







打破模态壁垒:基于多模态大型语言模型的通用嵌入学习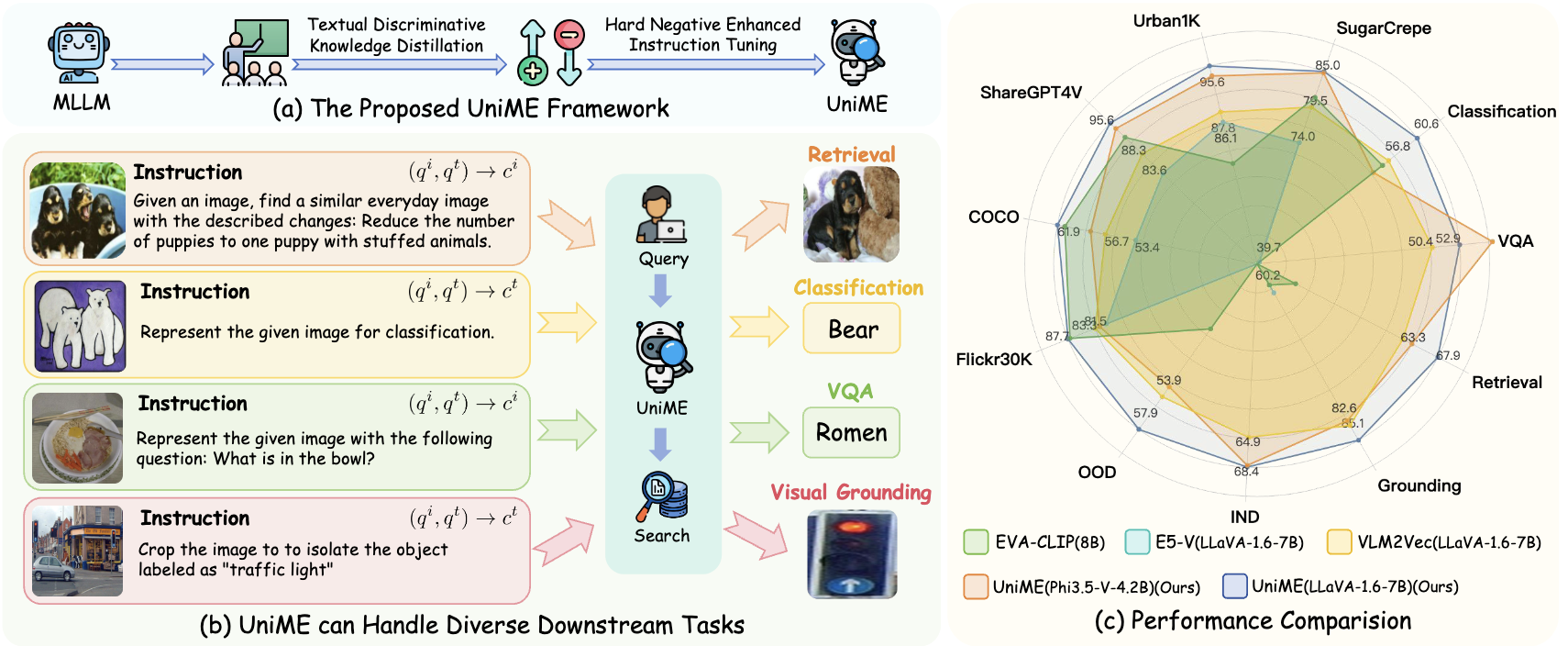
Tiancheng Gu*,
Kaicheng Yang*,
Ziyong Feng,
Xingjun Wang,
Yanzhao Zhang,
Dingkun Long,
Yingda Chen,
Weidong Cai,
Jiankang Deng
🏡 项目主页 | 📄 论文 | 🤗 UniME | 🤗 UniME(LLaVA-v1.6-7B)
🎺 新闻
2025/04/24: ✨UniME 的论文已提交至 arxiv。
[2025/04/22]: ✨我们在 🤗 Huggingface 发布了 UniME 的模型权重。
💡 亮点
为了增强 MLLM 的嵌入能力,我们提出了文本判别性知识蒸馏。训练过程包括解耦 MLLM 的 LLM 组件,并使用提示“用一个词总结以上句子。”处理文本,然后通过批次相似度分布上的 KL 散度对学生(MLLM)和教师(NV-Embed V2)嵌入进行对齐。值得注意的是,在此过程中仅对 LLM 组件进行微调,而所有其他参数保持冻结。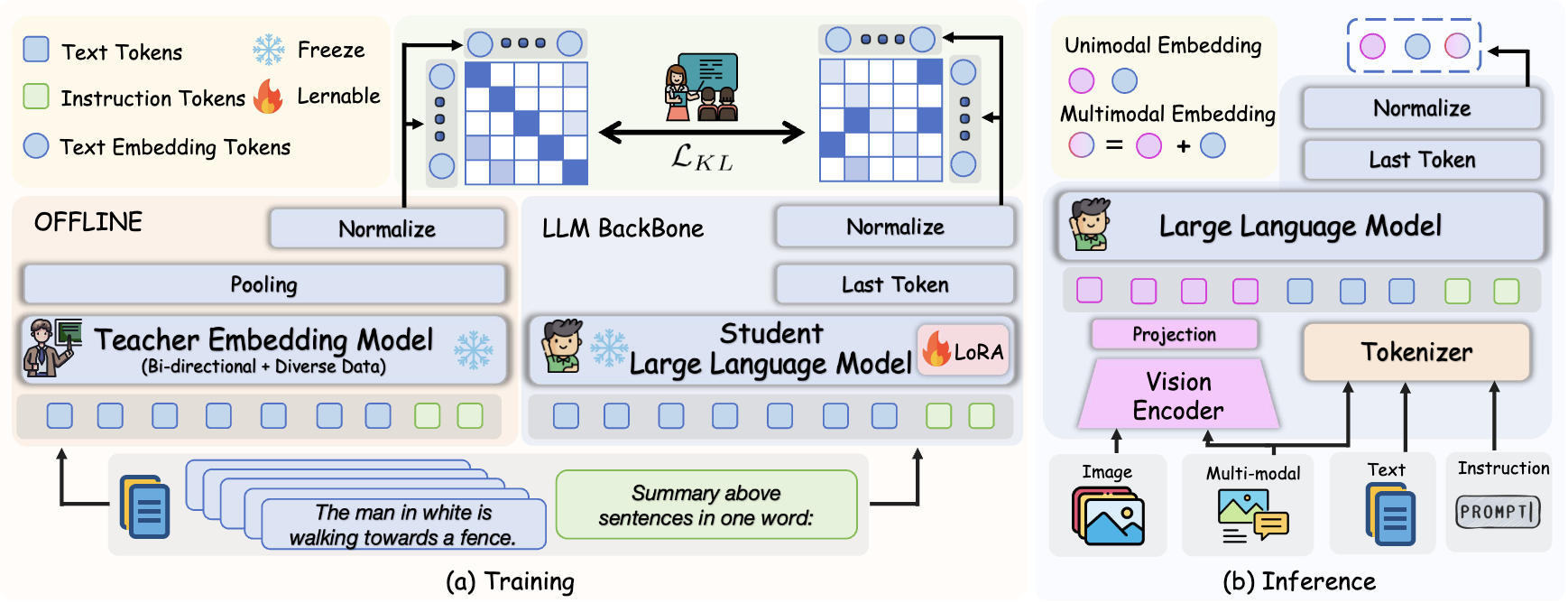
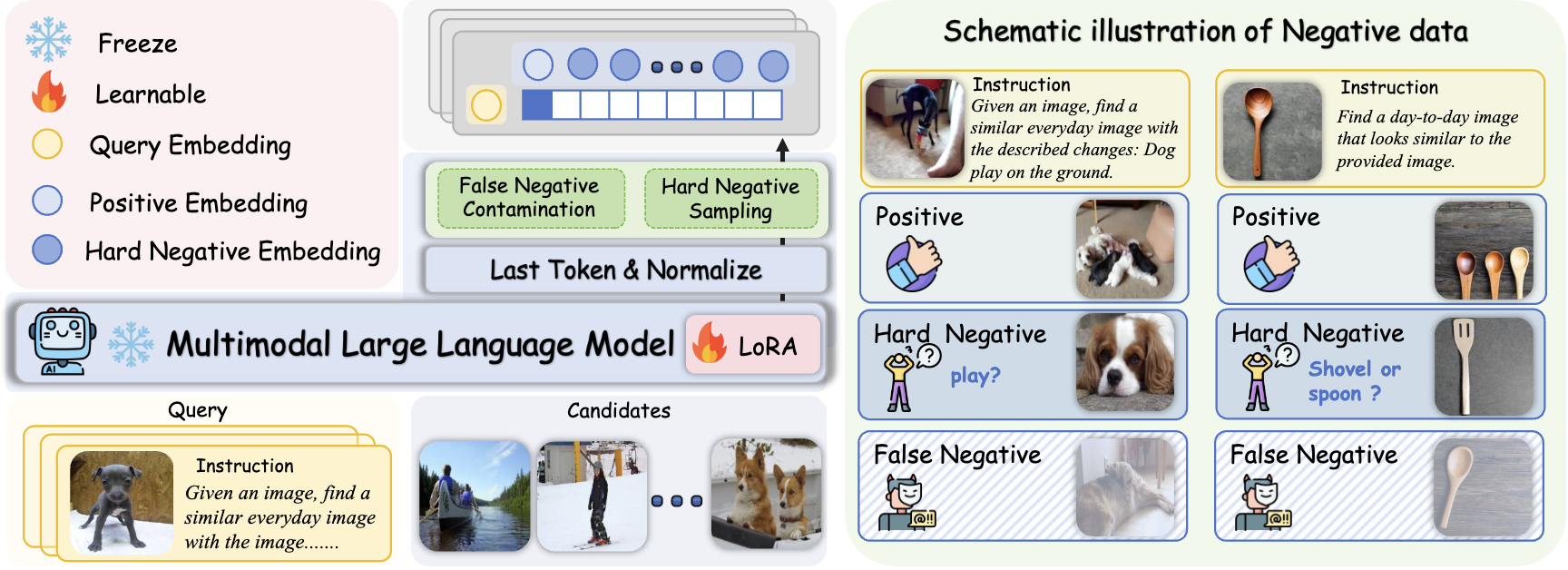
之后,我们提出了硬否定增强指令微调,通过提高视觉敏感性、加强跨模态对齐和增强指令遵循能力来改进多模态系统。其核心是两个关键创新:一个使用相似度阈值过滤假阴性以消除误导性样本的机制,以及一个自动硬否定采样策略,该策略选择 top-k 个相似但不匹配的示例来增加训练难度。
📗 环境
conda create -n uniME python=3.10 -y
conda activate uniME
pip install -r requirements.txt
🧭 快速开始
git clone https://github.com/deepglint/UniME.git
cd UniME
import torch
from PIL import Image
from torch.nn import functional as F
from self_evaluate.utils.utils import init_model_and_transform
model_name = "phi35V"
base_model_path="DeepGlint-AI/UniME-Phi3.5-V-4.2B"
# model_name = "llava_16"
# base_model_path="DeepGlint-AI/UniME-LLaVA-1.6-7B"
if model_name == "phi35V":
img_prompt = '<|user|>\n<|image_1|>\nSummary above image in one word: <|end|>\n<|assistant|>\n'
text_prompt = '<|user|>\n<sent>\nSummary above sentence in one word: <|end|>\n<|assistant|>\n'
elif model_name == "llava_16":
img_prompt = "[INST] <image>\nSummary above image in one word: [/INST]"
text_prompt = "[INST] <sent>\nSummary above sentence in one word: [/INST]"
text = "A man is crossing the street with a red car parked nearby."
image_path = "figures/demo.png"
input_texts = text_prompt.replace('<sent>', text)
input_image_prompt = img_prompt
input_image = [Image.open(image_path)]
model, transform = init_model_and_transform(model_name, base_model_path)
inputs_text = transform(text=input_texts,
images=None,
return_tensors="pt",
padding=True)
for key in inputs_text: inputs_text[key] = inputs_text[key].to("cuda")
inputs_image = transform(text=input_image_prompt,
images=input_image,
return_tensors="pt",
padding=True).to("cuda")
with torch.no_grad():
emb_text = model(**inputs_text, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
emb_image = model(**inputs_image, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
emb_text = F.normalize(emb_text, dim=-1)
emb_image = F.normalize(emb_image, dim=-1)
Score = emb_image @ emb_text.T
print("Score: ", Score) # Score: 0.59
🌡️ 评估
多样化检索 (Diverse Retrieval)
- 请按照 Flickr, CoCo, ShareGPT4V, Urban1k, SugarCrepe 准备数据。
- 编辑 “self_evaluate/utils/data_path.py” 中的数据路径。
# Phi35V
bash shell/test_Phi35V.sh
# LLaVA1.6-mistral
bash shell/test_LLaVA16.sh
MMEB
- 遵循 MMEB
git clone https://github.com/TIGER-AI-Lab/VLM2Vec.git
cd VLM2Vec
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/
cd VLM2Vec
#! Don't forget to edit data path
##### Phi35v
mkdir ../evaluate_results/uniME_phi35V/
python eval.py --model_name ../models/uniME_phi35V \
--model_backbone phi3_v \
--encode_output_path ../evaluate_results/uniME_phi35V/ \
--num_crops 4 --max_len 256 \
--pooling last --normalize True \
--dataset_name TIGER-Lab/MMEB-eval \
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211 \
--dataset_split test --per_device_eval_batch_size 16 \
--image_dir eval_images/
##### llava16
mkdir ../evaluate_results/uniME_llava_16/
python eval.py --model_name ../models/uniME_llava_16 \
--model_backbone llava_next \
--encode_output_path ../evaluate_results/uniME_llava_16/ \
--num_crops 4 --max_len 4096 \
--pooling last --normalize True \
--dataset_name TIGER-Lab/MMEB-eval \
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211 \
--dataset_split test --per_device_eval_batch_size 16 \
--image_dir eval_images/
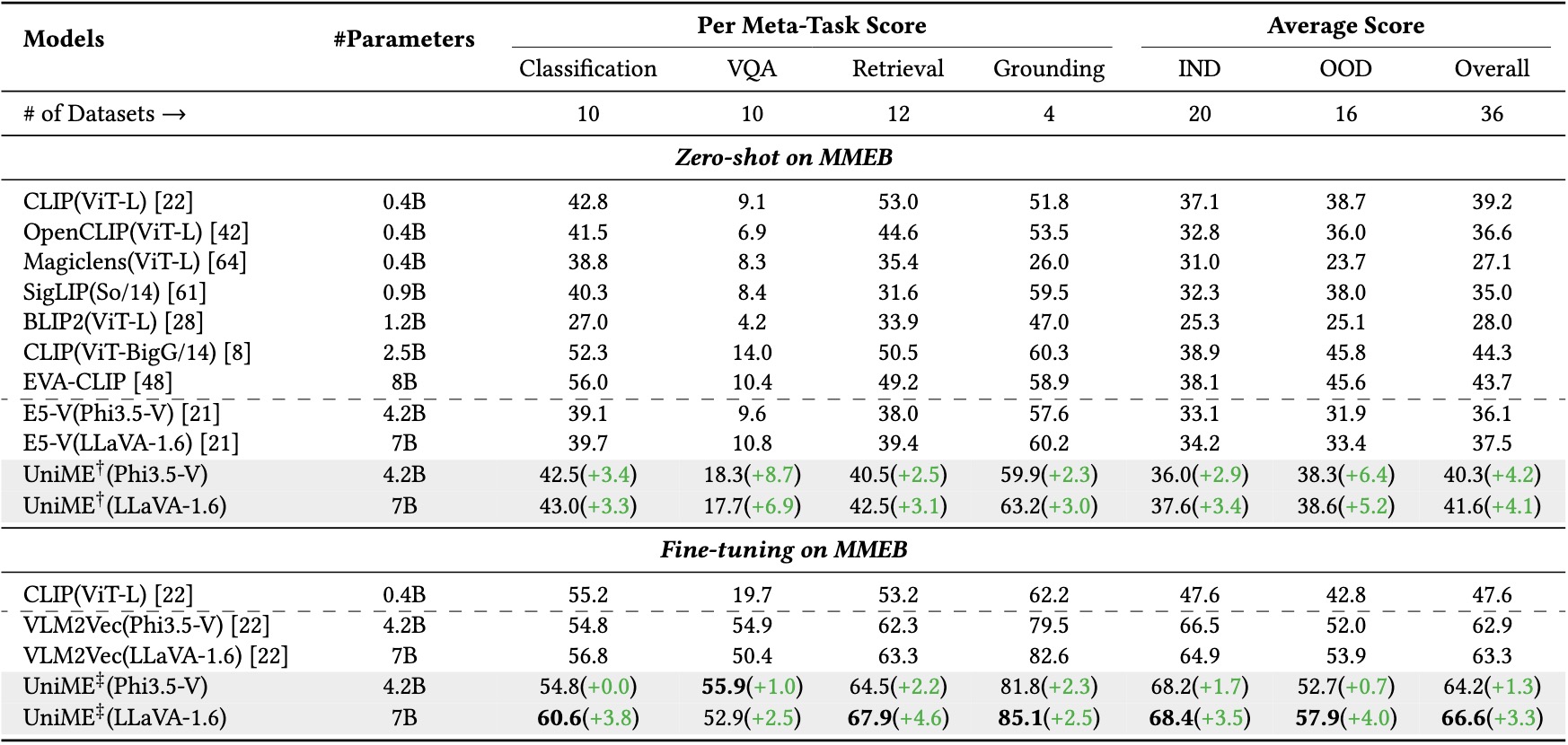
🔢 结果
多样化检索 (Diverse Retrieval)
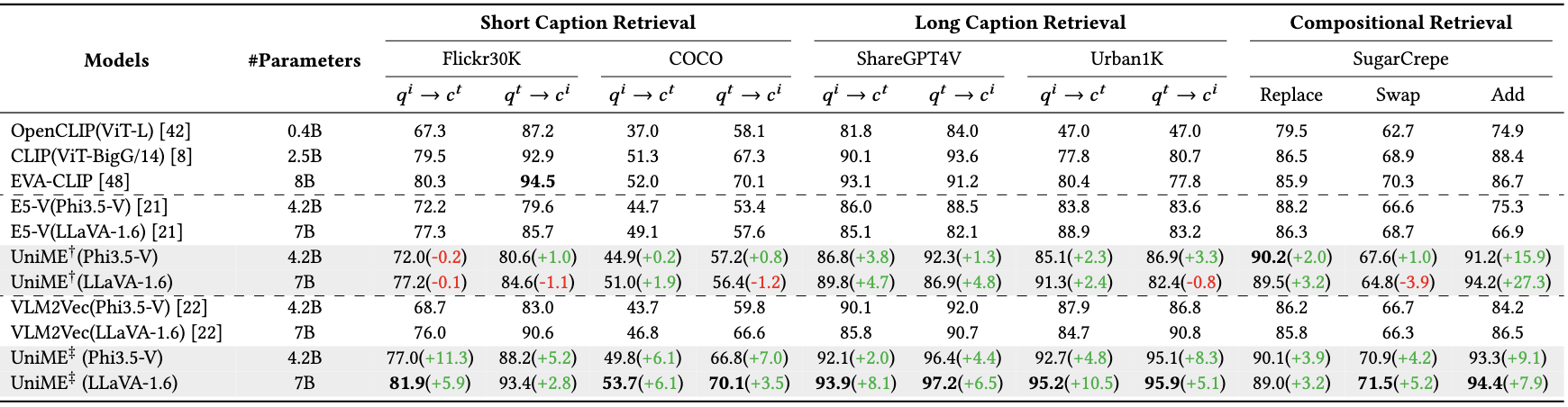
MMEB
👏 致谢
衷心感谢来自 E5-V, VLM2VEC, LamRA, ms-swift, sugar-crepe, LongCLIP, tevatron.的代码库。
📖 引用
如果您觉得本仓库有用,请使用以下 BibTeX 条目进行引用。
@misc{gu2025breakingmodalitybarrieruniversal,
title={Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs},
author={Tiancheng Gu and Kaicheng Yang and Ziyong Feng and Xingjun Wang and Yanzhao Zhang and Dingkun Long and Yingda Chen and Weidong Cai and Jiankang Deng},
year={2025},
eprint={2504.17432},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.17432},
}


















 3637
3637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











