








RAG范式
明白了RAG的整体流程之后,第六感一定会告诉你RAG肯定存在变种。因为如何检索和提问相关的知识、如何处理检索出来的多文档或者长文档、是否可以将问题分解循环提问、RAG的流程是否可以调整,这些问题存在较多的解决方法,因此也会产生较多的RAG变种。
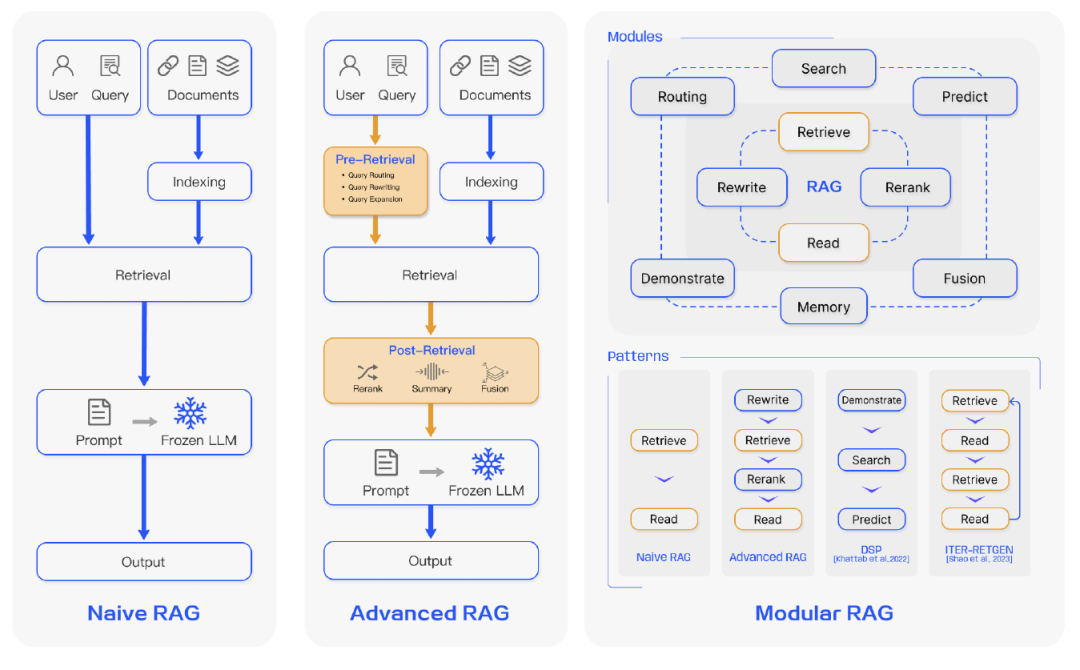
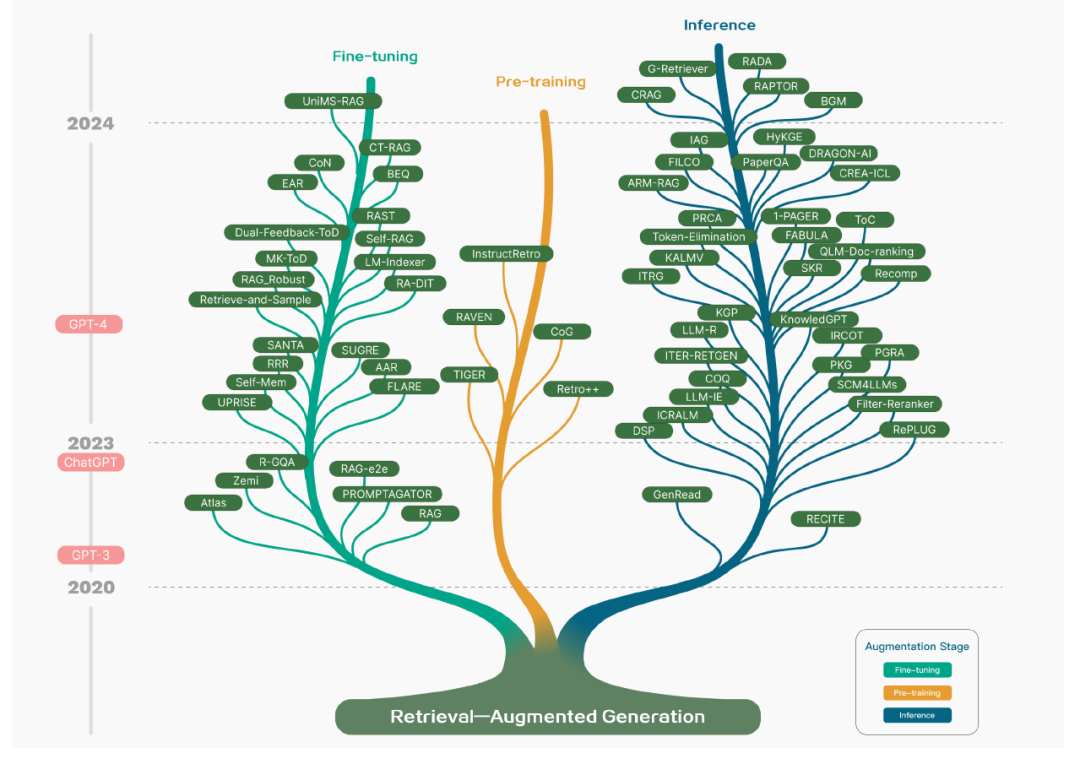
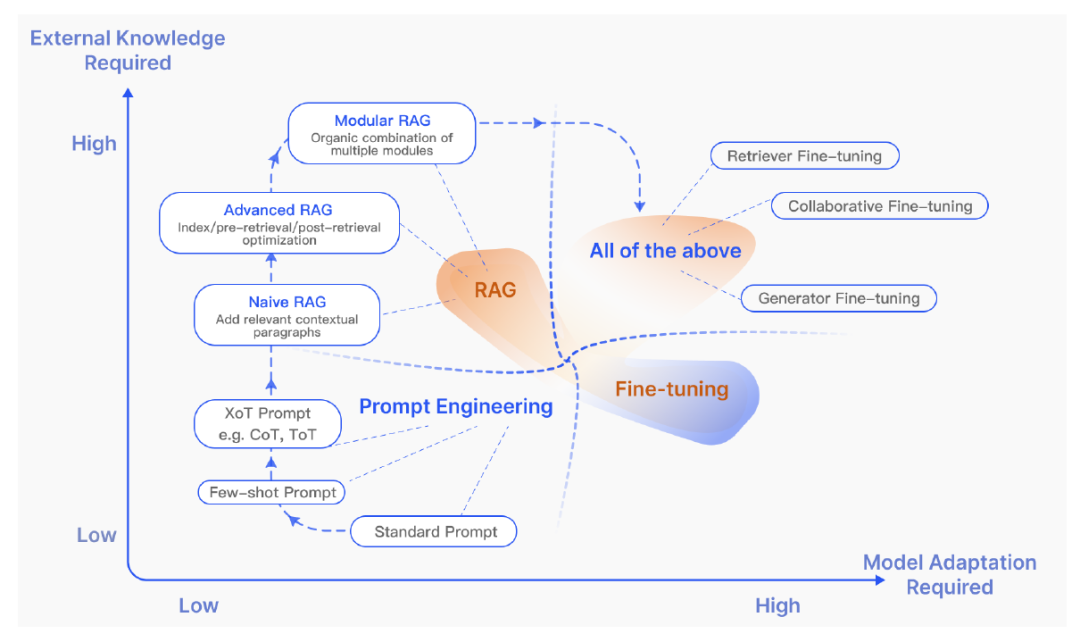
RAG存在三种范式。左边为普通模式,由索引、检索和生成三部分组成。中间是进阶版本,它围绕检索前和检索后提出了多种优化策略,其流程与普通版相似,仍然遵循链式结构。最后模块化的进一步发展之前的模式,整体上也拥有更大的灵活性。整个过程不在局限于顺序检索和生成,开启了迭代查询和自适应检索等方法,有点像代理(Agent)。
模块化RAG如何理解,其实也不难理解,从用户的提问开始,可以针对问题进行各种流程的怪异组合。例如可以将用户提问先送去大模型做个分解,让大模型给出问题的解题步骤,然后在将大模型返回的内容,逐条和知识库比对,最后在将子问题和相关的知识循环的送去给大模型,最后将所有的反馈组合,再次送给大模型做总结。当然,要记得商业化的大模型是按照Token收费的,私有化部署的大模型也是需要耗费算力资源的,如何让回答的性价比更高,值得探索。下图展示一些常见的玩法:
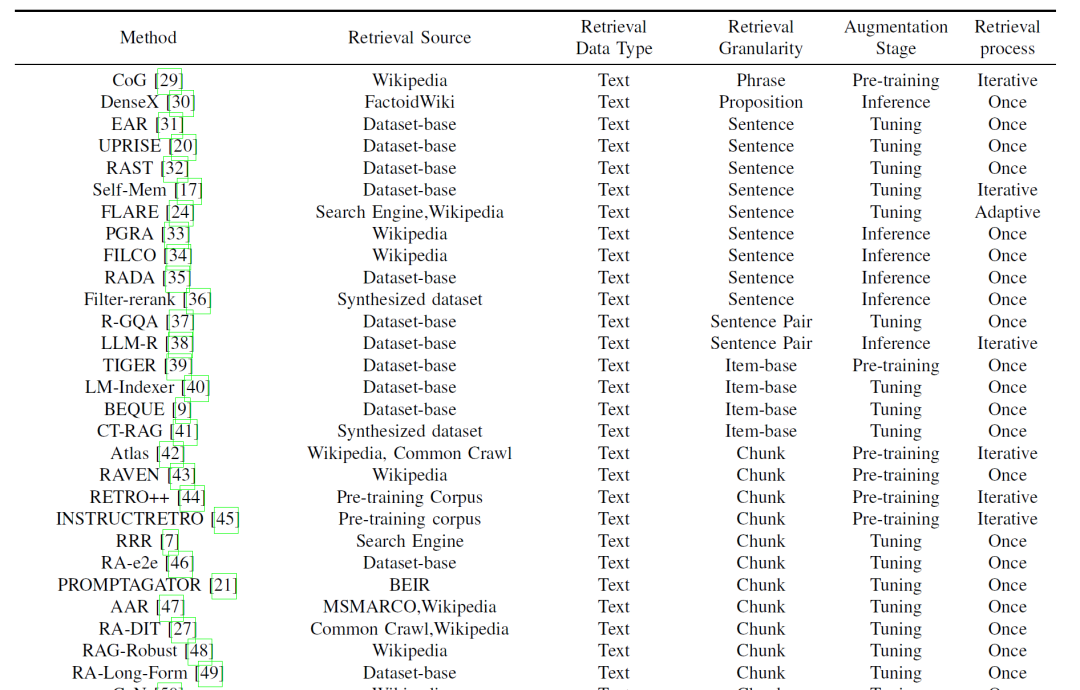
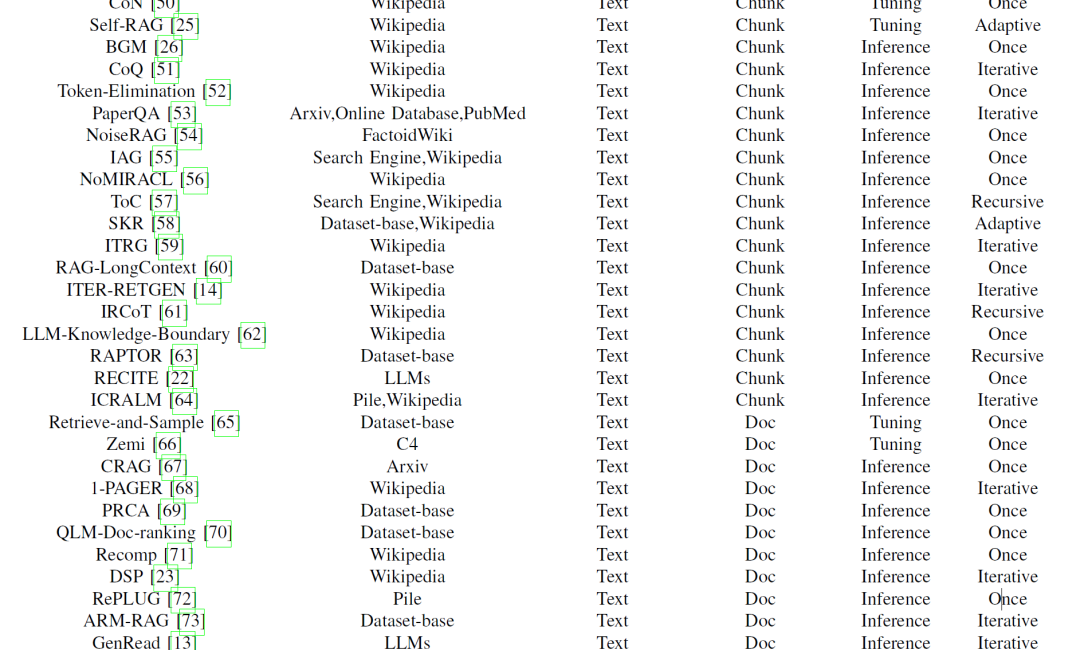

大模型应用的落地方案
其实RAG的目的是为了让大模型能够更加的聪明,从外部的知识库补充最新的或者专业化的信息,以便于它在各种生产场景中更加的“靠谱”。让大模型更加靠谱有两种路径,一种是“有效的外挂知识库”进行提问和上下文整合,另外一种就是需要对原始模型的参数进行校正。
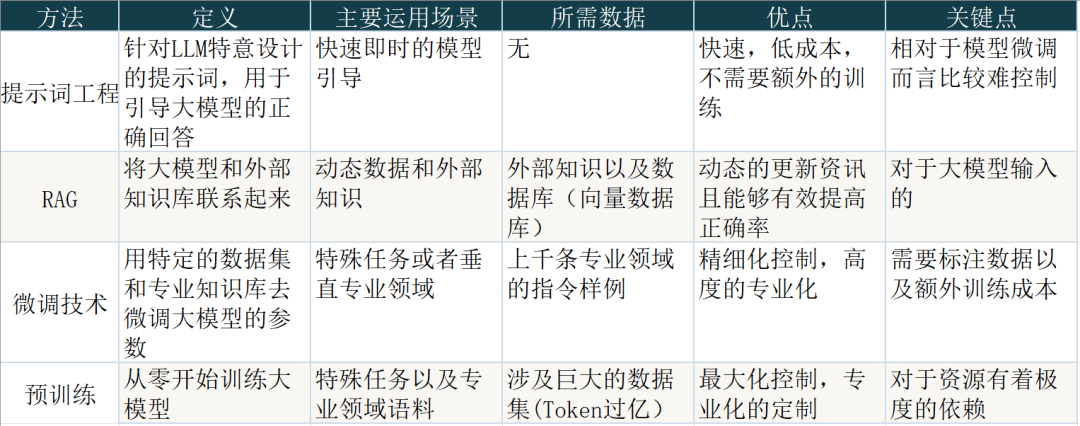
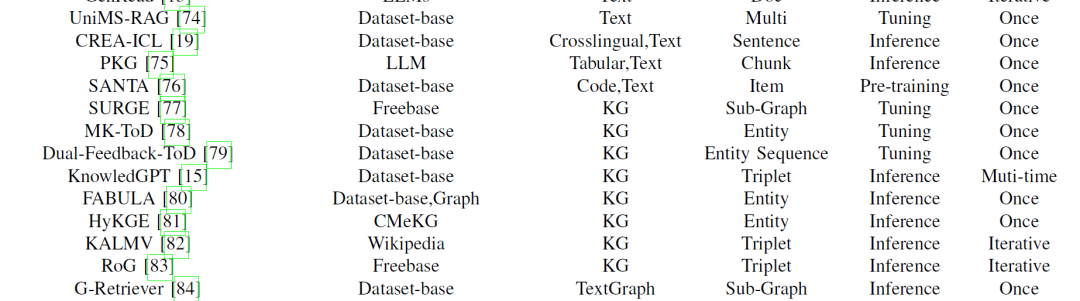
拿到一个基础模型,如何将其运用在自身特定的业务场景,基本上有四种办法,各种办法主要还在围绕着开销。
下图则从另外的维度展示了这几种方法差异,纵向代表着对于外部数据的需求度,横向代表着对于模型参数的修改读。在RAG(Naive RAG)的早期阶段,对模型参数的修改需求低,随着研究的进展,模块化RAG与微调技术的集成度越来越高。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









