






AEC3是WebRTC中基于子带滤波器实现的的一种回声消除算法,目标是在语音通话过程中消除远端信号(扬声器输出)在近端信号(麦克风输入)中的回声,从而提高通话质量和清晰度。为了实现这一目标,AEC3需要估计远端信号与近端信号之间的延时并对齐两个信号。这里将介绍AEC3中的延时估计和对齐算法的原理和具体步骤。
原理
AEC3中的时延估计算法是使用计算滤波器能量最大块来作为延迟估计值,它是当滤波器收敛到一定程度时,计算所有滤波器系数的能量,取峰值的系数(tap)对应的delay就是对齐需要的delay,之后使得远端信号与近端信号在时域上达到最佳对齐。为了实现这一目标,AEC3采用了匹配滤波器(Matched Filter)技术。
匹配滤波器通过计算两个信号之间的互相关函数来估计信号之间的延时。互相关函数的峰值对应的延时值即为最佳延时估计值。在AEC3中,使用了步长为0.7的5个时域的NLMS滤波器来实现匹配滤波器。
这5个滤波器分别处理不同的延时范围,每个滤波器默认为32个块,每个块有16个样点,总计有32*16=512个样点。5个滤波器理论上共有512*5=2560个点,但实际上5个滤波器在时域上互相重叠8块(即输入的信号在时间上存在重叠),所以实际上5个滤波器可以估计2560-8*16*4(重叠一共有4块区域)=2048个样点。由于输入信号是经过分频后(低频0~16kHz)再经过4倍下采样的信号(实际采样率为4000Hz),所以实际最多能估计的延迟为2048/4000=512ms。
NLMS算法
NLMS(Normalized Least Mean Squares)算法是一种自适应滤波算法,用于估计信号的滤波器系数。它可以根据输入信号和期望输出信号之间的误差来更新滤波器系数,从而实现滤波器的自适应调整。NLMS算法的步骤如下:
-
初始化滤波器系数
在NLMS算法开始运行之前,需要对滤波器系数进行初始化。通常情况下,可以将滤波器系数初始化为0或者一个较小的随机值。
-
输入信号和期望输出信号
在每个时间步骤,NLMS算法会接收到一个输入信号x(n)和一个期望输出信号d(n)。其中,x(n)是输入信号的样本值,d(n)是期望输出信号的样本值。
-
计算滤波器的输出信号
根据当前的滤波器系数,NLMS算法可以计算出滤波器的输出信号y(n)。滤波器的输出信号是输入信号x(n)和滤波器系数w(n)的加权和,即:y(n) = w(n) * x(n)。
-
计算误差信号
将期望输出信号d(n)和滤波器的输出信号y(n)相减,可以得到误差信号e(n)。误差信号表示期望输出信号与实际输出信号之间的差异,即:e(n) = d(n) - y(n)。
-
更新滤波器系数
NLMS算法的核心是根据误差信号e(n)来更新滤波器系数w(n)。具体地,NLMS算法会根据以下公式来更新滤波器系数:
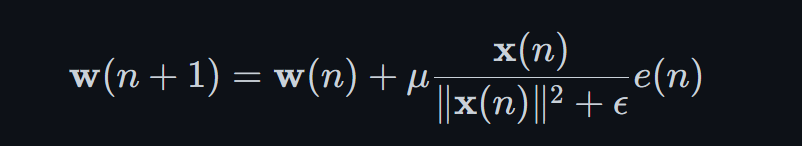
其中,μ是步长参数,用于控制滤波器系数的更新速度;δ是一个小的正数,用于避免分母为0的情况;||x(n)||表示输入信号x(n)的能量。
-
归一化滤波器系数
为了避免滤波器系数过大或过小,NLMS算法会对滤波器系数进行归一化处理。具体地,NLMS算法会将滤波器系数除以滤波器系数的模长,从而得到归一化的滤波器系数。
-
重复迭代
NLMS算法会不断地接收输入信号和期望输出信号,并根据误差信号来更新滤波器系数。重复执行第二步至第六步,直到滤波器系数收敛或达到预设的迭代次数。
综上,NLMS算法是一种自适应滤波算法,可以根据输入信号和期望输出信号之间的误差来更新滤波器系数,从而实现滤波器的自适应调整。它可以有效地估计信号的滤波器系数,并实现自适应滤波。NLMS算法的优点是收敛速度快,对于非平稳信号和非线性系统也有较好的适应性。但是,它也存在一些缺点,如对于高动态范围信号和噪声较大的情况,容易出现数值不稳定和收敛慢的问题。
具体步骤
延时估计
在modules/audio_processing/aec3/render_delay_controller.cc的GetDelay()中实现具体的时延估计。主要包括两个部分,计算时延的EchoPathDelayEstimator类下的EstimateDelay()函数和ComputeBufferDelay()。
EstimateDelay()
该函数的输入参数如下:
| 参数名 | 类型 | 说明 |
| render_buffer | const DownsampledRenderBuffer& | 用于存储进行了降采样(采样率4000Hz)的参考信号 |
| capture | const Block& | 用于存储输入的采集信号 |
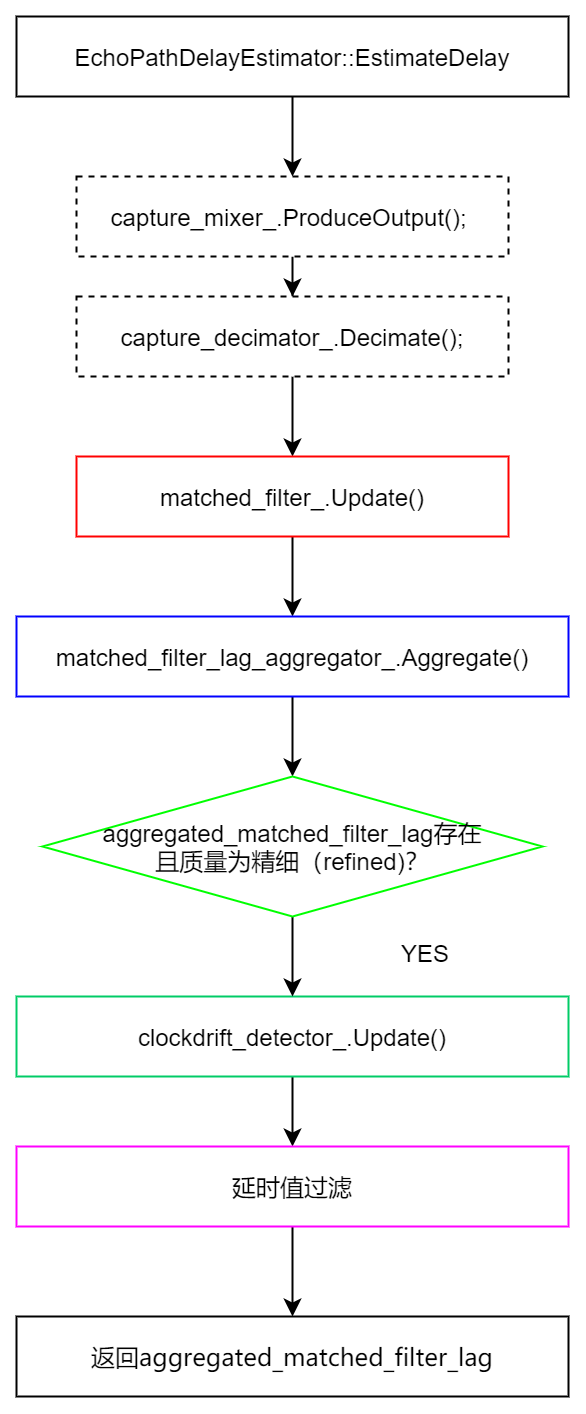
- 预处理
预处理部分主要是对输入的近端和远端信号进行下采样和混合。这里将输入信号的采样率从48kHz降至4kHz。这个步骤可以减少计算量,并使得算法更加稳定。
capture_mixer_.ProduceOutput(capture, downmixed_capture);
capture_decimator_.Decimate(downmixed_capture, downsampled_capture);- 匹配滤波器更新
匹配滤波器的更新是基于NLMS算法的。在这一步中,首先检查近端信号是否不超过预设阈值(如32000或-32000),同时检查远端信号能量是否大于某个阈值。如果满足这两个条件,则进行滤波器的更新。
滤波器更新的核心函数是MatchedFilterCore(),它实现了NLMS滤波器的更新公式。这个公式的目标是使得误差最小,即使采集信号和经过滤波之后的参考信号之间的误差最小。
若近端语音出现爆音,则对齐不进行更新,即该场景下回声消除效果可能一般;另外,远端能量如果小于阈值,则对齐也不进行更新,即实际场景中例如耳机残留回声可能也会带来效果的影响。
- 计算每个滤波器的延时值
为了找到最佳的延时估计值,需要通过MatchedFilter::Update()计算每个滤波器的延时值,并选择误差能量最小的滤波器系数作为最佳匹配滤波器。这个过程中,首先计算滤波器的输出信号与期望信号之间的误差能量,然后找到使误差能量最小的滤波器系数(tap)对应的延时值。
- 挑选最佳延时估计值
在MatchedFilterLagAggregator::Aggregate()函数中,需要从5个滤波器中挑选出最佳的延时估计值。为了实现这个目标,首先计算每个滤波器的可信度。可信度主要包括以下三个方面:
- 延时值落在 2~(滤波器长度-10)范围内;
- 误差能量小于近端能量的0.2倍;
- 滤波器是否更新。
在这之后,对于每个滤波器,计算其延时估计值和误差信号的能量。如果当前滤波器的延时估计可信且误差信号的能量小于之前的最小误差信号能量,那么就更新最小误差信号能量和最佳延时估计值的索引。之后,从5个滤波器中选取可信度为真且误差信号能量最小的滤波器作为最佳延时估计值。通过直方图(Histogram)存储和统计每个滤波器的可信度。每次更新时,直方图会根据当前可信度值更新,以便在一定时间窗口内跟踪最佳延时估计值的变化,统计过去的延时值。在一定时间窗口内,从直方图中选取可信度最高的延时估计值作为最终的延时估计值。
- 检测延时估计值的稳定性
在确定了最佳延时估计值之后,还需要检查这个值是否稳定。这个检查过程是基于直方图的。首先计算直方图中的峰值(Peak),然后判断峰值是否大于阈值,如果大于阈值(20),则认为延时估计值是稳定的。
- 时钟漂移检测
质量好的延时值会用来做时钟漂移检测:
void ClockdriftDetector::Update(int delay_estimate)
时钟漂移是指时钟的频率偏离其标准频率的程度。在数字信号处理中,时钟漂移通常指的是采样时钟的频率偏移,即采样时钟的实际频率与其标准频率之间的差异。由于时钟漂移的存在,采样时钟的实际频率可能会略微偏离其标准频率,导致采样时刻的误差,从而影响数字信号的处理和重构。
在该函数中,首先会检查延时估计值是否与历史延时值相同。如果延时估计值与历史延时值相同,则会增加稳定性计数器,如果稳定性计数器超过了7500个块(约30秒),则将时钟漂移级别设置为“无”(Level::kNone)。
接着,会计算当前延时估计值与历史延时值之间的差值,并根据差值的模式来判断时钟漂移的情况。具体来说,如果差值的模式符合正向时钟漂移的模式或负向时钟漂移的模式,则将时钟漂移级别设置为“已验证”(Level::kVerified);如果差值的模式符合可能的正向时钟漂移的模式或可能的负向时钟漂移的模式,并且时钟漂移级别为“无”,则将时钟漂移级别设置为“可能”(Level::kProbable)。
最后,会将延时估计值存储到历史延时值数组中,并将历史延时值数组向前移动一位。
在AEC3中,只对时钟漂移的级别进行了检测,而并没有进行相关处理。
ComputeBufferDelay()
这个函数的作用是计算计算音频缓冲区的延迟估计值,以便在音频处理中进行延迟补偿。
函数的输入参数包括:
| 参数名 | 类型 | 说明 |
|---|---|---|
| current_delay | const absl::optional<DelayEstimate>& | 当前的延迟估计 |
| hysteresis_limit_blocks | int | 延迟估计的滞后限制 |
| estimated_delay | DelayEstimate | 期望的延迟估 |
函数首先根据期望的延迟估计值计算出所需的缓冲区延迟增加量,即将期望的延迟估计值转换为块数。然后,根据滞后限制块数和当前的延迟估计值,对计算出的缓冲区延迟增加量进行调整,以避免缓冲区延迟的突然变化。具体来说,如果新的缓冲区延迟增加量大于当前的延迟估计值,并且小于等于当前延迟估计值加上滞后限制块数,则将新的缓冲区延迟增加量设置为当前的延迟估计值,以避免缓冲区延迟的突然增加。最后,函数将计算出的缓冲区延迟增加量转换为延迟估计值,并返回新的延迟估计值。
延时对齐
调整音频缓冲区主要在render_delay_buffer.cc文件中的RenderDelayBuffer类中实现。RenderDelayBuffer类负责处理渲染音频的延迟缓冲。在这个类中,Insert()函数用于将新的渲染音频帧插入缓冲区,而GetRenderBuffer()函数则根据延迟来从缓冲区中获取对齐的渲染音频数据。这样,通过调整缓冲区中的音频数据,可以实现参考信号和捕获信号的对齐。
AEC3提测代码:
在学习过程中,我将WebRTC中的AEC3部分单独抠出进行了相关测试和验证:Jeremiahandsome/AEC3Demo (github.com)。WebRTC版本:

参考链接:
AEC个人学习串讲之AEC3:时延对齐、线性处理、非线性处理 - 小奥的学习笔记 (yushuai.xyz)
WEBRTC AEC3算法原理_myangel13141的博客-CSDN博客















 1079
1079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









