中
- 递进地推广:支持通过配置关闭 Dapper,早期默认是关闭的,Dapper 团队会和关闭 Dapper 的团队沟通,大部分是担心性能损耗,经过一定时间的检验以及线上数据支撑,最终几乎所有业务线的 Dapper 都是打开状态了
5 Dapper 管理系统开销
虽然有人说链路追踪作为基础架构的一部分收益大于开销,是值得的。但还是应该把开销降到最低,并且证明开销确实可以忽略不计。
首先 Dapper 最大的开销分为两部分 1 trace 的生成 2 trace 的收集与分析
5.1 trace 生成开销控制
Trace 生成阶段主要影响业务系统的性能,表现在请求处理时间的增加。
Trace 生成阶段最大的开销是本地磁盘日志的写入。其次是 span 的生成和销毁,大约在 200 纳秒以内。
如果只做串联不写入磁盘日志,一台 2.2GHz x86 的机器平均耗时是 9 纳秒,开销几乎是忽略不计的。
对了减少开销,Dapper 采用批量的方式记录日志,减少 IO
5.2 trace 收集开销控制
Trace 收集阶段的开销主要是系统资源上的,守护进程会占用机器的 CPU 以及网络带宽。
Dapper 守护进程线上运行对机器资源的占用如图五所示:
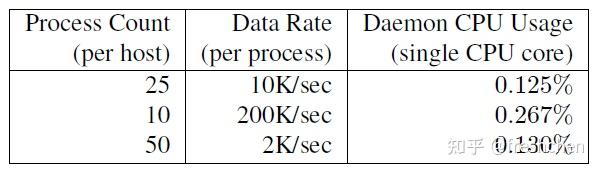

Dapper 守护进程具体采用了哪些措施减少开销
- 自身 CPU 调度优先级设置为最低
- 精简 Span 信息减少网络开销,每个 Span 平均 426 比特大小。实际数据显示 Dapper 仅仅占用谷歌 0.01% 的带宽
5.3 自适应采样
是否采样就是说是否将 span 记录日志文件并且收集,因此控制采样比例是控制开销效果最明显的方式。如图六所示,采样比例与系统的延迟以及吞吐量损耗是成正比的。虽然随着采样比例的增长变化不是很大,但由业务觉得采样率还是很有必要的
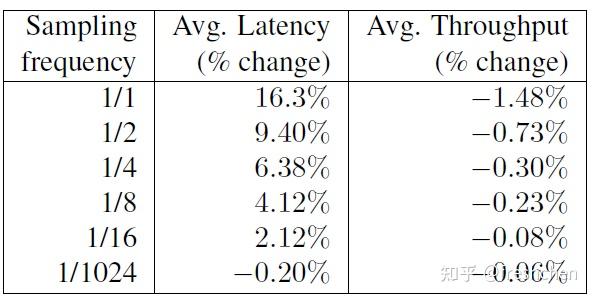

谷歌的系统流量非常的大,如果系统出现问题会被无限放大,换言之问题不会只出现一次,例如我们把采样率设置为 1%,某一类错误短时间内发生了 100次,那我们就大概率能记录下出错问题的链路。经过反复的推敲,对于当时的谷歌来说设置 1/1024 采样率的时就能够获得足够的信息。
但是概率毕竟是不确定的,如果业务系统不希望放过任何的问题请求,对性能的开销没有那么高的时候,或者另外一种情况例如系统本身的吞吐量不是很大时我们可以提高采样率。
因此谷歌对采样进行了优化,提出了自适应采样,Dapper 可以根据系统当前的负载,自动调整是否采样,采样的控制方式除了百分比还增加了单位时间的采样速率控制。
除了业务系统的指定,Dapper 在收集过程中还会进行二级采样控制,做法是对 traceId 散列,不满足要求的 trace 全部丢弃,从而控制全局的开销。
6 Dapper 通用工具
为了使 Dapper 更加易用,上手成本更小,Dapper 团队提供了一系列周边工具:
- 命令行操作工具
- 干净直观的界面
- ·支持 traceId 查询
- ·提供 api 支持自定义批量查询
- ·维护机器和trace的关系等索引信息,索引的存储成本很高,因此使用服务名+机器+时间戳的复合索引
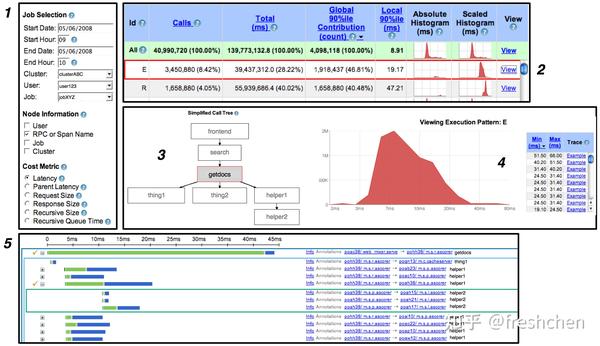
Dapper UI 界面如图七所示,后续多数分布式链路追踪系统的 UI 都以此作为参考

7 Dapper 在谷歌使用总结
- 通过 Dapper 可以帮助代码的后期维护人员发现很多不曾注意的细节
- 通过调用链发现系统的不合理之处,例如服务间隐蔽的循环依赖
- 如果做了读写分离,及早发现读请求是不是有被负载到写服务器上的情况
- 帮助新人理解业务
- 帮助bug问题定位
- 和其他监控系统集成,例如能才监控系统跳转到Dapper页面
- 找出 Top N 延迟的接口重点优化
- 基于 trace 绘制整体服务依赖网
- 基于 trace 进行网络流量的监控
- 对共享服务的不同客户使用程度进行了解















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









