






1.在anaconda里创建标注环境,并open Terminal
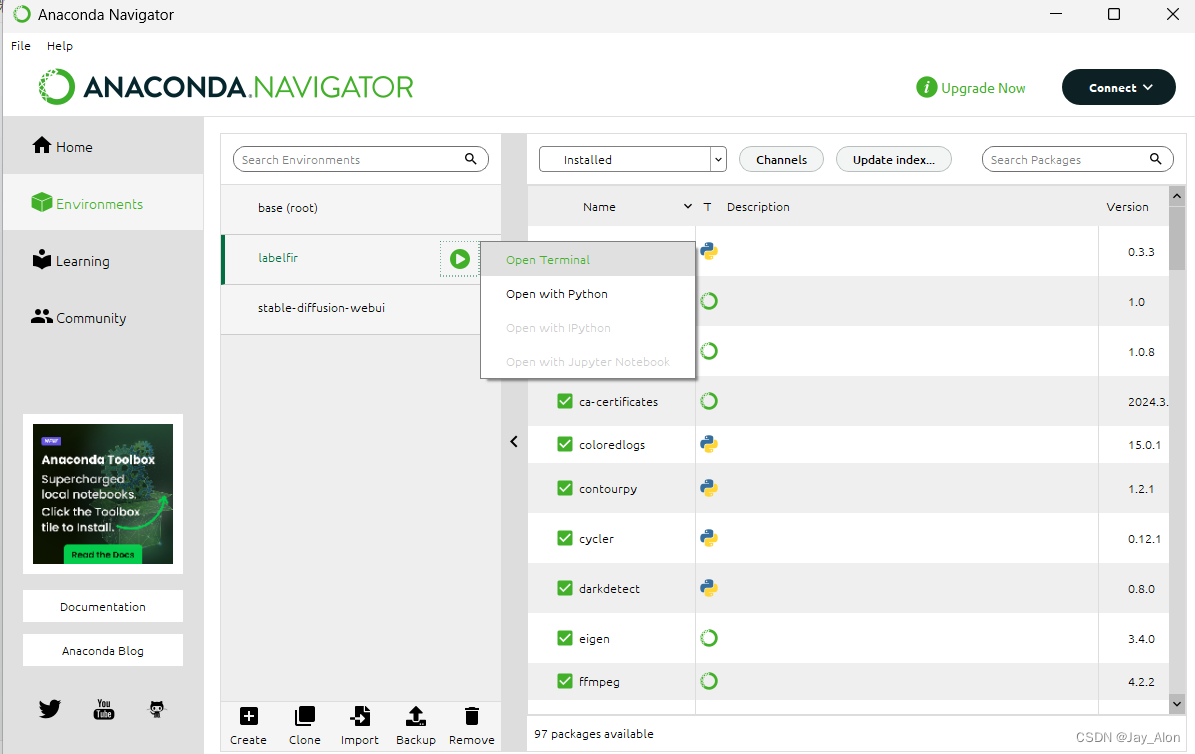
输入指令下载anylabeling工具,
下载完后打开anylabeling,界面如图:
2.选择路径
2.1 左上角文件夹图标 打开路径,找到自己数据集所在文件夹。
2.2 左下位置有一个 粉色大脑状的图标,这里可以载入模型辅助打标签。

这里的模型可以直接选择下载(需要科学上网),也可以载入自己的权重。
2.3 模型选择完点右边的 + point 即可点选目标,倘若超过边界可以选 - point 消除掉多余内容。
一般来说如果自己所需目标边界清晰的话借助ai模型可以避免很多麻烦,当遇到边界模糊的也可以点击左边六边形图标选择人工标注。
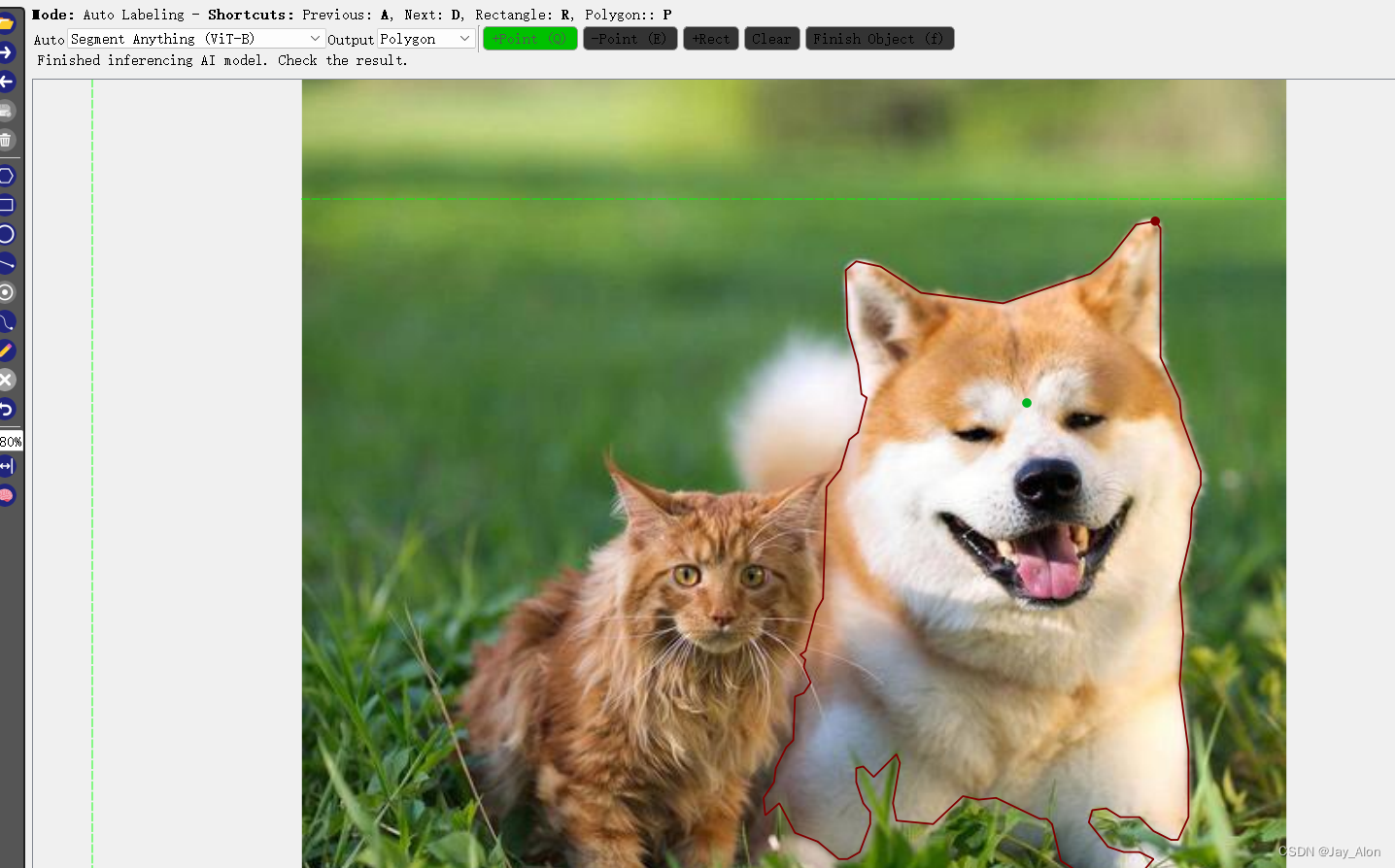
如图示,借助模型鼠标一键即可选中dog边界,倘若人工标注至少要鼠标点击十几次。标记一个目标后按F键打标注;一次标注后后面的重复目标不需要输入,直接点选就可以。
这里可以按A返回上一个,D进到下一张,快捷打标。
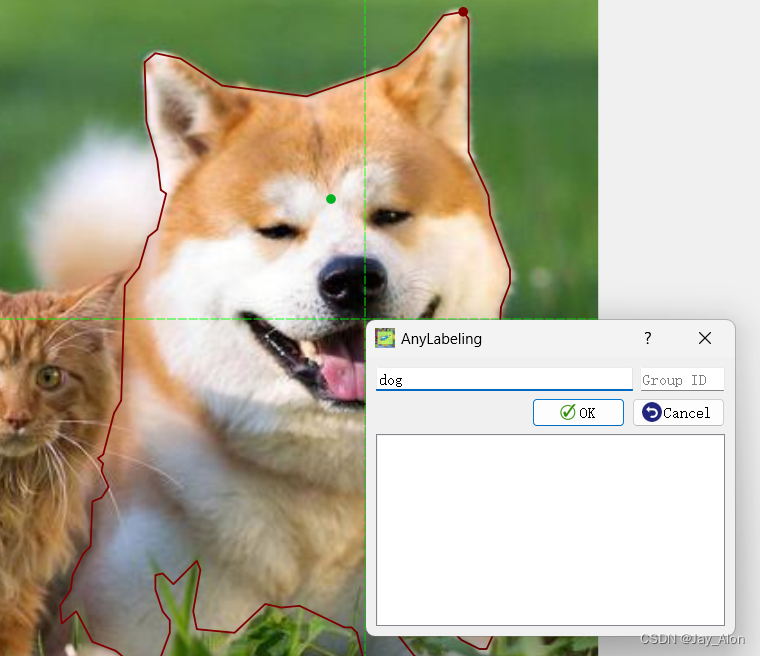
可以在路径下自动生成json文件:
然后就可以根据需要处理数据集啦!
3.数据处理
由于都是生成的json文件,我试想过去用labelme制作数据集时的png转换脚本或许在这里也可以用,于是没多想直接ctrl+v过来,完全可用。
3.1路径设置:before文件夹即原图+json文件路径,jpgs_path原图路径;pngs_path即生成图路径;
3.2自己设置好classes:背景+自己目标的名称
注这里需下载labelme帮助处理数据。
import base64
import json
import os
import os.path as osp
import numpy as np
import PIL.Image
from labelme import utils
if __name__ == '__main__':
jpgs_path = "dataset2/JPEGImages"
pngs_path = "dataset2/SegmentationClass"
classes = ["_background_", "dog"]
count = os.listdir("./dataset2/before/")
for i in range(0, len(count)):
path = os.path.join("./dataset2/before", count[i])
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
PIL.Image.fromarray(img).save(osp.join(jpgs_path, count[i].split(".")[0]+'.jpg'))
new = np.zeros([np.shape(img)[0],np.shape(img)[1]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes.index(name)
new = new + index_all*(np.array(lbl) == index_json)
utils.lblsave(osp.join(pngs_path, count[i].split(".")[0]+'.png'), new)
print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
生成png图以及叠加后的Mask图如下所示:


当然也可以根据自己的需要做相应的数据处理;
Anylabeling作为支持ai模型的标注工具为标注工作减轻了不少负担~

















 3364
3364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









