







通过E-R图转换得出一组关系模式后
**选择1:**把一些关系模式合并为更大的关系 —— 会产生过多的数据冗余
inst_dept(ID, name, salary, dept_name, building, budget)
如果通过E-R模型转换得出如下两个关系模式
sec_class(sec_id, building, room_number) and
section(course_id, sec_id, semester, year)
那么在逻辑设计中,可以将上述两个关系合并为如下关系
section(course_id, sec_id, semester, year, building, room_number)
上述关系模式不会产生数据冗余
设计选择2:更小的模式?
如果通过E-R模型转换得出inst_dept关系模式,那么在逻辑设计中,我们可以将其分解为两个关系模式
instructor(ID, name, salary, dept_name)
department(dept_name, building, budget)
# 从而避免(building, budget)的数据冗余
如何知道该合并或分解关系模式呢?
- 可以通过保持如下一条规则:dept_name确定(building, budget)数据,即保持函数依赖:dept_name → building, budget
- 由于dept_name在inst_dept关系中不是主码,因此需要将其拆分为更小的关系模式
并不是所有的关系模式拆分是有益的
将employee(ID, name, street, city, salary)分解为
employee_attr1(ID, name)
employee_attr2(name, street, city, salary)
name无法作为employee_attr2关系的主码,有可能会重名
无法通过分解出的employee_attr1和employee_attr2重建(自然连接)得出原始关系
我们称无法通过自然连接重建原始关系元组的分解为有损分解 (lossy decomposition)
无损分解
R
=
(
A
,
B
,
C
)
R = (A, B, C)
R=(A,B,C)的分解
R
1
=
(
A
,
B
)
R
2
=
(
B
,
C
)
R1 = (A, B) \ R2 = (B, C)
R1=(A,B) R2=(B,C)
KaTeX parse error: Undefined control sequence: \join at position 18: …= \Pi_{A,B}(r) \̲j̲o̲i̲n̲ ̲\Pi_{B,C)(r)和 R ( A , B , C ) R(A,B,C) R(A,B,C)等价
函数依赖
假设
r
(
R
)
r(R)
r(R)是一个关系模式,
α
⊆
R
\alpha \sube R
α⊆R,
β
⊆
R
\beta \sube R
β⊆R, 模式R上的函数依赖
α
→
β
\alpha\rightarrow \beta
α→β
成立的条件是:如果对于任意关系实例r中任意两个元组t1 和t2,如果两者的属性(集)
α
\alpha
α取值相同, 那么它们的属性(集)
β
\beta
β取值也相同。也就是
t
1
[
α
]
=
t
2
[
α
]
⇒
t
1
[
β
]
=
t
2
[
β
]
t1[\alpha] = t2 [\alpha] \Rightarrow t1[\beta ] = t2 [\beta ]
t1[α]=t2[α]⇒t1[β]=t2[β]
称之为 α \alpha α函数确定 β \beta β, β \beta β函数依赖于 α \alpha α
假设r(A,B) 有如下关系实例
1 4
1 5
3 7
A → B A\rightarrow B A→B不成立,反之成立
函数依赖和码
➢ 超码:在某关系中,若一个或多个属性的集合
{
A
1
,
A
2
,
…
,
A
n
}
\{A_1, A_2,…, A_n\}
{A1,A2,…,An}函数决定该关系中的其它全部属性,则称该属性为该关系的超码
✓若属性组K满足K → R,则K 是关系模式R的超码
➢ 候选码:若集合
{
A
1
,
A
2
,
…
,
A
n
}
\{A_1, A_2,…, A_n\}
{A1,A2,…,An}的任何真子集均不能函数决定该关系中的其它属性,则此时
{
A
1
,
A
2
,
…
,
A
n
}
\{A_1, A_2,…, A_n\}
{A1,A2,…,An}是最小的超码,即候选码
✓ K → R 且不存在
α
⊂
K
\alpha \sub K
α⊂K, 满足
α
→
R
\alpha → R
α→R
➢ 外码:若关系模式R中属性或属性组X是另一关系模式的主码,则称X是R的外码
S(Sno,Sname,Sdept,Sage)
SC(Sno,Cno,G)
函数依赖允许我们表达超码不能表达的约束。考虑下面的模式:
i
n
s
t
d
e
p
t
(
I
D
‾
,
n
a
m
e
,
s
a
l
a
r
y
,
d
e
p
t
_
n
a
m
e
,
b
u
i
l
d
i
n
g
,
b
u
d
g
e
t
)
.
inst_dept (\underline{ID}, name, salary, dept\_name, building, budget).
instdept(ID,name,salary,dept_name,building,budget).
超码函数依赖:
ID → name, salary, dept_name, building, budget
函数依赖在关系实例和关系模式上的体现区别:
- 如果关系实例r在函数依赖集F上合法,则称r满足F
- 如果模式R上的所有合法关系实例都满足函数依赖集F,我们说F在关系模式R上成立
notice:即使函数依赖并没有对关系模式r®的所有合法实例成立,这个关系模式的其中一个具体实例r可能满足函数依赖
相关术语
有些函数依赖被称为平凡(trivial)的,因为它们在所有关系中都是满足的
• name → name
• ID, name → ID
如果
β
⊆
α
\beta\sube \alpha
β⊆α,
α
→
β
\alpha \rightarrow \beta
α→β是平凡的函数依赖
β
⊈
α
\beta\not\subseteq \alpha
β⊆α,
α
→
β
\alpha \rightarrow \beta
α→β则这个是非平凡的函数依赖
α
→
β
\alpha \rightarrow \beta
α→β 则
α
\alpha
α是决定因素
函数依赖
α
→
β
\alpha \rightarrow \beta
α→β 称为部分依赖的条件是:存在
α
\alpha
α的真子集γ,
使得
γ
→
β
γ→ \beta
γ→β
闭包
从给定函数依赖集F能够推导出的所有函数依赖的集合,我们称之为F集合的闭包
A
→
B
,
B
→
C
A\rightarrow B, B\rightarrow C
A→B,B→C
推出
A
→
C
A\rightarrow C
A→C
我们用
F
+
F^+
F+来表示函数依赖集F的闭包,是F的超集
- 给定关系模式r( R ),如果r( R ) 的每个满足F的 实例也满足某个函数依赖f,则R上的函数依赖f逻辑蕴含(logically imply)于r上的函数依赖集F
- 已知关系R上的函数依赖集T、F,如果对于该关系中满足F的每一个关系实例都满足T,称函数依赖集F 逻辑蕴含 函数依赖集T
- 若F蕴含于T,且T蕴含于F,则函数依赖集T和F是等价的,记为T≡F
推理规则
Armstrong公理:
- 如果 β ⊆ α \beta\sube \alpha β⊆α, , 则有 α → β \alpha \rightarrow \beta α→β (自反律)
- 如果 α → β \alpha \rightarrow \beta α→β, 则有 γ α → γ β \gamma\alpha \rightarrow \gamma\beta γα→γβ (增补律)
- 如果 α → β \alpha \rightarrow \beta α→β及 β → γ \beta \rightarrow \gamma β→γ, 则有 α → γ \alpha \rightarrow \gamma α→γ (传递律)
有效的:它们不会产生错误的函数依赖
完备的:对一个给定函数依赖集F,它们能产生整个F+
函数依赖证明(A → H):
已知A → B,根据函数依赖定义,可得:
对于任意元组t1, t2,如果t1[A] = t2[A],那么 t1[B]=t2[B]
已知B → H,同理可得:如果t1[B] = t2[B],那么 t1[H]=t2[H]
综上可得:如果t1[A] = t2[A],那么t1[H] = t2[H],即A → H得证
计算函数依赖集F的闭包算法:
repeat
for each F +中的函数依赖 f
在f上应用自反律和增补律
将结果加入到F +中
for each F +中一对函数依赖f1和 f2
if f1 和 f2 可以使用传递律结合起来
将结果加入到F +中
until F + 不再发生变化
附加定理:
若有
α
→
β
\alpha \rightarrow \beta
α→β 及
α
→
γ
\alpha \rightarrow \gamma
α→γ, 则有
α
→
γ
β
\alpha \rightarrow \gamma\beta
α→γβ (合并律)
若有
α
→
γ
β
\alpha \rightarrow \gamma\beta
α→γβ, 则有
α
→
β
\alpha \rightarrow \beta
α→β 及
α
→
γ
\alpha \rightarrow \gamma
α→γ (分解律)
若有
α
→
β
\alpha \rightarrow \beta
α→β及
β
γ
→
δ
\beta\gamma \rightarrow \delta
βγ→δ, 则有
α
γ
→
δ
\alpha\gamma \rightarrow \delta
αγ→δ (伪传递律)
给定属性集 α \alpha α, 我们称在函数依赖集F下由 α \alpha α函数确定的所有属性集合为F下 α \alpha α的闭包,记为 α + \alpha^+ α+
算法
result := α;
while (result发生变化) do
for each 函数依赖 β → γ in F do
begin
if β ⊆ result then result := result ∪ γ
end
闭包用途
属性闭包算法有多个用途:
- 超码的判断:
- 判断α 是不是超码,通过计算α+,看α+ 是否包含R中的所有属性
- 验证函数依赖:
- 要检验函数依赖α → β是否成立 (换句话说,是否在F +中), 只需要检验是否β ⊆ α+
- 也就是说,我们用属性闭包计算α+ ,看它是否包含β
- 是一个简单快速的验证方法,但是很有用
- 计算F的闭包:
- 对任意的γ ⊆ R, 我们找出闭包γ+;对任意的S ⊆ γ+, 我们输出一个函数依赖γ → S
规范化(Normalization)
一个数据库的描述对象包括:学生(Sno),系(Sdept)、系负责人(Name)、课程(Cname)和成绩(G)
U ={Sno, Sdept, Name, Cname, G}
FD ={ Sno->Sdept,Sdept->Name,(Sno,Cname)->G }
建立关系模式:S(Sno, Sdept, Name, Cname, G)
存在问题:
➢ 数据冗余
➢ 需要用空值来表示某些信息
可以将S分解为三个关系模式:
S(Sno, Sdept)
SG(Sno, Cname, G)
Dept(Sdept, Name)
假设R是关系模式,具有函数依赖集F
在关系模式不是“好”的模式的情况下,将其分解成
关系模式集
{
A
1
,
A
2
,
…
,
A
n
}
\{A_1, A_2,…, A_n\}
{A1,A2,…,An}
- 每个关系模式都是好的模式:无数据冗余(符合一定范式,例如BCNF)
- 分解是无损连接分解
- 最好的是,分解是保持依赖的(p225)
各种范式之间包含关系如下
1
N
F
⊃
2
N
F
⊃
3
N
F
⊃
B
C
N
F
⊃
4
N
F
⊃
5
N
F
1NF \supset 2NF \supset 3NF \supset BCNF \supset 4NF \supset 5NF
1NF⊃2NF⊃3NF⊃BCNF⊃4NF⊃5NF
某一关系模式R最高属于第n范式,可简记为R∈nNF
第一范式
如果某个域的元素被认为是不可分的单元,那么这个域就是原子的
✓非原子域的例子:
• 复合属性(E-R模型)
• 类似于CS101的ID(只要数据库应用没有将CS标识号拆开并解析为系的缩写,那么可认为是原子的)
如果一个关系模式R的所有属性域都是原子的,我们称关系模式R属于第一范式
非原子的值会造成复杂存储及数据冗余
第二范式
例: 关系模式 SLC(S#, SD, SL, C#, G)
SL为学生住处,假设每个系的学生住在同一个地方
SD为学生所在系,假设每个学生属于一个系
若存在如下函数依赖
{
(
S
#
,
C
#
)
→
f
G
;
(
S
#
,
C
#
)
→
P
S
D
;
S
D
→
S
L
;
(
S
#
,
C
#
)
→
P
S
L
}
\{ (S\#,C\#) \mathop{\rightarrow}\limits^{f}G; (S\#,C\#) \mathop{\rightarrow}\limits^{P}SD; SD\rightarrow SL; (S\#,C\#) \mathop{\rightarrow}\limits^{P}SL \}
{(S#,C#)→fG;(S#,C#)→PSD;SD→SL;(S#,C#)→PSL}
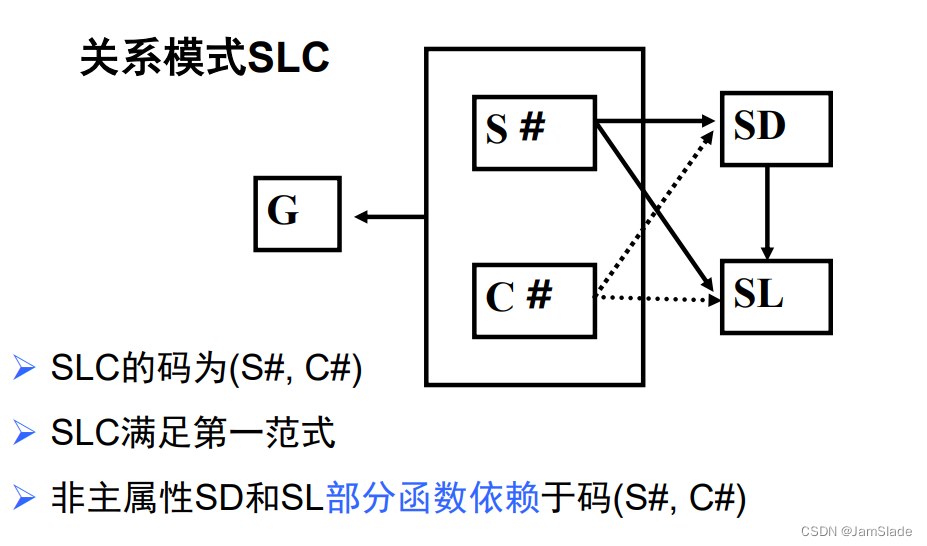
SLC (S#, SD, SL, C#, G)分解为
两个关系模式:
S
C
(
S
#
‾
,
C
#
‾
,
G
)
S
L
(
S
#
‾
,
S
D
,
S
L
)
SC(\underline{S\#}, \underline{C\#}, G) SL(\underline{S\#}, SD, SL)
SC(S#,C#,G)SL(S#,SD,SL)
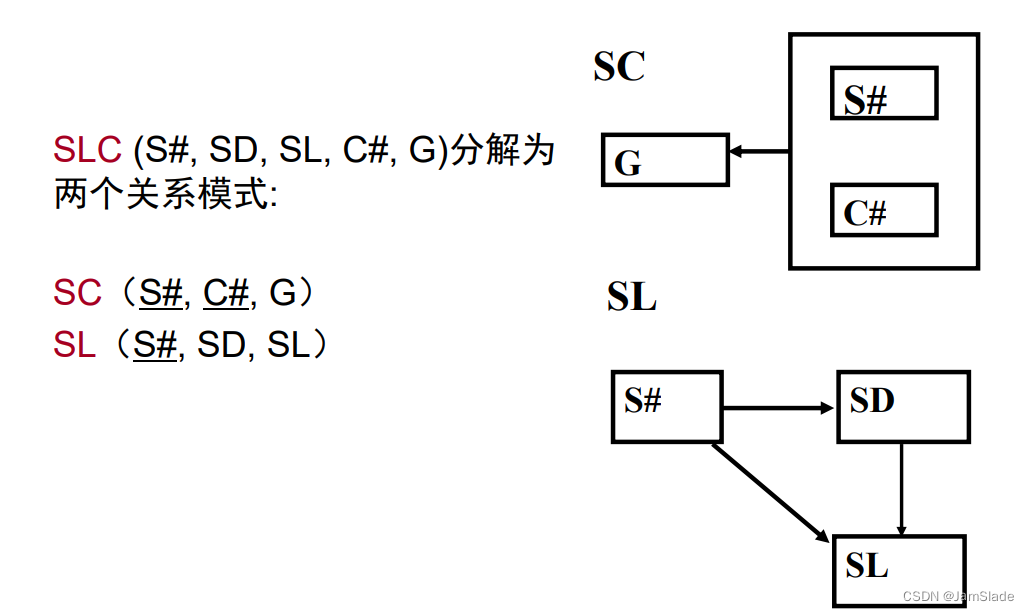
2NF的定义
若关系模式R∈1NF,且在F+中每一个非主属性完全函数依赖于候选码,则R∈2NF
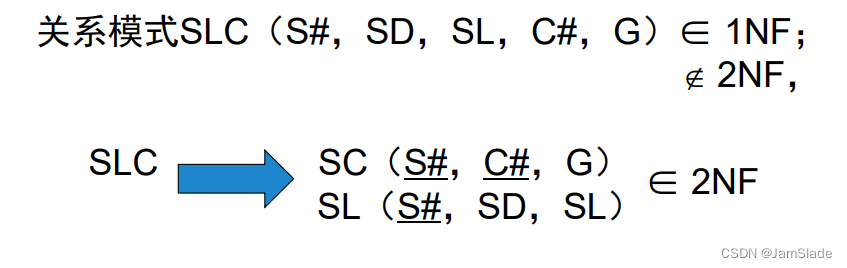
Boyce-Codd范式 BCNF
具有函数依赖集F的关系模式R属于BCNF的条件是:对所有F+中形如 α → β \alpha \rightarrow \beta α→β的函数依赖( β ⊆ R \beta \subseteq R β⊆R且 α ⊆ R \alpha \subseteq R α⊆R ),下面至少有一个成立:
- α → β \alpha \rightarrow \beta α→β是平凡函数依赖
- α \alpha α是模式R的一个超码
不属于BCNF的模式的例子:
i
n
s
t
_
d
e
p
t
(
I
D
‾
,
n
a
m
e
,
s
a
l
a
r
y
,
d
e
p
t
_
n
a
m
e
,
b
u
i
l
d
i
n
g
,
b
u
d
g
e
t
)
inst\_dept (\underline{ID}, name, salary, dept\_name, building,budget)
inst_dept(ID,name,salary,dept_name,building,budget)
因为 dept_name → building, budget 在inst_dept上成立,但是 dept_name 不是超码
另一个判定标准:
另一个判定准则:在关系模式R(U, F)中,如果F+中的每一个非平凡 函数依赖的 决定属性集都包含候选码(即为超码),则
r
(
R
)
∈
B
C
N
F
r(R)∈BCNF
r(R)∈BCNF
BCNF范式:排除了任何属性(包括主属性和非主属性)对候选码的部分依赖和传递依赖,也排除了主属性之间的传递依赖
例子
- r( R)=r(A,B,C), F={ A->B,B->C }.
r( R)的候选码为A
r ( R ) ∉ B C N F r(R) ∉ BCNF r(R)∈/BCNF - r( R)=r(A,B,C),F={ AB->C,C->A }.
r( R)的候选码为AB和BC
r ( R ) ∉ B C N F r(R) ∉ BCNF r(R)∈/BCNF - r( R)=r(A,B,C),F={ AB->C,BC->A }.
r( R)的候选码为AB和BC
r ( R ) ∈ B C N F r(R) ∈ BCNF r(R)∈BCNF
假设有模式R,及其一个非平凡依赖
α
→
β
\alpha \rightarrow \beta
α→β 不属于BCNF,那么我们可以将R分解成:
(
a
∪
β
)
和
(
R
−
(
β
−
α
)
)
(a\cup \beta) 和 (R-(\beta - \alpha))
(a∪β)和(R−(β−α))
inst_dept的例子中
α = dept_name
β = building, budget
inst_dept 被以下两个模式取代
( dept_name, building, budget )
( ID, name, salary, dept_name )
有可能分解完之后仍有关系模式不符合BCNF,那么continue
保持依赖
检查包括各种约束(码、check子句、函数依赖、断言等)的开销是很大的,但是如果只涉及到单个关系,检查约束的开销相对较低
然而,BCNF分解会妨碍某些函数依赖的高效检查
如果F上的每一个函数依赖都在其分解后的一个关系上成立,那么这个分解是保持依赖的
因为通常无法同时实现BCNF和保持依赖,因此我们考虑另外一种范式,它比BCNF宽松,允许我们保持依赖,称为第三范式
第三范式
具有函数依赖集F的关系模式R属于第三范式(3NF)的条件是:对F+ 中所有形如 → 的函数依赖中,至少有以下之一成立
- α → β \alpha \rightarrow \beta α→β 是一个平凡的函数依赖
- α 是R的一个超码
- β - α 中的每个属性A都包含在R的候选码中
(注意: 每个属性也许包含在不同的候选码中
➢ 第三个条件是BCNF的一个最小放宽:即允许存在主属性对候选码的传递依赖和部分依赖,在函数依赖集F中用来满足保持某些函数依赖
等价定义
关系模式R(U, F)中,若不存在这样的码X、属性组Y及非主属性Z(
Z
⊈
Y
Z\not\sube Y
Z⊆Y)使得
X
→
Y
X\rightarrow Y
X→Y(
Y
↛
X
,
Y
↛
X
,
Y
→
Z
Y\not\rightarrow X, Y\not\rightarrow X, Y\rightarrow Z
Y→X,Y→X,Y→Z),则称
R
(
U
,
F
)
∈
3
N
F
R(U,F)\in 3NF
R(U,F)∈3NF
具有属性依赖集F的关系模式R属于3NF,则R张任何非主属性A不部份依赖与码也不传递依赖于R的码

在关系模式SJP(S,J,P)中,S表示学生,J表示课程, P表示名次。存在函数依赖集F:{(S,J)→P,(J,P)→S}
候选码: (S,J), (J,P)
S, J, P都是主属性
因为: 没有非主属性部份依赖或传递依赖于候选码
所以: STJ ∈ 3NF
因为:对于F任意一个 X → Y,X都是候选码
所以:STJ ∈ BCNF
例:在关系模式STJ(S,T,J)中,S表示学生,T表示教师,J表示课程。存在如下函数依赖:
每一教师只教一门课;某一学生选定某门课,就确定了一位授课教师;某个学生选修某个教师的课就确定了所选课的名称(假设)F={T→J,(S,J)→T,(S,T)→J}
∵ (S,J)和(S,T)都是候选码
∴ S、T、J都是主属性
∵ 没有非主属性部分依赖或传递依赖于候选码
∴ STJ∈3NF
∵ T→J,T是决定属性集,T不是候选码
∴ STJ \not ∈ BCNF
解决方法:将STJ分解为二个关系模式:
TJ(T,J) ∈ BCNF, ST(S,T) ∈ BCNF
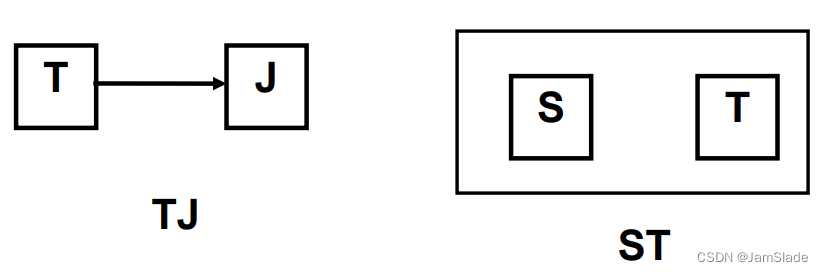
原始函数依赖(S,J)→T,(S,T)→J 在该符合BCNF的关系模式中无法保持
BCNF足够优秀吗?
考虑一个关系模式
inst_info (ID, child_name, phone)
其中,一个instructor可以有多个children和多个phone
由于该关系模式中只有平凡的函数依赖关系存在,因此其属于BCNF
然而该BCNF模式仍存在由多值依赖(p238)造成的信息冗余:如果需要为99999教师增加一个电话号码981-992-3443,那么需要增加两条元组,如下
(99999, David, 981-992-3443)
(99999, William, 981-992-3443)
可以将inst_info关系模式分解为两个关系模式
inst_child(ID, child_name)
inst_phone(ID, phone)
因此,需要更为严格的范式来规范关系模式,如4NF
函数依赖理论
正则覆盖
函数依赖集可能存在冗余依赖(这些依赖可以从其他依赖中推导出来)
在 {A → B, B → C, A→C }中A → C是冗余的
函数依赖集的一部分也可能是冗余的
如: {A → B, B → C, A → CD }
可以简化成 {A → B, B → C, A → D }
如: {A → B, B → C, AC → D }
可以简化为 {A → B, B → C, A → D }
直观上,F的正则覆盖
F
c
F_c
Fc没有任何冗余依赖或存在冗余部分的依赖
F
c
F_c
Fc具有和F相同的函数依赖集闭包。其意义在于:验证
F
c
F_c
Fc比验证F更加容易、3NF算法必备
无关属性
如果去除函数依赖中的一个属性不改变该函数依赖集的闭包,则称该属性是无关属性(extraneous)
形式化定义:考虑函数依赖集F及F中函数依赖 α → β
- 如果A ∈ α并且F逻辑蕴涵(F – {α→ β}) ∪ {(α – A)→β},则属性A在α 中是无关的
- 如果A ∈ β并且函数依赖集(F – {α→β}) ∪ {α→(β–A)} 逻辑蕴涵F,则属性A在β中是无关的
eg: 给定 F = {A → C, AB → C}
- B 是AB → C中的无关属性,因为 {A → C, AB → C}逻辑蕴涵A → C (即从 AB → C中去掉B后的结果)
eg: 给定 F = {A → C, AB → CD}
- C是AB → CD中的无关属性
验证方法
考虑函数依赖集F及F中的函数依赖α → β.
验证属性A ∈ α 是不是多余的
- 使用F中的函数依赖计算属性集闭包 ( α – A ) + (\alpha –A)^+ (α–A)+
- 验证 ( α – A ) + (α –A)^+ (α–A)+ 是否包含β;如果包含,那么A 是多余属性
验证属性A ∈ β 在 β 中是否多余
- 使用函数依赖集F’= (F –{α → β}) ∪ {α →(β–A)}计算 α + \alpha^+ α+
- 验证 α + \alpha^+ α+ 是否包含A;如果包含,那么A 在α中是多余属性
正则覆盖
计算F的正则覆盖算法:首先,初始化Fc= F;
repeat
使用合并律将Fc中的形如α1 → β1 及 α1 → β2 的依赖替换为 α1 → β1β2
在Fc中找出 在α或中含无关属性的函数依赖α → β
/* 注意:使用Fc而不是F检验无关属性*/
若发现无关属性
则将它从Fc中的α → β中删除
until Fc 不再发生变化
注意:在删除了某些无关属性后可能需要使用合并律,因此合并律会重复应用
F的正则覆盖Fc是一个函数依赖集 ,具有如下特性:
- F 逻辑蕴涵Fc中的所有函数依赖
- Fc逻辑蕴涵F中的所有函数依赖
- Fc中任何函数依赖都不含无关属性
- Fc中函数依赖的左半部都是不同的
R = (A, B, C)
F = { A → BC,B → C,A → B,AB → C }
✓合并 A → BC 和 A → B ,形成 A → BC
修改Fc1为{ A → BC, B → C, AB → C }
✓A在AB → C中是无关属性
利用Fc1检验(AB-A)+是否包含C
包含,则修改Fc2为{ A → BC, B → C }
✓C在A → BC中是无关属性
计算F’{A → B, B → C}下A+闭包是否包含C
包含,则修改Fc3为{A → B, B → C}
正则覆盖是
A
→
B
B
→
C
A\rightarrow B\\ B\rightarrow C
A→BB→C
无损分解
对于R = (R1, R2), 我们要求模式R上的所有可能关系r都有
r
=
Π
R
1
(
r
)
⋈
Π
R
2
(
r
)
r=\Pi_{R1}(r) \Join \Pi_{R2}(r)
r=ΠR1(r)⋈ΠR2(r)
如果下面的依赖中至少有一个属于
F
+
F^+
F+,那么将R分解成 R1 和R2 是无损分解连接:
R
1
∩
R
2
→
R
1
R
1
∩
R
2
→
R
2
R1 \cap R2 → R1\\ R1 \cap R2 → R2
R1∩R2→R1R1∩R2→R2
即 R1 ∩ R2 是R1或R2的超码
上述函数依赖测试只是无损连接分解的一个充分条件;只有当所有约束都是函数依赖时,它才是必要条件(某些情况下,即使不存在函数依赖的情况下,仍可保证一个分解是无损分解)
eg
R = ( A, B, C )
F = { A → B, B → C }
// 可以通过两种方式分解
1.
R1 = (A, B), R2 = (B, C)
无损连接分解:
R1 ∩ R2 = { B }
B→ BC
2.
R1 = (A, B), R2 = (A, C)
无损连接分解:
R1 ∩ R2= { A }
A → AB
保持依赖
F为模式R上的一个函数依赖集,R1,R2, … , Rn为R的一个分解。F在Ri上的限定是 F + F^+ F+中所有只包含Ri中属性的函数依赖的集合Fi
方法一(图8-10):令 F ’ = F 1 ∪ F 2 ∪ … ∪ F n F’ = F_1 \cup F_2 \cup … \cup F_n F’=F1∪F2∪…∪Fn。 F’ 是模式R上的一个函数依赖集
- 如果下面的式子成立,那么分解是保持依赖的
( F ’ ) + = F + (F’ )^+ = F^+ (F’)+=F+ - 称具有性质 ( F ’ ) + = F + (F’ )^+ = F^+ (F’)+=F+的分解为保持依赖的分解
方法二(充要条件):当R分解成R1, R2, …, Rn后,应用以下算法,验证F中每一个函数依赖α → β 是否被保持:
result = α
while (result发生变化) do
for each 分解后的Ri
t =((result ∩ Ri)^+) ∩ Ri
result = result ∪ t
- 如果result 包含β中的所有属性,那么函数依赖 α → β 被保持
- 可以将这个验证应用到所有F中的依赖,来验证这个分解是否保持依赖
- 方法的好处:没有计算F在Ri上的限定并使用它计算result 的属性闭包,而是使用F上(result ∩ Ri)上的属性闭包得到一个相同的结果`
eg
R = (A, B, C)
F = {A → B, B → C}
// 可以通过两种方式分解
R1 = (A, B), R2 = (B, C)
无损连接分解: 保持依赖
R1 ∩ R2 = {B} and B → BC
R1 = (A, B), R2 = (A, C)
无损连接分解: 不保持依赖
R1 ∩ R2 = {A} and A → AB
(不计算R1 \Join R2, 无法验证B →C)
分解算法
对于 F + F^+ F+中非平凡依赖 α → β \alpha\rightarrow \beta α→β验证是否违反BC范式
- 计算 α + \alpha^+ α+
- 检验是否包含R的所有属性,验证是否是R的超码
检查R是否属于BCNF,检查F的函数依赖是否违反BCNF(如果F中没有违反BCNF的函数依赖,那么F+中也不会有违反BCNF的函数依赖)
在检测由关系R分解后的关系Ri是否满足BCNF范式时,只使用F是不正确的
R = (A, B, C, D, E), F = { A → B, BC → D}
• 将R 分解成R1 = (A,B) 和 R2 = (A,C,D, E)
• F中没有一个依赖仅包含来自(A,C,D,E)的属性,所以我们可能误认为R2满足BCNF
• 事实上,F+中有一个函数依赖AC → D,这表明R2不属于BCNF
检查R分解后的关系Ri是否属于BCNF
- 使用F在Ri上的限定检测 R i R_i Ri是否满足BCNF (即, F + F^+ F+中只包含 R i R_i Ri中的属性的FD)
- 使用R中成立的原来的依赖集F 进行以下测试
- 对每个属性集 α ∈ R i \alpha \in R_i α∈Ri, 确保 α + \alpha^+ α+(在F下的)要么不包含 R i − α R_{i} - \alpha Ri−α的任何属性,要么包含 R i R_i Ri的所有属性
- 如果F中的某些函数依赖
α
→
β
\alpha\rightarrow \beta
α→β违反了该条件,那么
如下函数依赖出现在F+中: α → ( α + − α ) ∩ R i \alpha\rightarrow (\alpha^+-\alpha) \cap R_i α→(α+−α)∩Ri则Ri违反了BCNF

我们将关系模式R分解成:
- ( α ∪ β ) (\alpha \cup \beta ) (α∪β)
- ( R − ( β − α ) ) ( R - ( \beta - \alpha ) ) (R−(β−α))
α
\alpha
α = dept_name
β
\beta
β = building, budget
inst_dept
- ( α ∪ β ) (\alpha \cup \beta ) (α∪β) = ( dept_name, building, budget )
- ( R − ( β − α ) ) ( R - ( \beta - \alpha ) ) (R−(β−α)) = ( ID, name, salary, dept_name )
example
class (course_id, title, dept_name, credits, sec_id, semester, year, building, room_number, capacity, time_slot_id)
# 函数依赖
course_id → title, dept_name, credits
building, room_number → capacity
course_id, sec_id, semester, year → building, room_number, time_slot_id
候选码{course_id, sec_id, semester, year}.
分析:
course_id→ title, dept_name, credits 不符合BCNF要求
但是 {building, room_number} 不是class-1的超码
拆成三部分
R = (J, K, L )
F = {JK → L, L → K }
两个候选码:JK 和JL
✓R 不满足BCNF
✓R 满足3NF
✓R 的任何分解都不可能保持
J
K
→
L
JK → L
JK→L
✓这意味着要验证 JK → L 需要连接操作
✓BCNF分解可能无法做到保持依赖
✓能够有效的验证更新是否违反函数依赖很重要
解决方法:采用一个稍弱的范式,第三范式
- 允许冗余(会引起问题)
- 但是函数依赖可以在不进行连接操作的情况下在单个关系上检验
- 总是能够在无损连接及保持依赖的情况下分解成3NF
关系dept_advisor:
dept_advisor (s_ID, i_ID, dept_name)
F = { s_ID, dept_name → i_ID, i_ID → dept_name }
- 两个候选码: s_ID, dept_name, 和 i_ID, s_ID
- R 是3NF
- s_ID, dept_name → i_ID
- s_ID,dept_name 是超码
- i_ID → dept_name
- β − α \beta - \alpha β−α= dept_name 在一个候选码中
冗余覆盖
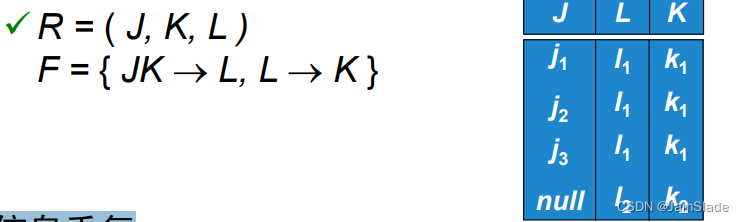
➢ 信息重复
- R中( l1, k1)
- dept_advisor中(i_ID, dept_name)
➢ 需要使用空值
- R中没有对应l2, k2的J值.
- dept_advisor (s_ID,i_ID, dept_name) 没有学生信息时

cust_banker_branch = (customer_id, employee_id, branch_name, type)
函数依赖是:
1. customer_id, employee_id → branch_name, type
2. employee_id → branch_name
3. customer_id, branch_name → employee_id
计算正则覆盖
✓ 1
st 依赖中是branch_name多余的
✓ 没有其他冗余属性,所以得到 FC =
customer_id, employee_id → type
employee_id → branch_name
customer_id, branch_name → employee_id
产生下面的3NF模式:
(customer_id, employee_id, type) <- primary key(c_id, e_id)
(employee_id, branch_name) <- primary key(e_id)
(customer_id, branch_name, employee_id)<- primary key(c_id, b_name)
(customer_id, employee_id, type ) 包含了原模式的一个候选码,因此没有其他关系模式需要添加
检测并删除类似(employee_id, branch_name)的模式,这个模式是其它模式的子集
由此产生的简化3NF模式为:
(customer_id, employee_id, type)
(customer_id, branch_name, employee_id)
BC和3的比较
BCNF和3NF的比较
➢ 总能够把一个关系分解为多个满足3NF的关系,并且:
✓分解是无损的
✓保持依赖
✓可能存在信息冗余
➢ 总能够把一个关系分解为多个满足BCNF的关系,并且:
✓分解是无损的
✓可能不满足保持依赖
➢ 关系数据库设计目标:
✓BCNF
✓无损
✓保持依赖
➢ 如果不能同时达到上述三个目标,选择接受下面的其中一个
✓缺少保持依赖
✓使用3NF,可能带来冗余
➢ 除了可以通过用主码外,SQL不提供指定函数依赖的途径.
特殊的FD可以使用断言,但是测试代价太高(目前不被大多
数数据库所支持)
➢ 即使我们能够得到保持依赖的分解,使用SQL 还是不能有效
地测试一个左边不是主码的函数依赖
review
➢什么是有损分解、无损分解?
➢什么是原子域和第一范式?
➢什么是函数依赖?
➢什么是BCNF和3NF?
➢什么是逻辑蕴含?函数依赖集的闭包、属性集
的闭包、正则覆盖?
➢如何将一个关系模式分解为属于BCNF、3NF
的关系模式


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









