







从 0 开始写一个操作系统
作者:解琛
时间:2020 年 8 月 29 日
一、准备知识
写一个操作系统难吗?别被现在上百万行的 Linux 和 Windows 操作系统吓倒。
当年 Thompson 乘他老婆带着小孩度假留他一人在家时,写了 UNIX。
当年 Linus 还是一个 21 岁大学生时完成了 Linux 雏形。
MIT 的 Frans Kaashoek 等在 2006 年参考 PDP-11 上的 UNIX Version 6 写了一个可在 X86 上跑的操作系统 xv6(基于MIT License),用于学生学习操作系统。
我们可以站在他们的肩膀上,基于 xv6 的设计,尝试从 0 开始完成一个操作系统 ucore,包含虚存管理、进程管理、处理器调度、同步互斥、进程间通信、文件系统等主要内核功能,总的内核代码量(C + asm)不会超过5K行。
ucore 的运行环境可以是真实的 X86 计算机,不过考虑到调试和开发的方便,我们可采用 X86 硬件模拟器,比如 QEMU、BOCHS、VirtualBox、VMware Player 等。
ucore 的开发环境主要是 GCC 中的 gcc、gas、ld 和 MAKE 等工具,也可采用集成了这些工具的 IDE 开发环境 Eclipse-CDT 等。
在分析源代码上,可以采用 Scitools 提供的 understand 软件(跨平台),windows 环境上的 source insight 软件,或者基于 emacs + ctags,vim + ctags 等,都可以比较方便在在一堆文件中查找变量、函数定义、调用/访问关系等。
软件开发的版本管理可以采用 GIT、SVN 等。
比较文件和目录的不同可发现不同实验中的差异性和进行文件合并操作,可使用 meld、kdiff3、UltraCompare 等软件。
调试(deubg)实验有助于发现设计中的错误,可采用 gdb(配合qemu)等调试工具软件。
并可整个实验的运行环境和开发环境既可以在 Linux 或 Windows 中使用。推荐使用 Linux 环境。
1.1 实现方案

通过如下步骤来一步步实现这个操作系统。
- 启动操作系统的 bootloader,用于了解操作系统启动前的状态和要做的准备工作,了解运行操作系统的硬件支持,操作系统如何加载到内存中,理解两类中断————“外设中断”,“陷阱中断”等;
- 物理内存管理子系统,用于理解 x86 分段 / 分页模式,了解操作系统如何管理物理内存;
- 虚拟内存管理子系统,通过页表机制和换入换出(swap)机制,以及中断-“故障中断”、缺页故障处理等,实现基于页的内存替换算法;
- 内核线程子系统,用于了解如何创建相对与用户进程更加简单的内核态线程,如果对内核线程进行动态管理等;
- 用户进程管理子系统,用于了解用户态进程创建、执行、切换和结束的动态管理过程,了解在用户态通过系统调用得到内核态的内核服务的过程;
- 处理器调度子系统,用于理解操作系统的调度过程和调度算法;
- 同步互斥与进程间通信子系统,了解进程间如何进行信息交换和共享,并了解同步互斥的具体实现以及对系统性能的影响,研究死锁产生的原因,以及如何避免死锁;
- 文件系统,了解文件系统的具体实现,与进程管理等的关系,了解缓存对操作系统 IO 访问的性能改进,了解虚拟文件系统(VFS)、buffer cache和disk driver之间的关系。
1.2 gcc
我的 Linux 开发环境如下。
xiechen@xiechen-Ubuntu:~$ uname -a
Linux xiechen-Ubuntu 5.4.0-42-generic #46~18.04.1-Ubuntu SMP Fri Jul 10 07:21:24 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
在 Ubuntu Linux 中的 C 语言编程主要基于 GNU C 的语法,通过 gcc 来编译并生成最终执行文件。GNU 汇编(assembler)采用的是 AT&T 汇编格式,Microsoft 汇编采用 Intel 格式。
使用下面的指令安装 gcc 编译环境。
sudo apt-get install build-essential
gcc 编译时,添加 -Wall 开启编译器几乎所有常用的警告。
1.2.1 AT&T 汇编基本语法
Ucore 中用到的是 AT&T 格式的汇编,与 Intel 格式的汇编有一些不同。二者语法上主要有以下几个不同:
| 不同点 | AT&T | Intel |
|---|---|---|
| 寄存器命名原则 | %eax | eax |
| 源/目的操作数顺序 | movl %eax, %ebx | mov ebx, eax |
| 常数/立即数的格式 | movl $_value, %ebx | mov eax, _value |
| 把 value 的地址放入 eax 寄存器 | movl $0xd00d, %ebx | mov ebx, 0xd00d |
| 操作数长度标识 | movw %ax, %bx | mov bx, ax |
| 寻址方式 | immed32(basepointer, indexpointer, indexscale) | [basepointer + indexpointer × indexscale + imm32) |
如果操作系统工作于保护模式下,用的是 32 位线性地址,所以在计算地址时不用考虑 segment:offset 的问题。上式中的地址应为:
imm32 + basepointer + indexpointer × indexscale
1.2.2 GCC 基本内联汇编
GCC 提供了两类内联汇编语句(inline asm statements)。
- 基本内联汇编语句(basic inline asm statement);
- 扩展内联汇编语句(extended inline asm statement)。
GCC基本内联汇编很简单,一般是按照下面的格式。
asm("statements");
“asm” 和 “__asm__” 的含义是完全一样的。如果有多行汇编,则每一行都要加上 “\n\t”。
在每条命令的 结束加这两个符号,是为了让 gcc 把内联汇编代码翻译成一般的汇编代码时能够保证换行和留有一定的空格。
对于基本 asm 语句,GCC 编译出来的汇编代码就是双引号里的内容。
实际上 gcc 在处理汇编时,是要把 asm(…) 的内容"打印"到汇编文件中,所以格式控制字符是必要的。
asm("movl %eax, %ebx");
asm("xorl %ebx, %edx");
asm("movl $0, _boo);
在上面的例子中,由于我们在内联汇编中改变了 edx 和 ebx 的值,但是由于 gcc 的特殊的处理方法,即先形成汇编文件,再交给 GAS 去汇编,所以 GAS 并不知道我们已经改变了 edx和 ebx 的值。
如果程序的上下文需要 edx 或 ebx 作其他内存单元或变量的暂存,就会产生没有预料的多次赋值,引起严重的后果。
对于变量 _boo 也存在一样的问题。为了解决这个问题,就要用到扩展 GCC 内联汇编语法。
1.2.3 GCC 拓展内联汇编
#define read_cr0() ({ \
unsigned int __dummy; \
__asm__( \
"movl %%cr0,%0\n\t" \
:"=r" (__dummy)); \
__dummy; \
})
GCC扩展内联汇编的基本格式如下。
asm [volatile] ( Assembler Template
: Output Operands
[ : Input Operands
[ : Clobbers ] ])
- __asm__ 表示汇编代码的开始;
- 其后可以跟 __volatile__(这是可选项),其含义是避免 “asm” 指令被删除、移动或组合,在执行代码时,如果不希望汇编语句被 gcc 优化而改变位置,就需要在 asm 符号后添加 volatile 关键词;
- 括弧中的内容是具体的内联汇编指令代码;
- “” 为汇编指令部分;
- 数字前加前缀 “%“,如 %1,%2 等表示使用寄存器的样板操作数,可以使用的操作数总数取决于具体CPU中通用寄存器的数量;
- 由于这些样板操作数的前缀使用了 ”%“,因此,在用到具体的寄存器时就在前面加两个 “%”,如 %%cr0;
- 输出部分(output operand list),用以规定对输出变量(目标操作数)如何与寄存器结合的约束(constraint),输出部分可以有多个约束,互相以逗号分开;
- 每个约束以“=”开头,接着用一个字母来表示操作数的类型,然后是关于变量结合的约束。
表示约束条件的字母很多,下表给出几个主要的约束字母及其含义。
| 字母 | 含义 |
|---|---|
| m, v, o | 内存单元 |
| R | 任何通用寄存器 |
| Q | 寄存器eax, ebx, ecx,edx之一 |
| I, h | 直接操作数 |
| E, F | 浮点数 |
| G | 任意 |
| a, b, c, d | 寄存器eax/ax/al, ebx/bx/bl, ecx/cx/cl或edx/dx/dl |
| S, D | 寄存器esi或edi |
| I | 常数(0~31) |
输入部分(input operand list):输入部分与输出部分相似,但没有“=”。
如果输入部分一个操作数所要求使用的寄存器,与前面输出部分某个约束所要求的是同一个寄存器,那就把对应操作数的编号(如“1”,“2”等)放在约束条件中。
修改部分(clobber list,也称乱码列表):这部分常常以“memory”为约束条件,以表示操作完成后内存中的内容已有改变,如果原来某个寄存器的内容来自内存,那么现在内存中这个单元的内容已经改变。
乱码列表通知编译器,有些寄存器或内存因内联汇编块造成乱码,可隐式地破坏了条件寄存器的某些位(字段)。
指令部分为必选项,而输入部分、输出部分及修改部分为可选项,当输入部分存在,而输出部分不存在时,分号“:“要保留,当“memory”存在时,三个分号都要保留,例如:
#define __cli() __asm__ __volatile__("cli": : :"memory")
1.2.4 案例
int count=1;
int value=1;
int buf[10];
void main()
{
asm(
"cld nt"
"rep nt"
"stosl"
:
: "c" (count), "a" (value) , "D" (buf[0])
: "%ecx","%edi"
);
}
翻译之后的汇编代码为:
movl count,%ecx
movl value,%eax
movl buf,%edi
#APP
cld
rep
stosl
#NO_APP
cld, rep, stos 这几条语句的功能是向 buf 中写上 count 个 value 值。
冒号后的语句指明输入,输出和被改变的寄存器。
通过冒号以后的语句,编译器就知道你的指令需要和改变哪些寄存器,从而可以优化寄存器的分配。
其中符号 “c”(count) 指示要把 count 的值放入 ecx 寄存器。
| 值 | 意义 |
|---|---|
| a | eax |
| b | ebx |
| c | ecx |
| d | edx |
| S | esi |
| D | edi |
| I | 常数值,(0 - 31) |
| q, r | 动态分配的寄存器 |
| g | eax,ebx,ecx,edx或内存变量 |
| A | 把eax和edx合成一个64位的寄存器(use long longs) |
也可以让 gcc 自己选择合适的寄存器。如下面的例子:
asm("leal (%1,%1,4),%0"
: "=r" (x)
: "0" (x)
);
翻译后的汇编代码为:
movl x,%eax
#APP
leal (%eax,%eax,4),%eax
#NO_APP
movl %eax,x
- 使用 q 指示编译器从 eax, ebx, ecx, edx 分配寄存器。 使用 r 指示编译器从 eax, ebx, ecx, edx, esi, edi 分配寄存器;
- 不必把编译器分配的寄存器放入改变的寄存器列表,因为寄存器已经记住了它们;
- "="是标示输出寄存器,必须这样用;
- 数字 %n 的用法:数字表示的寄存器是按照出现和从左到右的顺序映射到用 “r” 或 “q” 请求的寄存器.如果要重用 “r” 或 “q” 请求的寄存器的话,就可以使用它们;
- 如果强制使用固定的寄存器的话,如不用%1,而用ebx,则:
asm("leal (%%ebx,%%ebx,4),%0"
: "=r" (x)
: "0" (x)
);
1.3 makefile
见我的另一篇文章:MakeFile 入门及应用
1.4 gdb
在可以使用 gdb 调试程序之前,必须使用 -g 或 –ggdb 编译选项编译源文件。
可以使用 layout src 命令,或者按 Ctrl-X 再按 A,就会出现一个窗口可以查看源代码。也可以用使用 -tui 参数,这样进入 gdb 里面后就能直接打开代码查看窗口。
| 指令名称 | 说明 |
|---|---|
| info win | 显示窗口的大小 |
| layout next | 切换到下一个布局模式 |
| layout prev | 切换到上一个布局模式 |
| layout src | 只显示源代码 |
| layout asm | 只显示汇编代码 |
| layout split | 显示源代码和汇编代码 |
| layout regs | 增加寄存器内容显示 |
| focus cmd/src/asm/regs/next/prev | 切换当前窗口 |
| refresh | 刷新所有窗口 |
| tui reg next | 显示下一组寄存器 |
| tui reg system | 显示系统寄存器 |
| update | 更新源代码窗口和当前执行点 |
| winheight name +/- line | 调整name窗口的高度 |
| tabset nchar | 设置tab为nchar个字符 |
具体使用方法见我的另两篇总结文章:MX Linux
1.5 QEMU
sudo apt install qemu-system
即将使用的命令有:
qemu -hda ucore.img -parallel stdio # 让ucore在qemu模拟的x86硬件环境中执行;
qemu -S -s -hda ucore.img -monitor stdio # 用于与gdb配合进行源码调试;
1.6 gdb 和 qemu 联调
为了与 qemu 配合进行源代码级别的调试,需要先让 qemu 进入等待 gdb 调试器的接入并且还不能让 qemu 中的 CPU 执行,因此启动 qemu 的时候,我们需要使用参数 -S –s 这两个参数来做到这一点。
在使用了前面提到的参数启动 qemu 之后,qemu 中的 CPU 并不会马上开始执行,这时我们启动 gdb,然后在 gdb 命令行界面下,使用下面的命令连接到 qemu。
target remote 127.0.0.1:1234
然后输入 c (也就是continue)命令之后,qemu 会继续执行下去,但是 gdb 由于不知道任何符号信息,并且也没有下断点,是不能进行源码级的调试的。为了让 gdb 获知符号信息,需要指定调试目标文件,gdb 中使用 file 命令。
file ./bin/kernel
之后 gdb 就会载入这个文件中的符号信息了。
让 gdb 在启动时执行脚本中命令,使用下面的命令启动gdb:
gdb -x tools/gdbinit
为了能够让 gdb 识别变量的符号,我们必须给 gdb 载入符号表等信息。
在进行 gdb 本地应用程序调试的时候,因为在指定了执行文件时就已经加载了文件中包含的调试信息,因此不用再使用 gdb 命令专门加载了。
但是在使用 qemu 进行远程调试的时候,我们必须手动加载符号表,也就是在 gdb 中用 file 命令。
这样加载调试信息都是按照 elf 文件中制定的虚拟地址进行加载的,这在静态连接的代码中没有任何问题。但是在调试含有动态链接库的代码时,动态链接库的 ELF 执行文件头中指定的加载虚拟地址都是 0,这个地址实际上是不正确的。
从操作系统角度来看,用户态的动态链接库的加载地址都是由操作系统动态分配的,没有一个固定值。
然后操作系统再把动态链接库加载到这个地址,并由用户态的库链接器(linker)把动态链接库中的地址信息重新设置,自此动态链接库才可正常运行。
由于分配地址的动态性,gdb 并不知道这个分配的地址是多少,因此当我们在对这样动态链接的代码进行调试的时候,需要手动要求 gdb 将调试信息加载到指定地址。
我们要求 gdb 将 linker 加载到 0x6fee6180 这个地址上:
add-symbol-file android_test/system/bin/linker 0x6fee6180
这样的命令默认是将代码段 (.data) 段的调试信息加载到 0x6fee6180 上,当然,你也可以通过 -s 这个参数来指定,比如:
add-symbol-file android_test/system/bin/linker –s .text 0x6fee6180
这样,在执行到 linker 中代码时 gdb 就能够显示出正确的代码和调试信息出来。
这个方法在操作系统中调试动态链接器时特别有用。
1.7 设定目标架构
在调试的时候,我们也许需要调试不是 i386 保护模式的代码,比如 8086 实模式的代码,我们需要设定当前使用的架构:
set arch i8086
1.8 Intel 80386
1.8.1 运行模式
一般 CPU 只有一种运行模式,能够支持多个程序在各自独立的内存空间中并发执行,且有用户特权级和内核特权级的区分,让一般应用不能破坏操作系统内核和执行特权指令。
80386 处理器有四种运行模式:
- 实模式;
- 保护模式;
- SMM模式;
- 虚拟8086模式。
这里对涉及 ucore 的实模式、保护模式做简要分析。
1.8.1.1 实模式
这是个人计算机早期的 8086 处理器采用的一种简单运行模式,当时微软的 MS-DOS 操作系统主要就是运行在 8086 的实模式下。
80386 加电启动后处于实模式运行状态,在这种状态下软件可访问的物理内存空间不能超过 1MB,且无法发挥 Intel 80386 以上级别的 32 位 CPU 的 4GB 内存管理能力。
实模式将整个物理内存看成分段的区域,程序代码和数据位于不同区域,操作系统和用户程序并没有区别对待,而且每一个指针都是指向实际的物理地址。
这样用户程序的一个指针如果指向了操作系统区域或其他用户程序区域,并修改了内容,那么其后果就很可能是灾难性的。
1.8.1.2 保护模式
保护模式的一个主要目标是确保应用程序无法对操作系统进行破坏。
实际上,80386 就是通过在实模式下初始化控制寄存器(如 GDTR,LDTR,IDTR 与 TR 等管理寄存器)以及页表,然后再通过设置 CR0 寄存器使其中的保护模式使能位置位,从而进入到 80386 的保护模式。
当 80386 工作在保护模式下的时候,其所有的 32 根地址线都可供寻址,物理寻址空间高达 4GB。
在保护模式下,支持内存分页机制,提供了对虚拟内存的良好支持。
保护模式下 80386 支持多任务,还支持优先级机制,不同的程序可以运行在不同的特权级上。
特权级一共分 0~3 四个级别,操作系统运行在最高的特权级 0 上,应用程序则运行在比较低的级别上;配合良好的检查机制后,既可以在任务间实现数据的安全共享也可以很好地隔离各个任务。
1.8.2 内存架构
地址是访问内存空间的索引。
一般而言,内存地址有两个。
- 一个是CPU通过总线访问物理内存用到的物理地址;
- 一个是我们编写的应用程序所用到的逻辑地址(也有人称为虚拟地址)。
80386 是 32 位的处理器,即可以寻址的物理内存地址空间为 2 3 2 = 4 G 2^32=4G 232=4G 字节。
我们将用到三个地址空间的概念。
- 物理地址;
- 线性地址;
- 逻辑地址。
物理内存地址空间是处理器提交到总线上用于访问计算机系统中的内存和外设的最终地址。一个计算机系统中只有一个物理地址空间。
线性地址空间是 80386 处理器通过段(Segment)机制控制下的形成的地址空间。在操作系统的管理下,每个运行的应用程序有相对独立的一个或多个内存空间段,每个段有各自的起始地址和长度属性,大小不固定,这样可让多个运行的应用程序之间相互隔离,实现对地址空间的保护。
在操作系统完成对 80386 处理器段机制的初始化和配置(主要是需要操作系统通过特定的指令和操作建立全局描述符表,完成虚拟地址与线性地址的映射关系)后,80386 处理器的段管理功能单元负责把虚拟地址转换成线性地址
相对而言,段机制对大量应用程序分散地使用大内存的支持能力较弱,所以 Intel 公司又加入了页机制。
每个页的大小是固定的(一般为 4KB),也可完成对内存单元的安全保护,隔离,且可有效支持大量应用程序分散地使用大内存的情况。
在操作系统完成对80386处理器页机制的初始化和配置(主要是需要操作系统通过特定的指令和操作建立页表,完成虚拟地址与线性地址的映射关系)后,应用程序看到的逻辑地址先被处理器中的段管理功能单元转换为线性地址,然后再通过 80386 处理器中的页管理功能单元把线性地址转换成物理地址。
三种地址的关系如下。
- 分段机制启动、分页机制未启动:逻辑地址 —> 段机制处理 —> 线性地址=物理地址;
- 分段机制和分页机制都启动:逻辑地址 —> 段机制处理 —> 线性地址 —> 页机制处理 —> 物理地址。
1.8.3 寄存器
80386 的寄存器可以分为 8 组:
- 通用寄存器;
- 段寄存器;
- 指令指针寄存器;
- 标志寄存器;
- 系统地址寄存器;
- 控制寄存器;
- 调试寄存器;
- 测试寄存器。
它们的宽度都是 32 位。
1.8.3.1 General Register

EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP 这些寄存器的低 16 位就是 8086 的 AX、BX、CX、DX、SI、DI、SP、BP。
对于 AX、BX、CX、DX 这四个寄存器来讲,可以单独存取它们的高 8 位和低 8 位 (AH、AL、BH、BL、CH、CL、DH、DL)。
| 寄存器 | 说明 |
|---|---|
| EAX | 累加器 |
| EBX | 基址寄存器 |
| ECX | 计数器 |
| EDX | 数据寄存器 |
| ESI | 源地址指针寄存器 |
| EDI | 目的地址指针寄存器 |
| EBP | 基址指针寄存器 |
| ESP | 堆栈指针寄存器 |
1.8.3.2 Segment Register

段寄存器,也称 Segment Selector,段选择符,段选择子。
除了 8086 的 4 个段外(CS、DS、ES、SS),80386 还增加了两个段 FS、GS。
这些段寄存器都是16位的,用于不同属性内存段的寻址。
| 寄存器 | 说明 |
|---|---|
| CS | 代码段(Code Segment) |
| DS | 数据段(Data Segment) |
| ES | 附加数据段(Extra Segment) |
| SS | 堆栈段(Stack Segment) |
| FS | 附加段 |
| GS | 附加段 |
1.8.3.3 Instruction Pointer

指令指针寄存器。
EIP 的低 16 位就是 8086 的 IP,它存储的是下一条要执行指令的内存地址,在分段地址转换中,表示指令的段内偏移地址。
1.8.3.4 Flag Register

标志寄存器。
EFLAGS,和 8086 的 16 位标志寄存器相比,增加了 4 个控制位。
| 寄存器 | 说明 |
|---|---|
| CF(Carry Flag) | 进位标志位; |
| PF(Parity Flag) | 奇偶标志位; |
| AF(Assistant Flag) | 辅助进位标志位; |
| ZF(Zero Flag) | 零标志位; |
| SF(Singal Flag) | 符号标志位; |
| IF(Interrupt Flag) | 中断允许标志位,由CLI,STI两条指令来控制;设置IF位使CPU可识别外部(可屏蔽)中断请求,复位IF位则禁止中断,IF位对不可屏蔽外部中断和故障中断的识别没有任何作用; |
| DF(Direction Flag) | 向量标志位,由CLD,STD两条指令来控制; |
| OF(Overflow Flag) | 溢出标志位; |
| IOPL(I/O Privilege Level) | I/O特权级字段,它的宽度为2位,它指定了I/O指令的特权级。如果当前的特权级别在数值上小于或等于IOPL,那么I/O指令可执行。否则,将发生一个保护性故障中断; |
| NT(Nested Task) | 控制中断返回指令IRET,它宽度为1位。若NT=0,则用堆栈中保存的值恢复EFLAGS,CS和EIP从而实现中断返回;若NT=1,则通过任务切换实现中断返回。在ucore中,设置NT为0。 |
1.9 面向对象
uCore 设计中采用了一定的面向对象编程方法。
uCore 的面向对象编程方法,目前主要是采用了类似 C++ 的接口(interface)概念。
即是让实现细节不同的某类内核子系统(比如物理内存分配器、调度器,文件系统等)有共同的操作方式,这样虽然内存子系统的实现千差万别,但它的访问接口是不变的。
这样不同的内核子系统之间就可以灵活组合在一起,实现风格各异,功能不同的操作系统。
接口在 C 语言中,表现为一组函数指针的集合。放在 C++ 中,即为虚表。
接口设计的难点是如果找出各种内核子系统的共性访问/操作模式,从而可以根据访问模式提取出函数指针列表。
1.10 双向链表
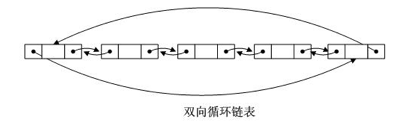
双向循环链表的特点是尾节点的后继指向首节点,且从任意一个节点出发,沿两个方向的任何一个,都能找到链表中的任意一个节点的 data 数据。
这种双向循环链表数据结构的一个潜在问题是,虽然链表的基本操作是一致的,但由于每种特定数据结构的类型不一致,需要为每种特定数据结构类型定义针对这个数据结构的特定链表插入、删除等各种操作,会导致代码冗余。
在 uCore 内核中使用了大量的双向循环链表结构来组织数据,包括空闲内存块列表、内存页链表、进程列表、设备链表、文件系统列表等的数据组织。
其具体实现借鉴了 Linux 内核的双向循环链表实现。
struct list_entry {
struct list_entry *prev, *next;
};
注意 uCore 内核的链表节点 list_entry 没有包含传统的 data 数据域,而是在具体的数据结构中包含链表节点。
以空闲内存块列表为例,空闲块链表的头指针定义为:
typedef struct {
list_entry_t free_list; // the list header
unsigned int nr_free; // of free pages in this free list
} free_area_t;
每一个空闲块链表节点定义为:
struct Page {
atomic_t ref; // page frame's reference counter
……
list_entry_t page_link; // free list link
};
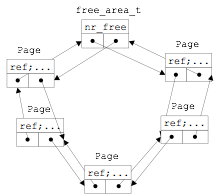
这样以 free_area_t 结构的数据为双向循环链表的链表头指针,以 Page 结构的数据为双向循环链表的链表节点,就可以形成一个完整的双向循环链表。
这种通用的双向循环链表结构避免了为每个特定数据结构类型定义针对这个数据结构的特定链表的麻烦,而可以让所有的特定数据结构共享通用的链表操作函数。
在实现对空闲块链表的管理过程中,就大量使用了通用的链表插入,链表删除等操作函数。
1.10.1 初始化
uCore 只定义了链表节点,并没有专门定义链表头。
list_init 内联函数(inline funciton)如下。
static inline void
list_init(list_entry_t *elm) {
elm->prev = elm->next = elm;
}
当我们调用 list_init(&(free_area.free_list)) 时,就声明一个名为 free_area.free_list 的链表头时,它的 next、prev 指针都初始化为指向自己,这样,我们就有了一个表示空闲内存块链的空链表。
我们可以用头指针的 next 是否指向自己来判断此链表是否为空,而这就是内联函数 list_empty 的实现。
1.10.2 插入
对链表的插入有两种操作,即在表头插入(list_add_after)或在表尾插入(list_add_before)。
因为双向循环链表的链表头的 next、prev 分别指向链表中的第一个和最后一个节点,所以,list_add_after 和 list_add_before 的实现区别并不大。
实际上 uCore 分别用 list_add(elm, listelm, listelm->next) 和 list_add(elm, listelm->prev, listelm) 来实现在表头插入和在表尾插入。
static inline void
__list_add(list_entry_t *elm, list_entry_t *prev, list_entry_t *next) {
prev->next = next->prev = elm;
elm->next = next;
elm->prev = prev;
}
从上述实现可以看出在表头插入是插入在 listelm 之后,即插在链表的最前位置。
而在表尾插入是插入在 listelm->prev 之后,即插在链表的最后位置。
list_add 等于 list_add_after。
1.10.3 删除
当需要删除空闲块链表中的 Page 结构的链表节点时,可调用内联函数 list_del,而 list_del 进一步调用了 __list_del 来完成具体的删除操作。
static inline void
list_del(list_entry_t *listelm) {
__list_del(listelm->prev, listelm->next);
}
static inline void
__list_del(list_entry_t *prev, list_entry_t *next) {
prev->next = next;
next->prev = prev;
}
如果要确保被删除的节点 listelm 不再指向链表中的其他节点,这可以通过调用 list_init 函数来把 listelm 的 prev、next 指针分别自身,即将节点置为空链状态。
这可以通过 list_del_init 函数来完成。
1.10.4 查询
访问链表节点所在的宿主数据结构。
通过上面的描述可知,list_entry_t 通用双向循环链表中仅保存了某特定数据结构中链表节点成员变量的地址,通过这个链表节点成员变量访问到它的所有者(即某特定数据结构的变量),可以使用 Linux 提供的数据结构 XXX 的 le2XXX(le, member) 的宏。
其中 le,即 list entry 的简称,是指向数据结构 XXX 中 list_entry_t 成员变量的指针,也就是存储在双向循环链表中的节点地址值, member 则是 XXX 数据类型中包含的链表节点的成员变量。
我们要遍历访问空闲块链表中所有节点所在的基于 Page 数据结构的变量,则可以采用如下编程方式。
// free_area 是空闲块管理结构,free_area.free_list 是空闲块链表头;
free_area_t free_area;
list_entry_t * le = &free_area.free_list; // le 是空闲块链表头指针;
while((le=list_next(le)) != &free_area.free_list) { // 从第一个节点开始遍历;
struct Page *p = le2page(le, page_link); // 获取节点所在基于 Page 数据结构的变量;
……
}
le2page 宏的使用相当简单。
#define le2page(le, member) \
to_struct((le), struct Page, member)
它的实现用到的 to_struct 宏和 offsetof 宏。
/* Return the offset of 'member' relative to the beginning of a struct type */
#define offsetof(type, member) \
((size_t)(&((type *)0)->member))
/* *
* to_struct - get the struct from a ptr
* @ptr: a struct pointer of member
* @type: the type of the struct this is embedded in
* @member: the name of the member within the struct
* */
#define to_struct(ptr, type, member) \
((type *)((char *)(ptr) - offsetof(type, member)))
这里采用了一个利用 gcc 编译器技术的技巧,即先求得数据结构的成员变量在本宿主数据结构中的偏移量,然后根据成员变量的地址反过来得出属主数据结构的变量的地址。
我们首先来看 offsetof 宏,size_t 最终定义与 CPU 体系结构相关,本实验都采用 Intel X86-32 CPU,故 szie_t 等价于 unsigned int。
((type *)0)->member 是为了求得数据结构的成员变量在本宿主数据结构中的偏移量。
为了达到这个目标,首先将 0 地址强制"转换"为 type 数据结构(比如 struct Page)的指针,再访问到 type 数据结构中的 member 成员(比如 page_link)的地址,即是 type 数据结构中 member 成员相对于数据结构变量的偏移量。
在 offsetof 宏中,这个 member 成员的地址(即 &((type *)0)->member))实际上就是 type 数据结构中 member 成员相对于数据结构变量的偏移量。
对于给定一个结构,offsetof(type,member) 是一个常量,to_struct 宏正是利用这个不变的偏移量来求得链表数据项的变量地址。
接下来再分析一下 to_struct 宏,可以发现 to_struct 宏中用到的ptr变量是链表节点的地址,把它减去 offsetof 宏所获得的数据结构内偏移量,即就得到了包含链表节点的属主数据结构的变量的地址。
1.11 参考文献
pdos
Youtube Unix intro
The UNIX Time-Sharing System, Dennis M. Ritchie and Ken L.Thompson,. Bell System Technical Journal 57, number 6, part 2 (July-August 1978) pages 1905-1930.
The Evolution of the Unix Time-sharing System, Dennis M. Ritchie, 1979.
The C programming language (second edition) by Kernighan and Ritchie. Prentice Hall, Inc., 1988. ISBN 0-13-110362-8, 1998.
How to make an Operating System
xv6 book 中文
自己动手写操作系统于渊 著,电子工业出版社,2005
Linux-0.11内核完全注释 赵炯,2009
oldlinux
osdev.org
6.828: Operating Systems Engineering - in MIT
CS-537: Introduction to Operating Systems - in WISC
QEMU user manual
Intel 80386 Programmer’s Reference Manual, 1987 (HTML).
Linux 汇编语言开发指南
汇编语言程序设计 布鲁姆 著, 马朝晖 等译,机械工业出版社,2005
MP specification
IO APIC
微型计算机技术及应用(第4版) 戴梅萼,史嘉权 编著, 清华大学出版社, 2008
x86/x64体系探索及编程 邓志 著,电子工业出版社,2012
x86汇编语言:从实模式到保护模式 李忠,王晓波,余洁 著,电子工业出版社,2013
BIOS Services and Software Interrupts, Roger Morgan, 1997.
















 1790
1790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











