







 本文探讨了Linux内核中的hlist_head/hlist_node数据结构,它们用于处理散列冲突。通过节省一个指向数组元素的指针,减少了内存消耗。文章分析了hlist_node的next指针设计,解释了其在链表操作中的作用,特别是在插入和删除节点时保持一致性的重要性。
本文探讨了Linux内核中的hlist_head/hlist_node数据结构,它们用于处理散列冲突。通过节省一个指向数组元素的指针,减少了内存消耗。文章分析了hlist_node的next指针设计,解释了其在链表操作中的作用,特别是在插入和删除节点时保持一致性的重要性。
Linux内核提供的数据结构里,除了常见的list,还有他的另一个孪生兄弟——hlist(由struct hlist_head和struct hlist_node构成)。hlist结构如下:
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
就像hlist名字中h所预示的那样,他主要用于hash_table。在典型的hash_table,我们用链表处理散列冲突(colision)。此时,我们都是从数组的某一个位桶(slot)出发,沿着链表搜索,从而获取目标元素。
在这种情况下,很难想象会有这么一种需求——我们需要重新回到散列数组的位桶中,也就是说,我们不需要一个用于指向数组元素的指针。
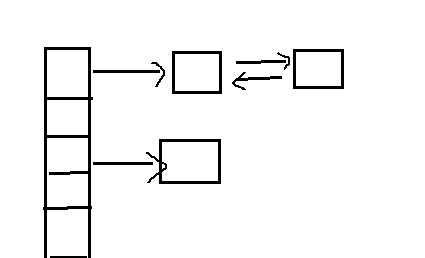
这样,我们就省下了一个指针!或者说,省下了n * sizeof(void *)个字节(这里的n是散列数组的长度)。以Linux2.6.11中的pid_hash[]、32位系统为例,共有4张表,每张表2048个slot,省下了
2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4443
4443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









