






常用数据结构
一、数据结构
- 按存储方式分为数组存储和链式存储。
- 按逻辑结构分为线性结构和非线性结构。
二、按逻辑结构划分
- 线性结构有Stack、Queue(单端队列,双端队列、循环队列)
- 非线性结构有HashTable、HashMap、Heap(大顶堆,小顶堆)、Skip List、Tree等。
三、常见问题总结
1. Stack
单调递增栈,栈顶到栈底递增。
单调递减栈,栈顶到栈底递减。
#include<stack>
stack<int> st;
st.top();
st.pop();
st.push(val);
st.size()
st.empty();2. Queue
顺序队列存在假溢出,消除假溢出就是当rear和front到大QueueSize时,让队尾指针自动转化为存储空间的最小值0。常用方法有,加标志位,使用计数器记录队列长度,空闲单元法。
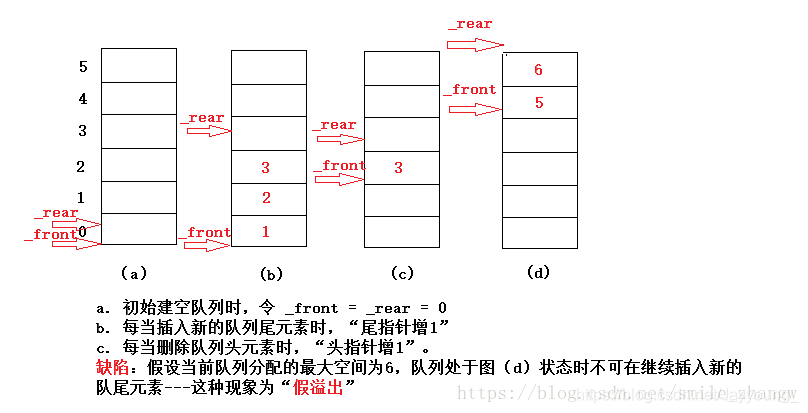
循环队列,队列空间中的一个单元闲置,使得队列非空时,Q.rear与Q.front之间至少间隔一个空闲单元。
队空时,front=rear
队满时,front=(rear+1)%m
队列长度,L=(m+rear-front)%m
#include<queue>
queue<int> Q;
Q.front();
Q.back();
Q.push(val);
Q.pop();
Q.empty();
Q.size();3、Map
C++中有map与unordered_map。
map底层通过红黑树实现,内部是有序的,其查询、插入、删除的时间复杂度都为O(logN)。
unordered_map通过哈希表实现,内部是无序的,查询效率为O(1),但是哈希表建立耗费时间,且消耗内存。
multimap 关键字key可以重复出现的map。
unordered_multimap关键字key可以重复出现的unordered_map。
#include<iostream>
#include<map>
#include<unordered_map>
#include<string>
using namespace std;
int main()
{
//定义
map<string, int> dict;
unordered_map<string,int> unorder_dict;
// 插入数据两种方法
dict.insert(pair<string,int>("apple",2));
uborder_dict["banana"] = 6;
//遍历
unordered_map<string, int>::iterator iter;
for(iter=unorder_dict.begin();iter!=unorder_dict.end();iter++)
cout<<iter->first<<ends<<iter->second<<endl;
map<string, int>::iterator iter;
for(iter=dict.begin();iter!=dict.end();iter++)
cout<<iter->first<<ends<<iter->second<<endl;
//查找
if(iter=dict.find()!=dict.end())
cout<<"找到了"<<iter->second<<endl;
else
cout<<"没有"<<endl;
if(dict.count("apple")==1);
cout<<"找到了"<<endl;
else
cout<<"没有"<<endl;
//是否为空
if(dict.empty())
cout<<"该字典无元素"<<endl;
else
cout<<"该字典共有"<<dict.size()<<"个元素"<<endl;
}
4、Heap、Proiority_queue
//C++
#include <queue>
priority_queue <int,vector<int>,greater<int> > q; //升序队列,小顶堆
priority_queue <int,vector<int>,less<int> >q; //降序队列,大顶堆
//less<int> 表示数字大的优先级越大
//greater<int> 表示数字小的优先级越大
q.top();
q.push(val);
q.pop();
q.empty();
q.size();
vector<int> arr;
sort(arr.begin(),arr.end(),less<int>()) //升序
sort(arr.begin(),arr.end(),greater<int>()) //降序#python
import heapq
arr=[1,2,3,4,5]
arr=heapq.heapify(arr) #默认小顶堆
heapq.heappop(arr)
heapq.heappush(arr,val)
heapq.heappushpop(arr,val) #push进去,调整堆,再pop
heapq.heapreplace(arr,val) #先删除最小值,再push
heapq.nsmallest(k,arr)
heapq.nlargest(k,arr)5、Set
C++中有set与unordered_set,可以理解为将value作为key的map。
set底层通过红黑树实现,内部是有序的,其查询、插入、删除的时间复杂度都为O(logN)。
unordered_set通过哈希表实现,内部是无序的,查询效率为O(1),但是哈希表建立耗费时间,且消耗内存。
multiset 关键字key可以重复出现的set。
unordered_multiset关键字key可以重复出现的unordered_set。
6、Skip List
有序链表+多级索引,时间复杂度为O(logN),实现起来比红黑树简单,非关系型数据库Redis。
7、Tree
二叉搜索树
AVL,二叉自平衡搜索树,查询效率与树的深度有关,引入平衡因子,存储平衡因子浪费空间。
红黑树,近似二叉平衡搜索树,查询效率低于AVL,插入删除效率高于AVL。
B-Tree,多叉平衡二叉树。
B+Tree,多叉平衡二叉树,非叶子节点存放索引,叶子节点存放关键字。叶子节点带有顺序访问的指针。
Trie 树,字典树,每个节点26个分支,查询效率高,空间换时间。
总结
介绍了常用的数据结构,后续会继续补充!















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









