






#头歌#
第三关
任务描述
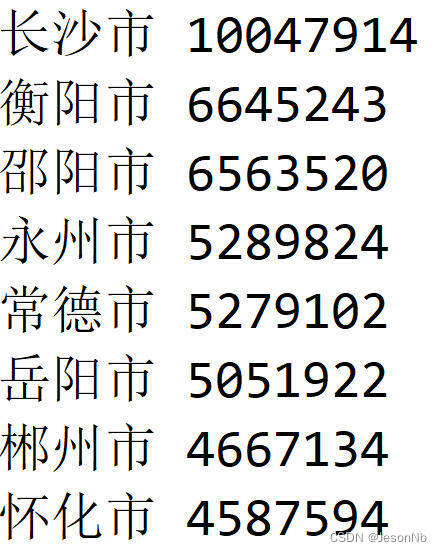
本关任务:根据上个步骤中爬取的表格内容,将城市名称和人口数存放在列表 lb 中,按人口数降序排列后输出。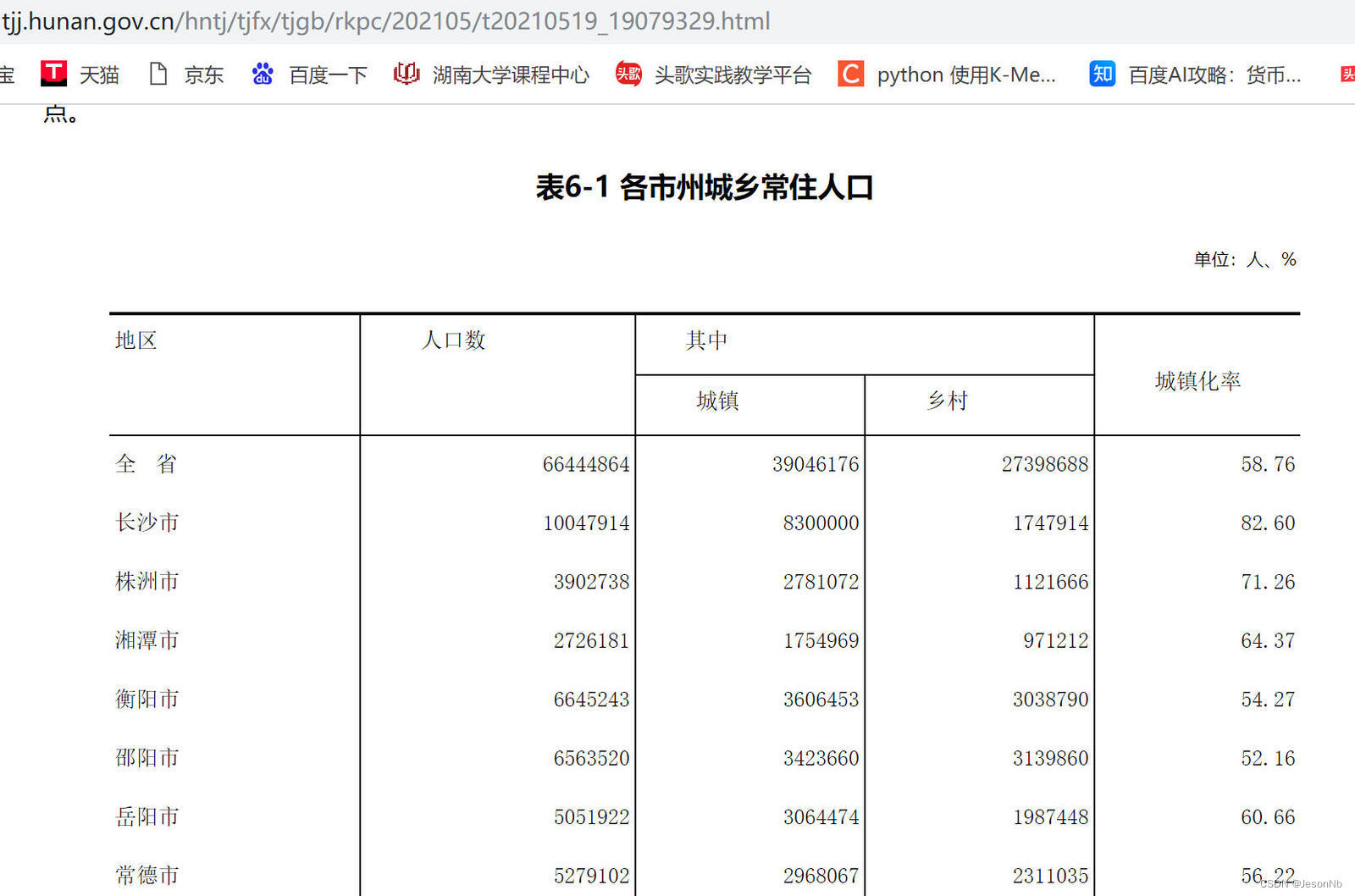
代码
import requests
from bs4 import BeautifulSoup
url = "https://tjj.hunan.gov.cn/hntj/tjfx/tjgb/pcgbv/202105/t20210519_19079329.html"
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,"html.parser")
bg = soup.find('table')
#代码开始
lb = bg.find_all("tr")
citys = {}
for i in range(3,len(lb)):
#print(lb[i])
datas = lb[i].find_all("td")
#print(datas)
str1 = ""
for i in range(0,2):
data = datas[i].find("p").text
str1 += data + ' '
result = str1.split()
citys[result[0]] = int(result[1])
# 按人口数量对城市进行排序
sorted_cities = sorted(citys.items(), key=lambda x: x[1], reverse=True)
# 输出排序后的结果
for city, population in sorted_cities:
print(f"{city} {population}")
第四关
任务描述
本关任务:编写一个爬取湖南大学讲座信息网页的程序。
湖南大学讲座信息的网址为 https://www.hnu.edu.cn/xysh/xshd.htm 。
编写程序,爬取该页第一个讲座的时间、标题、主讲人和地点信息,存储在字符串 jzsj 、jzbt 、jzdd 中,如下所示:
代码
import requests
from bs4 import BeautifulSoup
url = 'https://www.hnu.edu.cn/xysh/xshd.htm'
r = requests.get(url)
r.encoding = 'utf-8'
#代码开始
soup = BeautifulSoup(r.text, "html.parser")
xw = soup.find("div", class_="xinwen-wen")
jzsj = xw.find("div", class_="xinwen-sj-top").text.strip()
# print(jzsj)
jzbt=xw.find("div", class_="xinwen-wen-bt").text.strip()
# print(jzbt)
jzdd=xw.find("div", class_="xinwen-wen-zy").text.strip()
# print(jzdd)
#代码结束
f1=open("jzxx.txt","w")
f1.write(jzsj+"\n")
f1.write(jzbt+"\n")
f1.write(jzdd+"\n")
f1.close()
















 2065
2065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









