







经典回顾 | 检索任务的经典工作VSE++
【写在前面】
作者提出了一种用于学习跨模态检索的视觉语义嵌入的新技术。受难例挖掘、结构化预测中难例的使用和损失函数排名的启发,作者对用于多模态嵌入的常见损失函数进行了简单的更改。结合微调和增强数据的使用,可以显着提高本文的方法 VSE++,使用消融研究和与现有方法的比较。在 MS-COCO 上,本文的方法在字幕检索方面比最先进的方法高出 8.8%,在图像检索方面高出 11.3%(在 R@1 时)。
1. 论文和代码地址

VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
论文地址:http://www.bmva.org/bmvc/2018/contents/papers/0344.pdf
代码地址:https://github.com/fartashf/vsepp
2. 动机
联合嵌入支持图像、视频和语言理解方面的广泛任务。示例包括用于形状推断的形状图像嵌入、双语词嵌入、用于 3D 姿势推断的人体姿势图像嵌入 、细粒度识别、zero-shot 学习和通过合成进行模态转换。这种嵌入需要从两个(或更多)域映射到一个公共向量空间,其中语义相关的输入(例如,文本和图像)被映射到相似的位置。因此,嵌入空间代表了底层域结构,其中位置和方向通常在语义上是有意义的。
视觉语义嵌入一直是图像标题检索和生成以及视觉问答的核心。例如,视觉问答的一种方法是首先通过一组标题描述图像,然后找到最近的标题以响应问题。对于文本的图像合成,可以从文本映射到联合嵌入空间,然后再返回到图像空间。
在这里,作者专注于跨模态检索的视觉语义嵌入;即检索给定标题的图像,或查询图像的标题。在检索中很常见,作者通过 R@K 来衡量性能,即在 Top-K 处的召回率。更一般地说,检索是评估图像和语言数据联合嵌入质量的一种自然方式。
正确的目标应该比语料库中的其他项目更接近查询,这与学习对问题进行排序和 max margin 结构化预测 不同。本文中的公式和模型架构与VSE中的公式和模型架构最密切相关,通过三元组排序损失学习。与这项工作相比,作者提出一种新的损失、增强数据的使用和微调,与众所周知的基准数据上的baseline排名损失相比,它们共同产生了字幕检索性能的显着提高。作者在 MS-COCO 上的最佳报告结果高出近 9%。作者还表明,使用本文更强的损失函数可以放大更强大的图像编码器和微调的好处。作者将本文的模型称为 VSE++。
本文的主要贡献是在损失函数中加入难例挖掘。这受到在分类任务中使用难例挖掘以及使用难例来改进人脸识别的图像嵌入的启发。使用难例挖掘最小化损失函数等效于使用均匀采样最小化修改后的非透明损失函数。作者通过在多模态嵌入的损失中明确引入难例定来扩展这一想法,而无需任何额外的挖掘成本。
3. 方法
对于图像标题检索,查询是标题,任务是从数据库中检索最相关的图像。或者,查询可能是图像,任务是检索相关标题。目标是在 K (R@K) 处最大化召回率,即最相关项目在返回的前 K 个项目中排名的查询比例。
令 S = { ( i n , c n ) } n = 1 N S=\left\{\left(i_{n}, c_{n}\right)\right\}_{n=1}^{N} S={(in,cn)}n=1N为图像-字幕对的训练集。作者将 ( i n , c n ) \left(i_{n}, c_{n}\right) (in,cn)称为正对,将 ( i n , c m ≠ n ) \left(i_{n}, c_{m \neq n}\right) (in,cm=n)称为负对;即,与 i n i_{n} in 中的图像最相关的标题是 c n c_n cn。作者定义了一个相似函数 s ( i , c ) ∈ R s(i, c) \in \mathbb{R} s(i,c)∈R,理想情况下,它应该给正对比负对更高的相似度分数。在字幕检索中,查询是图像,作者根据相似度函数对字幕数据库进行排名;即,R@K 是使用 s ( i , c ) s(i, c) s(i,c)在前 K 个标题中排名的查询百分比。图像检索也是如此。在下文中,相似函数定义在联合嵌入空间上。这与其他公式不同,后者使用相似性网络直接将图像-字幕对分类为匹配或不匹配。
3.1 Visual-Semantic Embedding
设 ϕ ( i ; θ ϕ ) ∈ R D ϕ \phi\left(i ; \theta_{\phi}\right) \in \mathbb{R}^{D_{\phi}} ϕ(i;θϕ)∈RDϕ 是从图像 i 计算的基于特征的表示。类似地,令 ψ ( c ; θ ψ ) ∈ R D ψ \psi\left(c ; \theta_{\psi}\right) \in \mathbb{R}^{D_{\psi}} ψ(c;θψ)∈RDψ 是字幕嵌入空间中字幕 c 的表示(例如基于 GRU 的文本编码器)。在这里, θ φ θ_φ θφ 和 θ ψ θ_ψ θψ 表示对应到这些初始图像和字幕表示的映射的模型参数。
然后,让到联合嵌入空间的映射由线性投影定义:
f ( i ; W f , θ ϕ ) = W f T ϕ ( i ; θ ϕ ) g ( c ; W g , θ ψ ) = W g T ψ ( c ; θ ψ ) \begin{aligned} f\left(i ; W_{f}, \theta_{\phi}\right) &=W_{f}^{T} \phi\left(i ; \theta_{\phi}\right) \\ g\left(c ; W_{g}, \theta_{\psi}\right) &=W_{g}^{T} \psi\left(c ; \theta_{\psi}\right) \end{aligned} f(i;Wf,θϕ)g(c;Wg,θψ)=WfTϕ(i;θϕ)=WgTψ(c;θψ)
其中 W f ∈ R D ϕ × D W_{f} \in \mathbb{R}^{D_{\phi} \times D} Wf∈RDϕ×D和 W g ∈ R D ψ × D W_{g} \in \mathbb{R}^{D_{\psi} \times D} Wg∈RDψ×D。作者进一步归一化 f ( i ; W f , θ ϕ ) f\left(i ; W_{f}, \theta_{\phi}\right) f(i;Wf,θϕ)和 g ( c ; W g , θ ψ ) g\left(c ; W_{g}, \theta_{\psi}\right) g(c;Wg,θψ),使其位于单位超球面上。最后,将联合嵌入空间中的相似度函数定义为通常的内积:
s ( i , c ) = f ( i ; W f , θ ϕ ) ⋅ g ( c ; W g , θ ψ ) s(i, c)=f\left(i ; W_{f}, \theta_{\phi}\right) \cdot g\left(c ; W_{g}, \theta_{\psi}\right) s(i,c)=f(i;Wf,θϕ)⋅g(c;Wg,θψ)
设 θ = { W f , W g , θ ψ } \theta=\left\{W_{f}, W_{g}, \theta_{\psi}\right\} θ={Wf,Wg,θψ} 为模型参数。如果我们还微调图像编码器,那么还将在 θ 中包含 θ ϕ \theta_{\phi} θϕ。
训练需要最小化关于 θ 的实验损失,即训练数据 S = { ( i n , c n ) } n = 1 N S=\left\{\left(i_{n}, c_{n}\right)\right\}_{n=1}^{N} S={(in,cn)}n=1N的累积损失:
e ( θ , S ) = 1 N ∑ n = 1 N ℓ ( i n , c n ) e(\theta, S)=\frac{1}{N} \sum_{n=1}^{N} \ell\left(i_{n}, c_{n}\right) e(θ,S)=N1n=1∑Nℓ(in,cn)
其中 ℓ ( i n , c n ) \ell\left(i_{n}, c_{n}\right) ℓ(in,cn)是单个训练样本的合适损失函数。受使用三元组损失进行图像检索的启发,最近联合视觉语义嵌入的方法使用了基于hinge的三元组排序损失。
ℓ S H ( i , c ) = ∑ c ^ [ α − s ( i , c ) + s ( i , c ^ ) ] + + ∑ i ^ [ α − s ( i , c ) + s ( i ^ , c ) ] + , \ell_{S H}(i, c)=\sum_{\hat{c}}[\alpha-s(i, c)+s(i, \hat{c})]_{+}+\sum_{\hat{i}}[\alpha-s(i, c)+s(\hat{i}, c)]_{+}, ℓSH(i,c)=c^∑[α−s(i,c)+s(i,c^)]++i^∑[α−s(i,c)+s(i^,c)]+,
其中 α 作为边距参数,[x]+ ≡ max(x,0)。这种铰链损失包括两个对称项。在给定查询 i 的情况下,第一个总和用于所有负字幕
c
^
\hat{c}
c^。第二个是用于所有负图像
i
^
\hat{i}
i^,给定标题 c。每个项都与负样本集的预期损失成正比。如果 i 和 c 在联合嵌入空间中彼此之间的距离比任何负值都更近,则在边距 α 处,铰链损失为零。在实践中,为了计算效率,而不是对训练集中的所有负数求和,通常只对小batch随机梯度下降中的负数求和(或随机抽样)。计算这种损失近似的运行时复杂度是小batch中图像-字幕对数量的二次方。
当然还有其他的损失函数可以考虑。一种是成对的铰链损失,其中正对的元素被鼓励位于联合嵌入空间中半径为
ρ
1
\rho_{1}
ρ1的超球面内,而负对的距离不应小于
ρ
2
>
ρ
1
\rho_{2}>\rho_{1}
ρ2>ρ1。这是有问题的,因为它比排名损失更多地限制了潜在空间的结构,并且它需要使用两个很难设置的超参数。另一种可能的方法是使用典型相关分析来学习
W
f
W_{f}
Wf 和
W
g
W_{g}
Wg,从而尝试在联合嵌入中保持文本和图像之间的相关性。相比之下,当以 R@K 衡量性能时,对于较小的 K,基于相关性的损失不会对负项在正对的局部附近的嵌入产生足够的影响,这对 R@K 至关重要。
3.2. Emphasis on Hard Negatives
受结构化预测中使用的常见损失函数的启发,作者专注于训练难例,即最接近每个训练查询的负数。这与检索特别相关,因为它是决定 R@1 衡量的成功或失败的最难的否定。
给定一个正数对 ( i , c ) (i, c) (i,c),最难的负样本由 i ′ = arg max j ≠ i s ( j , c ) i^{\prime}=\arg \max _{j \neq i} s(j, c) i′=argmaxj=is(j,c)和 c ′ = arg max d ≠ c s ( i , d ) c^{\prime}=\arg \max _{d \neq c} s(i, d) c′=argmaxd=cs(i,d)给出。为了强调难例,作者将损失定义为:
ℓ M H ( i , c ) = max c ′ [ α + s ( i , c ′ ) − s ( i , c ) ] + + max i ′ [ α + s ( i ′ , c ) − s ( i , c ) ] + \ell_{M H}(i, c)=\max _{c^{\prime}}\left[\alpha+s\left(i, c^{\prime}\right)-s(i, c)\right]_{+}+\max _{i^{\prime}}\left[\alpha+s\left(i^{\prime}, c\right)-s(i, c)\right]_{+} ℓMH(i,c)=c′max[α+s(i,c′)−s(i,c)]++i′max[α+s(i′,c)−s(i,c)]+
损失包括两个项,一个带有 i 和一个带有 c 作为查询。从 SH (Sum of Hinges)损失到 MH (Max of Hinges)损失有一系列损失函数。在 MH 损失中,获胜者获得所有梯度,而本文使用所有三元组的重新加权梯度。这里只讨论 MH 损失,因为根据实验发现它表现最好。
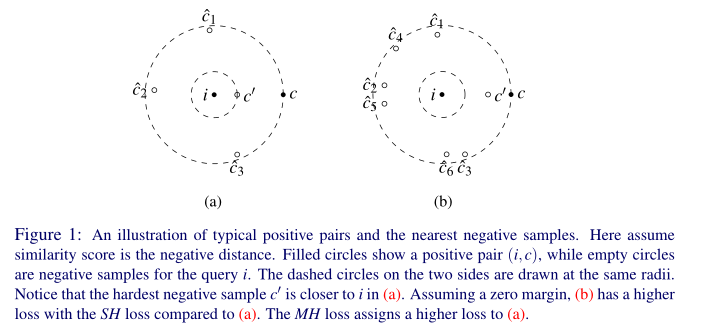
MH 损失优于 SH 的一种情况是,多个具有小violation的负例结合起来主导 SH 损失。例如,上图描绘了一对正数和两组负例。在图上 (a) 中,单个负例与查询太接近,这可能需要对映射进行重大更改。然而,任何将硬负例推开的训练步骤都可能导致一些小的violation负例,如上图(b) 所示。使用 SH 损失,这些“新”负值可能会主导损失,因此模型被推回到上图(a) 中的第一个示例。这可能会在 SH 损失中产生局部最小值,这对于 MH 损失来说可能没有问题,MH 损失集中在最难的负例上。
为了计算效率,作者不是在整个训练集中找到最难的负样本,而是在每个小batch中找到它们。这与 SH 损失的复杂度具有相同的二次复杂度。通过小batch的随机抽样,这种近似产生了其他优点。一是很有可能得到比整个训练集至少 90% 更难的难负样本。此外,损失对于标记训练数据中的错误具有潜在的鲁棒性,因为在整个训练集中对最难的负样本进行采样的概率有点低。
4.实验
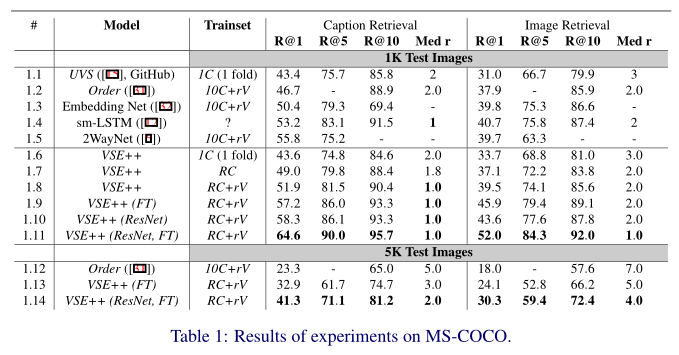
MS-COCO 实验结果。
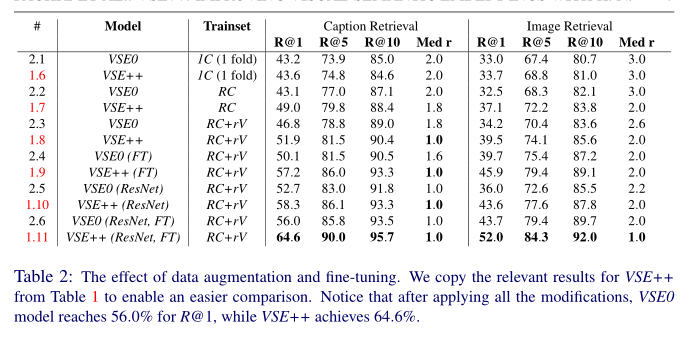
数据增强和微调的效果。
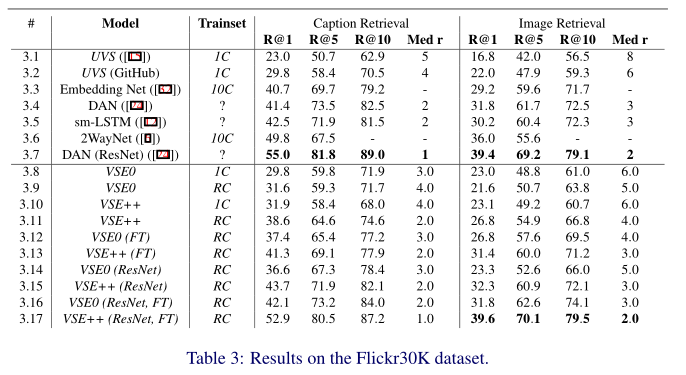
Flickr30K 数据集上的结果。
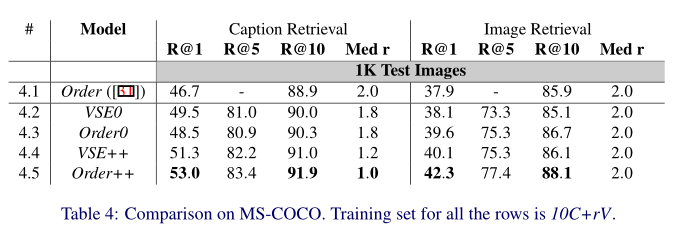
MS-COCO 上的比较。
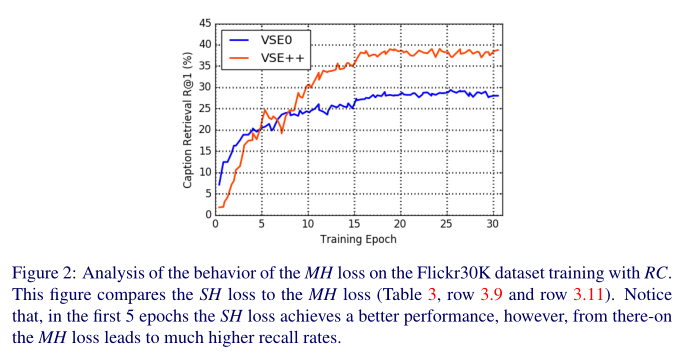
使用 RC 训练 Flickr30K 数据集上的 MH 损失行为分析。

根据经过训练的 VSE++ 模型的损失,来自 Flickr30K 训练集的示例及其在随机小批量中的难例样本。
5. 总结
本文的重点是学习用于跨模态、图像标题检索的视觉语义嵌入。受结构化预测的启发,作者提出了一种新的损失,该损失基于与使用预期错误的当前方法相比相对较难的负样本所导致的violation。作者在 MS-COCO 和 Flickr30K 数据集上进行了实验,并表明提出的损失显着提高了这些数据集的性能。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

“点个在看,月薪十万!”
“学会点赞,身价千万!”















 2459
2459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









