







 本文介绍了Haar分类器在人脸检测中的应用,重点讲解了AdaBoost算法的工作流程,包括弱分类器的选择、训练以及如何构建强分类器的级联结构。通过级联分类器,可以高效地筛选图像中的潜在人脸区域,提高检测速度和精度。
本文介绍了Haar分类器在人脸检测中的应用,重点讲解了AdaBoost算法的工作流程,包括弱分类器的选择、训练以及如何构建强分类器的级联结构。通过级联分类器,可以高效地筛选图像中的潜在人脸区域,提高检测速度和精度。
引言:
上一小节对矩形特征和积分图的相关概念作了简要介绍,然后我们要利用积分图对矩形特征的计算进行人脸检测算法中弱分类器的选取。
Haar分类器是一个监督学习分类器。要进行物体的检测,首先要对图像进行直方图均衡化并归一化到同样大小,然后标记里面是否包含要检测的物体,故人脸检测也不例外。
Haar分类器使用AdaBoost算法,但是把它组织为筛选式的级联分类器,每个节点是多个树构成的分类器,且每个节点的正确识别率很高。在任一级计算中,一旦获得“不在类别中”的结论,则计算终止。只有通过分类器中所有级别,才会认为物体被检测到。这样的优点是当目标出现频率较低的时候(即人脸在图像中所占比例小时),筛选式的级联分类器可以显著地降低计算量,因为大部分被检测的区域可以很早被筛选掉,迅速判断该区域没有要求被检测的物体。
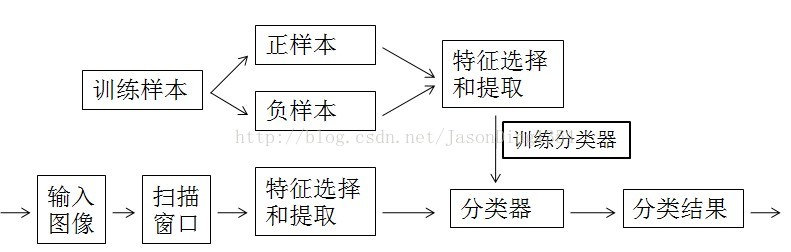
图1 物体检测流程框架图
1、Boosting提升算法简述
Boosting算法涉及到两个重要的概念就是弱学习和强学习,所谓的弱学习,就是指一个学习算法对一组概念的识别率只比随机识别好一点,所谓强学习,就是指一个学习算法对一组概率的识别率很高。Kearns和Valiant提出了弱学习和强学习等价的问题 ,并证明了只要有足够的数据,弱学习算法就能通过集成的方式生成任意高精度的强学习方法。
针对Boosting的若干缺陷,Freund和Schapire于1996年前后提出了一个实际可用的自适应Boosting算法AdaBoost,AdaBoost目前已发展出了大概四种形式的算法,Discrete AdaBoost、Real AdaBoost、LogitBoost、gentle AdaBoost。
2、AdaBoost算法流程
Boosting是一个迭代的过程,用来自适应地改变训练样本的分布,使得基分类器聚焦在那些很难分的样本上。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8178
8178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









