







@creat_data: 2017-05-08
@author: huangyongye
前言: 在进行数据处理的时候,我们经常会用到 pandas 。但是 pandas 本身好像并没有提供多进程的机制。本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行。其中,我们主要借助 joblib 库,这个库为python 提供了一个非常简洁方便的多进程实现方法。
所以,本文将按照下面的安排展开,前面可能比较啰嗦,若只是想知道怎么用可直接看第三部分:
- 首先简单介绍 pandas 中的分组聚合操作 groupby。
- 然后简单介绍 joblib 的使用方法。
- 最后,通过一个去停用词的实验详细介绍如何实现 pandas 中 apply 函数多进程执行。
注意:本文说的都是多进程而不是多线程。
1. DataFrame.groupby 分组聚合操作
# groupby 操作
df1 = pd.DataFrame({
'a':[1,2,1,2,1,2], 'b':[3,3,3,4,4,4], 'data':[12,13,11,8,10,3]})
df1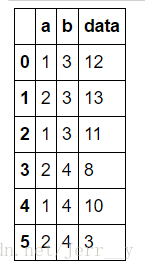
按照某列分组
grouped = df1.groupby('b')
# 按照 'b' 这列分组了,name 为 'b' 的 key 值,group 为对应的df_group
for name, group in grouped:
print name, '->'
print group3 ->
a b data
0 1 3 12
1 2 3 13
2 1 3 11
4 ->
a b data
3 2 4 8
4 1 4 10
5 2 4 3
按照多列分组
grouped = df1.groupby(['a','b'])
# 按照 'b' 这列分组了,name 为 'b' 的 key 值,group 为对应的df_group
for name, group in grouped:
print name, '->'
print group(1, 3) ->
a b data
0 1 3 12
2 1 3 11
(1, 4) ->
a b data
4 1 4 10
(2, 3) ->
a b data
1 2 3 13
(2, 4) ->
a b data
3 2 4 8
5 2 4 3
若 df.index 为[1,2,3…]这样一个 list, 那么按照 df.index分组,其实就是每组就是一行,在后面去停用词实验中,我们就用这个方法把 df_all 处理成每行为一个元素的 list, 再用多进程处理这个 list。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









