










强化学习入门需要系统性掌握基础概念、核心算法、工具平台和实践路径。以下从理论框架、算法体系、应用场景及学习资源四个维度展开深度解析:
一、理论框架构建
马尔可夫决策过程(MDP)是强化学习的数学基础,包含五元组(S, A, P, R, γ):
- 状态空间(S):环境所有可能状态的集合,如棋类游戏的棋盘布局
- 动作空间(A):智能体可执行操作的集合,如机器人关节运动角度
- 状态转移概率(P):P(s'|s,a)表示执行动作a后从状态s转移到s'的概率
- 奖励函数(R):R(s,a)定义在状态s执行动作a的即时奖励,如游戏得分
- 折扣因子(γ):0≤γ≤1,用于平衡当前与未来奖励的权重
价值函数是评估策略优劣的核心指标:
- 状态价值函数Vπ(s)=E[∑γt R_t],衡量状态s在策略π下的长期收益
- 动作价值函数Qπ(s,a)=E[∑γt Rt|at=a],评估特定动作的预期收益
8年经验告诉你,学强化学习的顺序千万不要学反了!博士精讲强化学习dqn及ppo算法原理及实战(人工智能自动驾驶/深度强化学习/超级马里奥/大模型)
二、算法体系演进
主流算法可分为三大类(附典型算法对比):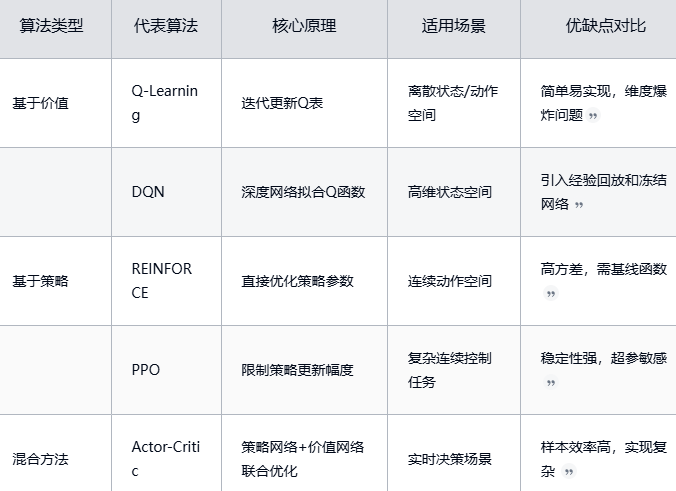
算法选择建议:
- 离散控制选DQN(如Atari游戏)
- 连续控制选PPO(如机器人运动)
- 样本效率要求高选SAC(Soft Actor-Critic)
三、实践路径规划
基础实验:
- 使用OpenAI Gym搭建悬崖寻路(CliffWalking)环境
- 实现Q-Learning算法,调整学习率α和折扣因子γ观察收敛速度
# Q-Learning伪代码示例
for episode in episodes:
s = env.reset()
while not done:
a = ε-greedy(Q[s]) # 探索策略
s', r, done = env.step(a)
Q[s,a] += α*(r + γ*max(Q[s']) - Q[s,a])
s = s'进阶项目:
- 基于PyTorch实现DQN解决CartPole平衡问题
- 关键组件:经验回放缓冲池、目标网络延迟更新、ε衰减策略
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)工业级应用:
- 使用Stable Baselines3库训练PPO模型控制UR5机械臂
- 部署要点:观察空间归一化、奖励函数工程、并行采样优化
四、学习资源体系
理论奠基:
- 必读书籍:《Reinforcement Learning: An Introduction》(Sutton & Barto)
- 视频课程:李宏毅《深度强化学习》系列(含PPt+代码)
实践平台:
- 算法框架:Stable-Baselines3(支持GPU加速)
- 训练环境:OpenAI Gym(经典控制任务)、Unity ML-Agents(3D场景)
前沿追踪:
- 顶会论文:NeurIPS/ICML强化学习专题
- 开源项目:OpenAI Spinning Up(含算法实现教程)
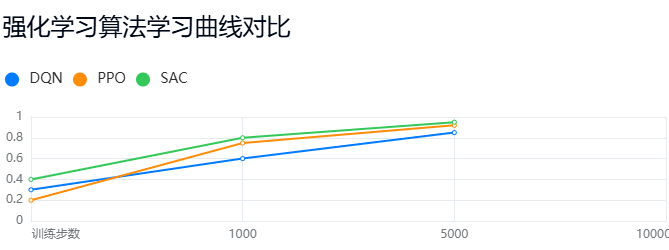
学习建议:从GridWorld等简单环境起步,逐步过渡到MuJoCo物理仿真,最终落地工业控制场景。建议每周投入10小时,3个月可掌握基础算法实现,6个月能完成完整项目部署。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









