






 本文介绍了如何在LangChainSummarizer中使用ChatGLM进行文档摘要,包括从无ChatGLM类到找到官方文档的过程,本地部署ChatGLMAPI的设置,以及遇到的OSError问题的解决方法,旨在帮助读者避免常见陷阱。
本文介绍了如何在LangChainSummarizer中使用ChatGLM进行文档摘要,包括从无ChatGLM类到找到官方文档的过程,本地部署ChatGLMAPI的设置,以及遇到的OSError问题的解决方法,旨在帮助读者避免常见陷阱。
一、相关资料
LangChain summarizer是一个可以利用大语言模型生成文档摘要的工具。本人在实操过程中,主要参阅了以下资料:
文章一:ChatGPT生成英文摘要
LangChain Summarizer:一个让你轻松生成文档摘要的神奇工具![]() https://blog.csdn.net/FrenzyTechAI/article/details/131524746文章二:ChatGLM生成中文摘要
https://blog.csdn.net/FrenzyTechAI/article/details/131524746文章二:ChatGLM生成中文摘要
ChatGLM-6B + LangChain 实践![]() https://zhuanlan.zhihu.com/p/630147161
https://zhuanlan.zhihu.com/p/630147161
文章三:官方文档关于ChatGLM类的使用
ChatGLM | 🦜️🔗 Langchain![]() https://python.langchain.com/docs/integrations/llms/chatglm
https://python.langchain.com/docs/integrations/llms/chatglm
二、使用过程
1.在根据文章二的博主在写文章时,LangChain中并没有ChatGLM类。大概半个月后,LangChain貌似添加了ChatGLM类,通过评论区我找到了官方关于ChatGLM类使用的说明(即文章三)。文章二中博主自己定义了一个GLM类,按照文章三的示范,替换成官方已有的ChatGLM类即可。
关于ChatGLM类里的具体参数及含义,可以参阅:langchain_community.llms.chatglm — 🦜🔗 LangChain 0.1.1![]() https://api.python.langchain.com/en/latest/_modules/langchain_community/llms/chatglm.html
https://api.python.langchain.com/en/latest/_modules/langchain_community/llms/chatglm.html
2.如果ChatGLM是部署在本地,需要先运行ChatGLM中的api.py(一样把里面的模型路径改成你自己的模型路径),生成服务端口,其他的无需改动。
api.py需要一直运行,而且貌似在命令窗口运行会报错,找不到本地模型。可以在pycharm开两个窗口,一个运行langchain summarizer,一个运行api。默认url的就是"http://127.0.0.1:8000",虽然运行api后会显示"Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)",但是不用管它。

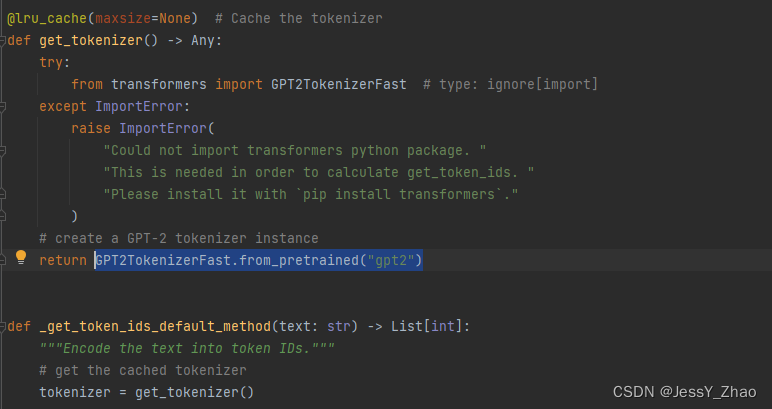
三、报错及解决:OSError: Can't load tokenizer for 'gpt2'.
报错显示,langchain里面确实有试图加载GPT-2 tokenizer。

直接去hugging face上找到GPT-2的模型下载到本地。
https://huggingface.co/gpt2/tree/main![]() https://huggingface.co/gpt2/tree/main再根据报错的指引,把langchain里的那句程序改掉,GPT2TokenizerFast.from_pretrained("gpt2"),把gpt2改成自己的路径。
https://huggingface.co/gpt2/tree/main再根据报错的指引,把langchain里的那句程序改掉,GPT2TokenizerFast.from_pretrained("gpt2"),把gpt2改成自己的路径。
大功告成!
前人多探路,后人少踩坑。希望对你有所帮助!!















 7527
7527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









