









人工智能必备数学基础
https://blog.csdn.net/Java_rich/article/details/120361765?spm=1001.2014.3001.5501
https://blog.csdn.net/Java_rich/article/details/120412229?spm=1001.2014.3001.5501
为了方便大家学习交流,我建了一个扣裙:966367816(学习交流、大牛答疑、大厂内推)
另外我还整理了整整200G的人工智能学习笔记、课程视频、面试宝典一并可以无套路免费
分享给大家!
什么是word2vec
word2vec 是 Google 在 2013 年年中开源的一款将词表征为实数值向量的高效 工具,采用的模型有 CBOW(Continuous Bag-Of-Words,即连续的词袋模型)和 Skip-Gram 两种。
word2vec 一般被外界认为是一个 Deep Learning(深度学习)的模型,究其原 因,可能和 word2vec 的作者 Tomas Mikolov 的 Deep Learning 背景以及 word2vec 是一种神经网络模型相关,但我们谨慎认为该模型层次较浅,严格来说还不能算 是深层模型。当然如果 word2vec 上层再套一层与具体应用相关的输出层,比如 Softmax,此时更像是一个深层模型。
word2vec 通过训练,可以把对文本内容的处理简化为 K 维向量空间中的向量 运算,而向量空间上的相似度可以用来表示文本语义上的相似度。因此,word2vec 输出的词向量可以被用来做很多 NLP 相关的工作,比如聚类、找同义词、词性分 析等等。
word2vec 被人广为传颂的地方是其向量的加法组合运算(Additive Compositionality ), 官 网 上 的 例 子 是 : vector('Paris') - vector('France') + vector('Italy') ≈vector('Rome'),vector('king') - vector('man') + vector('woman') ≈ vector('queen')。
word2vec 也只是少量的例子完美符合 这种加减法操作,并不是所有的 case 都满足。 word2vec 大受欢迎的另一个原因是其高效性。
快速入门
1.针对个人需求修改 makefile 文件,比如作者使用的 linux 系统就需要把 makefile 编译选项中的-Ofast 要更改为-O2 或者-g(调试时用),同时删除编译器 无法辨认的-march=native 和-Wno-unused-result 选项。有些系统可能还需要修改 相关的 c 语言头文件,具体可能得去网上搜。
2.运行“make”编译 word2vec 工具。
3.运行 demo 脚本:./demo-word.sh demo-word.sh 中的代码如下,主要工作为:
1) 编译(make)
2) 下载训练数据 text8,如果不存在。text8 中为一些空格隔开的英文单 词,但不含标点符号,一共有 1600 多万个单词。
3) 训练,大概一个小时左右,取决于机器配置
4) 调用 distance,查找最近的词

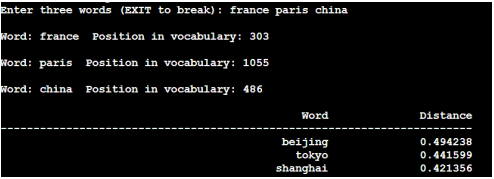
训练完毕后,输入 china 就会找出与其最相近的词:

4.也可以自己执行其他相关的程序,比如作者比较推崇的向量加减法操作, 在命令行执行./word-analogy vectors.bin 即可。相关结果如下:
5.模型的输出 vectors.bin 是每个词及其对应的浮点数向量,只是默认为二进 制的,不好查看,如果想要查看文本形式,请在训练时把 binary 选项设置为 0。
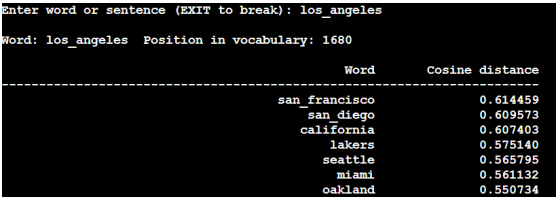
6.也可以./demo-phrases.sh 进行短语训练,这样 los angeles 就会被当成一个 整体来看待。distance 的相关测试如下:
7.如果是中文的语料,则需要调用相应的分词工具将预料中的词用空格隔开
优缺点
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用。
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
模型
1.CBOW (Continuous Bag-of-Words Mode)
是一种与前向 NNLM 类似 的模型,不同点在于 CBOW 去掉了最耗时的非线性隐层且所有词共享隐层。如 下图所示。可以看出,CBOW 模型是预测 P(wt|wt-k,wt-(k-1)…,wt-1,wt+1,wt+2…,wt+k)。

2.Skip-Gram
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。

从图中看应该 Skip-Gram 应该预 测概率 p(wi |wt),其中𝑡 − 𝑐 ≤ 𝑖 ≤ 𝑡 + 𝑐且𝑖 ≠ 𝑡,c 是决定上下文窗口大小的常数, c 越大则需要考虑的 pair 就越多,一般能够带来更精确的结果,但是训练时间也 会增加。假设存在一个 w1,w2,w3,…,wT的词组序列,Skip-gram 的目标是最大化:
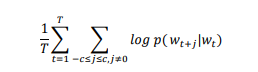
基本的 Skip-Gram 模型定义 p(wO|wI)为:
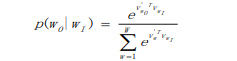
从公式不能看出,Skip-gram 是一个对称的模型,如果 wt 为中心词时 wk在其 窗口内,则 wt 也必然在以 wk 为中心词的同样大小窗口内,也就是:
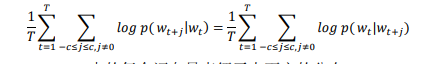
同时,Skip-gram 中的每个词向量表征了上下文的分布。Skip-gram 中的 skip 是指在一定窗口内的词两两都会计算概率,就算他们之间隔着一些词,这样的好 处是“白色汽车”和“白色的汽车”很容易被识别为相同的短语。
关注我了解更多的人工智能专业知识
强烈建议配合课件资料一起学习!效果最好!
需要课件配套课件资料和源码笔记的伙伴可以加微信领取的哦~
为了方便大家学习交流,我建了一个扣裙:966367816(学习交流、大牛答疑、大厂内推)
另外我还整理了整整200G的人工智能学习笔记、课程视频、面试宝典一并可以无套路免费
分享给大家!
欢迎大家扫码撩我呀~
















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









