







爬取网页内容
第三方库:BeautifulSoup,sqlite3,urllib,xlwt,re
#-*- codeing = utf-8 -*-
from bs4 import BeautifulSoup
import sqlite3
import xlwt
import urllib.request,urllib.error
import re
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
print("get data")
#2.解析数据
#3.保存数据
# savepath = "douban_top250.xls"
# saveData(datalist,savepath)
dbpath="movie250.db"
saveData2(datalist, dbpath)
# print("hello")
#爬取网页
def getData(baseurl):
datalist=[]
#2.逐一解析
for i in range(0,10): #页面
url=baseurl + str(i*25)
html=askURL(url)
#寻找电影链接
findlink=re.compile(r'<a href="(.*?)">')
findImgSrc=re.compile(r'<img.*src="(.*?)"',re.S)
findTitle=re.compile(r'<span class="title">(.*)</span>')
findRating=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findComment=re.compile(r'<span>(\d*)人评价</span>')
findInq=re.compile(r'<span class="inq">(.*)</span>')
#详情
findBd=re.compile(r'<p class="">(.*?)</p>',re.S)
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
data=[] #保存每一部电影的所有信息
item=str(item)
# print(item)
# break
title=re.findall(findTitle, item)
if(len(title)==2):
ctitle=title[0]
data.append(ctitle)
otitle=title[1].replace("/","")
otitle=re.sub('\s', " ", otitle)
data.append(otitle)
else:
data.append(title[0])
data.append('') #外国名留空
link=re.findall(findlink, item)[0]
data.append(link)
imgsrc=re.findall(findImgSrc, item)[0]
data.append(imgsrc)
inq=re.findall(findInq, item)
data.append(inq[0] if(len(inq)) else "")
rating=re.findall(findRating, item)[0]
data.append(rating)
comment=re.findall(findComment, item)[0]
data.append(comment)
bd=re.findall(findBd, item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?', " ", bd)
bd=re.sub('/', " ", bd)
bd=re.sub('\s', "", bd)
data.append(bd.strip())
datalist.append(data)
# print(datalist)
return datalist
def askURL(url):
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36 Edg/91.0.864.71"
}
# url="https://www.douban.com"
data = bytes(urllib.parse.urlencode({'name':'eric'}),encoding='utf-8')
#封装request
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
# print(response.read().decode("utf-8"))
return response
def saveData(datalist,savepath):
workbook=xlwt.Workbook(encoding='utf-8',style_compression=0)
worksheet=workbook.add_sheet('douban_top250',cell_overwrite_ok=True)
col=('电影名','外文名','电影链接','图片','概况','评分','评价人数','相关信息')
for i in range(0,8):
worksheet.write(0,i,col[i])
for i in range(0,250):
print("第%d条"%i)
data=datalist[i]
for j in range(0,8):
worksheet.write(i+1,j,data[j])
workbook.save(savepath)
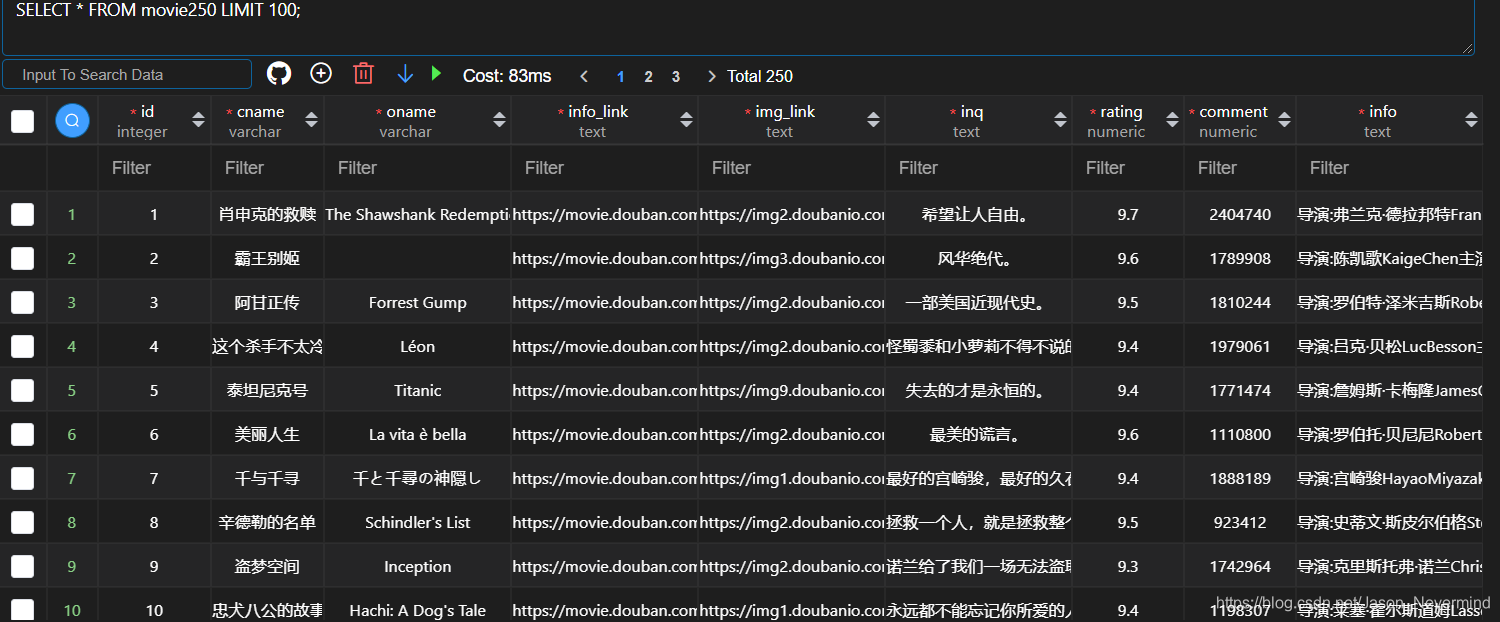
def saveData2(datalist,dbpath):
# initDb(dbpath)
conn=sqlite3.connect(dbpath)
c=conn.cursor()
n=1
for data in datalist:
for i in range(len(data)):
data[i] = '"'+data[i]+'"'
sql='''insert into movie250
values(%d,%s)
'''%(n,",".join(data))
# print(sql)
c.execute(sql)
conn.commit()
print("第%d条"%(n))
n+=1
c.close()
conn.close()
def initDb(dbpath):
sql='''create table movie250(
id integer primary key autoincrement,
cname varchar,
oname varchar,
info_link text,
img_link text,
inq text,
rating numeric,
comment numeric,
info text
)'''
conn=sqlite3.connect(dbpath)
c=conn.cursor()
c.execute(sql)
conn.commit()
conn.close()
if __name__=="__main__":
# try:
# response = urllib.request.urlopen("http://www.baidu.com",timeout=0.01)
# print(response.read().decode('utf-8'))
# except urllib.error.URLError as e:
# print("time out!")
#伪装浏览器,request headers
url1="http://httpbin.org/post"
#urllib.error.HTTPError: HTTP Error 418: (我是一个茶壶,豆瓣反爬虫)
# response = urllib.request.urlopen("https://www.douban.com")
# print(response.read().decode("utf-8"))
# foo = open("./index1.html","wb")
# foo.write(response.read())
# foo.close()
# file = open("./baidu.html","rb")
# html = file.read()
# bs = BeautifulSoup(html,"html.parser")
# print(bs.title.string)
# print(type(bs.head))
# print(bs.a.attrs)
# print(bs)
# getData("https://movie.douban.com/top250?start=")
main()
# initDb("movie250.db")
配置flask框架
flask是python下一款轻量级web框架,只用很少的代码就可以搭建一个web服务。
from flask import Flask,render_template,request
import datetime
import sqlite3
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!你好世界!"
@app.route("/index")
def index():
return render_template("index.html")
@app.route("/movie")
def movie():
datalist=[]
con = sqlite3.connect("movie250.db")
c=con.cursor()
sql='''
select * from movie250
'''
data = c.execute(sql)
#不能直接断开数据库,data因为游标的关闭而缺失数据,先保存
for i in data:
datalist.append(i)
con.commit()
con.close()
return render_template("movie.html",list=datalist)
@app.route("/score")
def score():
num=[]
score=[]
con = sqlite3.connect("movie250.db")
c=con.cursor()
sql='''
select rating,count(rating) from movie250 group by rating
'''
data = c.execute(sql)
#不能直接断开数据库,data因为游标的关闭而缺失数据,先保存
for i in data:
score.append(i[0])
num.append(i[1])
con.commit()
con.close()
return render_template("score.html",score=score,num=num)
@app.route("/word")
def word():
return render_template("word.html")
@app.route("/team")
def team():
return render_template("team.html")
if __name__ == '__main__':
app.debug = True
app.run(host='localhost', port=5000)
echarts数据可视化
jinja数据传入html界面要{}访问
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: '豆瓣电影top250评分分布'
},
tooltip: {},
legend: {
data:['评分']
},
xAxis: { //分数分布
data: {{ score|tojson }}
},
yAxis: {},
series: [{
name: '部数',
type: 'bar',
data: {{ num|tojson }}
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
jieba分词构建词云
import jieba #分词
from matplotlib import pyplot as plt #绘图,数据可视化
from wordcloud import WordCloud #词云
from PIL import Image #图片处理
import numpy as np #矩阵运算
import sqlite3 #数据库
import re
#准备词云所需的词
con = sqlite3.connect("movie250.db")
cur = con.cursor()
sql = 'select inq from movie250'
data = cur.execute(sql)
text = ""
for item in data:
text+=item[0]
# print(text)
cur.close()
con.close()
#分词
cut = jieba.cut(text)
string = " ".join(cut)
string = re.sub(r"\S\s\S", " ", string)
# print(len(string))
img = Image.open('tree.jpg')
img_arr = np.array(img) #将图片转化成图片数组
wc = WordCloud(
background_color="white",
mask=img_arr,
font_path="msyh.ttc" #字体所在位置
)
wc.generate_from_text(string)
#绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') #显示坐标轴
# plt.show() #显示词云图片
#输出词云图片到文件
plt.savefig("wordcloud.jpg",dpi=500)
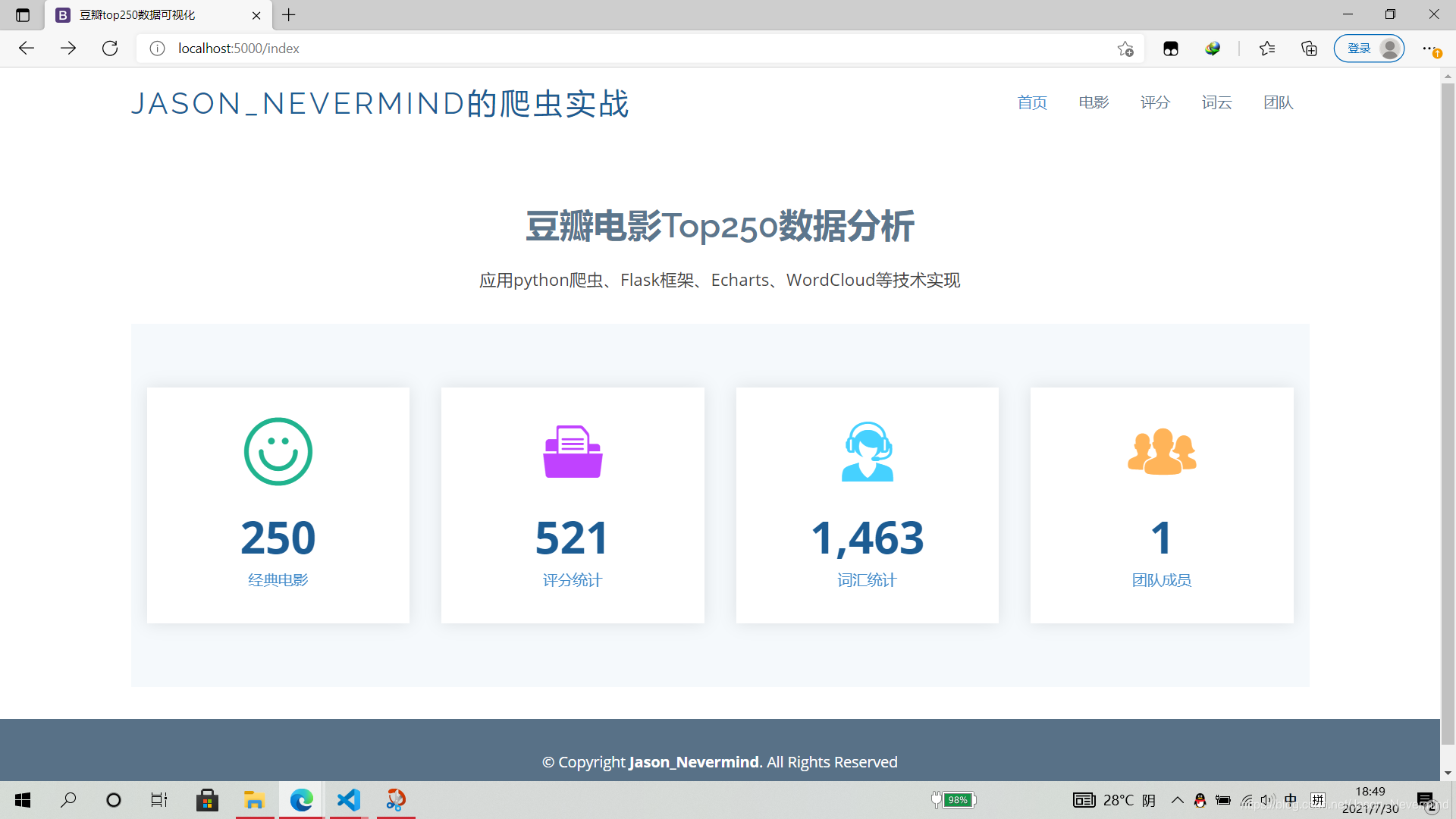
网页展示
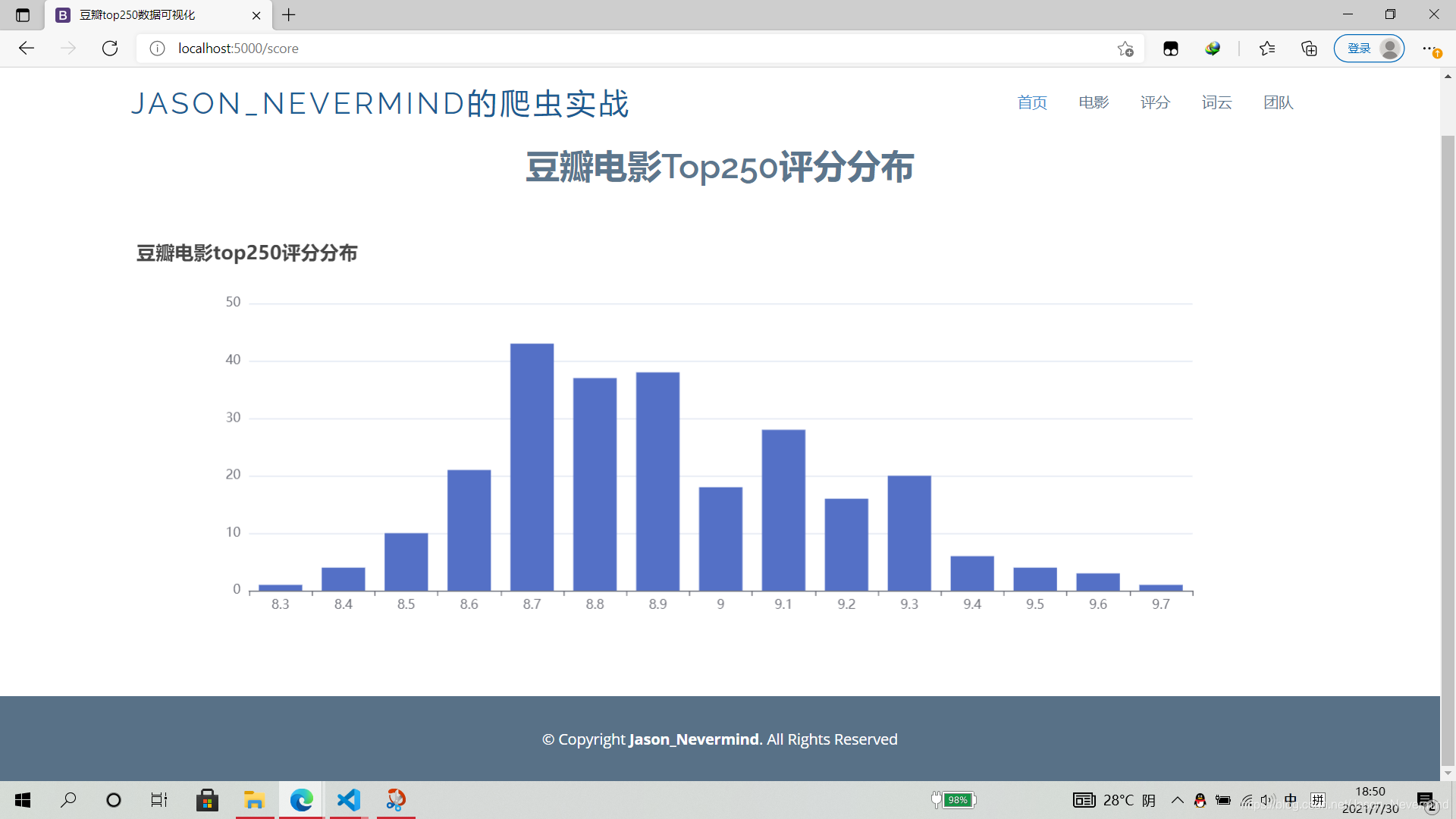
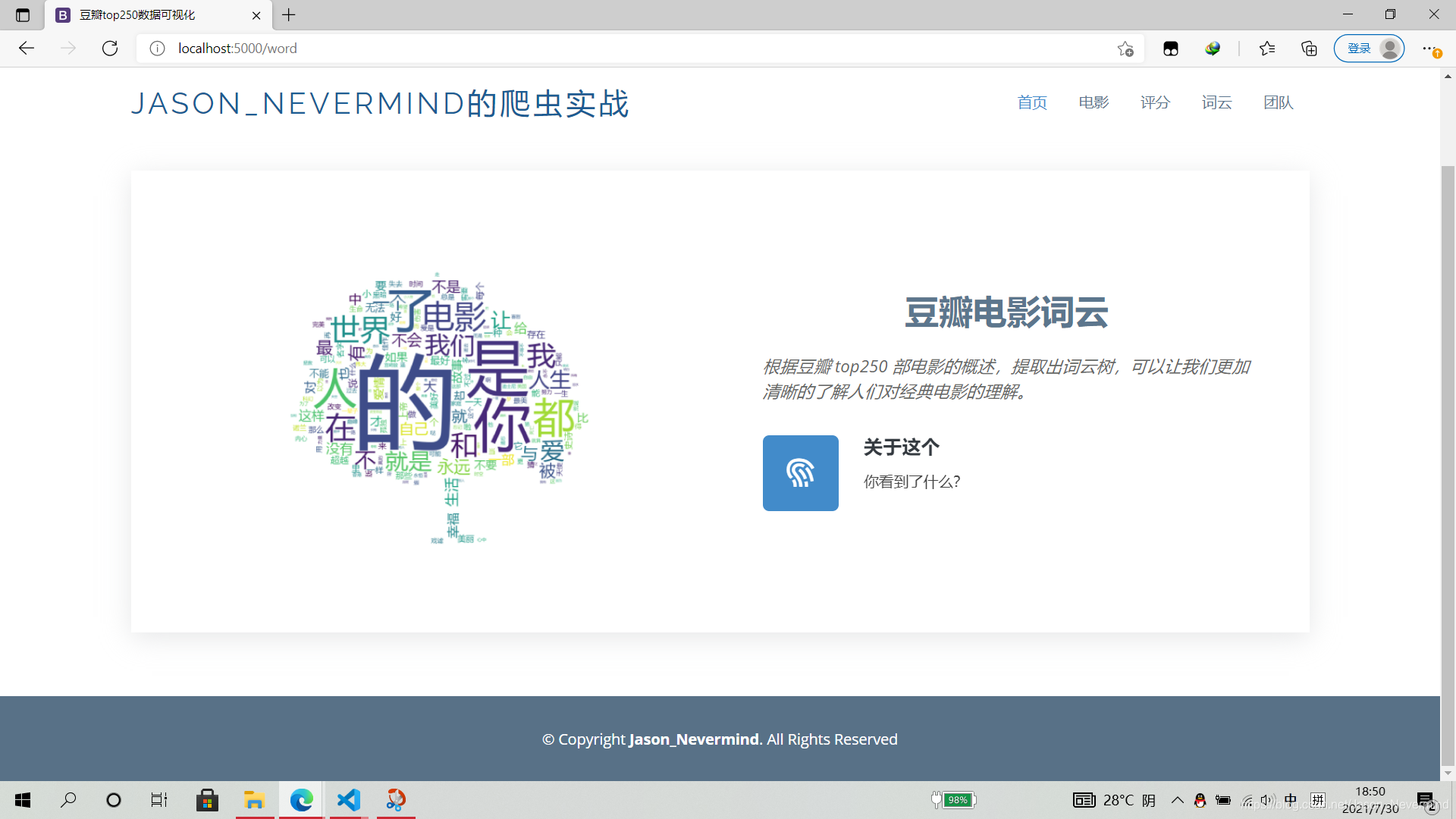
详细代码:github














 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









