







C++编译与内存相关
C++程序编译
csapp.cs.cmu.edu/3e/pieces/preface3e.pdf
C++内存管理
1.ELF 文件:
可执行与可链接格式 (Executable and Linkable Format) 是一种用于可执行文件、目标代码、共享库和核心转储 (core dump) 的标准文件格式,每个 ELF 文件都由一个 ELF header 和紧跟其后的文件数据部分组成,可以参考 ELF 文件的构成如下:
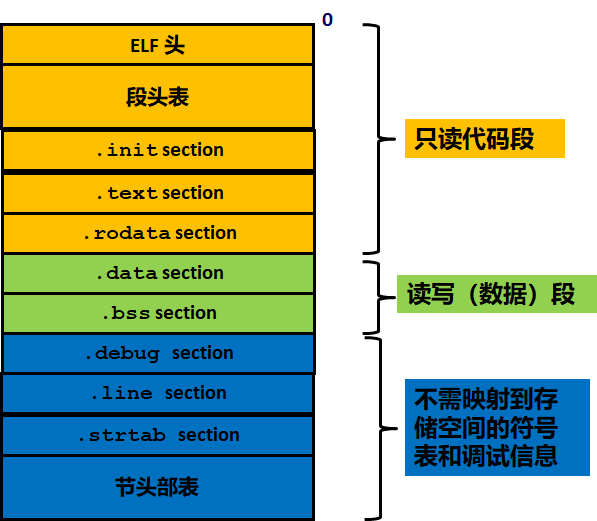
我们可以看到可执行程序内部都是分段进行存储的。
- .text section:代码段。通常存放已编译程序的机器代码,一般操作系统加载后,这部分是只读的。
- .rodatasection:只读数据段。此段的数据不可修改,存放程序中会使用的常量。比如程序中的常量字符串 "aasdasdaaasdasd"
- .datasection:数据段。主要用于存放已初始化的全局变量、常量。
- .bsssection: bss 段。该段主要存储未初始化全局变量,仅是占位符,不占据任何实际磁盘空间。目标文件格式区分初始化和非初始化是为了空间效率。
操作系统在加载 ELF 文件时会将按照标准依次读取每个段中的内容,并将其加载到内存中,同时为该进程分配栈空间,并将 pc 寄存器指向代码段的起始位置,然后启动进程。
2.内存分区:
C++ 程序在运行时也会按照不同的功能划分不同的段,C++ 程序使用的内存分区一般包括:栈、堆、全局/静态存储区、常量存储区、代码区。
- 栈:目前绝大部分 CPU体系都是基于栈来运行程序,栈中主要存放函数的局部变量、函数参数、返回地址等,栈空间一般由操作系统进行默认分配或者程序指定分配,栈空间在进程生存周期一直都存在,当进程退出时,操作系统才会对栈空间进行回收。
- 堆:动态申请的内存空间,就是由 malloc 函数或者 new 函数分配的内存块,由程序控制它的分配和释放,可以在程序运行周期内随时进行申请和释放,如果进程结束后还没有释放,操作系统会自动回收。我们可以利用
- 全局区/静态存储区:主要为 .bss 段和 .data 段,存放全局变量和静态变量,程序运行结束操作系统自动释放,在 C 中,未初始化的放在 .bss 段中,初始化的放在 .data 段中,C++ 中不再区分了。
- 常量存储区:.rodata 段,存放的是常量,不允许修改,程序运行结束自动释放。
- 代码区:.text 段,存放代码,不允许修改,但可以执行。编译后的二进制文件存放在这里。
我们参考常见的
Linux
Linux 操作系统下的内存分布图如下:
从操作系统的本身来讲,以上存储区在该程序内存中的虚拟地址分布是如下形式(虚拟地址从低地址到高地址,实际的物理地址可能是随机的):.text→.data→.bss→heap→unused→stack→⋯。
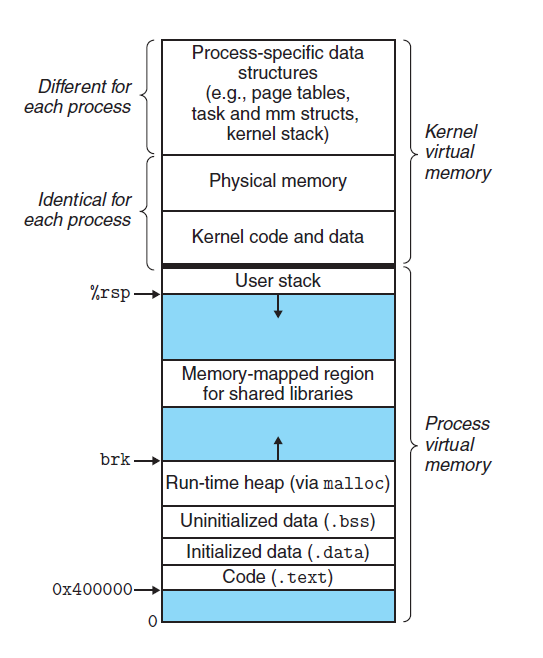
程序实例:
以下为详细的程序实例,当然可以通过 GDBGDB 工具来查看具体的每个变量的存放地址。
#include <iostream>
using namespace std;
/*
说明:C++ 中不再区分初始化和未初始化的全局变量、静态变量的存储区,如果非要区分下述程序标注在了括号中
*/
int g_var = 0; // g_var 在全局区(.data 段)
char *gp_var; // gp_var 在全局区(.bss 段)
int main()
{
int var; // var 在栈区
char *p_var; // p_var 在栈区
char arr[] = "abc"; // arr 为数组变量,存储在栈区;"abc"为字符串常量,存储在常量区
char *p_var1 = "123456"; // p_var1 在栈区;"123456"为字符串常量,存储在常量区
static int s_var = 0; // s_var 为静态变量,存在静态存储区(.data 段)
p_var = (char *)malloc(10); // 分配得来的 10 个字节的区域在堆区
free(p_var);
return 0;
}
How programs get run: ELF binaries [LWN.net]
堆与栈
1.栈:
首先需要详细了解计算机系统中的 「Stack machine」的基本概念,了解程序中函数的调用过程。每次在调用函数时,会按照从右向左的顺序依次将函数调用参数压入到栈中,并在栈中压入返回地址与当前的栈帧,然后跳转到调用函数内部,pc 跳转函数内部执行该函数的指令,在此不再展开叙述,可以详细参考许多关于栈模型的资料。
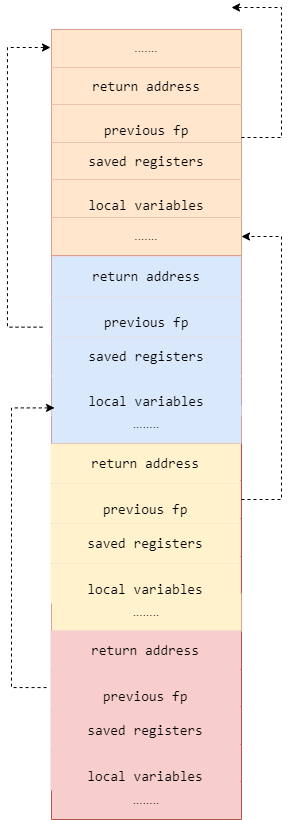
程序示例:我们可以在 gdb 下查看分配的栈的空间以及当前栈上分配的元素。
#include <iostream>
using namespace std;
/*
说明:C++ 中不再区分初始化和未初始化的全局变量、静态变量的存储区,如果非要区分下述程序标注在了括号中
*/
int g_var = 0; // g_var 在全局区(.data 段)
char *gp_var; // gp_var 在全局区(.bss 段)
int main()
{
int var; // var 在栈区
char *p_var; // p_var 在栈区
char arr[] = "abc"; // arr 为数组变量,存储在栈区;"abc"为字符串常量,存储在常量区
char *p_var1 = "123456"; // p_var1 在栈区;"123456"为字符串常量,存储在常量区
static int s_var = 0; // s_var 为静态变量,存在静态存储区(.data 段)
p_var = (char *)malloc(10); // 分配得来的 10 个字节的区域在堆区
free(p_var);
return 0;
}- 我们使用调试工具「GDBGDB」查看程序的堆栈信息,以及当前堆中的变量信息如下:
$ gdb d
(gdb) b main
Breakpoint 1 at 0x81d: file d.cpp, line 10.
(gdb) r
Starting program: /mnt/c/work/leetcode/d
Breakpoint 1, main () at d.cpp:10
10 {
(gdb) bt full
#0 main () at d.cpp:10
var = <optimized out>
p_var = 0x8000730 <_start> "1\355I\211\321^H\211\342H\203\344\360PTL\215\005\n\002"
arr = "\377\177\000"
p_var1 = 0x80008e0 <__libc_csu_init> "AWAVI\211\327AUATL\215%\206\004 "
s_var = 0
(gdb) info reg
rax 0x8000815 134219797
rbx 0x0 0
rcx 0x100 256
rdx 0x7ffffffedd28 140737488280872
rsi 0x7ffffffedd18 140737488280856
rdi 0x1 1
rbp 0x7ffffffedc30 0x7ffffffedc30
rsp 0x7ffffffedc10 0x7ffffffedc10
r8 0x7ffffefdcd80 140737471434112
r9 0x0 0
r10 0x6 6
r11 0x7fffff1316d0 140737472829136
r12 0x8000730 134219568
r13 0x7ffffffedd10 140737488280848
r14 0x0 0
r15 0x0 0
rip 0x800081d 0x800081d <main()+8>
eflags 0x202 [ IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
(gdb)我们知道 rsp 寄存器存放的地址即为当前的栈顶,rbp 寄存器存放的地址即为当前的栈帧,与 rbp 寄存器相邻的位置存放的数据即为函数的返回地址与调用函数的栈帧,通过以上信息我们即可获取函数的调用关系。
栈溢出:
一般情况操作系统为每个进程会固定栈空间的大小:
$ ulimit -s
8192当然实际情况,我们可以根据自己的需要来分配每个进程的栈空间。在实际编写程序时,如果出现两个函数互相调用或者递归无退出条件时,此时栈空间的就会无限增长。
当然实际的栈的分配与应用较为复杂,需要详细阅读操作系统的相关材料,栈一般还分为内核栈与用户栈,在栈顶会有一个特殊的内存页 guard,当栈一旦越界访问该特殊的 guard 页时,则会出现栈溢出的错误。
2.堆:
当程序在运行时,需要动态申请额外的内存来存放相应的数据和变量,此时就需要用到堆。堆的内存空间一般由操作系统或者专门内存程序来管理的。在 C/C++ 一般用 malloc 或者 new 来从堆中申请内存,使用 free 或者 delete 来释放空间,空间释放后会有操作系统进行回收。当然在实际的程序运行中动态内存管理非常复杂,会有许多非常复杂的技巧来处理。
3.堆与栈的优缺点:
- 申请方式:栈中存放的变量在编译时由编译器为其在栈上分配了空间,即程序编译后该变量在栈中使用的内存即确定,释放时也由于函数调用的返回,栈的空间会自动进行回收。堆中存放的变量由程序运行时决定的,会有操作系统或者内存管理模块来进行分配的。
- 申请后系统响应:
- 分配栈空间时如果剩余空间大于申请空间则分配成功,否则分配失败栈溢出,绝大多数情况下,栈的空间较小,一般栈上分配的变量不会占用太大的空间,且当函数返回时,当前栈帧中的变量生存周期会结束;申请堆空间,堆在内存中呈现的方式类似于链表(记录空闲地址空间的链表),在链表上寻找第一个大于申请空间的节点分配给程序,将该节点从链表中删除,大多数系统中该块空间的首地址存放的是本次分配空间的大小,便于释放,将该块空间上的剩余空间再次连接在空闲链表上,堆上可以分配较大的空间,如果不对申请的内存进行释放,则堆上存储的变量生存周期一直存在,直到当前进程退出。
- 栈在内存中是连续的一块空间(向低地址扩展)最大容量是系统预定好的,且只能被当前的线程访问;堆在内存中的空间(向高地址扩展)是不连续的,中间允许有间隔,堆中的内存并不是线程安全的,同一进程的线程都都可访问。
- 申请效率:栈是有系统自动分配,申请效率高,但程序员无法控制;堆是由程序员主动申请,效率低,使用起来方便但是容易产生碎片。
- 存放的内容:栈中存放的是局部变量,函数的参数;堆中存放的内容由程序员控制。
4.实际的内存管理
- 实际的内存管理可能更为复杂,一般分为两级内存管理。
- 操作系统按照段页式来管理内存,当需要创建新的进程或者线程时,操作系统会为新创建的进程分配物理页,当运行的进程需要更多的内存时,操作系统也会为其分配新的物理页并将其映射到该进程的虚拟地址空间中。
- 程序运行时,每个程序都含有一个内存管理的子程序,专门负责程序中的内存申请和释放,其中的技巧可能非常复杂,并且涉及许多内存分配的算法。
4.6. Memory Management: The Stack And The Heap (weber.edu)
Dynamic Memory Allocation and Fragmentation in C and C++ (design-reuse.com)
从操作系统内存管理来说,malloc申请一块内存的背后原理是什么? - 知乎 (zhihu.com)
变量定义与生存周期
C/C++ 变量有两个非常重要的属性:作用域与生命周期,这两个属性代表从时间和空间两个不同的维度来描述一个变量。
1.作用域:
- 作用域即一个变量可以被引用的范围,常见的作用域可分为 6 种:全局作用域,局部作用域,语句作用域,类作用域,命名空间作用域和文件作用域。从作用域来来看:
- 全局变量:具有全局作用域。全局变量只需在一个源文件中定义,就可以作用于所有的源文件。其他不包含全局变量定义的源文件需要用 extern 关键字再次声明这个全局变量。
- 静态全局变量:具有文件作用域。它与全局变量的区别在于如果程序包含多个文件的话,它作用于定义它的文件里,不能作用到其它文件里,即被 static 关键字修饰过的变量具有文件作用域。这样即使两个不同的源文件都定义了相同名字的静态全局变量,它们也是不同的变量。
- 局部变量:具有局部作用域。它是自动对象(auto),在程序运行期间不是一直存在,而是只在函数执行期间存在,函数的一次调用执行结束后,变量被撤销,其所占用的内存也被收回,局部变量对于函数外部的程序来说是不可见的。当然内部实际更复杂,实际是以 {} 为作用域的。
- 静态局部变量:具有局部作用域。它只被初始化一次,自从第一次被初始化直到程序运行结束都一直存在,它和全局变量的区别在于全局变量对所有的函数都是可见的,而静态局部变量只对定义自己的函数体始终可见, 只有定义该变量的函数内部可以使用访问和修改该变量。
- 比如以下文件定义
- 程序实例:
- 以下为详细的程序实例 a.cpp, b.cpp,分别对应的变量定义。
//a.cpp
#include <iostream>
using namespace std;
int g_var = 0; // 全局变量
static char *gs_var; // 静态全局变量
int main()
{
int var; // 局部变量
static int s_var = 0; // 静态局部变量
return 0;
}//b.cpp
#include <iostream>
using namespace std;
extern int g_var = 0; // 访问全局变量
// extern static char *gs_var; 无法访问静态全局变量
int test()
{
g_var = 1;
}
2.生命周期:
- 生命周期即该变量可以被引用的时间段(生存期表示变量存在的时间)。
- 全局变量: 全局变量在整个程序运行期间都会一直存在,都可以随时访问,当程序结束时,对应的变量则会自动销毁,内存会被系统回收。
- 局部变量: 局部变量的生命周期仅限于函数被调用期间,当函数调用结束时,该变量会自动销毁。
- 静态局部变量:实际上静态局部变量的作用域仅限于函数内部,它的作用域与局部变量相同,但实际上该变量在程序运行期间是一直存在的,生命周期贯穿于整个程序运行期间。局部静态变量只能被初始化一次。
3.从分配内存空间看:
不同生命周期的变量,在程序内存中的分布位置是不一样的。。我们知道程序的内存分为代码区(.text)、全局数据区(.data,.bss,.rodata)、堆区(heap)、栈区(stack),不同的内存区域,对应不同的生命周期。
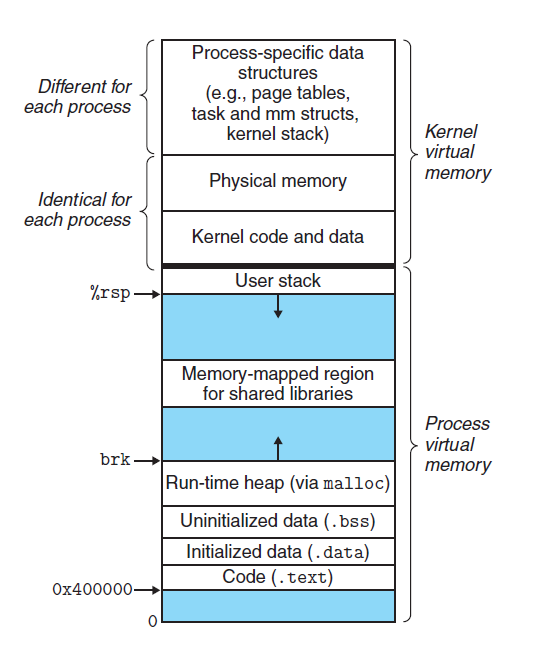
- 静态变量一般存储在数据段,包括 data 段、bss 段、rodata 段,其中 data 存储已经已经初始化的静态变量和全局变量,bss 存储未初始化的静态变量与全局变量。这里静态变量包括全局变量,静态全局变量,静态局部变量。
- 局部变量一般存储在栈区或者堆区。
4.注意:
- 静态变量和栈变量(存储在栈中的变量)、堆变量(存储在堆中的变量)的区别:静态变量会被放在程序的静态数据存储区(.data 段,bss 段,rodata 段)中(静态变量会自动初始化),这样可以在下一次调用的时候还可以保持原来的赋值。而栈变量或堆变量不能保证在下一次调用的时候依然保持原来的值。
- 静态变量和全局变量的区别:静态变量仅在变量的作用范围内可见,实际是依靠编译器来控制作用域。全局变量在整个程序范围内都可可见,只需声明该全局变量,即可使用。
- 全局变量定义在不要在头文件中定义:如果在头文件中定义全局变量,当该头文件被多个文件 include 时,该头文件中的全局变量就会被定义多次,编译时会因为重复定义而报错,因此不能再头文件中定义全局变量。一般情况下我们将变量的定义放在 .cpp 文件中,一般在 .h 文件使用extern 对变量进行声明。
https://en.wikipedia.org/wiki/.bss
https://en.wikipedia.org/wiki/Data_segment
内存对齐
1.什么是内存对齐:
计算机中内存的地址空间是按照 byte 来划分的,从理论上讲对任何类型变量的访问可以从内存中的任意地址开始,但实际情况是:在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置进行限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。编译器将程序中的每个 数据单元 的地址安排在机器字的整数倍的地址指向的内存之中。
2.为什么要内存对齐:
主要是由于 CPU 的访问内存的特性决定,CPU 访问内存时并不是以字节为单位来读取内存,而是以机器字长为单位,实际机器字长由 CPU 数据总线宽度决定的。实际 CPU 运行时,每一次控制内存读写信号发生时,CPU 可以从内存中读取数据总线宽度的数据,并将其写入到 CPU 的通用寄存器中。比如 32 位 CPU,机器字长为 4 字节,数据总线宽度为 32 位,如果该 CPU 的地址总线宽度也是为 32 位,则其可以访问的地址空间为 [0,0xffffffff]。内存对齐的主要目的是为了减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。假设读取 8 个字节的数据,按照每次读取 4 个字节的速度,则 8 个字节需要 CPU 耗费 2 次读取操作。CPU 始终以字长访问内存,如果不进行内存对齐,很可能增加 CPU 访问内存的次数。
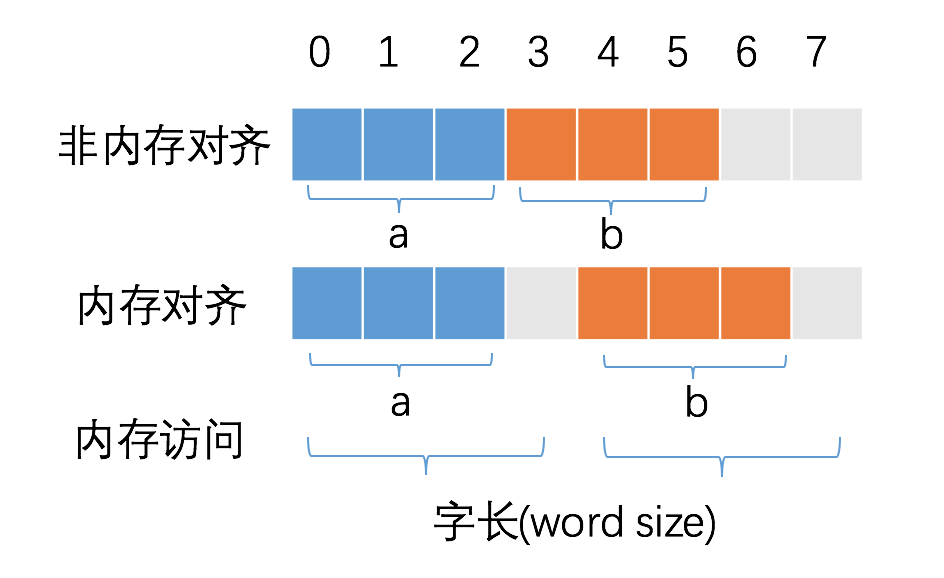
比如以上在读取变量 b 时,如果不进行内存对齐的话,会导致 CPU 读取次数为 2,在内存对齐的情况下,只需读取一次即可,当然实际的读取非对齐的内存处理更为复杂,我们参考下图中读取非对齐内存时的数据处理过程:
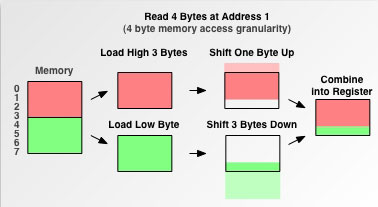
2.除了能够减少内存访问次数,增加内存读取的吞吐量以外,还有其他原因:
- 比如某些特定的硬件设备只能存取对齐数据,存取非对齐的数据可能会引发异常,比如对于 CPU 中 SIMD 指令,则必须要求内存严格对齐;
- 每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的。某些硬件设备不能保证在存取非对齐数据的时候的操作是原子操作,因此此时 CPU 需要可能需要读取多次内存,这样就破坏了变量的原子性;
- 相比于存取对齐的数据,存取非对齐的数据需要花费更多的时间,提高内存的访问效率,因为 CPU 在读取内存时,是一块一块的读取;
- 某些处理器虽然支持非对齐数据的访问,但会引发对齐陷阱(alignment trap);
- 某些硬件设备只支持简单数据指令非对齐存取,不支持复杂数据指令的非对齐存取。
3.内存对齐的原则:
- 程序中的内存对齐大部分都是由编译器来处理,编译器会自动在内存之间填充字节。结构体中的变量对齐的基本规则如下:
- 结构体变量的首地址能够被其最宽的基本类型成员的长度和对齐基数二者中的较小者所整除;
- 结构体中的 static 成员变量不占用结构体的空间,由于静态成员变量在程序初始化时已经在静态存储区分配完成,所有该结构体实例中的静态成员都指向同一个内存区域;
struct st {
char a;
int b;
static double c; //静态成员
} T;
cout<<sizeof(st)<<endl;
// 8
- 结构体每个成员相对于结构体首地址的偏移量 (offset) 都是该成员大小与对齐基数中的较小者的整数倍,如有需要编译器会在成员之间加上填充字节 (internal padding);
- 结构体的总大小为结构体中最宽基本类型成员的长度与对齐基数二者中的较小者的整数倍,如有需要编译器会在最末尾的成员之后加上填充字节 (trailing padding);
- 实例:我们可以利用 offset 宏定义来计算出结构体中每个变量的偏移地址。
/*
说明:程序是在 64 位编译器下测试的
*/
#include <iostream>
using namespace std;
#define offset(TYPE,MEMBER) ((long)&((TYPE *)0)->MEMBER)
struct A
{
short var; // 偏移 0 字节 (内存对齐原则 : short 2 字节 + 填充 2 个字节)
int var1; // 偏移 4 字节 (内存对齐原则:int 占用 4 个字节)
long var2; // 偏移 8 字节 (内存对齐原则:long 占用 8 个字节)
char var3; // 偏移 16 字节 (内存对齐原则:char 占用 1 个字节 + 填充 7 个字节)
string s; // 偏移 24 字节 (string 占用 32 个字节)
};
int main()
{
string s;
A ex1;
cout << offset(A, var) <<endl;
cout << offset(A, var1) <<endl;
cout << offset(A, var2) <<endl;
cout << offset(A, var3) <<endl;
cout << offset(A, s) <<endl;
cout << sizeof(ex1) << endl; // 56 struct
return 0;
}我们可以看到运行结果如下:
0
4
8
16
24
56- 指定程序对齐规则:
我们可以指定结构体的对齐规则,在某些特定场景下我们需要指定结构体内存进行对齐,比如在发送特定网络协议报文、硬件协议控制、消息传递、硬件寄存器访问时,这时就就需要避免内存对齐,因为双方均按照预先定义的消息格式来进行交互,从而避免不同的硬件平台造成的差异,同时能够将双方传递的数据进行空间压缩,避免不必要的空间浪费。
programpack: 我们可以用 #progma pack(x) 指定结构体以 x 为单位进行对齐。一般情况下我们可以使用如下:
#pragma pack(push)
#pragma pack(x)
// 存放需要 x 对齐方式的数据块
#pragma pack(pop)我们同样指定上述程序以 11 字节对齐,则可以看到结果如下:
/*
说明:程序是在 64 位编译器下测试的
*/
#include <iostream>
using namespace std;
#define offset(TYPE,MEMBER) ((long)&((TYPE *)0)->MEMBER)
#pragma pack(push)
#pragma pack(1)
struct A
{
short var; // 偏移 0 字节 (内存对齐原则 : short 2 字节 + 填充 2 个字节)
int var1; // 偏移 4 字节 (内存对齐原则:int 占用 4 个字节)
long var2; // 偏移 8 字节 (内存对齐原则:long 占用 8 个字节)
char var3; // 偏移 16 字节 (内存对齐原则:char 占用 1 个字节 + 填充 7 个字节)
string s; // 偏移 24 字节 (string 占用 32 个字节)
};
#pragma pack(pop)
int main()
{
string s;
A ex1;
cout << offset(A, var) <<endl;
cout << offset(A, var1) <<endl;
cout << offset(A, var2) <<endl;
cout << offset(A, var3) <<endl;
cout << offset(A, s) <<endl;
cout << sizeof(ex1) << endl; // 56 struct
return 0;
}运行结果如下:
0
2
6
14
15
47attribute((aligned (n))): __attribute__((aligned (n))) 让所作用的结构成员对齐在 n 字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。需要注意的是:内存对齐的对齐数取决于对齐系数和成员的字节数两者之中的较小值。对齐属性的有效性会受到链接器(linker)固有限制的限制,即如果你的链接器仅仅支持 8 字节对齐,即使你指定16字节对齐,那么它也仅仅提供 8 字节对齐。__attribute__((packed)) 表示取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,这部分属于 gcc 中的用法,详细了解详情可以参考 gcc 的手册。
alignof: C++ 11 以后新增 alignof 的特性,通过调用 alignof 返回当前变量的字节对齐方式。比如以下程序:
```C++ []
/*
说明:程序是在 64 位编译器下测试的
*/
#include <iostream>
using namespace std;
#define offset(TYPE,MEMBER) ((long)&((TYPE *)0)->MEMBER)
#pragma pack(push)
#pragma pack(1)
struct A
{
short var; // 偏移 0 字节 (内存对齐原则 : short 2 字节 + 填充 2 个字节)
int var1; // 偏移 4 字节 (内存对齐原则:int 占用 4 个字节)
long var2; // 偏移 8 字节 (内存对齐原则:long 占用 8 个字节)
char var3; // 偏移 16 字节 (内存对齐原则:char 占用 1 个字节 + 填充 7 个字节)
string s; // 偏移 24 字节 (string 占用 32 个字节)
};
#pragma pack(pop)
int main()
{
string s;
A ex1;
cout << alignof(A) <<endl;
return 0;
}
```
此时返回结果为 $1$。
4.小结:
内存对齐使得程序便于在不同的平台之间进行移植,因为有些硬件平台不能够支持任意地址的数据访问,只能在某些地址处取某些特定的数据,否则会抛出异常;另一方面提高内存的访问效率,因为 CPU 在读取内存时,是以块为单位进行读取。
Purpose of memory alignment - Stack Overflow
Memory and Alignment (umd.edu)
一文轻松理解内存对齐 - 腾讯云开发者社区-腾讯云 (tencent.com)
(转) 内存对齐 | Light.Moon (light3moon.com)
Memory alignment... run, you fools! - Virtual Method's Blog (virtualmethodstudio.com)
智能指针
智能指针:
智能指针是为了解决动态内存分配时带来的内存泄漏以及多次释放同一块内存空间而提出的。C++ 11 中提供了智能指针的定义,所有关于智能指针的定义可以参考 <memory> 头文件。传统的指针在申请完成后,必须要调用 free 或者 delete 来释放指针,否则容易产生内存泄漏的问题;smart pointer 遵循 RAII 原则,当 smart pointer 对象创建时,即为该指针分配了相应的内存,当对象销毁时,析构函数会自动释放内存。需要注意的是,智能指针不能像普通指针那样支持加减运算。
#include <iostream>
using namespace std;
class SmartPtr {
int* ptr;
public:
explicit SmartPtr(int* p = NULL) { ptr = p; }
~SmartPtr() { delete (ptr); }
int& operator*() { return *ptr; }
};
int main()
{
SmartPtr ptr(new int());
*ptr = 20;
cout << *ptr;
return 0;
}
同时 smart pointer 重载了 * 和 -> 等操作,使用该对象就像 C 语言中的普通指针一样,但是区别于普通指针的它会自动释放所申请的内存资源。以下为智能指针的简单实现:
#include <iostream>
using namespace std;
template <class T>
class SmartPtr {
T* ptr; // Actual pointer
public:
explicit SmartPtr(T* p = NULL) { ptr = p; }
~SmartPtr() { delete (ptr); }
T& operator*() { return *ptr; }
T* operator->() { return ptr; }
};
int main()
{
SmartPtr<int> ptr(new int());
*ptr = 20;
cout << *ptr;
return 0;
}
按照常用的使用用途,智能指针有三类:
- unique_ptr:独享所有权的智能指针,资源只能被一个指针占有,该指针不能拷贝构造和赋值。但可以进行移动构造和移动赋值构造(调用 move() 函数),即一个 unique_ptr 对象赋值给另一个 unique_ptr 对象,可以通过该方法进行赋值。
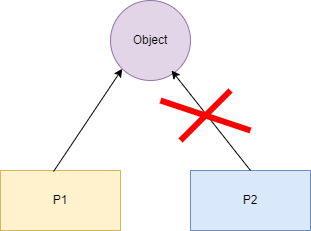
如图所示,object 资源只能被 P1 占有,P2 无法对 object 有所有权,只能通过移动赋值给 P2。如下代码示例:
#include <iostream>
using namespace std;
#include <memory>
class Rectangle {
int length;
int breadth;
public:
Rectangle(int l, int b){
length = l;
breadth = b;
}
int area(){
return length * breadth;
}
};
int main(){
unique_ptr<Rectangle> P1(new Rectangle(10, 5));
cout << P1->area() << endl; // This'll print 50
unique_ptr<Rectangle> P2;
// unique_ptr<Rectangle> P2(P1); // 无法拷贝构造
// P2 = P1; // 无法赋值构造
P2 = move(P1);
cout << P2->area() << endl;
// cout<<P1->area()<<endl; // 已经传递,P1 无所有权
return 0;
}我们可以通过查看源代码看到该函数的拷贝构造函数和赋值构造函数均被禁止,只允许使用移动拷贝构造函数和移动赋值构造函数:
// Disable copy from lvalue.不允许复制,体现专属所有权语义
unique_ptr(const unique_ptr&) = delete;
unique_ptr& operator=(const unique_ptr&) = delete;
// Move constructor.体现专属所有权语义和只移型别
// 只允许使用移动拷贝构造函数
// 如果复制一个unique_ptr对象,会将源unique_ptr对象管理的资源release掉
unique_ptr(unique_ptr&& __u) noexcept
: _M_t(__u.release(), std::forward<deleter_type>(__u.get_deleter())) { }
// 这个也是移动拷贝构造函数
// 只是使用的类型是可以隐式转换的其他unique_ptr对象
template<typename _Up, typename _Ep, typename = _Require<
__safe_conversion_up<_Up, _Ep>,
typename conditional<is_reference<_Dp>::value,
is_same<_Ep, _Dp>,
is_convertible<_Ep, _Dp>>::type>>
unique_ptr(unique_ptr<_Up, _Ep>&& __u) noexcept
: _M_t(__u.release(), std::forward<_Ep>(__u.get_deleter()))
{ }
// Assignment,也可以说明是专属所有权语义和只移型别
unique_ptr& operator=(unique_ptr&& __u) noexcept
{
// __u.release()释放并返回源unique_ptr对象管理的资源
// reset是将__u.release()返回的资源赋给目标(当前)unique_ptr对象
reset(__u.release());
get_deleter() = std::forward<deleter_type>(__u.get_deleter());
return *this;
}
// 析构函数,调用析构器析构掉管理的资源,并将__ptr指向nullptr
~unique_ptr()
{
auto& __ptr = _M_t._M_ptr();
if (__ptr != nullptr)
get_deleter()(__ptr);
__ptr = pointer();
}
同时我们可以看到 reset 重新给其赋值,在获取资源的同时会释放原有的资源。
void reset(pointer __p = pointer()) noexcept
{
using std::swap;
swap(_M_t._M_ptr(), __p);
if (__p != pointer() get_deleter()(__p);
}
- shared_ptr:与 unique_ptr 不同的是,shared_ptr 中资源可以被多个指针共享,但是多个指针指向同一个资源不能被释放多次,因此使用计数机制表明资源被几个指针共享。
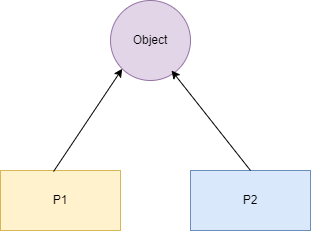
通过 use_count() 查看资源的所有者的个数,可以通过 unique_ptr、weak_ptr 来构造,调用 release() 释放资源的所有权,同时将计数减一,当计数减为 0 时会自动释放内存空间,从而避免了内存泄漏。特别需要注意的是 shared_ptr 并不是线程安全的,但 shared_ptr 的计数是原子操作实现的,利用 atmoic CAS 指令实现。我们可以看到 share_ptr 的内存模型,当引用计数和 weak count 同时为 0 时,share_ptr 对象才会被最终释放掉。
#include <iostream>
using namespace std;
#include <memory>
class Rectangle {
int length;
int breadth;
public:
Rectangle(int l, int b)
{
length = l;
breadth = b;
}
int area()
{
return length * breadth;
}
};
int main()
{
shared_ptr<Rectangle> P1(new Rectangle(10, 5));
cout << P1->area() << endl;
shared_ptr<Rectangle> P2;
P2 = P1;
cout << P2->area() << endl; // 50
cout << P1->area() << endl; // 50
cout << P1.use_count() << endl; // 2
return 0;
}
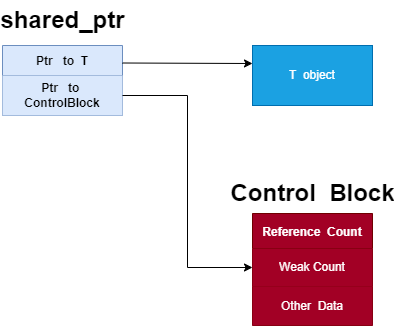
我们通过查看 shared_ptr 的源代码可以看到如下,shared_ptr 实际成员包含两个指针,一个指向对象资源的指针 ptr,另一个指向管理区域的指针 __cntrl_,具体 __cntrl_ 指向的区域包括 deleter、allocator、shared_ptr 对象的引用计数、weak_ptrs 的对象的引用计数。
template<class _Tp>
class shared_ptr {
typedef _Tp element_type;
private:
element_type* __ptr_;
__shared_weak_count* __cntrl_;
...
}
- weak_ptr:指向 share_ptr 指向的对象,能够解决由 shared_ptr 带来的循环引用问题。与 shared_ptr 配合使用,将 weak_ptr 转换为 share_ptr 时,虽然它能访问 share_ptr 所指向的资源但却不享有资源的所有权,不影响该资源的引用计数。有可能资源已被释放,但 weak_ptr 仍然存在,share_ptr 必须等待所有引用的 weak_ptr 全部被释放才会进行释放。因此每次访问资源时都需要判断资源是否有效。
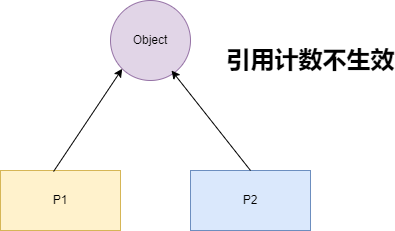
shared_ptr 通过引用计数的方式来管理对象,当进行拷贝或赋值操作时,每个 shared_ptr 都会记录当前对象的引用计数,当引用计数为0时,内存将被自动释放。当对 shared_ptr 赋予新值或者被对象被销毁时,引用计数会递减。但特殊情况出现循环引用时,shared_ptr 无法正常释放资源。循环引用,即 A 指向 B,B 指向 A,在表示双向关系时,是很可能出现这种情况的。下面的示例代码即为出现了循环引用导致内存无法正常被释放。
#include <iostream>
#include <memory>
using namespace std;
class B;
class A {
public:
shared_ptr<B> b_;
A() {
cout << "A constructed!" << endl;
}
~A() {
cout << "A destructed!" << endl;
}
};
class B {
public:
shared_ptr<A> a_;
B() {
cout << "B constructed!" << endl;
}
~B() {
cout << "B destructed!" << endl;
}
};
int main()
{
auto classA = make_shared<A>();
auto classB = make_shared<B>();
classA->b_ = classB;
classB->a_ = classA;
cout << "A: " << classA.use_count() << endl;
cout << "B: " << classB.use_count() << endl;
return 0;
}程序结果运行如下:
A constructed!
B constructed!
A: 2
B: 2为了解决上述的循环引用问题,才出现了 weak_ptr,我们知道 shared_ptr A 被赋值给 shared_ptr B 时,A 的引用计数加 1;但是 shared_ptr A 被赋值给 weak_ptr C 时,A 的引用计数不变。weak_ptr 在使用时是与 shared_ptr 绑定的,weak_ptr 不影响对象 shared_ptr 的引用计数,weak_ptr 可以用来跟踪 shared_ptr 对象,当 shared_ptr 的对象引用计数为 0 时,此时 shared_ptr 会释放所占用的对象资源,但 shared_ptr 对象本身不会释放,它会等待 weak_ptrs 引用计数为 0 时,此时才会释放管理区域的内存,而释放 shared_ptr 对象本身。上述的循环引用,我们可以将一个对象改为 weak_ptr 即可避免循环引用导致的异常。例如下列代码:
#include <iostream>
#include <memory>
using namespace std;
class B;
class A {
public:
shared_ptr<B> b_;
A() {
cout << "A constructed!" << endl;
}
~A() {
cout << "A destructed!" << endl;
}
};
class B {
public:
weak_ptr<A> a_;
B() {
cout << "B constructed!" << endl;
}
~B() {
cout << "B destructed!" << endl;
}
};
int main()
{
auto classA = make_shared<A>();
auto classB = make_shared<B>();
classA->b_ = classB;
classB->a_ = classA;
cout << "A: " << classA.use_count() << endl;
cout << "B: " << classB.use_count() << endl;
return 0;
}
A constructed!
B constructed!
A: 1
B: 2
A destructed!
B destructed!std::weak_ptr - cppreference.com
std::shared_ptr - cppreference.com
c++ - What is a smart pointer and when should I use one? - Stack Overflow
当我们谈论shared_ptr的线程安全性时,我们在谈论什么 - 知乎 (zhihu.com)
循环引用中的shared_ptr和weak_ptr - 知乎 (zhihu.com)
why using make_unique rather than unique_ptr - 知乎 (zhihu.com)
c++ - Differences between std::make_unique and std::unique_ptr with new - Stack Overflow
which one is better between make_unique and new | Sololearn: Learn to code for FREE!
智能指针的创建
1.make_unique 与 make_share:
make_unique 在 C++ 14 以后才被加入到标准的 C++ 中,make_shared 则是 C++ 11 中加入的。在 「《Effective Modern C++》」 学习笔记之条款二十一:优先选用 std::make_unique 和 std::make_shared,而非直接 new。
- make_unique:减少代码量,能够加快编译速度,定义两遍类型时,编译器需要进行类型推导会降低编译速度,某些意外意外情况下可能会导致内存泄漏。但是 make_unique 不允许自定析构器,不接受 std::initializer_list 对象。
auto upw1(std::make_unique<Widget>());
//重复写了两次Widget型别
std::unique_ptr<Widget> upw2(new Widget);
make_shared:这个主要是可以减少对堆中申请内存的次数,只需要申请一次即可。我们知道share_ptr的内存模型如下:
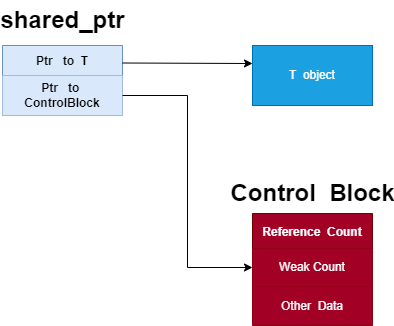
当我们使用 new 时,我们将 new 出的资源指针赋给 share_ptr 的 ptr, 然后 share_ptr 本身还需要再次在堆上申请一块单独的内存作为它的管理区,存放引用计数、用户自定的函数等,因此创建 shared_ptr 时需要在堆上申请两次。
C++ [] std::shared_ptr<Widget>(new Widget);
当我们使用 make_share 时,我们只需要申请一块大的内存,一半用来存储资源,另一半作为管理区, 存放引用计数、用户自定的函数等,此时需要在堆上申请一次即可。
C++ auto upw1(std::make_unique<Widget>());
以下为两种方式的对比:
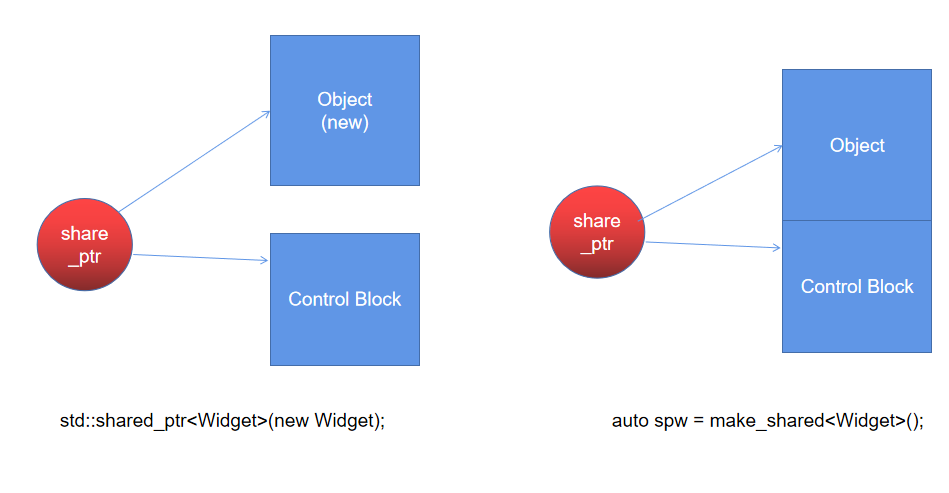
make_share 虽然效率高,但是同样不能自定义析构器,同时 share_ptr 的对象资源可能会延迟释放,因为此时对象资源与管理区域在同一块内存中,必须要同时释放。
大端和小端
Understanding Big and Little Endian Byte Order – BetterExplained
内存泄露
Memory leak detection - How to find, eliminate, and avoid · Raygun Blog
内存泄露检测与预防
Find memory leaks with the CRT Library - Visual Studio (Windows) | Microsoft Docs
Linux 性能分析valgrind(一)之memcheck使用 - 知乎 (zhihu.com)
Using Valgrind to Find Memory Leaks - Cprogramming.com
c - How do I use valgrind to find memory leaks? - Stack Overflow
General guidelines to avoid memory leaks in C++ - Stack Overflow
C++关键字与库函数
sizeof和strlen的区别
sizeof operator - cppreference.com
lambda表达式
Lambda expressions in C++ | Microsoft Docs
Lambda expressions (since C++11) - cppreference.com
c++ - What is a lambda expression in C++11? - Stack Overflow
explicit
C++ explicit 关键字 - 知乎 (zhihu.com)
explicit specifier - cppreference.com
c++ - What does the explicit keyword mean? - Stack Overflow
static
static members - cppreference.com
C/C++ 中 static 的用法全局变量与局部变量 | 菜鸟教程 (runoob.com)
The static keyword and its various uses in C++ - Stack Overflow
Static Members of a C++ Class (tutorialspoint.com)
const
C++ const 关键字小结 | 菜鸟教程 (runoob.com)
深入理解C++中的mutable关键字 - 蛋疼先生的手札 - ITeye博客
define和const的区别
Difference between const and #define in C, C++ programming language (includehelp.com)
define和typedef的区别
Difference between typedef and define in C - javatpoint
new/delete、malloc/free
new 运算符 (C++) | Microsoft Docs
C++ new的三种面貌 - 腾讯云开发者社区-腾讯云 (tencent.com)
https://zh.m.wikipedia.org/zh/New_(C++)
C library function - malloc() (tutorialspoint.com)
Difference between delete and free() in C++ (includehelp.com)
struct
【C++】struct和class的区别 - 知乎 (zhihu.com)
Difference between Structure and Class in C++ - javatpoint
No == operator found while comparing structs in C++ - Stack Overflow
volatile
volatile (C++) | Microsoft Docs
What is volatile keyword in C++? (tutorialspoint.com)
c++ - Why do we use volatile keyword? - Stack Overflow
extern
auto
C++面向对象
面向对象及其三大特性
C++ OOP (Object-Oriented Programming) (w3schools.com)
重写、重载、覆盖(隐藏)
C++中的函数隐藏机制_牛不才的博客-CSDN博客_c++隐藏函数
C++ Programming: Method Overriding Vs. Method Hiding (expertscolumn.com)
虚函数、虚继承
C++ 虚函数和纯虚函数的区别 | 菜鸟教程 (runoob.com)
c++ vptr和vptr_table - 简书 (jianshu.com)
C++基础——虚指针(vptr)与虚基表(vtable)_&动感超人的博客-CSDN博客_vptr
C++对象模型3——vptr的位置、手动调用虚函数、从汇编代码看普通调用和多态调用_Master Cui的博客-CSDN博客
C++:对象模型:关于vptr(虚指针)和vtbl_sheeper200626的博客-CSDN博客
C++ 虚函数表解析_haoel的博客-CSDN博客_虚函数表
C++ Multiple, Multilevel and Hierarchical Inheritance (programiz.com)
Multiple Inheritance in C++ - javatpoint
虚继承中,虚基类在派生类中的内存分布是如何? - 知乎 (zhihu.com)
【c++内存分布系列】虚基类表 - DKMP - 博客园 (cnblogs.com)
C++ 虚继承实现原理(虚基类表指针与虚基类表) - 北极星! - 博客园 (cnblogs.com)
C++ 虚函数表_Linux猿的博客-CSDN博客_c++ 虚函数表
C++动态绑定原理_商汤科技的博客-CSDN博客_动态绑定实现原理
构造/析构函数相关
Default constructors (C++ only) - IBM Documentation
Default constructors - cppreference.com
C++禁止使用拷贝构造函数和赋值运算符方法_我不是萧海哇~~~~的博客-CSDN博客_如何禁用拷贝构造函数
如何禁止自动生成拷贝构造函数? - 简书 (jianshu.com)
c++ - Meaning of = delete after function declaration - Stack Overflow
拷贝构造函数在哪几种情况下会被调用 - 知乎 (zhihu.com)
language agnostic - What is the difference between a deep copy and a shallow copy? - Stack Overflow
类、对象的初始化
C++成员变量的初始化顺序问题_zhaojj1988的博客-CSDN博客
What are initializer lists in C++? (educative.io)
Constructors and member initializer lists - cppreference.com
友元
Friendship and inheritance - C++ Tutorials (cplusplus.com)
C++ Friend Functions and Classes (With Examples) (programiz.com)
Friend Functions and Friend Classes - Cprogramming.com
C++语言特性
左值和右值:区别、引用及转化
从4行代码看右值引用 - qicosmos(江南) - 博客园 (cnblogs.com)
谈谈C++的左值右值,左右引用,移动语意及完美转发 - 知乎 (zhihu.com)
c++引用折叠_kupeThinkPoem的博客-CSDN博客_c++ 引用折叠
Reference declaration - cppreference.com
Value Categories: Lvalues and Rvalues (C++) | Microsoft Docs
Reference declaration - cppreference.com
Understanding lvalues and rvalues in C and C++ - Eli Bendersky's website (thegreenplace.net)
C++ Rvalue References Explained (thbecker.net)
terminology.pdf (stroustrup.com)
Understanding the meaning of lvalues and rvalues in C++ - Internal Pointers
std::move
谈谈C++的左值右值,左右引用,移动语意及完美转发 - 知乎 (zhihu.com)
c++引用折叠_kupeThinkPoem的博客-CSDN博客_c++ 引用折叠
条款23.理解move和forward_干干干就完了的博客-CSDN博客
指针
c++指针运算_EverNoob的博客-CSDN博客_c++ 指针运算
What are Wild Pointers in C/C++? (tutorialspoint.com)
nullptr (C++/CLI and C++/CX) | Microsoft Docs
9.8 — Pointers and const – Learn C++ (learncpp.com)
为什么c语言中对函数名取地址和解引用得到的值一样? - 知乎 (zhihu.com)
Use of '&' operator before a function name in C++ - Stack Overflow
引用
Differences between pointers and references in C++ (educative.io)
c++ - What are the differences between a pointer variable and a reference variable? - Stack Overflow
类型转换
为什么说不要使用 dynamic_cast,需要运行时确定类型信息,说明设计有缺陷? - 知乎 (zhihu.com)
c++的几种类型转换使用场景 - 知乎 (zhihu.com)
(C++ 成长记录) —— C++强制类型转换运算符(static_cast、reinterpret_cast、const_cast和dynamic_cast) - 知乎 (zhihu.com)
C++中的类型转换(static_cast、const_cast、dynamic_cast、reinterpret_cast)_MachineChen的博客-CSDN博客
C H A P T E R 9 - Cast Operations (oracle.com)
参数传递
c++值传递,指针传递,引用传递以及指针与引用的区别 - Mr左 - 博客园 (cnblogs.com)
C++中引用传递与指针传递区别(进一步整理) - - ITeye博客
模板
Templates (C++) | Microsoft Docs
Templates in C++ | C++ Template - All You Need to Know (mygreatlearning.com)
C++ Function Template and Class Template (programmer.group)
c++ - Difference between Class Template and Function Template - Stack Overflow
c++11-17 模板核心知识(四)—— 可变参数模板 Variadic Template - 知乎 (zhihu.com)
模板特化_langminglang的博客-CSDN博客_模板特化
迭代器
<iterator> - C++ Reference (cplusplus.com)
std::iterator - cppreference.com
C++ Iterators (northwestern.edu)
类型萃取
C++之类型萃取_xuzhangze的博客-CSDN博客_c++类型萃取
A quick primer on type traits in modern C++ - Internal Pointers
https://www.youtube.com/watch?v=eVtLOHoDbTo
C++I/O与多线程
C++I/O操作
C++中的IO操作_几亿少女的梦的博客-CSDN博客_c++ io
C++ Basic Input/Output (tutorialspoint.com)
Input/output library - cppreference.com
C++ IO Streams and File Input/Output (ntu.edu.sg)
线程同步与异步
mutex Class (C++ Standard Library) | Microsoft Docs
c++ - Mutex example / tutorial? - Stack Overflow
C++11 并发指南三(std::mutex 详解) - Haippy - 博客园 (cnblogs.com)
C++ 并发编程(二):Mutex(互斥锁) - SegmentFault 思否
unique_lock详解_奇诺比奥大聪明的博客-CSDN博客_uique_lock
std::counting_semaphore, std::binary_semaphore - cppreference.com
std::call_once - cppreference.com
Std::call_once - C++ - W3cubDocs
互斥信号量
C++ 多线程异步(std::async)_GreedySnaker的博客-CSDN博客_std::async
thread::join - C++ Reference (cplusplus.com)
std::async的使用总结 - SegmentFault 思否
C++ std::async 用法與範例 | ShengYu Talk (shengyu7697.github.io)
(原创)用C++11的std::async代替线程的创建 - 南哥的天下 - 博客园 (cnblogs.com)
std::async 的两个坑 - 知乎 (zhihu.com)
条件变量
std::condition_variable - cppreference.com
使用条件变量condition_variable, 什么条件下会虚假唤醒? - SegmentFault 思否
为什么条件锁会产生虚假唤醒现象(spurious wakeup)? - 知乎 (zhihu.com)
C语言中pthread_cond_wait 详解_绛洞花主敏明的博客-CSDN博客_pthread_cond_wait 详解















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









