







本篇分享论文『Sparse Fusion Mixture-of-Experts are Domain Generalizable Learners』,不同的图像patch由不同的专家模型来处理!南洋理工&Mila稀疏融合混合专家模型SF-MoE,具有超强泛化能力!代码已开源!
详细信息如下:

论文地址:https://arxiv.org/abs/2206.04046
代码地址:https://github.com/Luodian/SF-MoE-DG
01
摘要
领域泛化(DG)旨在学习分布转移下的可泛化模型,以避免冗余的过度拟合海量训练数据。之前关于复杂损失设计和梯度约束的工作尚未在大规模基准上取得实验上的成功。
在这项工作中,作者通过利用分布式处理跨领域预测特征的多个方面,揭示了混合专家(MoE)模型在DG上的可泛化性。为此,作者提出了稀疏融合混合专家模型(SF-MoE),该模型将稀疏性和融合机制结合到MoE框架中,以保持模型的稀疏性和预测性。SF-MoE有两个专用模块:稀疏块和融合块,分别对对象的不同学习信号进行分离和聚合。
大量实验表明,SF-MoE是大规模基准测试领域的可泛化学习者。它在5个大型DG数据集(如DomainNet)中的表现优于最先进的同类模型2%以上,计算成本相同甚至更低。作者进一步从分布式表示的角度(如视觉属性)揭示了SF-MoE的内部机制。
02
Motivation
泛化到分布外(OOD)数据对人类来说是一种天生的能力,但对机器学习模型来说是一种挑战。为了解决这个问题,领域泛化(DG)研究鼓励模型在面对各种分布变化时具有弹性,如照明、纹理、背景和地理/人口因素。
为了实现模型的可泛化性,学习DG的领域不变表示已被广泛探索,因为它们具有理论基础。然而,它们的性能在大规模DG基准上受到了挑战。一方面,强有力的证据表明,在领域适应( domain adaptation)问题中,仅学习领域不变表示是不够的。如果边缘标签分布在不同的训练域中不同,域不变方法可能会损害目标域的泛化性能。另一方面,最近的工作也考虑了对领域特定信息的利用,提出了多个网络分别捕获和对齐领域特定信息,或同时利用领域不变网络和领域特定网络。
同时,另一系列研究发现,当主干网络和数据集变得更大时,简单的baseline可以匹配甚至优于现有的具有复杂设计的DG方法。例如,之前有工作训练了一个 linear probing MLP,将样本动态路由到多个具有不同架构的预训练网络。这些结果启发研究者关注模型架构或训练范式的修改,以便在大规模DG基准上取得更好的绩效。
什么结构具有更好的泛化能力?最近的研究表明,基于彩票假设的原理,包含子网的密集网络可以比原始的全网络实现更好的域外泛化性能。理想结构可以通过寻求稀疏性和预测性来消除虚假特征。因此,作者认为在稠密网络中改善稀疏性并保持其预测性将在领域泛化中发挥重要作用。
稀疏混合专家(稀疏MoE)模型被认为是一种很有希望的方法,可以在依赖输入的路由机制中将密集模型缩放为稀疏模型。具体而言,稀疏MoE模型可以看作是子网络的动态集合。这种训练范式在广泛的应用领域取得了实验上的成功,尤其是在自然语言处理领域和计算机视觉领域。然而,目前还没有研究稀疏MoE的工作机理并将其与DG联系起来的工作。
在本文中,作者通过利用分布式处理跨领域预测特征的多个方面,揭示了混合专家(MoE)模型在DG上的可推广性。本文提出了稀疏融合混合专家模型(SF-MoE),该模型结合了稀疏性和融合机制,以保持模型的稀疏性和预测性。

SF-MoE包括稀疏块和融合块,如上图所示。稀疏块由多头注意力(MHA)层和混合专家(MoE)层组成。MHA层关注稀疏信号,并在patch(特征子集)之间建立自注意力。然后,MoE层通过向不同的专家分发patch来进一步分离所学的注意力。稀疏块以grid-wise方式工作,如下图所示。

然而,增加稀疏性也会给训练带来困难。因此,作者引入了一个融合块,它由MHA层和密集前馈网络(FFN)层组成。密集FFN学习跨patch集成位置信息,并转换MHA层的稀疏信号。
为了进一步节省计算成本并提高性能,作者提出了一种高效的变体:混合SF-MoE,它由一个ResNet主干组成,用于将原始图像中的特征压缩并提取到较小的patch中(与普通的patch嵌入相比)。总的来说,如下图所示,SF MoE以类似甚至更低的训练成本,大幅优于其他最先进的模型。

总的来说,本文的主要贡献总结如下:
一种新的DG模型:SF-MoE:为了寻求一种既稀疏又具有预测性的良好结构,作者提出了稀疏融合专家混合模型,即SF-MoE,这是一种统一的结构,稀疏地处理鉴别特征的多个方面。
出色的性能和效率:为了证明本文提出的稀疏体系结构SF MoE的有效性,作者在8个大规模DG数据集上提供了大量的实验结果。SF MoE和混合SF MoE在5个数据集中以类似甚至更低的成本超过其他最先进的同类模型2%以上。
SF-MoE的模型分析:为了从内部了解SF-MoE的工作机制,作者提出了一个诊断数据集CUB-DG,用于研究1)不同图像样式域的泛化性能,以及2)专家决策与图像中视觉属性之间的相关性。作者还研究了不同注意力头和路由中学习到的注意对稀疏块泛化性能的影响。
03
方法
3.1 Preliminary: ViT and Multi-Head Attention
SF-MoE构建在视觉Transformer上,它包含两个基本组件,即多头注意力(MHA)层和前馈网络(FFN)层。每个层都使用残差连接和层归一化进行构造。最近的研究表明,多头注意力和FFN层中的子层具有固有的整体子结构。每个层中的子结构可以看作是较小稀疏模型的集合。具体而言,将投影权重矩阵按行分为h个部分,因此。给定一系列patch由patch嵌入层处理,以及一个查询向量。一个多头注意力层由权重矩阵参数化,可并行计算h个头,以获得最终结果:
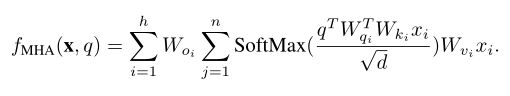
在这种情况下,多头注意力机制可以被视为通过整合多个注意头来共同关注多个地方,每个注意头都专注于所有patch之间的特定注意关系。这也揭示了多头注意力的内在协作机制。
然而,最近的研究表明,多头注意层可以学习冗余的键/查询投影,即一些头部可能会注意到输入空间中的类似特征。为了说明这个问题,作者考虑两个头和计算相同的键/查询表示得到 unitary matrix ,因此。
在这种情况下,即使两个头部计算的注意力得分相同,即,也可以是满秩的,这表明一些注意力集中在相同的内容上,但彼此不可知。
3.2 Sparse Blocks: Disentangling Attentions

为了避免头的冗余并提高网络稀疏性,作者在多头部注意力(MHA)层之后引入了一个混合专家(MoE)层,并将其命名为稀疏块。接下来,作者研究了稀疏块中的固有解纠缠和稀疏机制。
在上图中,以grid方式呈现,MHA层关注不同头部的不同信号(特征),而MoE层通过将每个patch处理给不同的专家来分离信息。这种机制扩展了网络的稀疏性,因此能够提高模型的泛化能力。总之,稀疏块旨在利用不同的专家来建模不同图像信号之间的关系,而不是显式捕获域不变/特定信息。

为了证实这一点,作者对在DomainNet(所有域)上训练的vanilla ViT和SF MoE进行了实验,并使用来自真实域的验证图像捕获它们的多头注意力输出。上图中的鸟图像示例表明,ViT头的注意力区域在很大程度上重叠,而本文提出的SF-MoE有两个头(head 1、2)聚焦于图像背景,三个头(head 3、5、6)关注鸟爪,一个头(head4)关注鸟喙。
具体而言,将N个专家表示为、 每个都具有特定的可学习权重,并且在层内不共享。作者使用多个FFN作为专家,表示为,其中是每个专家中两层MLP的参数,是非线性激活函数。作者使用gating网络将前一块输出的每个token路由给不同的专家。MoE层表示为:

其中是FFN层的输入和是路由函数,它规定了专家的输入条件权重,例如,表示为x选择专家的概率。
路由函数具体定义为,其中,操作是一个one-hot嵌入,将输出向量中的所有其他元素设置为零,但k值最大的元素除外。
3.3 Fusion Blocks: Aggregating Attentions
在稀疏块中,MoE层利用路由网络来学习patch到专家的affinity。理论上,学习的路由网络应该将相同或相关的patch分配给同一专家。理想情况下,当所有patch都对路由网络保持不变时,次优策略将导致少数专家适应大多数patch,而其余专家则参数化不足。这将使训练更具挑战性,因为不同层次的更多专家将需要更多的训练数据,这些数据对于每个专家来说都是适当平衡的。
如上图所示,不断添加稀疏块(例如,[S]×12)会导致性能下降。作者认为,稀疏性的增加也会导致保留更多虚假信息。更多的虚假信息会篡改网络以捕获训练数据中的虚假相关性,也会削弱泛化性能。
由于上述困难,无法直接应用具有完全稀疏块模式的V-MoE结构。为了缓解这个问题,作者提出了一种具有MHA层和密集FFN层的融合块。
根据经验,作者设定k=2d。如果k=d,融合块降级为基本ViT块。密集FFN层集成并转换不同头之间的不同注意力。因此,上表图中的实验研究表明,平衡稀疏/融合块的数量(例如,6个稀疏块,6个融合块)将提高三个数据集中的域外泛化性能。
3.4 Hybrid SF-MoE: Integrating Convolutional Features
多头注意力和稀疏/融合块的主要元素是MLP,这可以提高信息的利用率,同时也增加了计算成本。一种自然的变体是将CNN与Transformer结构相结合。作者采用这种设计,并引入ResNet主干来进行patch嵌入。ResNet patch嵌入层将提取一个比原来的16×16 patch嵌入小得多的特征图,并且仍然保留局部信息。由于图像包含自然图像中像素之间的冗余信息,该特性对DG任务产生了积极影响。作者采用在ImageNet-21k上预训练并在ImageNet-1k上微调的HybridViT,然后用稀疏/融合块替换HybridViT的基本块。为了进行公平的比较,作者将混合SF MoE与同样在ImageNet-21k数据集上预训练的其他模型进行了比较。混合SF MoE可以在运行时内存和吞吐量时间最低的大型数据集上提高性能。
04
实验
DomainBed上的结果如上表所示,其中包括baseline方法和最新的最新方法。从训练域验证选择的结果来看,SFMoE在大多数数据集上都优于其他模型。

作者还在另外三个大型数据集:SVIRO、WildsCamelyon、Wilds FMOW上对本文的方法进行了实验。它们的规模相似,能够捕捉到现实世界中各个领域的分布变化。
作者在DomainBed中采用了数据预处理和域分割。由于没有发现以前的研究使用相同的标准对其方法进行实验,因此作者只报告本文的方法和baseline的结果。上表中的结果显示,SF MoE在SVIRO和WildsFMOW中大大超过了baseline。

为了了解SF MoE的内部工作原理,作者从Caltech-UCSD Birds (CUB)数据集中创建了CUB-DG。在CUB-DG中,首先将原始图像样式化为三个域:Candy、Mosaic和Udnie。图像示例如上表左侧所示。CUB-DG数据集为每个鸟类图像提供视觉属性(例如鸟喙的颜色)。
然后在MoE层测量视觉属性与专家选择之间的相关性。由于样式化不会修改对象的形状和轮廓,不同的域将具有很强的不变性先验知识。通过这种方式,可以使用许多其他解决域不变表示学习的方法来评估SF MoE在图像样式化方面的泛化性能。上表右侧的结果表明,SF MoE的性能大大优于其他最先进的方法。

为了评估SF MoE及其有效变体,即混合SF MoE,作者对训练步长时间和运行时显存进行了效率分析。这样,具有更复杂损失设计或梯度约束的不同算法将导致这两个指标发生更大的变化。从上表的结果中,可以观察到SF MoE和混合SF MoE几乎是所有模型中运行时显存和训练step最低的。
05
总结参考资料
[1]https://arxiv.org/abs/2206.04046[2]https://github.com/Luodian/SF-MoE-DG
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch















 5239
5239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









