






Ctrl + Shift +} = 在匹配的括号、括号内选择文本
Ctrl + Shift + S = 保存所有文件和项目
Ctrl + Shift + H = 查找替换
Ctrl + K,Ctrl + C = 注释选定行
Ctrl + K,Ctrl + U = 取消选定行的注释
Ctrl + K,Ctrl + D = 正确对齐所有代码
Ctrl + R, 替换选中项
c/c++基础知识
1. 一些概念
1)主函数描述的是main()和操作系统之间的接口。
c++,类和泛型,编译与链接
1.1 数据变量
| 数据类型 | |
|---|---|
| 整型 | short \int \long \long long\ |
| 无符号类型 | 在整型前面加上unsigned unsined int a=10; |
| 十进制 | 第一个数字为1~9 |
| 八进制 | 第一个数字为0,eg: 042表示八进制数,输出时候用cout << oct<< |
| 十六进制 | 前缀为0x , 0X,输出时用cout << hex<<… |
| 字符 | char 赋值用’’ char cha=‘m’, 'm’也等于ASCII码的值 |
| 布尔类型 | bool 只有两个值true!=0可被转换成1;false=0 |
| 常量 | const 加在其他数据类型前面 eg:const int a=1; 或者用#define eg: #define MAX_EAG 100 |
| 浮点数 | float \double eg:+5.37E+16 |
| 自判断类型 | auto eg:auto n=10; 根据后面的数据类型自己判断了,只能用于单值初始化 |
| 数字后缀 | 数字后面加后缀表示存储形式,比如2930L表示以long类型存储该数字 |
头文件climits中包含了整形限制信息
cout << SHRT_MAX << endl;//输出short的最大值
cout << INT_MAX << endl;//输出int型最大值
cout << LONG_MAX << endl;
cout << LLONG_MAX << endl;
cout << CHAR_BIT << endl;
字符串数组
const char* in[10];
| 用单引号括起来 | 转义序列编码(一些符号的表示) |
|---|---|
| \n =endl | 换行符 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \b | 退格(光标前移) |
| \r | 回车 |
| \a | 振铃 |
| \ ? " | 斜杠、问号、引号(在要输入的符号前加) |
| \0 | 空字符,在字符串中表示结尾字符 |
| cin.get() | 等待键盘输入 |
变量命名:str或s表示字符串,b表示布尔值,c表示单个字符,p表示指针
例如:strMyName
常量用全大写
1.2 名称空间
//名称空间::函数eg
Microflop::wanda();
std::cout<<"hello world!"<<std::endl;
//使用using来申明名称空间
using namespace std;
using std::cout;
using std::cin;
1.3 cmath函数
double sqrt(double);//计算平方根
double pow(double,double);//计算幂
int rand(void);//生成随机数
double atan(y,x);//计算倾斜角
1.4 头文件
#include <iostream>
#include <stdio.h>
#include <string.h>
#include <cstdlib>
#include <time.h>
#include <math.h>
//--------------------C++
#include <iostream>
#include<cstring>
#include <cmath>
#include <climits>
#include<Windows.h>
#include<ctime>
using namespace std;
1.5 C++随机数
#include <cstdlib> // rand(), srand() prototypes
#include <ctime>
double direction = rand() % m;//生成0~m的伪随机数
2. 输入输出
scanf("%f,%f,%f", &a,&b,&c);//输入
scanf("%s", m);//字符串输入
printf("%c,%d\n", a1, a1);//输出%d整数,%f小数,%c字符,%s字符串,%p指针
char a = getchar();//字符输入与输出
putchar(a);
cout.put(ch);//输出字符
cout << "score: " << PStu->score << endl;
cin>>inta;
cout<<"input habby:____________\b\b\b\b\b\b\b";//输出后光标前移
cin.get(ch);//可以读空格
cin.get(name,size);//输入size大小的名字为name数组或者字符串
#define Max(a, b) (a > b) ? a : b //比较大小
cin.fail()==false;//检测输入是否为EOF<Ctrl>+<Z><Enter>、
cin.get()!=EOF;
cin.clear();//清楚EOF标记
cerr << ;//输出报错信息
2.1 cout.setf()
对输出的格式进行设置
cout.setf(ios_base::boolalpha);
ios_base::boolalpha 输入和输出bool值,可以为true或者false
ios_base::showbase 对于输出,使用C++前缀(0for Octal, 0Xfor hexadecimal)
ios_base::showpos 在正数前面加上+(decimal)
ios_base::uppercase 对于16进制输出来使用大写字母,E表示法
ios_base::showpoint 显示末尾的小数点
ios_base::fixed 显示为定点格式
switch选择函数
int chioce;
switch(chioce);
case 1:
//method
break;
case 2:
//method
break;
//..............
保持串口打开
cin.clear();
while (cin.get() != '\n')
continue;
cin.get();
3. 数组&字符串
3.1 二维数组
//数组必须在定义的时候初始化
int twoarr[4][3]=
{
{1,2,3},
{4,5,6},
{7,8,9},
{10,11,12}
}; //二维数组
//数组初始化
int cards[4]={0};
int cards[]={1,2,3,4};
short cards[10]={};
//二维数组的指针表示法
twoarr[a][b]=*(*(twoarr+a)+b);
int* ar2[4];//表示一个由4个指向int的指针构成的数组
int (*ar2)[4];//表示一个指向由4个int组成的数组的指针=int ar2[][4]
模板数组
template<class T ,int n>
T ar[n];
//=========使用======
class_name<double,10> object;
3.2 字符串数组的赋值
//字符串赋值******************************
char c[10] = {'a', 'b', 'c', 'd', 'e','\0'};//字符和存储一定是以'\0'结尾的,否则不是字符串
int array[10]={0};
char d[]="c program";//字符串定义可以直接引号
char *p1 = "c program";
string mychar="c program";
3.3 字符串数组的输入输出
使用cin>>输入字符串时候,如果有空格,则只会获取空格前的第一段连续字符串。
//输入输出字符串***************************
cin>>str;//输入直到遇到空格,遇到空格就转化为\0
cin.getline(str,strlength);//获取一行的输入,可以包含空格
getline(cin,string_name);
cin.get(name,50).get();//获取字符包括换行符,后面的get()是为了检查换行健
cin.get();//读取并丢弃换行符号,一般用在多次输入几个不同数据时候放在每一次输入完成之后
gets(str);//输入字符串,scanf("%s", m);
//字符串结束符'\0',eg:while(str[i]!='\0')
puts(st1);//输出字符串,printf("%s", m);
3.4 string操作
string str="HelloWorld!";
//字符串拼接*****************************
getline(cin,myStr);//输入string,可以包含空格,如果用cin不能输入空格,mystr为要键入的字符串
strcpy(str1,str2)//拷贝字符串
strcat(st1, str); //连接字符串
str3=str1+str2;
str1+=str2;//string直接使用+表示把后面的字符串连接在前一个上面,和strcat一样的效果
strcmp(str1,str2);//如果两个字符串不同则返回true,如果相同返回false
sizeof(str);//得出的是字符串或者数组的定义的大小
strlen(str);//求出的是里面字符一共有多少个,直到最后一个 元素‘\0’
str.size()//对于string类型的数据,其长度可以直接用string.size查看
3.5 类型别名typedef
#define BYTE char
typedef int WORD;
typedef 类型名 别名
4. 指针
int *point = &a;//*取地址符:&,而符号\*表示取地址所存的内容,eg:\*(p+i)=a[i]*
const char* name[] = {"A", "B", "C", "D"};//const char*表示的就是字符串,与string相同
float FindeAver(int *array, int n) //传入参数是数组时,传数组名指针
rewind(fp);//把指针重置到开头
int *GetNumber() //函数返回一个数组
{
static int array[10];
srand(time(NULL)); //随机种子
for (size_t i = 0; i < 10; i++)
{
array[i] = rand(); //产生随机数
}
return array;
}
4.1 常量指针
如果定义指针变量时在前面加const则表示指针指向的数据为常量,不能通过指针改变所指的数据
int a=8;
const int* ptr_int=&a;//表示ptr_int指向的数据为常量,不能通过指针改变a的值,但是可以对a直接赋值
a=10;//允许
*ptr_int=10;//不允许
如果定义指针时在指针变量前面加const则表示指针本身为常量,不能改变指针的值,但是可以改变指针所指的指。
int a=5;
int* const ptr_int=&a;//表示ptr_int为一个常量,不能给他赋予其他值,但是可以改变他指向的指的大小
空指针nullptr
4.2 指针数组
*pt[3];//表示pt是一个包含三个指针的数组
5. 结构体
5.1 定义、赋值、函数传参:
struct Student
{
int number;
char name[20];
char sex;
int age;
float score;
char address[30];
};//结构体定义
结构体赋值:
C++允许将一个结构体直接赋值给另一个结构体,可以直接使用=
Student stu;//先定义一个结构体变量
{
stu.number = 21750;
strcpy(stu.name, "lijun"); //数组的赋值用strcpy()
stu.sex = 'M';
stu.age = 24;
stu.score = 88.5;
strcpy(stu.address, "xi'an");
}//结构体赋值,直接用 . 赋值
Student stu2 =
{
21750,
"lijun", //数组的赋值用strcpy()
'M',
24,
88.5,
"xi'an"
};//直接在定义的时候赋值,和数组赋值一样
Student Pstu;
Student *PStu = &Pstu;
{
PStu->number = 21750;
strcpy(PStu->name, "lijun"); //数组的赋值用strcpy()
PStu->sex = 'M';
PStu->age = 24;
PStu->score = 88.5;
strcpy(PStu->address, "xi'an");
}//用指针形式赋值采用‘->’
使用new动态分配结构体
stu* ptr_stu=new stu;
delete ptr_stu;
结构体数组
Student stu1[50];
stu1[1].number = 21750;
strcpy_s(stu1[1].name, "lijun"); //数组的赋值用strcpy()
stu1[1].sex = 'M';
stu1[1].age = 24;
stu1[1].score = 88.5;
strcpy_s(stu1[1].address, "xi'an");
//结构体赋值,直接用 . 赋值
Student[2]={
{1,2,3,4,5},
{5,6,7,8,9}
};
结构体函数传参:
void PrintStruct(struct Student *pStudent)
{
cout << "xuehao: " << pStudent->number << endl;
}//传入的是定义结构体的指针和数组传参一样
PrintStruct(PStu);//函数调用
5.2 联合体union,枚举
联合体定义,和struct一样,联合体(共用体)内部的成员一般使用其中一个,用于节省内存
使用公有枚举提供可供客户使用的类常数
union uData
{
int i;
char ch;
float f;
};
enum Week//枚举
{
Mon = 1, //me
Tue,
Wed,
Thu,
Fri,
Sat,
Sun
};
Week date=Mon;
Week date2=2;//不能这样赋值
//枚举量可以视为整数参与运算,但不能把整数赋值给一个枚举量
6. 模板类vector,模板类array
vector的长度可以是变量,在需要的时候给他,而array的长度在声明的时候就需要给他
#include<vector>
std::vector<int> vi;
//vector<typeName> vt(n_elem);创建一个n_elem长度的vt
#include<array>
std::array<int,6> ai;
std::array<double,4> ad={1.2,2.1,3.4,5.3};
可以使用.at检索非法索引,ai.at(10)=1;
array还可以创建类对象数组,比如创建一个string类的数组
const int Seasons=4;
const std::array<std::string,Seasons> Saname={"Spring","Summer","Fall","Winter"};
7. 动态内存分配
7.1 动态内存分配malloc
前面说明数据类型,后面说明大小,realloc再分配,free释放内存。memcpy,memmove,memset
void *memcpy(void *dest, const void *src, size_t n)
函数说明: memcpy()用来拷贝src所指的内存内容前n个字节到dest所指的内存地址上。与strcpy()不同的是,memcpy()会完整的复制n个字节,不会因为遇到字符串结束’\0’而结束.
void *memccpy(void *dest, const void *src, int c, size_t n);
函数说明: memccpy()用来拷贝src所指的内存内容前n个字节到dest所指的地址上。与memcpy()不同的是,memccpy()如果在src中遇到某个特定值(int c)立即停止复制
void *memmove(void *dest, const void *src, size_t n);
函数说明:memmove()是从一个缓冲区移n个 数据量到另一个缓冲区中。
memset(src,"A",7);//把src前面7个数改为A
charP = (char *)malloc(500 * sizeof(char));
free(charP);//释放内存
7.2 使用new来分配内存
//typeName* pointerName = new typeName;
int* poniterName=new int;
delete pointerName;//释放通过new分配的指针
//使用new创建动他数组
//typeName* pointerName = new typeName [number];
int size;
sin>>size;
int* arr_ptr = new int [size];
delete [] arr_ptr;
//arr_ptr可以当作数组名来用,例如:arr_ptr[0]=1;
定位new运算符
int shuzi=1;
int* ptr1=new (&shuzi) int;
int* ptr2=new (&shuzi+100) int
8. 循环和判断
8.1 for循环
for(int i=0;i<10:i++)
{
i=i++;
}
使用符合语句即{}时,内部的变量的定义以及声明只在{}内部有效,
可以使用都好运算符将多个语句放在一个语句执行
for(i=0,j=10;i<j;i++,j--)
8.2 while循环
while(条件为true)
{
body
}
do while循环
do{
body;
}while(test-expression)
位运算
&按位与,|按位或,^按位异或,~按位取反,<<左移,>>右移。:位域是指说明一个数据类型占用多少个字节,比如int a:4表示整型数a占用4个字节,即最大为15,1111.
clock()返回当前系统时间
8.3 递归的概念与实例
long Factorial(int n) //阶乘函数
{
if (n <= 1)
{
cout << "1=";
return 1;
}
cout << n << "*";
return n * Factorial(n - 1);
}
int FibnuchiFun(int n)//斐波那切数列
{
int an;
if (n == 0)
{
return 0;
}
if (n == 1)
{
return 1;
}
an = FibnuchiFun(n - 2) + FibnuchiFun(n - 1);
return an;
}
9. 分支语句和逻辑判断
9.1 if else
if(test-condition)
statement;
else
statement 2;
if(test-condition1)
statement1;
else if(tes-condition2)
statement2;
else
statement3;
9.2 逻辑运算符
| 或 | || |
|---|---|
| 与 | && |
| 非 | ! |
| 判断运算符 | ?: |
condition ? state1:state2//条件如果满足则取状态1,否则取状态2
9.3 switch语句
switch (choice)
{
case 1: cout << "\a\n";
break;
case 2: report();
break;
case 3: cout << "The boss was in all day.\n";
break;
case 4: comfort();
break;
default: cout << "That's not a choice.\n";
}
10. 文件基础概念
FILE*文件指针
文件指针名=fopen(文件名,使用文件方式)
| 文件使用方式 | 意义 |
|---|---|
| “rt” | 只读打开一个文本文件,只允许读数据 |
| “wt” | 只写打开或建立一个文本文件,只允许写数据 |
| “at” | 追加打开一个文本文件,并在文件末尾写数据 |
| “rb” | 只读打开一个二进制文件,只允许读数据 |
| “wb” | 只写打开或建立一个二进制文件,只允许写数据 |
| “ab” | 追加打开一个二进制文件,并在文件末尾写数据 |
| “rt+” | 读写打开一个文本文件,允许读和写 |
| “wt+” | 读写打开或建立一个文本文件,允许读写 |
| “at+” | 读写打开一个文本文件,允许读,或在文件末追加数据 |
| “rb+” | 读写打开一个二进制文件,允许读和写 |
| “wb+” | 读写打开或建立一个二进制文件,允许读和写 |
| “ab+” | 读写打开一个二进制文件,允许读,或在文件末追加数据 |
| fclose(文件指针) | 关闭文件 |
| fgetc和fputc | 字符读写函数 |
| fgets和fputs | 字符串读写函数 |
| fread和fwrite | 数据块读写函数 |
| fscanf和fprintf | 格式化读写函数 |
fscanf//从文件中读取字符串,如果遇到第一个空格就停止*
fgets//从文件中读取字符,空格也算
FILE *fp;//文件指针
FILE *filep;//文件指针
char charBuffer[20];//缓存数组
char mes[20];
fputs("this is a test file", fileP);//向文件写
fwrite(mes, 1, strlen(mes) + 1, fileP);
// fwrite(要获取数据的地址, 要写入内容的单字节数, 要进行写入size字节的数据项的个数, 目标文件指针);
fread(buf, 1, strlen(mes) + 1, fileP);
fscanf(fp, "%s", charBuffer);//从文件读
fgets(cahrBuffer, 255, fp);
fprintf(fileP, "this is a test file.\n");
fread(buf, 1, strlen(mes) + 1, fileP);
//------下面的是用循环去读取字节,知道读取完整
if ((fp = fopen("test.txt", "rt")) == NULL)
{
cout << "filed to read file" << endl;
}
while ((myChar = fgetc(fp)) != EOF)
{
putchar(myChar);
}
10.1 c++文件写入ofstream
// outfile.cpp -- writing to a file
#include <iostream>
#include <fstream> // for file I/O
int main()
{
using namespace std;
char automobile[50];
int year;
double a_price;
double d_price;
ofstream outFile; // create object for output
outFile.open("carinfo.txt"); // associate with a file
cout << "Enter the make and model of automobile: ";
cin.getline(automobile, 50);
cout << "Enter the model year: ";
cin >> year;
cout << "Enter the original asking price: ";
cin >> a_price;
d_price = 0.913 * a_price;
// display information on screen with cout
cout << fixed;
cout.precision(2);
cout.setf(ios_base::showpoint);
cout << "Make and model: " << automobile << endl;
cout << "Year: " << year << endl;
cout << "Was asking $" << a_price << endl;
cout << "Now asking $" << d_price << endl;
// now do exact same things using outFile instead of cout
outFile << fixed;
outFile.precision(2);
outFile.setf(ios_base::showpoint);
outFile << "Make and model: " << automobile << endl;
outFile << "Year: " << year << endl;
outFile << "Was asking $" << a_price << endl;
outFile << "Now asking $" << d_price << endl;
outFile.close(); // done with file
// cin.get();
包含头文件#include
定义对象ofstream outFile;
定义的对象与cout用法相同
打开文件 outFile.open(“carinfo.txt”);
关闭文件outFile.close();
11. 函数
11.1 接口的封装与设计
自定义头文件,在include文件夹里面添加xxx.h的文件,然后在src里面添加xxx.cpp文件,该文件包含系统头文件,只写自己写的函数,没有主函数。
xxx.h文件
#ifndef HEAD_H //这里是标准的开头,防止文件被重复定义
#define HEAD_H
#include <iostream>
using namespace std;
int Add(int a, int b);//这里写的是函数名称
int Sub(int a, int b);
int Multi(int a, int b);
int Div(int a, int b);
extern int g_nNum;//声明全局变量
#endif
xxx.cpp文件
#include <iostream>
#include "Mathmatic.h"
using namespace std;
//下面跟函数就行,不用主函数
11.2 函数原型与调用
函数原型即为函数头后面加“;”
int cheer(int a,int b);
int Cheer(int,int);
11.3 数组函数
传入函数的形参或返回值为数组,传入参数为一个指针和处理数组的长度,数组名就是数组首个元素的地址。
void Array_Fun(int* arr,int lenth);
void Arraay_Funcation(int arr[],int len);
如果不想数组内元素被修改,则在参数前面加const,即表示传入的指针指向的元素为常量,不能被修改。
void Array_Func(const double arr[],int length);
二维数组作为形参要指定数组的列数,不用给定函数
void array2_function(int ar2[][4],int size);
void array2_func(int (*ar2)[4],int size);
//表示参数为一个由4个int组成的数组,size为行数
11.4 字符串函数
函数形参为字符串,传入参数
unsigned int Count_ch(char* str,char ch);
如果返回为字符串的话,则返回值设为char* 型
char* bulidstr(char c,int n)
{
char* pstr=new char[n+1];
pstr[n]='\0';
while(n-->0)
pstr[n]=c;
return pstr;
}
11.5 结构体函数
1.按值传递结构体参数,即把结构体视为一个标准变量
struct Struct_Eg{
int a;
int b;
};
Struct_Eg Struc_Fun(Struct_Eg strcA);
2.传入结构体的指针
void Struct_Fun(const Struct_Eg* strucA,Struct_Eg* strucB){
structB->a=structA->a;
}
对于不需要改变值的结构体形参使用const,使用指针传参数时可以不返回值v,需要返回的值在形参里面通过修改指针所指向的内容给需要使用的处理需要使用的参数,指针在使用结构体时用间接取值符号->取值,而不是用点。
11.6 string和array函数
把string和array视为一个简单变量,但是在函数原型中形参要像定义元素意义给出形参
void display_string(const string [],int len);//这里函数的参数为一个string数组
void show_array(std::array<double,4> a);//形参要定义明确
void show_array(std::array<double,4> *p);//传入的是一个array类型的指针
11.7 函数指针
function(fun());//表示外面的函数的参数为里面函数的返回值
function(fun);//表示外面的函数调用里面的函数,传入的参数为里面函数的指针
定义函数指针
double pam(int);//函数原型
double (*ptf)(int);//函数执政,将函数名用(*ptf)替换,则ptf为一个指针
ptf=pam;//函数名就是一个指针
一个函数的参数为函数指针
void estimate(int lines, double (*pf)(int));//形参为一个函数指针,实参为函数名称
12. 函数重载
12.1 内联函数
关键字inline,一般用于较为简单的函数,函数内容占用行数少,直接在原型处定义即可
inline double square(double x){return x*x;}
12.2 引用
引用是给变量取一个别名,引用变量和原来的变量表示同一个 值,相同改变
必须在声明引用时将其初始化,而指针可以先声明在赋值
int a;
int& b=a;
引用一般用来作为函数的形参
void Fun(int &a,char&b);
double Re_Fcunbe(const double& a);//应用常量,不能修改参数的值,如果声明将引用指定为const,C++会在必要时候生成临时变量
结构体引用
struct Struct_a{};
void Fun(Struct_a & stru);
void Fun(const Struct_a & stru);//使用const后不能改变传入结构体的值
Struct_a& Fun(Struct_a & a);//表示函数返回的为结构体
const Struct_a& Fun(Struct_a & a);//表示函数返回的为结构体
12.3 默认参数
在函数原型中给某些参数赋初值,从左往右,前面的被设置为默认参数,则右边的应该全部被设为默认参数,被设置为默认参数后,重新传入参数会改变参数值
注意:只有在函数原型中使用默认值,在函数定义中并不使用默认值
int Fun(int a,intb=1,in c=2);
int Fun(int a,intb,in c)
{
return a;
}
函数传参时,如果传入的参数少于形参,则后面的参数使用默认值
int a;
a=Fun(1,2);//=Fun(1,2,2)
12.4 函数重载
同一个函数名,函数参数的数目或类型必须不同,但是函数的返回类型可以相同也可以不同
void print(const char* str,int a);
void print(int a,int b);
void print(double a,int b);
12.5 函数模板
使用一个通用的模板名构造一个模板函数,在给出具体变量类型时生成该函数
template<typename T>//定义模板时后面没有分号
//也可以使用template<class T>
void Swap(T& a,T& b);//函数原型
int main()
{
int a=5,b=9;
int c=Swap<int>(a,b);//使用函数创建显示实例化
return 0;
}
template<typename T>//定义模板时后面没有分号
void Swap(T& a,T& b)//函数定义时前面还是要写上模板
{
T temp;
temp=a;
a=b;
b=temp;
}
template void Swap<int>(int&,int&);//实例化模板函数
-
函数模板并不是真正的函数,它只是C++编译生成具体函数的一个模子。
-
函数模板本身并不生成函数,实际生成的函数是替换函数模板的那个函数,这种替换是编译期就绑定的。
-
函数模板不是只编译一份满足多重需要,而是为每一种替换它的函数编译一份。
-
函数模板不允许自动类型转换。
-
函数模板不可以设置默认模板实参。比如template 不可以。
函数模板也可以重载
template <typename T> // original template void Swap(T& a, T& b); template <typename T> // new template void Swap(T* a, T* b, int n);//重载的模板函数,前面的函数形参为单个数,后面函数的形参为数组
12.6 显示具体化
template<> void hanshuming<bianliang_type>(bianliang_type a);
非模板函数优先于显示具体化函数,优先于模板函数
显式实例化和显式具体化
显示实例化是指通过指定数据类型为模板函数创建一个实例函数,而显示具体化是自己定义一个与模板函数同名的函数
template<typename T>
void Swap_Fun(T& a,T& b);
template void Swap_Fun<double>(double& a,double& b);//显式实例化,即给模板函数指定数据类型为double类型,后面不用给这个函数具体定义,它使用的是模板函数的定义
templae <> void Swap_Fun<float>(float& a,float& b);//显示具体化,相当于一个新函数,后面当都给出该函数的定义,当调用函数时,传入参数为float类型时候就会用这个函数
templae <> void Swap_Fun<float>(float& a,float& b)
{
a=a+b;
}
13. 数据结构 (data structure)
| 数组(Array) |
|---|
| 链表(linked list) |
| 栈(stack) |
| 队列(queue) |
| 树(tree) |
| 图(graph) |
| 散列表(哈希表)(hash table) |
13.1 数组/链表
int arr[10]
数组是连续存储的。链表是一种随机存储(逻辑连续)的在内存中叫做节点的对象集合,一个节点包含两个字段,一个是数据,一个是下一节点的地址。malloc,calloc,f,ree… 单链表,循环单链表,循环双链表。 (链表是一种嵌套的结构体,直接用链表名字=链表内的指针元素表示下一个节点)链表的操作包括在表头插入,表尾插入,表中间插入,查找,遍历等。
struct Node//链表结构定义
{
int data;//数据
struct Node* next;指针
};
struct Node* head;
struct Node* insertNode=NULL;
void InsertLiseBegin(int dataItem)链表表头插入函数
{
struct Node *insertNode = (struct Node *)malloc(sizeof(struct Node *));
if (insertNode == NULL)
{
cout << "memory allocation failed" << endl;
// exit 0;
}
else
{
insertNode->data = dataItem;
insertNode->next = head;
head = insertNode;
}
}
void InsertListLast(int dataItem) //链表末尾插入数据函数
{
struct Node *insertNode = (struct Node *)malloc(sizeof(struct Node *));
struct Node *tempNode; //临时节点
if (insertNode == NULL)
{
cout << "memory allocation failed" << endl;
exit(0);
}
else
{
if (head == NULL)//判断是否为空链表
{
insertNode->data = dataItem;
insertNode->next = NULL;
head = insertNode;
}
else
{
tempNode = head;
while (tempNode->next != NULL)//遍历到最后一个链表节点
{
tempNode = tempNode->next;
}
insertNode->data = dataItem;
tempNode->next = insertNode;
insertNode->next = NULL;
}
}
}
13.2 队列
typedef Customer Item;//Customer是一个类
class Queue
{
private:
struct Node//数据为顾客的队列
{
Item item;
struct Node* next;
};
static const int Q_SIZE = 10;
Node* front_;//队列头指针
Node* rear_;//队列尾指针
int item_size_;//队列中元素个数
const int qsize_;//队列最大长度
Queue(const Queue& q) :qsize_(0) {}//复制构造函数
Queue& operator=(const Queue& q) { return *this; }//=重载函数
public:
Queue(int qs=Q_SIZE);
~Queue();
bool isempty() const;//队伍是否为空
bool isfull() const;//队伍是否满员
int queue_count() const;//队伍长度
bool enter_queue(const Item& item);//顾客入队
bool level_queue(Item& item);//顾客离队
};
14. 内存模型与名称空间
14.1 头文件
头文件中常包含的内容
| 函数原型 |
|---|
| 使用#define或const定义的符号常量 |
| 结构体声明 |
| 类的声明模板声明 |
| 内联函数 |
头文件定义
#ifndef COORDIN_H_//防止多次包含头文件
#define COOEDIN_H_
//定义的内容
#endif
在cpp文件中包含头文件时要用双引号,包含标准库文件用<>
14.2 名称空间
名称空间定义
namespace Jack{
double pail;
void fetch();
struct well{
int a;
}
}
使用名称空间::,using 编译指令using namespace jack;using声明
使用::是每个变量每次使用的时候都要在前面加上名称空间::
using声明指令是对于某一个变量使用using 名称空间::变量 后,后面使用这个变量就不用在前面在加上名称空间了,一次只针对一个变量
using std::cout;//后面使用cout就可以不加std::前缀了
using编译指令是在全局中加入using namespace 名称空间名字,使用这种方法表示后面的代码块下的变量都是在该名称空间下的
15. 类与对象
类的特点:抽象、封装、数据隐藏、多态、继承、代码重用
防止程序直接访问数据被称为数据隐藏
15.1 类的定义
类的定义一般放在头文件中,和对应的函数声明的cpp文件中
#ifndef STOCK00_H_
#define STOCK00_H_
#include<string>
namespace Jack{
class Stock
{
private://对于未什么类型的数据默认为private类型
std::string company;
long shares_;
double share_val_;
double total_val_;
void set_tot() {
total_val = shares * share_val;
public:
Stock();
Stock(const string &company,long shares,double shares_val,double total_val);//构造函数
~Stock();//析构函数
void acquire(const std::string& co, long n, double pr);
void buy(long num, double price);
void sell(long num, double price);
void update(double orice);
void show() const;//常量成员函数的const要放在函数后面,这里表示该函数不会修改调用该函数的对象
};
}
#endif // !STOCK00_H_
在类声明时,可在私有成员数据变量后面加_,用于区分
private的类成员不能被直接访问,只能通过共有成员函数来访问对象的私有成员
对类的成员函数定义时,需要在函数名称前面加上类名和解析作用符
void Stock::buy(long num, double price)
{
}
对于类的成员函数访问用::(作用域解析运算符)
void Stock::update(double price);//类名放在函数名前面
在类中声明的函数为内联函数
15.2 类的构造函数与析构函数
构造函数
用于构造新对象,为对象私有成员赋值。
函数名称与类名称相同,且没有返回值,也不用void前缀;
具有默认构造函数,也可以对其重载,可以在定义时候赋予默认值。
原型位于共有部分。
构造函数定义
class Stock
{
private:
std::string company_;
long shares_;
double share_val_;
double total_val_;
void set_tot() {
total_val = shares * share_val;
public:
Stock;//默认构造函数,也需要声明
Stock(const string &company,long shares,double shares_val,double total_val);
void acquire(const std::string& co, long n, double pr);
void buy(long num, double price);
void sell(long num, double price);
void update(double orice);
void show();
};
构造函数声明
Stock::Stock(){};//这是默认构造函数,如果没有申明,则构造函数就为此类型
Stock::Stock(){
company_="no name";
shares_=0;
shares_val_=0;
total_cal_=0;
}
Stock(const string &company,long shares,double shares_val,double total_val){
company_="company";
shares_=shares;
shares_val_=shares_val;
total_val_=total_val;
}
构造函数使用
Stock garment("xiaomi",0,0,0);//隐式调用
Stock garments=Stock("huawei",0,0,0);//显示调用
Stock *germent_ptr=new Stock("vivo",0,0,0)//创建类指针
Stock gramentss;//使用默认构造函数创建对象
构造函数不仅可以初始化对象,还可以给对象重新赋值
Stock garment("xiaomi",0,0,0);//隐式调用、
garment=Stock("oppo",1,2,3);
构造函数对const类成员何被声明为引用的类成员赋值
引用和const类型只能在被创建时候初始化
在函数名后面,大括号前面用冒号+变量名(值)来赋值,这种方法只能用于构造函数
class Agent{
private:
double& dou_;
const int a_;
}
//==========构造函数中赋值==========
Agent::Agent(double& dou,int a):dou_(dou),a_(a)
{
//..............
}
析构函数
完成对象的清理工作
在类名前面加上,原型为Stock
15.3 this指针
成员函数,一个操作数通过this指针隐式的传递
this指针指向用来调用成员函数的对象,即使用该函数的对象本身的指针,*this指对象本身,即该对象的别名
class Stock
{
public:
const Stock & Stock::topval(const Stock & s)
//返回值为一个对象,使用该成员函数的对象与传入参数的对象不是一个,因此可以该函数可以处理两个对象
{
if(s.total_val_>total_val_)//前者为传入参数对象,后者为使用该成员函数的对象
return s;
else
return *this;//*this表示使用该成员函数的对象
}
};
//函数调用
Stock top_stock;
top_stock=stock1.topval(stock2);
15.4 对象数组
与定义常规类型的数组一样
Stock mystuff[4];
//对象数组的赋值或初始化,用大括号括起来,每个对象元素使用构造函数,之间用逗号隔开,与常规数组赋值一样
mystuff[4]={
Stock("tesila",1,2,3),
Stock("biyadi",1,2.3,4.5),
stock(),
Stock(),
}
15.5 类作用域
定义函数成员时,必须使用类作用域解析运算符::
在定义类时要使用常量,则加static关键字
class Bakery
{
private:
const int Months=12;
double costs[Months];
};//这样做不可以,在为创建对象时,并没有创建常量Months,将const改为static才可以
class Bakery
{
private:
static int Months=12;
double costs[Months];
};
作用域内枚举
在定义枚举量时候加上class或者struct关键字在枚举名前面
enum calss egg_size{Small,Medium,Large,Jumbo};//定义枚举量时在名称前面加上class
enum class t_shirt_size{Small,Medium,Large,Xlarge};
egg_size one=egg_size::Small;//使用枚举量时在前面加上枚举名称和作用域解析符::
t_shirt_size two=t_shirt_size::Medium;
16. 使用类
16.1 运算符重载
对于求运算的函数将函数名称改为opeart+(+这里指需要重载的符号)
const Time Time::operator+(const Time& t) const
const Time Time::Sum(const Time& t) const
{
Time sum;
sum.minutes = minutes + t.minutes;
sum.hours = hours + t.hours + sum.minutes / 60;
sum.minutes %= 60;
return sum;
}
const Time Time::operator+(const Time& t) const
{
Time sum;
sum.minutes = minutes + t.minutes;
sum.hours = hours + t.hours + sum.minutes / 60;
sum.minutes %= 60;
return sum;
}
total = coding+fixing;
16.2 友元函数
友元函数是非成员函数,但可以访问私有成员,一般用于重载运算符的函数
原型放在类声明中,在函数前面加上关键字friend
函数定义时,不在前面加类::限定符,定义中不使用friend
不能用成员运算符号.来调用
//========头文件===============
class Time
{
private:
int hours;
int minutes;
public:
friend Time operator*(double m, Time& t);//friend前缀
}
//========定义cpp文件===============
Time operator*(double m, Time& t)//函数前面不加friend,不用Time::在函数名前
{
Time result;
long totalminutes = t.hours * m * 60 + t.minutes * m;
result.hours = totalminutes / 60;
result.minutes = totalminutes % 60;
return result;
}
友元函数直接用函数名调用即可,不需要使用对象.调用
对<<进行重载,使用cout<<输出对象
//===========函数定义==========
friend void operator<<(std::ostream & os, const Time& t);
//=================函数声明==============
void operator<<(std::ostream & os, const Time& t)
{
os << t.hours << "hours," << t.minutes << "minutes";
}
上面的代码不能cout << "fixing tmie*2 = "<<total<<“time”;这样输出,因为使用cout类time后返回值不再是cout了,下面的代码将函数的返回值设置为cout类,这样就可以连续输出了 。
重载cout<<模板
friend std::ostream& operator<<(std::ostream& os, const Time& t);
//函数的返回值为ostream的引用
std::ostream& operator<<(std::ostream& os, const Time& t)
{
os << t.hours << "hours," << t.minutes << "minutes";
return os;
}
重载cin>>模板
//函数声明=================
friend std::istream& operator>>(std::istream& is, const Class_Name& obj);
//函数定义=================
std::istream& operator>>(std::istream& is, const Class_Name& obj)
{
is>>...;
return is;
}
cout的数据类型为ostream,cin的数据类型为istream
16.3 类的自动转换
其他类型转换为类:在构造函数前加关键字explicit
explicit Stock(double lbs);//将一个double值转换为一个类
//调用函数
Stock my_stock
my_stock=Stock(19.6);
my_stock=(Stock) 19.6;
类转换为其他类型:
//===========函数原型========
operator double() const;//关键字operator,无返回值,无传入参数
//=========函数定义=======
Stock::opeartor double() const
{
return double_val;
}
转换函数,将单个值转换为类类型
Class_Name(type_name value);
17. 类和动态内存分配
17.1 静态类成员
关键字static,在类声明时声明,除了const和枚举类型外的static变量一定不能在里面初始化,要在类声明之外初始化。初始化时要指出类作用域,但是没有static
class String
{
private:
char* str_;
int len_;
static int num_string_;
public:
String();
string(const char* str);
~String();
}
int String::num_tring_=0;//在类声明之外初始化
程序只创建一个静态类成员副本,所有的对象共享这个静态类成员,
不能通过对象调用静态成员函数,只能使用类名::调用
int count = Class_Name::Count_Funcation();
17.2 类成员动态内存分配
在构造函数中使用new进行动态内存分配,则在析构函数中要使用delete进行内存释放
new与delete一组,new type_name []和delete []一组
//构造函数
String::String(const char* str)
{
len=std::stelen(str);
str_=new char[len+1];
num_string_++;
}
//析构函数
String::~String()
{
delete [] str_;
--num_string_;
}
17.3 类的特殊成员函数
1)默认构造函数 class::class(){}
2)默认析构函数class::~class(){}
3)复制构造函数
用于将一个对象复制到新创建的对象中
Clss_name(const Class_name &)
在新建一个对象并将其初始化为同类现有对象时被调用
当函数按值传递对象或者函数返回对象时都会复制一个临时对象,是一种浅复制
Class_name Class1(Class2);//把class2赋值给class1
Clas_name Class3=Class4;
自定义显示复制构造函数
class_name::class_name(const class_name& cla)
{
type1=cla.type1;
type2=cla.type2;
type3=new char[5];
std::strcpy(type3,cla.tpye3);
}
对于多个构造函数,复制构造函数,=运算符重载等函数,都要使用一样的格式进行动态内存分配
重载赋值运算符的函数
Class_Name& operator=(const Class_name& cla);//这个函数不用友元函数
//=============函数定义===========
Class_Name& Class_Name::operator=(const Class_name& cla)
{
if(this==&cla)
return *this;
delete [] c_pointer;
c_pointer=new type_name[size];
//...
return *this;
}
17.4 返回对象的函数
可以返回指向对象的引用,指向对象的const引用,或const对象
关于类的成员函数使用const
const Class_Name& Class_Name::Class_Fun(const Class_Name& Class1) const
//第一个const表示返回值是一个常量对象,括号内的const表示传入的参数是一个常量对象,最后一个const表示调用该函数的对象是个常量,不会被该函数修改
//在调用函数时,传入的参数或生成的对象可以不是const类型
如果函数返回值为函数内创建的局部对象,那函数返回值应该为对象,而不是引用
创建一个指向对象的指针 使用该对象时要用->
Class_Name* object = new Class_Name();
18. 类继承(派生类)
18.1 公有继承类语法is-a
公有继承,继承接口与方法
class class_name:public fulei_name
{
};
冒号后面根父类(基类)的名称,public表示共有派生,积累的公有成员将成为派生类的共有成员,,私有成员只能通过公有和保护方法访问
派生类的构造函数
clsaa_name::class_name(int a,int b,int c):fulei_name(a,b)
{
c_=c;//初始化列表法构造函数
}
或者使用复制构造函数
clsaa_name::class_name(jilei_name& jilei,int c):jilei_name(jilei)
{
c_=c;//初始化列表法构造函数
}
传入的参数包括基类构造函数的参数和自己的参数,冒号后面根基类的构造函数,前面的参数直接传给它。
派生类调用基类的函数 需要使用作用域解析符
void pai_funct()//派生类的一个函数定义
{
base_class::base_fun();//调用基类的方法
}
基类与派生类的关系
①派生类对象可以使用基类的公有方法
②基类指针或引用可以在不进行显示类型转换的前提下指向派生类对象,即可以将派生类指针或应用指定为基类的数据类型,但不可以将基类对象的地址赋给派生类引用或指针
jilei_name* ptr1=&class_name;
jilei_name& yin=class_name;
③对于形参为指向基类指针的函数,可以使用基类对象的地址或者派生类对象的的地址作为实参
④可以将派生类对象直接复制给基类对象
class_name obj1=class_name();
jilei_name obj2;
obj2=obj1
如果创建指向基类指针的数组,则数组的成员可以是基类,也可以是派生类,因为派生类的引用和指针都可以是指向基类的
18.2 多态公有继承
虚方法:
在基类中派:生类会重新定义的方法叫虚方法,关键字virtual,在派生类和基类的同名函数前都加上关键字virtual,通常将析构函数也声明为虚方法
class jilei
{
pubulic :
virtual void xu_function();
}
class paishenglei:public jilei//公有类派生
{
pubulic :
virtual void xu_function();
}
//===========函数定义要两个都定义,且定义函数的类作用域不一样
//在类定义中不加关键字
如果是虚方法,则通过引用或者指针调用时使用的是具体对象所指的类的方法。
如果有重定义的方法,在派生类中调用基类方法需要加上基类作用域前缀 jilei_name::fun()
编译器对非虚方法使用静态联编,对非虚方法使用动态联编
只有当派生类中需要对基类中的方法进行再定义时,才使用虚方法
构造函数不能是虚函数,析构函数应该是虚函数,友元函数不能是虚函数
虚函数和重载函数不一样,因此基类和派生类中的虚函数的形参应该相同,原型应该相同,但函数返回类型可以不同
访问控制 protected
在类外protected和private一样,类外成员不可访问,但派生类可以访问protected成员。
最好对类 数据成员使用私有访问控制,而不要使用保护访问控制,通过基类方法使派生类访问基类数据。
18.3 抽象基类
抽象基类(Abstract Base class,ABC)包含所有派生类的公有数据和方法,在方法中一定包含纯虚函数
纯虚函数:
基类中的虚函数,并且在函数原型的结尾处有=0
class class_ABC
{
private:
double a_;
int b_;
protected:
double a_();
int b_();//protected方法访问私有数据
public:
class_ABC(double& a,int& b):a_(a),b_(b){}
virtual ~class_ABC(){}
viod fun(double ax,int bx)
virtual double area() const =0;//=0表示这个虚函数为纯虚函数,有纯虚函数则表示该基类为抽象基类
}
class paisheng_class : public class_ABC//派生类,又叫具体类
{
private:
int c;
public:
}
18.4 继承和动态内存分配
如果在基类中使用了new进行动态内存分配,则派生类中析构函数、复制构造函数和重载复制运算符函数的定义分两种情况:
基类,由于构造函数中使用了动态内存分配,因此其他函数不能使用默认的,需要显示定义
class baseclass//基类
{
private:
char* lable_;
int rating_;
public:
baseclass(const char* lable="null",int rating=0);//构造函数
baseclass(const baseclass& bc);//复制构造函数
virtual ~baseclass();
baseclass& operator=(const baseclass& bs)//重载复制运算符函数
}
派生类中,如果派生类私有成员没有使用new进行动态内存分配,则可以直接使用默认的构造函数及其他函数。因为在执行完自身的代码后会调用基类的对应函数对基类中的组件进行赋值。
如果派生类中使用了new进行动态内存分配,则其他的函数都应该显示的定义,并且复制构造函数还有用冒号调用基类的对应函数。
友元函数的继承
在基类中定义的友元函数,在派生类中也要定义,函数原型中形参与类相对应,在函数定义中使用强制转换将派生类转换为基类进行基类友元函数的调用
friend std::ostream& operator<<(ostream& os,const baseclass& bs);//基类中的友元函数
friend std::ostream& operator<<(ostream& os,const paishengclass& bs);//派生类中的友元函数
//==================派生类中友元函数的定义==========
friend std::ostream& operator<<(ostream& os,const paishengclass& ps){
os<<(const baseclass&) ps;
//......
}
强制类型转换
使用强制类型转换将派生类转换为基类,以调用基类方法
(const base_class&) paisheng_class
19. 代码重用
19.1 vector、valarray、array
std::vector<double> ved1(10), ved2(10), ved3(10);
std::vector<double> ved1{1.1, 2.2, 3.3, 4.4}//可以这样赋初值
array<double, 10> vod1, vod2, vod3;
valarray<double> vad1(10), vad2(10), vad3(10);
vector是STL中的内容,可以使用push_back()、insert()、begin()、end()等方法,其他两个不是STL内容,但是array可以使用begin()、end()、rbegin()、rend()方法
valarray模板类
#include<valarray>
valarray<type_name> name;
valarray<type_name> name(size);//size为int类型,括号里面只有一个数表示的是数组的长度
valarray<int> v1(8);//长度为8
valarray<double> v2(10,8)//初始化成员
operator[]():访问各个元素
size():返回元素个数
sum():返回元素总和
max():返回最大值
min():返回最小值
使用[]时候,和普通数组不一样的是并不表示地址,要使用取地址符 &v1[10]表示地址
valarray重载了所有运算符号,并且运算的是整个数组
vad3 = vad1 + vad2; //vad3中的每个元素是vad1与vad2的和
vad3 = vad1 + vad2; //vad3中的每个元素是vad1与vad2的乘积
vad3 = 2.5 * vad3; // vad3中的每个元素扩大2.5倍
vad3 *= 2.5;
vad3 = log(vad1);//与下面的方法一样
vad3 = vad1.apply(log);//vad3为vad1每个元素求对数
vad3 = sqrt(vad1);//对每个元素求平方根
vad3 = 10.0* ((vad1 + vad2) / 2.0 + vad1 * cos(vad2));//可以执行多部运算
sort(begin(vad), end(vad)); //使用sort()对内容排序,vad的迭代器用法与STL不同,用begin(vad)而不是vad.begin()
valarray<int> numbers(10);
valarray<bool> vbool = numbers > 9;//vbool[i]被设置为numbers[i] > 9的值,即true或false
varint[slice(1,4,3)] = 10; //slice(1, 4, 3)创建的对象表示选择4个元素,它们的索引分别是1、4、7和10
slice对象被初始化为三个整数值:起始索引、索引数和跨距。
19.2 包含对象成员的类has-a
一个类的私有数据成员包含另一个类的对象,则只能在类里面调用包含对象的方法,只获得了成员对象的实现,并么没有继承接口。
如果要用大类使用包含类的方法,则要在大类里面定义方法
#include <iostream>
#include <string>
#include <valarray>//模板类
class Student
{
private:
typedef std::valarray<double> ArrayDb;
std::string name; // contained object
ArrayDb scores; // contained object
// private method for scores output
std::ostream & arr_out(std::ostream & os) const;
public:
Student() : name("Null Student"), scores() {}//构造函数,采用初始化列表语法,初始化顺序和前面定义数据成员的顺序一样
explicit Student(const std::string & s)
: name(s), scores() {}//explicit关闭隐式转换,一个参数转换为一个类
explicit Student(int n) : name("Nully"), scores(n) {}//n表示的是scores的长度
Student(const std::string & s, int n)
: name(s), scores(n) {}//使用初始化列表的方法,后面没有分号
Student(const std::string & s, const ArrayDb & a)
: name(s), scores(a) {}
Student(const char * str, const double * pd, int n)
: name(str), scores(pd, n) {}//pd是一个数组
~Student() {}
double Average() const;
const std::string & Name() const;
double & operator[](int i);
double operator[](int i) const;
// friends
// input
friend std::istream & operator>>(std::istream & is,
Student & stu); // 1 word
friend std::istream & getline(std::istream & is,
Student & stu); // 1 line
// output
friend std::ostream & operator<<(std::ostream & os,
const Student & stu);
};
#endif
19.3 私有继承
使用私有继承,基类的公有成员和保护成员都将称为派生类的私有成员,基类的方法将不会成为派生对象公有接口的一部分
调用基类方法用类名加作用域解析符,调用数据使用强制类型转换
class Student: prvate std::string,private std::valarray<double>//从多个类派生,中间使用逗号,如果没有写派生类型,则默认未private类型
{
public:
}
私有继承和包含的区别
1)包含将需要使用的类作为一个命名的成员对象添加到类中,而私有继承则是将对象作为一个未被命名的继承对象添加到类中,
2)包含使用自己命名的的对象来调用基类的函数,在继承类中使用类名和作用域来调用基类方法,使用类名标识构造函数
Student(const char* str,const double* pd,int n): std::string(str),std::valarray(pd,n){}
私有继承访问基类对象
因为基类对象没有名称,只能通过将派生类强制类型转换为基类来调用基类部分的数据
const string& Student::Name() const
{
return (const string& )*this;//将派生类强制类型转换为string基类来调用string表示的数据
}
应更倾向于使用包含的方式,但是如果需要重新定义虚函数,则应该使用私有继承
保护继承 类的公有成员和保护成员都将成为派生类的保护成员
使用using重新定义访问权限
在派生类的公有方法里面使用using指令将基类的某些方法包含在里面
class Sudent : private std::string,private std::valarray<double>{
public:
using std::valarray<double>::max;//使用using声明时,函数只要函数名
using std::valarray<double>::min;//可以通过Student用点符号直接调用min()函数
using std::valarray<double>::operator[];
}
多重继承 虚基类
19.4 类模板template
template <class Type>
template <typename T>
使用模板类时,函数定义时候要将类限定符Class_Name::改为Class_Name::
template <class Type>//声明是一个模板类
class Stack
{
private:
enum {MAX = 10}; // constant specific to class
Type items[MAX]; // 这里的Type就是数据类型
int top; // index for top stack item
public:
Stack();
bool isempty();
bool isfull();
bool push(const Type & item); // add item to stack
bool pop(Type & item); // pop top into item
};
template <class Type>//每个函数前面都要加上这句话
Stack<Type>::Stack()//构造函数,类名后面加上<模板>
{
top = 0;
}
template <class Type>
bool Stack<Type>::isempty()
{
return top == 0;
}
template <class Type>
bool Stack<Type>::isfull()
{
return top == MAX;
}
template <class Type>
bool Stack<Type>::push(const Type & item)
{
if (top < MAX)
{
items[top++] = item;
return true;
}
else
return false;
}
template <class Type>
bool Stack<Type>::pop(Type & item)
{
if (top > 0)
{
item = items[--top];
return true;
}
else
return false;
}
使用模板类
隐式实例化
Class_Name<int> stack;
Stack<string> colonels;//在类后面加上<数据类型>
显示实例化,要在模板定义的名称空间中
template lass Class_Name<string>;
<>内的内容会替换掉类定义中的Type,在类外面定义类的成员函数一定要用Class_Name作为类名
可以为类型参量提供默认参数
template<classType=int>;
成员模板
模板类里面使用模板成员
template <typename T>
class beta//模板类
{
private:
template <typename V> // nested template class member
class hold//hold成员也是一个模板类
{
private:
V val;
public:
hold(V v = 0) : val(v) {}
void show() const { cout << val << endl; }
V Value() const { return val; }
};
hold<T> q; // template object
hold<int> n; // template object
public:
beta( T t, int i) : q(t), n(i) {}
template<typename U> // template method
U blab(U u, T t) { return (n.Value() + q.Value()) * u / t; }
void Show() const { q.show(); n.show();}
};
指定多个泛型
template <class T,class TT>
class Trophy
{
//...
}
Trophy<double,string> mix;
将模板用作参数
模板里面的typename T 是一个模板类
template<template <typename T> class Thing>;
class Crab
{
private:
Thing<int> S1;//Thing在实例化时是具体的模板类的类名
Thing<double> S2;
}
这里的template class相当于typename
Crab<Stack> nebula;//Stack是一个模板类,替换掉上面的Thing
19.5 模板类友元
1) 非模板友元
一种是友元函数于模板无关,形参不是模板类,则直接将它当成一个普通函数即可
template <class Type>
class Has-Friend
{
private:
public:
friend void counts();
}
//============使用===========
counts();//在主函数里面直接用函数名称调用即可
另一种是友元函数的形参为模板类,在声明和定义时要用模板类<>的方式
template <class Type>
class Has-Friend
{
private:
public:
friend void report(Has_Friend<Type> &);//里面的形参不能只给类名,还有给出模板<Type>
}
//============使用===========
HasFriend<int> hfi1(10);
reports(hfi1);//在主函数里面直接用函数名称调用即可
2)约束模板友元函数
友元函数是一个模板函数,要在类定义的前面声明每个模板函数,然后在类中将其再次声明为友元函数
template <typename T> void counts();//先声明这是模板函数
template <typename T> void report(T& );
template <class Type>
class Has_Friend
{
//...
friend void counts<Type>();//再次声明,这里要指定类模板
friend void report<>(Has_Friend<Type> &);
//全程friend void report<Has_Friend<Type>>(Has_Friend<Type> &);
}
//===============调用友元函数===================
counts<int>();
Has_Friend<int> hfi1(10);
report<hfi1>;
3) 非约束模板友元函数
只在类内部定义友元函数,且友元模板类型参数于模板类类型参数是不同的
19.6 模板别名
可使用typedef为模板具体化指定别名
typedef std::array<double,12> arrd;
ttypedf std::array<int,12> arri;
typdef std::array<std::string,12> arrst
arrd score;//arrd就表示一个上述重命名的类型
arri num;
arrst name;
使用模板提供一些列的别名
template<typename T>
using arraytype = std::array<T,12>;//这里将arraytype定义为一个模板别名,可以用它来指定类型
arraytype<double> score;//arraytype<T>表示是std::array<T,12>
arraytype<int> number;
using = h和typedef一样
typedef const char* ptr_char;
using ptr_int = const int*;
20. 友元、异常
20.1 友元类
友元类的所有方法可以访问原始类的私有公有成员,即可通过原始类的对象来使用函数和数据,在一个类中加入了ing一个友元类friend class Class_Name
友元成员函数
在原始类中添加某个类的成员函数作为友元,需要对原始类进行前向声明,如果整个类是友元类,则不需要前向声明
class original_class;//原始类前向声明
class friend_class
{//...
void set_fun(original_class& oc);
}
class original_class
{
//.....
friend friend_class::set_fun(original_class& oc);//友元成员函数
}
共同的友元
一个函数可以处理多个类的对象,可以将这个函数设置为多个类的友元函数
class cla_1;//前向声明
class cla_2
{
friend void dou_fun(cla_1& a,cla_2& b);//处理两个类对象的友元函数
friend void dou_fun(cla_2& b,cla_1& a);
};
class cla_1
{
friend void dou_fun(cla_1& a,cla_2& b);
friend void dou_fun(cla_2& b,cla_1& a);
};
inline void dou_fun(cla_1& a,cla_2& b)//使用内联的方法定义函数
{
//.....
}
inline void dou_fun(cla_2& b,cla_1& a)
{
//.....
}
20.2 嵌套类
将类声明放在另一个类中,则前面的类称为嵌套类,后面的称为包含类
包含类的成员函数可以创建和使用嵌套类的对象
如果嵌套类的声明是在公有部分,则在类的外面可以创建使用嵌套类对象,通过包含类作用域解析符
包含关系是在类定义里面创建一个对象,而嵌套没有创建对象
clsaa include_class//包含类
{
class nested_class//嵌套类
{
public:
Item item;
nested_class* next;
nested_class(const Item& it):item(it),next(nullptr){}//构造函数
}
}
如果在外面定义嵌套类的构造函数,则要使用两次作用域解析符
include_class::nested_class::nested_class():item(it),next(nullptr){}//使用两层作用域解符
如果嵌套类声明在包含类的公有部分,则在类外可以创建嵌套类的对象,使用包含类的作用域解析符
include_class::nested_class ne_clas;
模板中的嵌套类
template <class Item>
class QueueTP//包含类
{
private:
enum {Q_SIZE = 10};
class Node//嵌套类
{
public:
Item item;//这里的数据类型是上面模板定义的泛型
Node * next;
Node(const Item & i):item(i), next(0){ }
};
Node * front; // pointer to front of Queue
Node * rear; // pointer to rear of Queue
int items; // current number of items in Queue
const int qsize; // maximum number of items in Queue
QueueTP(const QueueTP & q) : qsize(0) {}
QueueTP & operator=(const QueueTP & q) { return *this; }
public:
QueueTP(int qs = Q_SIZE);
~QueueTP();
bool isempty() const
{
return items == 0;
}
bool isfull() const
{
return items == qsize;
}
int queuecount() const
{
return items;
}
bool enqueue(const Item &item); // add item to end
bool dequeue(Item &item); // remove item from front
};
// QueueTP methods
template <class Item>
QueueTP<Item>::QueueTP(int qs) : qsize(qs)//模板类的函数定义,作用域解析符要加上<泛型>
{
front = rear = 0;
items = 0;
}
template <class Item>
QueueTP<Item>::~QueueTP()
{
Node * temp;
while (front != 0) // while queue is not yet empty
{
temp = front; // save address of front item
front = front->next;// reset pointer to next item
delete temp; // delete former front
}
}
// Add item to queue
template <class Item>
bool QueueTP<Item>::enqueue(const Item & item)
{
if (isfull())
return false;
Node * add = new Node(item); // create node
// on failure, new throws std::bad_alloc exception
items++;
if (front == 0) // if queue is empty,
front = add; // place item at front
else
rear->next = add; // else place at rear
rear = add; // have rear point to new node
return true;
}
// Place front item into item variable and remove from queue
template <class Item>
bool QueueTP<Item>::dequeue(Item & item)
{
if (front == 0)
return false;
item = front->item; // set item to first item in queue
items--;
Node * temp = front; // save location of first item
front = front->next; // reset front to next item
delete temp; // delete former first item
if (items == 0)
rear = 0;
return true;
}
QueueTP<string> cs(5);//创建一个Item为string类型的包含类的对象,嵌套类中使用的数据类型也就是string
string temp;
getline(cin, temp);
cs.enqueue(temp);
20.3 异常
std::aort();//可用来终止程序
1)thorw try catch
int main()
{
double x, y, z;
std::cout << "Enter two numbers: ";
while (std::cin >> x >> y)
{
try { // start of try block
z = hmean(x, y);//如果在try中有异常(throw)发生,则查找并执行与之匹配的catch块代码
} // end of try block
catch (const char* s) //括号内的参数类型是throw后面根的类型
{
std::cout << s << std::endl;
std::cout << "Enter a new pair of numbers: ";
continue;
} // end of handler
std::cout << "Harmonic mean of " << x << " and " << y
<< " is " << z << std::endl;
std::cout << "Enter next set of numbers <q to quit>: ";
}
std::cout << "Bye!\n";
return 0;
}
double hmean(double a, double b)
{
if (a == -b)
throw "bad hmean() arguments: a = -b not allowed";
return 2.0 * a * b / (a + b);
}
throw关键字后面根的就是异常的类型,前文中是字符串类型,有异常发生则该部分处理程序终止,回退到try中,找到于try对应的处理程序catch,然后执行catch里面的内容
2)将对象用做异常
throw后面跟一个对象,对应的catch模块传入的参数就是这个类的对象
void function1()
{
if()
throw bad_1();//这里表示通过构造函数生成bad_1的对象
}
void function2()
{
if()
throw bad_2();//这里表示通过构造函数生成bad_2的对象
}
try{
function1();//如果这个函数发生异常,就会去找异常对象对应的catch块代码
function2();
}
catch(bad_1& bad1)
{
bad1.msgs();
}
catch(bad_2& bad2)
{
bad2.msgs();
}
catch代码块中使用的是引用传递参数,但是 引发异常时编译器总是创建一个临时拷贝。之所以使用引用时因为,可以把很多种异常从一个基类中派生
2)exception类
包含exception头文件,exception是一个基类,其中包含以个what()虚函数,用来返回表示错误类型的字符串,自己从虚类中派生出 自己想要表达的错误类型的类
#include<exception>
class bad_one :public std::exception
{
public:
const char* what() { return "bad one"; }
};
class bad_two :public std::exception
{
public:
const char* what() { return "bad two"; }
}
stdexcept异常类
| invalid_argument | 指出给函数传递了一个异常值 |
|---|---|
| legth_error | 没有足够的空间来执行所需要的操作 |
| out_of_bounds | 索引错误,比如数组索引无效 |
| runtime_error |
3)bad_alloc异常和new
#include<exception>
#include<cstdlib>
class bad_one :public std::exception
{
public:
const char* what() { return "bad one"; }
};
class bad_two :public std::exception
{
public:
const char* what() { return "bad two"; }
};
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IY4Y8eIE-1667439494044)(C:\Users\Jeet\AppData\Roaming\Typora\typora-user-images\image-20220423172024080.png)]
可以使用std::nothorw使new失败时返回空指针
int* pi=new (std::nothrow) int;
20.4 RTTI运行阶段类型识别
RTTI(Runtiome Tye Identifiction),用于跟踪生成对象的类型等
dynamic_cast,使用一个指向基类的指针来生成一个指向派生类的指针;
typeid,返回一个指向对象类型的值
type_info,结构体存储有关特定类型的指针
1) dynamic_cast
data_type2* obj;
data_type2* ptr1=dynamic_cast<data_type2 *> obj;
数据类型2的指针能否被转换为数据类型1的指针,如果不可以则返回空指针
直接或间接派生的类(数据类型2)的对象的指针可以被转换为基类对象的指针
2)typeid运算符和type_info类
包含头文件#include
typeid()用来计算两个数据的类型是否相同
#include<typeinfo>
int* a;
double* b;
if (typeid(int*) == typeid(a))
cout << "typeid(int) == typeid(a)" << endl;
typeid(int*) == typeid(a)
typeid(int) == typeid(*a)
typeid(data_name).name() 用于返回一个表示数据类型的字符串,可以cout查看
20.5 类型转换运算符
| dynamic_cast | 判断是否能转换 |
|---|---|
| const_cast | 改变值为const或volatile |
| static_const | 只有两种类型能被转换才是合法的 |
| reinterpret_cast |
danamic_cast<type_name_ptr> ptr1;
class_name bar;
const class_name* pbar=&bar;
class_name* pb=const_cast<class_name*>(pbar);//pbar是一个const指针,而pb是一个可修改的指针
//static_cast<type_name>(expression) 只有type_name可被隐式转换为expression或者后者可被隐式转换为前者才是合法的
int a;
double b;
int* pa=static_cast<int*>(&b);
21. String类和标准模板库
21.1 string类
1) string类的构造函数
| 构造函数 | |
|---|---|
| string(const char* s) | 括号中直接“字符串” |
| string(size n,char c) | 创建包含n个c的string |
| string(const string&str) | 把一个string对象赋值给另一个 |
| string() | string str |
| string(const char* s ,size n) | 将字符串S的前n个字符复制给字符串 |
| template string(Iter beging, iter end) | 将Iter从begin开始到end结束的字符复制给string |
| string(const string & sttr , size pos=0,size n=npos) | 把str从pos开始后面npos个字符赋值给字符串 |
| string(string && str) noexcept | |
| string(initializer_listil) |
using namespace std;
string one("Lottery Winner!"); // ctor #1
string two(20, '$'); // ctor #2
string three(one); // ctor #3
one += " Oops!"; // overloaded +=
two = "Sorry! That was ";
//可以像数组一样访问string数据
three[0] = 'P';
string four; // ctor #4
four = two + three; // overloaded +, =
char alls[] = "All's well that ends well";
//把alls的前20个字符赋值给five
string five(alls,20); // ctor #5
string six(alls+6, alls + 10); // ctor #6
string seven(&five[6], &five[10]); // ctor #6 again
string eight(four, 7, 16); // ctor #7
对于string类型的数据而言,&string_name[10]才表示地址,不能用string_name+10表示地址
2) string类的输入
#include<string>
using std::string;
using std::cin;
string stuff
cin>>sting;
getline(cin,stuff);
getline(stuff,':');//后面的参数表示确定输入的边界
常量string::npos表示string对象的最大允许长度
3) 从文件中读取string并指定分界符
// 从文件tobuy.tx中读取string
#include <iostream>
#include <fstream>
#include <string>
#include <cstdlib>
int main()
{
using namespace std;
ifstream fin;//fin和cin对象类型,需要自己生成对象
fin.open("tobuy.txt");//这里是相对路径
if (fin.is_open() == false)//打开文件是否成功
{
cerr << "Can't open file. Bye.\n";
exit(EXIT_FAILURE);
}
string item;
int count = 0;
getline(fin, item, ':');//从文件中读取文件
while (fin) // while input is good
{
++count;
cout << count << ": " << item << endl;
getline(fin, item, ':');
}
cout << "Done\n";
fin.close();
// std::cin.get();
// std::cin.get();
return 0;
}
4)size() length()都可以求string对象的长度
string str;
str="dsfreefre";
int len=str.size();
5) find()方法
| 方法参数 | |
|---|---|
| find(const& str,int pos=0)const | 查找string对象中子字符串str从pos位置后首次出现的位置,找到则返回索引值,没有找到则返回string::npos或者-1 |
| find(const char* s , int pos=0)const | 查找string对象中从位置pos开始,首次出现字符串char s[]的位置,不管pos为多少,如果找到,返回的索引值为从0开始数的 |
| find(const char* s ,int pos,int n) | 查找s从pos位置开始前n个子字符串 |
| find(cahr ch , int pos =0)const | 从string对象中查找字符ch |
| rfind(char ch) | 查找ch最后一次出现的位置 |
| find_first_of(char ch) | 查找字符ch,或者字符串第一次出现的位置 |
| find_last_of() | 查找字符ch,或者字符串最后一次出现的位置 |
| find_first_not_of() | 查找第一个不包含在参数中的字符 |
string str = "lijun12frbrtgrt23f4";
string str1 = "jun";
int n=str.rfind('f');
int m=str.find('lijun',3);
cout << "n= " << n << endl;
str.capacity();//返回str所占内存大小
str.reserve(50);//为str申请内存块最小长度,最后申请下来的可能比50大
ofstream fout;
fout.open(str.c_str());//str.c_str()将string转称char ch[]字符串类型
21.2 智能指针
三个智能指针模板(auto_ptr 、unique_ptr 、shared_ptr),包含头文件memory
#include<memory>
std::auto_ptr<string> ps(new string);
std::unique_ptr<double> ps(new double);
std::shared_ptr<string> ps(new string);
shared_ptr通过引用计数来管理所有权的问题,智能指针被赋值时,引用计数+1,指针过期时引用技术-1,最后一个指针过期时才调用delete
每个 shared_ptr 对象在内部指向两个内存位置:
1、指向对象的指针。
2、用于控制引用计数数据的指针。
共享所有权如何在引用计数的帮助下工作:
1、当新的 shared_ptr 对象与指针关联时,则在其构造函数中,将与此指针关联的引用计数增加1
2、当任何 shared_ptr 对象超出作用域时,则在其析构函数中,它将关联指针的引用计数减1。如果引用计数变为0,则表示没有其他 shared_ptr 对象与此内存关联,在这种情况下,它使用delete函数删除该内存。
std::shared_ptr<int> p1(new int());//创建指针
p1.use_count();//查看引用计数
std::shared_ptr<int> p1 = std::make_shared<int>();//make_shared()创建指针
std::shared_ptr<int> p2(p1);//p2 与p1指向同一个指针
当 shared_ptr 对象指向数组
// 指向数组的智能指针可以使用这种形式
std::shared_ptr<int[]> p3(new int[12]); // 正确使用方式
与普通指针相比,shared_ptr仅提供-> 、*和==运算符,没有+、-、++、--、[]等运算符
shared_ptr 检测空值方法
std::shared_ptr<Sample> ptr3;
if(!ptr3)
std::cout<<"Yes, ptr3 is empty" << std::endl;
if(ptr3 == NULL)
std::cout<<"ptr3 is empty" << std::endl;
if(ptr3 == nullptr)
std::cout<<"ptr3 is empty" << std::endl;
可以将unique作为右值 赋值给shared_ptr
21.3 标准模板库
STL(Standard template library)提供了容器、迭代器、函数对象和算法的模板;迭代器能够用来遍历容器的对象,是一种广义指针
声明迭代器 ::iterator
STL的一些基本方法
size()——返回容器中元素个数
capacity()——返回容器总容量
swap()——交换两容器的内容
begin()——返回容器中第一个元素的迭代器
end()——返回容器中最后一个元素的迭代器,标识超过结尾的位置
for(double x : vec_doub)——for循环用x访问容器元素
21.4 模板类vector
push_back()——将元素添加到容器的最后
erase(iterator pos1,iterator pos2)——删除指定区间的内容
for_each()——用函数遍历容器中每个元素
random_shuffle()——对指定范围内的容器元素进行随机排序
sort()——对容器内指定元素进行升序排序
#include<vector>
std::vector<int> rating(5);//用()指定向量长度
std::vector<double> douarrr(20);
rating[0]=9;//可以用[]符号访问每个元素
vector声明变量
vector<int> v1;
vector<father> v2;
vector<string> v3;
vector<vector<int> >; //注意空格。这里相当于二维数组int a[n][n];
vector<int> v5 = { 1,2,3,4,5 }; //列表初始化,注意使用的是花括号
vector<string> v6 = { "hi","my","name","is","lee" };
vector<int> v7(5, -1); //初始化为-1,-1,-1,-1,-1。第一个参数是数目,第二个参数是要初始化的值
vector<string> v8(3, "hi");
vector<int> v9(10); //默认初始化为0
vector<int> v10(4); //默认初始化为空字符串
push_back添加元素在末尾
使用push_back加入元素,并且这个元素是被加在数组尾部的。
for (int i = 0; i < 20; i++)
{
v1.push_back(i);
}
push_back会先为容器开辟空间,再赋值,下面的赋值方法是错误的,因为没有给v1开辟内存空间
vector<int> v1;
v1[1] = 0;
iterator,为vector类声明一个迭代器
using std::vector;
vector<double>::iterator pd;
vector<double> scores;
auto ps=scores.begin();//使用自动类型推断
pd=scores.begin();
*pd=22.3;
反向迭代器reverse_iterator
for (vector<string>::reverse_iterator iter = v6.rbegin(); iter != v6.rend(); iter++)
{
cout << *iter << endl;
}
insert 插入元素
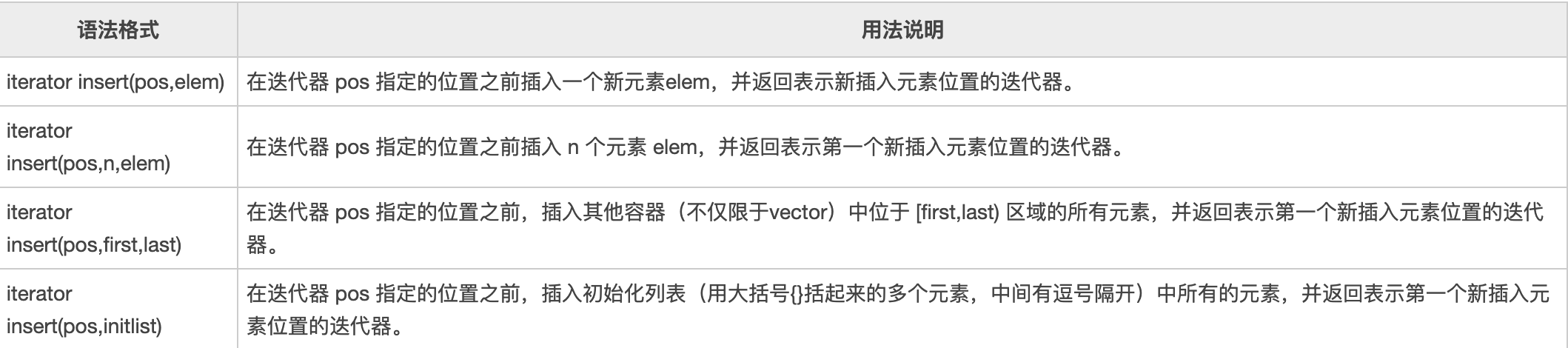
#include <iostream>
#include <vector>
#include <array>
using namespace std;
int main()
{
std::vector<int> demo{1,2};
//第一种格式用法
demo.insert(demo.begin() + 1, 3);//{1,3,2}
//第二种格式用法
demo.insert(demo.end(), 2, 5);//{1,3,2,5,5}
//注意:end()表示的是超尾元素,及最后一个元素的后一个位置
//第三种格式用法
std::array<int,3>test{ 7,8,9 };
demo.insert(demo.end(), test.begin(), test.end());//{1,3,2,5,5,7,8,9}
//第四种格式用法
demo.insert(demo.end(), { 10,11 });//{1,3,2,5,5,7,8,9,10,11}
for (int i = 0; i < demo.size(); i++) {
cout << demo[i] << " ";
}
return 0;
}
erase pop_back删除元素

#include <vector>
#include <iostream>
using namespace std;
int main()
{
vector<int>demo{ 1,2,3,4,5 };
demo.pop_back();
auto iter = demo.erase(demo.begin() + 1);//删除元素 2
}
遍历vector内容
vector<Review> books;
Review temp;
int num = books.size();
vector<Review>::iterator pr;//声明迭代器
for (pr = books.begin(); pr != books.end(); pr++)//遍历vector容器
{
ShowReview(*pr);
}
books.erase(books.begin() + 1, books.begin() + 3);//删除指定区间的内容
for_each(),将容器中的每个元素应用于某个函数
for_each要包含头文件algorithm,应用的函数不能改变容器内元素的值
#include <iostream>
#include <vector>
#include<algorithm>
void Show_Review(const double& doub)
{
std::cout << doub << std::endl;
}
int main()
{
using namespace std;
vector<double> vec_doub(10);
vector<double>::iterator pd;
double dou = 1.1;
for (pd = vec_doub.begin(); pd != vec_doub.end(); pd++)//遍历vector容器
{
*pd = dou;
dou += 1;
}
for_each(vec_doub.begin(),vec_doub.end(),Show_Review);
return 0;
}
for_each(vec_doub.begin(),vec_doub.end(),Show_Review);
for (pd = vec_doub.begin(); pd != vec_doub.end(); pd++)
{
Show_Review(*pd);
}
for(double x:vec_doub)Show_Review(x);//这三个函数相同
random_shuffle(vec_doub.begin(), vec_doub.end());//vec_doub内的元素随机排序
sort(vec_doub.begin(), vec_doub.end());//对容器内的元素进行升序排顺序
sort()排序函数
使用sort()函数时,如果容器元素是自定义对象,则需要对该对象进行operator<符号重载,sort(vec_doub.begin(), vec_doub.end(),paixuhanshu );最后的参数为自定义排序函数的函数名
for(double x:vec_doub)Show_Review(x); 用x访问vec_doub中的每个元素,x的类型也可以用auto指定
sort()函数也可以用于自定义数组
int arr[10] = { 4,1,5,2,6,3,7,3,1,9 };
sort(arr,arr+10);
21.5 泛型编程
STL是一种泛型编程,面向对象编程关注的是编程的数据方面,而泛型编程关注的是算法,泛型编程旨在编写独立于数据类型的代码。
迭代器 iterator
STL为每个标准模板类定义了iterator
输入迭代器、输出迭代器、正向迭代器、双向迭代器、随机访问迭代器
| 迭代器 | |
|---|---|
| 输入迭代器 | 对输入迭代器解出引用*可以使程序读取容器内容,但是不能修改值,即可以从容器中输入内容到程序中,单向通行,可以递增++不能递减 |
| 输出迭代器 | 从程序传输内容到容器中,对迭代器接触引用*可以修改容器内元素的值 |
| 正向迭代器 | 只能递增,每次遍历都是相同的顺序, |
| 双向迭代器 | 可以递增也可以递减 |
| 随机访问迭代器 | 可以随便跳转到任意位置,比如使用a+9,a[8],a+=10,也可以比较大小a<b,a>=b,指针就是一种随机访问迭代器 |
copy()、ostream_iterator、istream_iterator
copy(iterator1,iterator2,iterator3),将前两个迭代器之间的内容复制到最后一个迭代器(目标容器)开始位置的内容里面,会覆盖掉目标容器里面的内容
int casts[10] = { 6, 7, 2, 9 ,4 , 11, 8, 7, 10, 5 };
vector<int> dice(10);、
ostream_iterator模板
#include <iterator>
ostream_iterator<int, char> out_iter(cout, " ");
*out_iter+=15;//表示把15赋值给迭代器所指内容,然后迭代器+1
copy(dice.begin(), dice.end(), out_iter);
copy(dice.begin(), dice.end(),ostream_iterator<int, char> out_iter(cout, " "));//直接使用匿名迭代器
模板参数int表示发送给输出流的数据类型,char表示输出流使用的字符类型。构造函数里面的cout指出要使用的输出流对象,“ ” 表示输出内容分隔符号
istream_iterator模板
copy(istream_iterator<int,char>(cin), istream_iterator<int,char>(),dice.begain());//省略构造函数中的cin表示输入失败
#include <iostream>
#include <iterator>
#include <vector>
int main()
{
using namespace std;
int casts[10] = { 6, 7, 2, 9 ,4 , 11, 8, 7, 10, 5 };
vector<int> dice(10);
//把casts的数copy给dice
copy(casts, casts + 10, dice.begin());
cout << "Let the dice be cast!\n";
// 把dice数据copy给输出流ostream_iterator迭代器
ostream_iterator<int, char> out_iter(cout, " ");
copy(dice.begin(), dice.end(), out_iter);
cout << endl;
cout << "Implicit use of reverse iterator.\n";
//反向输出
copy(dice.rbegin(), dice.rend(), out_iter);
cout << endl;
cout << "Explicit use of reverse iterator.\n";
// vector<int>::reverse_iterator ri; //反向迭代器
for (auto ri = dice.rbegin(); ri != dice.rend(); ri++)
cout << *ri << ' ';
cout << endl;
// cin.get();
return 0;
}
revers_iterator 反向迭代器
rbegin()返回超尾迭代器,rend()返回第一个元素的迭代器,但是与begin()的类型不一样
vector<string>::reverse_iterator riter;
copy(dice.rbegin(),dice.rend(),out_iter);
back_insert_iterator 将元素插入到容器尾部,
front_insert_iterator 将元素插入到容器前端
insert_iterator 将元素插入到指定位置
#include <algorithm>
vector<int> dice(10);
back_insert_iterator <vector<int>> back_iter(dice);
insert_iterator<vector<int>> insert_iter(dice, dice.begin());
这里声明迭代器的时候,模板参数为容器类型,而构造函数参数为实际的容器名
#include <iostream>
#include <string>
#include <iterator>
#include <vector>
#include <algorithm>
void output(const std::string& s) { std::cout << s << " "; }
int main()
{
using namespace std;
string s1[4] = { "fine", "fish", "fashion", "fate" };
string s2[2] = { "busy", "bats" };
string s3[2] = { "silly", "singers" };
vector<string> words(4);
copy(s1, s1 + 4, words.begin());
for_each(words.begin(), words.end(), output);
cout << endl;
// construct anonymous back_insert_iterator object
copy(s2, s2 + 2, back_insert_iterator<vector<string> >(words));
for_each(words.begin(), words.end(), output);
cout << endl;
// construct anonymous insert_iterator object
copy(s3, s3 + 2, insert_iterator<vector<string> >(words, words.begin()));
for_each(words.begin(), words.end(), output);
cout << endl;
// cin.get();
return 0;
}
21.6 容器
容器时存储其他对象的对象,
其X表示容器类型,如vector;T表示存储在容器中的对象类型;a和b表示类型为X的值;r表示类型为X&的值;u表示类型为X的标识符(即如果X表示vector,则u是一个vector对象)
| 表 达 式 | 返 回 类 型 | 说 明 | 复 杂 度 |
|---|---|---|---|
| X :: iterator | 指向T的迭代器类型 | 满足正向迭代器要求的任何迭代器 | 编译时间 |
| X :: value_type | T | T的类型 | 编译时间 |
| X u; | 创建一个名为u的空容器 | 固定 | |
| X(); | 创建一个匿名的空容器 | 固定 | |
| X u(a); | 调用复制构造函数后u == a | 线性 | |
| X u = a; | 作用同X u(a); | 线性 | |
| r = a; | X& | 调用赋值运算符后r == a | 线性 |
| (&a)->~X() | void | 对容器中每个元素应用析构函数 | 线性 |
| a.begin() | 迭代器 | 返回指向容器第一个元素的迭代器 | 固定 |
| a.end() | 迭代器 | 返回超尾值迭代器 | 固定 |
| a.size() | 无符号整型 | 返回元素个数,等价于a.end()– a.begin() | 固定 |
| a.swap(b) | void | 交换a和b的内容 | 固定 |
| a = = b | 可转换为bool | 如果a和b的长度相同,且a中每个元素都等于(= =为真)b中相应的元素,则为真 | 线性 |
| a != b | 可转换为bool | 返回!(a= =b) | 线性 |
序列的要求
| 表 达 式 | 返 回 类 型 | 说 明 |
|---|---|---|
| X a(n, t); | 声明一个名为a的由n个t值组成的序列 | |
| X(n, t) | 创建一个由n个t值组成的匿名序列 | |
| X a(i, j) | 声明一个名为a的序列,并将其初始化为区间[i,j)的内容 | |
| X(i, j) | 创建一个匿名序列,并将其初始化为区间[i,j)的内容 | |
| a. insert(p, t) | 迭代器 | 将t插入到p的前面 |
| a.insert(p, n, t) | void | 将n个t插入到p的前面 |
| a.insert(p, i, j) | void | 将区间[i,j)中的元素插入到p的前面 |
| a.erase§ | 迭代器 | 删除p指向的元素 |
| a.erase(p, q) | 迭代器 | 删除区间[p,q)中的元素 |
| a.clear() | void | 等价于erase(begin(), end()) |
模板类deque、list、queue、priority_queue、stack和vector都是序列概念的模型
| 表 达 式 | 返 回 类 型 | 含 义 | 容 器 |
|---|---|---|---|
| a.front() | T& | *a.begin() | vector、list、deque |
| a.back() | T& | *- -a.end() | vector、list、deque |
| a.push_front(t) | void | a.insert(a.begin(), t) | list、deque |
| a.push_back(t) | void | a.insert(a.end(), t) | vector、list、deque |
| a.pop_front(t) | void | a.erase(a.begin()) | list、deque |
| a.pop_back(t) | void | a.erase(- -a.end()) | vector、list、deque |
| a[n] | T& | *(a.begin()+ n) | vector、deque |
| a.at(n) | T& | *(a.begin()+ n) | vector、deque |
①deque 双端队列 (double_ended queue)
deque<int , alloc , 8> ideq(20,9);//一段连续缓冲区可以存放8个int=32字节初始化内存,并将20个元素初始化为9.
cout <<"size = " << ideq.size() << endl;//20 deque上面存储的元素个数
②list 双向链表
#include <list>
#include <iterator>
#include <algorithm>
list强调元素的快速插入与删除,list不支持数组表示法
list() 声明一个空列表;
list(n) 声明一个有n个元素的列表,每个元素都是由其默认构造函数T()构造出来的
list(n,val) 声明一个由n个元素的列表,每个元素都是由其复制构造函数T(val)得来的
list(n,val) 声明一个和上面一样的列表
list(first,last) 声明一个列表,其元素的初始值来源于由区间所指定的序列中的元素
list<int> l1;
list<int> l2(2,0);
list<int>::iterator iter;
list成员和函数
| 函 数 | 说 明 |
|---|---|
| void merge(list<T, Alloc>& x) | 将链表x与调用链表合并。两个链表必须已经排序。合并后的经过排序的链表保存在调用链表中,x为空。这个函数的复杂度为线性时间 |
| void remove(const T & val) | 从链表中删除val的所有实例。这个函数的复杂度为线性时间 |
| void sort() | 使用<运算符对链表进行排序;N个元素的复杂度为NlogN |
| void splice(iterator pos, list<T, Alloc>x) | 将链表x的内容插入到pos的前面,x将为空。这个函数的的复杂度为固定时间 |
| void unique() | 将连续的相同元素压缩为单个元素。这个函数的复杂度为线性时间 |
using namespace std;
list<int> one(5, 2); // list of 5 2s
int stuff[5] = {1,2,4,8, 6};
list<int> two;
//插入元素
two.insert(two.begin(),stuff, stuff + 5 );
int more[6] = {6, 4, 2, 4, 6, 5};
list<int> three(two);
three.insert(three.end(), more, more + 6);
three.splice(three.begin(), one);//把one的内容移动到three里面去
three.sort();//从小到达排序
three.unique();//将相同元素删除到只有一个
③forward_list 单链表
④queue 队列
queue不允许随机访问队列元素,不允许遍历队列,
queue的操作
| 方法 | 说 明 |
|---|---|
| bool empty()const | 如果队列为空,则返回true;否则返回false |
| size_type size()const | 返回队列中元素的数目 |
| T& front() | 返回指向队首元素的引用 |
| T& back() | 返回指向队尾元素的引用 |
| void push(const T& x) | 在队尾插入x |
| void pop() | 删除队首元素 |
⑤priority_queue
priority_queue模板类(queue头文件)最大的元素被移到队首,默认的底层类是vector。可以修改用于确定哪个元素放到队首的比较方式,方法是提供一个可选的构造函数参数:
priority_queue<int> pq1;
priority_queue<int> pq2(greater<int>);
⑥stack 栈
头文件stack
不允许随机访问栈元素,不允许遍历栈。
即可以将压入推到栈顶、从栈顶弹出元素、查看栈顶的值、检查元素数目和测试栈是否为空。
stack的操作
| 方法 | 说 明 |
|---|---|
| bool empty()const | 如果栈为空,则返回true;否则返回false |
| size_type size()const | 返回栈中的元素数目 |
| T& top() | 返回指向栈顶元素的引用 |
| void push(const T& x) | 在栈顶部插入x |
| void pop() | 删除栈顶元素 |
⑦array
头文件array,并非STL容器,因为其长度是固定的。
operator [] ()和at()。可将很多标准STL算法用于array对象,如copy()和for_each()。
21.7关联容器
关联容器将值与键关联在一起,并使用键来查找值,X::key_type指出了键的类型。
允许插入新元素,但不能指定元素的插入位置
STL提供了4种关联容器:set、multiset、map和multimap。前两种头文件set,后两种是文件map
set
set,其值类型与键相同,键是唯一的,集合中不会有多个相同的键.。map中,值与键的类型不同,键是唯一的,每个键只对应一个值
set<string> A; // 关联集合,可反转,可排序,且键是唯一的
set<string, less<string> > A; // older i
const int N = 6;
string s1[N] = {"buffoon", "thinkers", "for", "heavy", "can", "for"};
set<string> A(s1, s1 + N); // 构造函数中给出迭代器区间,将set初始化为迭代器区间里面的内容,相同的元素只保留一个
ostream_iterator<string, char> out(cout, " ");
copy(A.begin(), A.end(), out);
求集合AB的并集set_union
set_union(A.begin(), A.end(), B.begin(), B.end(),
ostream_iterator<string, char> out(cout, " "));//把A和B求并集,将结果复制到out迭代器中
函数set_intersection()和set_difference()分别查找交集和获得两个集合的差
数据的插入
string s("tennis");
A.insert(s); // insert a value
B.insert(A.begin(), A.end()); // insert a range
map
map可以像数组一样用[“值”]来访问值,yigemap[“the”],表示与键the对应的值是多少
multimap
multimap键和值的类型不同,同一个键可能与多个值相关联。
其中键类型为int,存储的值类型为string:
multimap<int,string> codes;
pair<const int, string> item(213, "Los Angeles");//模板类pair<class T, class U>将两种值存储到一个对象中
codes.insert(item);//使用pair对象插入到codes中
codes.insert(pair<const int, string> (213, "Los Angeles"));//创建匿名pair对象并将它插入:
对于pair对象,可以使用first和second成员来访问其两个部分:
pair<const int, string> item(213, "Los Angeles");
cout << item.first << ' ' << item.second << endl;
关联容器是基于树结构的,而无序关联容器是基于数据结构哈希表的,这旨在提高添加和删除元素的速度以及提高查找算法的效率。4种无序关联容器,unordered_set、unordered_multiset、unordered_map和unordered_multimap
21.8 函数对象
函数对象(函数符)可以以函数方式与()结合使用的对象,包括函数名、指向函数的指针和重载了()符号的类对象
class Linear
{
private:
double slope;
double y0;
public:
Linear(double sl_ = 1, double y_ = 0)
: slope(sl_), y0(y_) {}
double operator()(double x) {return y0 + slope * x; }//重载()符,使得对象可以后面接(),当作一个函数用
};
Linear f1;
Linear f2(2.5, 10.0);
double y1 = f1(12.5); // right-hand side is f1.operator()(12.5)
double y2 = f2(0.4);
-
生成器(generator)是不用参数就可以调用的函数符。
-
一元函数(unary function)是用一个参数可以调用的函数符。
-
二元函数(binary function)是用两个参数可以调用的函数符。
-
返回bool值的一元函数是谓词(predicate);
-
返回bool值的二元函数是二元谓词(binary predicate)。
bool WorseThan(const Review & r1, const Review & r2);
...
sort(books.begin(), books.end(), WorseThan);//这里的WorseThan就是一个二元谓词,是一个函数对象传参给sort函数
list模板的remove_if()成员,该函数将谓词应用于区间中的每个元素,如果谓词返回true,则删除这些元素。
bool tooBig(int n){ return n > 100; }//删除链表three中所有大于100的元素:
list<int> scores;
//...
scores.remove_if(tooBig);//tooBig就是一个函数符
类函数符
通过重载类()运算符,使用类的数据成员来代替函数参数,使得函数符可以使用少的参数
template<class T>
class TooBig
{
private:
T cutoff;
public:
TooBig(const T & t) : cutoff(t) {}
bool operator()(const T & v) { return v > cutoff; }
};
TooBig<int> f100(100);//生成一个名叫f100的对象,括号里的是构造函数的参数
list<int> etcetera{50,100,39,43,556,322};
etcetera.remove_if(f100);
etcetera.remove_if(TooBig<int>(200));//构造匿名对象作为函数符,remove_if的参数
一个接受两个参数的模板函数,可以使用类将它转换为单个参数的函数对象
预定义的函数符 头文件functional
函数transform()
版本一,接受4个参数,前两个参数是指定容器区间的迭代器,第3个参数是指定将结果复制到哪里的迭代器,最后一个参数是一个函数符,它被应用于区间中的每个元素,生成结果中的新元素。
const int LIM = 5;
double arr1[LIM] = {36, 39, 42, 45, 48};
vector<double> gr8(arr1, arr1 + LIM);
ostream_iterator<double, char> out(cout, " ");//输出迭代器
transform(gr8.begin(), gr8.end(), out, sqrt);//计算gr8中每个数的平方根然后输出
版本2 ,使用一个接受两个参数的函数,并将该函数用于两个区间中元素。它用另一个参数(即第3个)标识第二个区间的起始位置。
mean(double,double)返回两个值的平均值,
//输出来自gr8和m8的值的平均值:
transform(gr8.begin(), gr8.end(), m8.begin(), out, mean);
plus< >类 来完成常规的相加运算:
#include <functional>
...
plus<double> add; // 生成一个plus对象add
double y = add(2.2, 3.4);
它使得将函数对象作为参数很方便:
transform(gr8.begin(), gr8.end(), m8.begin(), out, plus<double>() );
运算符和相应的函数符
使用函数符生成对应的函数对象plus add
| 运 算 符 | 相应的函数符 |
|---|---|
| + | plus |
| - | minus |
| * | multiplies |
| / | divides |
| % | modulus |
| - | negate |
| = = | equal_to |
| ! = | not_equal_to |
| > | greater |
| < | less |
| >= | greater_equal |
| <= | less_equal |
| && | logical_and |
| | | | logical_or |
| ! | logical_not |
| 运 算 符 | 相应的函数符 |
|---|---|
| + | plus |
| - | minus |
| * | multiplies |
| / | divides |
| % | modulus |
| - | negate |
| = = | equal_to |
| ! = | not_equal_to |
| > | greater |
| < | less |
| >= | greater_equal |
| <= | less_equal |
| && | logical_and |
| | | | logical_or |
| ! | logical_not |
自适应函数符
函数符自适应性的意义在于:函数适配器对象可以使用函数对象,并认为存在这些typedef成员。
用binder1st和binder2nd类将自适应二元函数转换为自适应一元函数。
binder1st(f2, val) f1;//函数f2需要两个参数,f1为他的自适应一元函数,f2其中一个参数用val
21.9 算法
可以用==比较不同类型的容器,如果内容和顺序都相同,则返回true
STL算法库分为四种,
非修改式序列操作,修改式序列操作,排序和相关操作,通用数字运算
前三种头文件algorithm,最后一种头文件numeric
STL函数使用迭代器和迭代器区间
next_permutation(iterator iter1 , iterator iter2),将容器内容转化为下一种排列方式,直到所有的排列都完全有了。
#include <iostream>
#include <string>
#include <algorithm>
int main()
{
using namespace std;
string letters;
cout << "Enter the letter grouping (quit to quit): ";
while (cin >> letters && letters != "quit")
{
cout << "Permutations of " << letters << endl;
sort(letters.begin(), letters.end());
cout << letters << endl;
while (next_permutation(letters.begin(), letters.end()))//将容器内的所有元素的排列方式都列出来
cout << letters << endl;
cout << "Enter next sequence (quit to quit): ";
}
cout << "Done.\n";
return 0;
}
链表删除某个元素,remove, la.remove(4); remove后元素被删除,容器长度变短
STL中的remove形参为迭代器,remove(la.begin(), la.end() , 4); remove后返回一个被删除元素后的迭代器,迭代器前面没有了被删除的元素,迭代器后面还有元素。
initializer_list模板类
complex复数数组
22. 输入、输出和文件
22.1 流和缓冲区
管理输入包含两步,将流与输入去向的程序关联起来,将流与文件连接起来
缓冲区帮助匹配两种不同的信息传输速率
22.2 cout输出
put()可用于输出字符,write()可用于输出字符串
cout.put('w');
cout.put('l').put("i");
string str1="lijun";
cout.write(str1,5);//第二个参数表示要显示几个字符串
flush刷新缓冲区,endl刷新缓冲区并提行
cout<<fulsh;
使用cout格式化
1)dec hex oct 十进制,十六进制,八进制
hex(cout);
cout<<hex;
2)调整字符宽度
cout.width(12);//下一次的输出内容具有12宽度,右对齐
//只影响下一次的输出
3)填充字符
cout。fill('*');//用*来填充空格,设置一直有效
4)设置浮点数显示精度
cout.prcision(3);//浮点数显示的总位数为3,设置一直有效
5)显示末尾的0
cout.setf(ios_base::showpoint);
6)setf()
| 常 量 | 含 义 |
|---|---|
| ios_base ::boolalpha | 输入和输出bool值,可以为true或false |
| ios_base ::showbase | 对于输出,使用C++基数前缀(0,0x) |
| ios_base ::showpoint | 显示末尾的小数点 |
| ios_base ::uppercase | 对于16进制输出,使用大写字母,E表示法 |
| ios_base ::showpos | 在正数前面加上+ |
要恢复以前的设置,可以这样做:
cout.setf(old, ios::adjustfield);
22.3 cin 输入
char ch;
cin.get(ch);//cin会丢弃空格,但是get不会,直到读取到enter
char line[50];
cin.get(line, 50);
cin.getline(temp,80);
get()和getline()之间的主要区别在于,get()将换行符留在输入流中,这样接下来的输入操作首先看到的将是换行符,而getline()抽取并丢弃输入流中的换行符。
| 方 法 | 行 为 |
|---|---|
| getline(char *, int) | 如果没有读取任何字符(但换行符被视为读取了一个字符),则设置failbit 如果读取了最大数目的字符,且行中还有其他字符,则设置failbit |
| get(char *, int) | 如果没有读取任何字符,则设置failbit |
22.4 文件的输入与输出
头文件fstream,包括用于文件输入的ifstream类和用于文件输出的ofstream类
程序写入文件
1.创建一个ofstream对象来管理输出流;
2.将该对象与特定的文件关联起来;
3.以使用cout的方式使用该对象,唯一的区别是输出将进入文件,而不是屏幕。
#include <fstream>
ofstream fout; // fout与cout使用方法一样、
fout.open("jar.txt"); //打开一个文件,没有该文件则会创建文件、
fout << "Dull Data";//打开文件输出会覆盖掉原来文件中的所有内容
读取文件的要求与写入文件相似:
- 创建一个ifstream对象来管理输入流;
- 将该对象与特定的文件关联起来;
- 以使用cin的方式使用该对象。
ifstream fin;
fin.open("jellyjar.txt");
if(!fin)
{
cout<<"open file failed"
}
if(!fin.is_open())
{
//检查文件是否正确打开,一般用这种方式
}
显示的关闭流与文件之间的连接
fout.close();
fin.close();
打开多个
ifstream fin; // create stream using default constructor
fin.open("fat.txt"); // associate stream with fat.txt file
... // do stuff
fin.close(); // terminate association with fat.txt
fin.clear(); // reset fin (may not be needed)
fin.open("rat.txt"); // associate stream with rat.txt file
...
fin.close();
命令行处理技术
int main(int argc, char *argv[])
argc为命令行中的参数个数,其中包括命令名本身。argv为命令行中的命令,比如在命令行中输入
wc report1 report2 report3
则argv[0]表示”wc" argv[1]表示“report1
读取、写入文件的模式
| 常 量 | 含 义 |
|---|---|
| ios_base::in | 打开文件,以便读取 |
| ios_base::out | 打开文件,以便写入 |
| ios_base::ate | 打开文件,并移到文件尾 |
| ios_base::app | 追加到文件尾 |
| ios_base::trunc | 如果文件存在,则截短文件 |
| ios_base::binary | 二进制文件 |
ofstream fout("bagels", ios_base::out | ios_base::app);//保留源文件内容,并在后面继续添加内容
| C++模式 | C模式 | 含 义 |
|---|---|---|
| ios_base :: in | “r” | 打开以读取 |
| ios_base :: out | “w” | 等价于ios_base :: out | ios_base :: trunc |
| ios_base :: out | ios_base :: trunc | “w” | 打开以写入,如果已经存在,则截短文件 |
| ios_base :: out | ios_base :: app | “a” | 打开以写入,只追加 |
| ios_base :: in | ios_base :: out | “r+” | 打开以读写,在文件允许的位置写入 |
| ios_base :: in | ios_base :: out | ios_base::trunc | “w+” | 打开以读写,如果已经存在,则首先截短文件 |
| c++mode | ios_base :: binary | “cmodeb” | 以C++mode(或相应的cmode)和二进制模式打开;例如,ios_base :: in | ios_base :: binary成为“rb” |
| c++mode | ios_base :: ate | “cmode” | 以指定的模式打开,并移到文件尾。C使用一个独立的函数调用,而不是模式编码。例如,ios_base :: in | ios_base :: ate被转换为“r”模式和C函数调用fseek(file, 0, SEEK_END) |
随机存取文件
同时使用in模式和out模式将得到读/写模式
finout.open(file,ios_base::in | ios_base::out);
需要一种在文件中移动的方式。fstream类为此继承了两个方法:seekg()和seekp(),前者将输入指针移到指定的文件位置,后者将输出指针移到指定的文件位置
fin.seekg(30, ios_base::beg); // 移动到开头后面的30个字节处
fin.seekg(-1, ios_base::cur); // 移动到当前位置的前一个字节处
fin.seekg(0, ios_base::end); // 移动到文件末尾
fin.seekg(112);//文件指针指向第112个字节
使用临时文件
常量L_tmpnam和TMP_MAX(二者都是在cstdio中定义的)限制了文件名包含的字符数以及在确保当前目录中不生成重复文件名的情况下tmpnam()可被调用的最多次数
#include <cstdio>//包含头文件
#include <iostream>
int main()
{
using namespace std;
cout << "This system can generate up to " << TMP_MAX
<< " temporary names of up to " << L_tmpnam
<< " characters.\n";
char pszName[ L_tmpnam ] = {'\0'};
cout << "Here are ten names:\n";
for( int i=0; 10 > i; i++ )
{
tmpnam( pszName );//随机生成文件名
cout << pszName << endl;
}
return 0;
}















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









