







文章目录
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 什么是内存屏障?
内存屏障(Memory Barrier),就如其名字所暗示的那样,就是在代码里面插入一个屏障,或者说栅栏,使得屏障前的存储操作不会跨越到屏障后的位置执行,屏障后的存储操作也不会跨越到屏障前的位置执行。也就是说,内存屏障对其之前和之后的存储操作保序,内存屏障之前的存储操作比其之后的存储操作先完成。
3. 为什么需要内存屏障?
1. 多发射(Multi-issuing)
2. 乱序执行(Out-of-order execution)
3. 预测执行(Speculative execution)
4. Load-Store 优化
5. CPU Cache
6. 编译乱序其中 1~5 为硬件实现的技术,现代硬件架构大多支持;6 为编译器软件技术。上面列举的这些软硬件技术,会导致指令的执行、访存顺序不按期待的顺序(编码顺序)执行,并最终可能造成程序逻辑错误。接下来对这些软硬件技术做简单介绍,其中的硬件技术 1~5,以 ARM 架构为例加以说明。
3.1 多发射(Multi-issuing)
多发射(Multi-issuing),是指 CPU 的执行单元有多个端口,同一个时钟周期可以发射多条指令给不同的执行单元去执行。假设有如下 ARM 汇编代码片段:
add r0, r0, #1
mul r2, r2, r3
ldr r1, [r0]
mov r4, r2
sub r1, r2, r5
str r1, [r0]
bx lr在一个支持 dual-issuing(双发射) 的处理器上,上面的代码片段的执行过程看起来会像是这样:
| Cycle | Issue0 | Issue1 |
|---|---|---|
| 0 | add r0, r0, #1 | mul r2, r2, r3 |
| 1 | ldr r1, [r0] | mov r4, r2 |
| 2 | sub r1, r2, r5 | * stall * |
| 3 | str r1, [r0] | bx lr |
上面表格中的 Issue0 和 Issue1 同时执行,即在同一 Cycle 中分别执行不同的指令。在 Cycle 2 时,Issue1 处于 stall 状态,因为它不能立马执行 bx lr 指令从子程序返回,而是要等待 Issue0 的 sub r1, r2, r5 的执行结果(Issue0 的最后一条指令 str r1, [r0] 需要 r1 的值),然后在 Cycle 3 中分别在 Issue0 和 Issue1 中同时执行 str r1, [r0] 和 bx lr 指令。
3.2 乱序执行(Out-of-order execution)
第一款支持 乱序执行(Out-of-order execution) 的 ARM 处理器是 Arm1136J(F)-S,它允许没有依赖关系的读写指令完全乱序的执行。发展到 Cortex-A9,仍然支持无依赖存储指令的乱序执行,同时,当指令因为等待前一条指令的结果而停滞时,CPU 可以继续执行后续没有因未满足依赖关系而等待的指令。
假定有如下 ARM 汇编代码片段:
add r0, r0, #4
mul r2, r2, r3
str r2, [r0]
ldr r4, [r1]
sub r1, r4, r2
bx lr其中,mul 和 ldr 指令,在多种架构上需要消耗几个 cycle 才能得到结果,我们假定它们均需要消耗 2 个 cycle。在 按序(in-order)执行 的 CPU 上,上述代码片段执行过程看起来会像是这样:
| Cycle | Issue |
|---|---|
| 0 | add r0, r0, #4 |
| 1 | mul r2, r2, r3 |
| 2 | * stall * |
| 3 | str r2, [r0] |
| 4 | ldr r4, [r1] |
| 5 | * stall * |
| 6 | sub r1, r4, r2 |
| 7 | bx lr |
如果在支持 乱序执行(Out-of-order execution) 的 CPU 上,上述代码片段执行过程看起来会像是这样:
| Cycle | Issue |
|---|---|
| 0 | add r0, r0, #4 |
| 1 | mul r2, r2, r3 |
| 2 | ldr r4, [r1] |
| 3 | str r2, [r0] |
| 4 | sub r1, r4, r2 |
| 5 | bx lr |
可以看到,在 按序(in-order)执行 的 CPU 上,mul 和 ldr 导致了 CPU 等待(stall);而在支持 乱序执行(Out-of-order execution) 的 CPU 上,mul 和 ldr 玩成数据期间,后续没有数据依赖关系的指令可以继续执行,而不必等待 mul 和 ldr 指令完成。
3.3 预测执行(Speculative execution)
预测执行(Speculative execution) 可以简单的描述为:CPU 在确切地知道是不是需要执行指令前,预测指令可能会执行(最终不一定需要执行),就提前做指令执行的准备工作(取指、翻译等)或干脆完成指令执行(取指、翻译、执行)。这意味着,如果预测是正确的,最终确定指令需要执行,将可以更快的得到执行结果。
在 ARM 架构下,预测执行(Speculative execution) 的例子有 带条件的 ARM、Thumb 指令,或 条件分支指令之后的指令。
对于存储访问,可以预测对某些存储位置的访问,从而提前执行对这些存储位置的加载操作,这样加快了实际使用时的访问速度。
3.4 Load-Store 优化
相对于现在 CPU 的执行速度,由于 CPU 访存的延迟相当可观,因此会想方设法的进行优化。Load-Store 优化,通常是将多次访存事务,合并成一个,这样使得原本的多次访存事务的延迟,在合并后只有一个访存事务的延迟。但凡事利弊并存,合并访存事务,譬如写入,会推迟在其它 CPU 核看到存储设备写入结果的时间。
3.5 CPU Cache
为缓解 CPU 高速执行 和 内存访问速度相对较慢 之间的矛盾,在 CPU 和 内存 之间引入比内存访问更快的 Cache:第一次访问内存某个位置的数据时,将它们缓存到 Cache,这样后续可以从 Cache 访问,速度更快;然后在需要的时候将 Cache 中缓存的数据刷回到内存。
CPU Cache 技术,提高了存储访问速度,这是它利的一方面;同时,CPU Cache 也会导致多个 CPU 核之间、以及 CPU 和外设之间的 Cache 一致性(Cache Coherent)问题。举个例子,假设 CPU 1 和 2 分别加载存储位置 0x8000 处的数据到自己私有的 L1 cache,接着 CPU 1 修改了数据并写入自己私有的 L1 cache,但不将新数据回写到存储位置 0x8000。这时候 CPU 2 从自己私有的 L1 cache 读取该数据,读到的仍然是从存储位置 0x8000 处加载的旧数据,而不是 CPU 1 更新后的数据,这样分别从 CPU 1 和 2 角度观察同一份数据(存储位置 0x8000)的不同副本(CPU 各自私有的 L1 cache 副本),它们的值不一样,这就是 Cache 一致性(Cache Coherent)问题。
3.6 编译乱序
假设有如下 C 代码片段:
int flag = BUSY;
int data = 0;
int somefunc(void)
{
while (flag != DONE)
;
return data;
}
void otherfunc(void)
{
data = 888;
flag = DONE;
}假定上面的函数 otherfunc() 在 线程 A 中执行,而函数 somefunc() 在 线程 B 中执行。C 语言规范中没有任何内容能够保证,函数 somefunc() 在轮询 flag 之前不会线读取 data 的值,也就说,somefunc() 返回 0 或 888 都是合法的。虽然我们可以通过插入编译屏障(如 Linux 内核接口 READ_ONCE())来解决这类问题。要知道的是,虽然编译屏障可以解决编译乱序,但仍然无法解决像前面提到的硬件执行乱序。
3.7 小结
需要知道的是,不管是 编译器 还是 CPU 内存访问乱序,都需要遵循一个基本规则:不得修改单线程程序的行为。这条基本规则的意思是,不管是编译时的编译器内存访问重排序,还是运行时的 CPU 内存访问重排序,都要在不改变单线程行为的前提下进行。如有以下代码:
int x, y;
void foo(void)
{
x = y + 1;
y = 0;
}不管是编译器还是 CPU,如果将 y = 0; 重排序到 x = y + 1; 之前完成,从单线程的上下文来看,这不影响执行结果,那么这个重排序就是符合基本规则的。
4. ARM 内存一致性模型 和 内存屏障
4.1 ARM 内存一致性模型
先看一张来自 WiKi 文档 Runtime_memory_ordering 的表格,它描述了各常见硬件架构下的内存一致性模型:
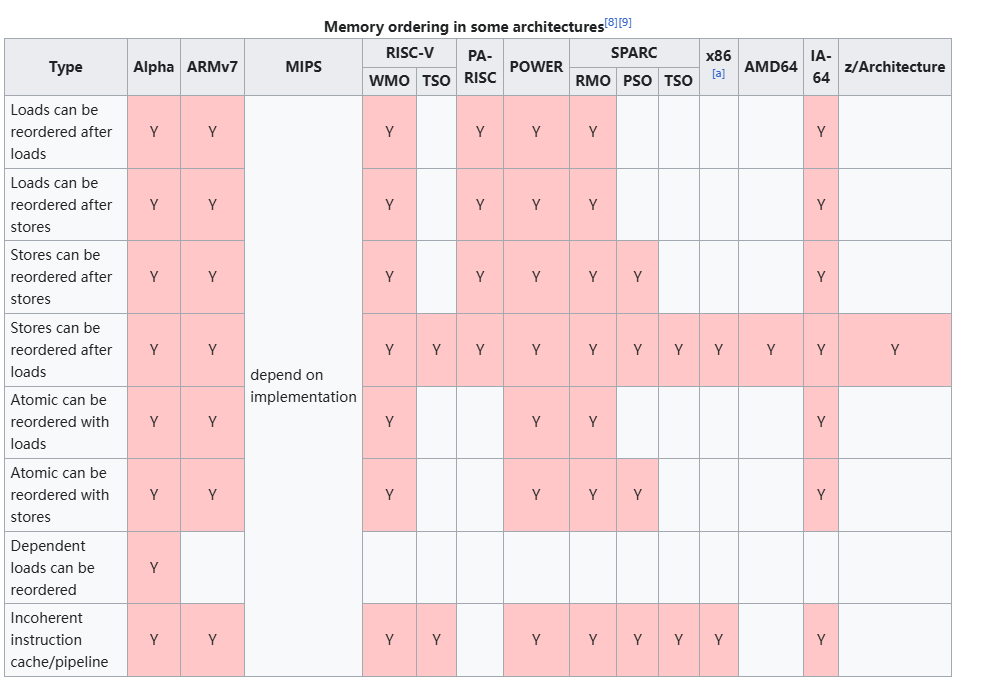
我们重点关注上图中 ARMv7 那一栏,从表格可以看到,除了 有依赖关系的 Load-Load 操作 不会乱序外(没有 Y 标记的空白格),其它的组合都可能出现乱序。
ARM 官方手册也没有明确使用的内存一致性模型,只说是 weakly-ordered:
Accesses to Normal Memory conform to the weakly-ordered model of memory ordering.4.2 ARM 内存类型和属性
ARMv7 架构下定义了 3 种类型的内存空间:
1. Strongly Ordered Memory: 外设映射的 IO 内存空间
2. Device Memory: 外设映射的 IO 内存空间,或 外设映射的 IO 寄存器
3. Normal Memory:Flash ROM, ROM, SRAM, DRAM, DDR 等ARM 文档 DDI0406C_d_armv7ar_arm.pdf,A3.5.2 Summary of ARMv7 memory attributes 小节给出下表,列举了这 3 种类型的 内存空间 及其 属性(Shareability, Cacheability):
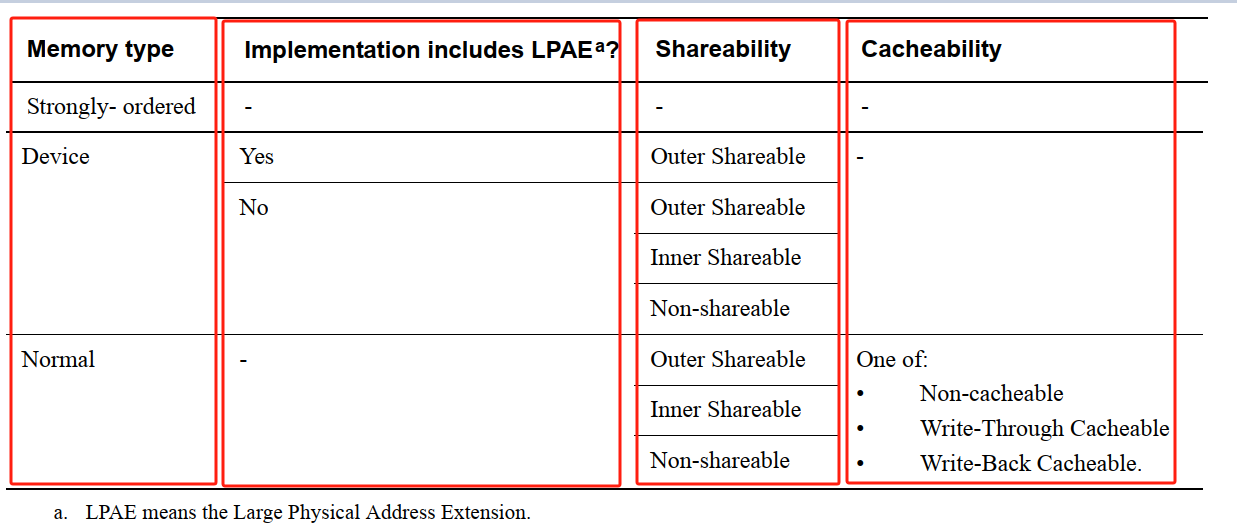
其中,Cacheability 属性 Cacheable 和 Non-cacheable 指各种类型内存中的数据是否会经过 CPU cache;Shareability 属性 Inner-shareable、Outer Shareable、Non-Shareable 指内存空间的数据,可被哪些角色(CPU cores、Device)访问。理解 Shareability 属性,是理解 ARM 内存屏障指令的基础。
内存的属性,包括但不仅限于 Cacheability 和 Shareability,ARM 架构(这里重点关注 ARMv7)在系统初始化阶段配置了 Cache 策略 和 内存页面属性初始默认值。
start_kernel()
setup_arch()
setup_processor()
...
#ifdef CONFIG_MMU
early_mm_init()
build_mem_type_table()
#endif4.2.1 ARM Cache 策略配置
/* arch/arm/mm/proc-v7-3level.S */
#define PMD_FLAGS_SMP (PMD_SECT_WBWA|PMD_SECT_S)
/* arch/arm/mm/proc-v7.S */
/*
* Standard v7 proc info content
*/
.macro __v7_proc name, initfunc, mm_mmuflags = 0, io_mmuflags = 0, hwcaps = 0, proc_fns = v7_processor_functions
/* proc_info_list::__cpu_mm_mmu_flags */
ALT_SMP(.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_AP_READ | \
PMD_SECT_AF | PMD_FLAGS_SMP | \mm_mmuflags)
/* proc_info_list::__cpu_io_mmu_flags */
.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | \
PMD_SECT_AP_READ | PMD_SECT_AF | \io_mmuflags
......
.endm
/*
* ARM Ltd. Cortex A7 processor.
*/
/* Cortex A7 处理器对象定义
* 详见: struct proc_info_list (arch/arm/include/asm/procinfo.h)
*/
.type __v7_ca7mp_proc_info, #object
__v7_ca7mp_proc_info: // 定义 ARMv7 CPU 的 struct proc_info_list 对象
.long 0x410fc070 /* proc_info_list::cpu_val */
.long 0xff0ffff0 /* proc_info_list::cpu_mask */
__v7_proc __v7_ca7mp_proc_info, __v7_ca7mp_setup
.size __v7_ca7mp_proc_info, . - __v7_ca7mp_proc_info/* arch/arm/kernel/setup.c */
/* Cache 等其它一些 CPU 相关的初始化(这里重点关注 Cache,因为这和本文所述的内存屏障相关) */
static void __init setup_processor(void)
{
unsigned int midr = read_cpuid_id();
struct proc_info_list *list = lookup_processor(midr); /* arch/arm/mm/proc-v7.S: &__v7_ca7mp_proc_info */
...
#ifdef CONFIG_MMU
// list->__cpu_mm_mmu_flags 的见前面的汇编代码:
// PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_AP_READ | \
// PMD_SECT_AF | PMD_FLAGS_SMP
init_default_cache_policy(list->__cpu_mm_mmu_flags);
#endif
...
}
/* arch/arm/mm/mmu.c */
static struct cachepolicy cache_policies[] __initdata = {
{
.policy = "uncached",
.cr_mask = CR_W|CR_C,
.pmd = PMD_SECT_UNCACHED,
.pte = L_PTE_MT_UNCACHED,
.pte_s2 = s2_policy(L_PTE_S2_MT_UNCACHED),
}, {
.policy = "buffered",
.cr_mask = CR_C,
.pmd = PMD_SECT_BUFFERED,
.pte = L_PTE_MT_BUFFERABLE,
.pte_s2 = s2_policy(L_PTE_S2_MT_UNCACHED),
}, {
.policy = "writethrough",
.cr_mask = 0,
.pmd = PMD_SECT_WT,
.pte = L_PTE_MT_WRITETHROUGH,
.pte_s2 = s2_policy(L_PTE_S2_MT_WRITETHROUGH),
}, {
.policy = "writeback",
.cr_mask = 0,
.pmd = PMD_SECT_WB,
.pte = L_PTE_MT_WRITEBACK,
.pte_s2 = s2_policy(L_PTE_S2_MT_WRITEBACK),
}, {
.policy = "writealloc",
.cr_mask = 0,
.pmd = PMD_SECT_WBWA,
.pte = L_PTE_MT_WRITEALLOC,
.pte_s2 = s2_policy(L_PTE_S2_MT_WRITEBACK),
}
};
#ifdef CONFIG_CPU_CP15
static unsigned long initial_pmd_value __initdata = 0;
void __init init_default_cache_policy(unsigned long pmd)
{
int i;
initial_pmd_value = pmd; // PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_AP_READ | PMD_SECT_AF | PMD_FLAGS_SMP
pmd &= PMD_SECT_CACHE_MASK;
/* 设置 cache 策略 */
for (i = 0; i < ARRAY_SIZE(cache_policies); i++)
if (cache_policies[i].pmd == pmd) {
cachepolicy = i;
break;
}
...
}
#endif4.2.2 ARM 内存页面属性初始默认值 配置
/* arch/arm/mm/mmu.c */
static struct mem_type mem_types[] __ro_after_init = {
[MT_DEVICE] = { /* Strongly ordered / ARMv6 shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED |
L_PTE_SHARED,
.prot_pte_s2 = s2_policy(PROT_PTE_S2_DEVICE) |
s2_policy(L_PTE_S2_MT_DEV_SHARED) |
L_PTE_SHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE | PMD_SECT_S,
.domain = DOMAIN_IO,
},
[MT_DEVICE_NONSHARED] = { /* ARMv6 non-shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_NONSHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE,
.domain = DOMAIN_IO,
},
[MT_DEVICE_CACHED] = { /* ioremap_cached */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_CACHED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE | PMD_SECT_WB,
.domain = DOMAIN_IO,
},
[MT_DEVICE_WC] = { /* ioremap_wc */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_WC,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE,
.domain = DOMAIN_IO,
},
[MT_UNCACHED] = {
.prot_pte = PROT_PTE_DEVICE,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN,
.domain = DOMAIN_IO,
},
[MT_CACHECLEAN] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN,
.domain = DOMAIN_KERNEL,
},
#ifndef CONFIG_ARM_LPAE
[MT_MINICLEAN] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN | PMD_SECT_MINICACHE,
.domain = DOMAIN_KERNEL,
},
#endif
[MT_LOW_VECTORS] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_RDONLY,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_VECTORS,
},
[MT_HIGH_VECTORS] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_USER | L_PTE_RDONLY,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_VECTORS,
},
[MT_MEMORY_RWX] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_ROM] = {
.prot_sect = PMD_TYPE_SECT,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RWX_NONCACHED] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_MT_BUFFERABLE,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW_DTCM] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_XN,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RWX_ITCM] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW_SO] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_MT_UNCACHED | L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_S |
PMD_SECT_UNCACHED | PMD_SECT_XN,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_DMA_READY] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_KERNEL,
},
};
/*
* 根据 CPU 架构 @cpu_arch 的特性,调整各类型内存页面
* MT_DEVICE(Device Memory / Strongly Ordered Memory), MT_MEMORY_*(Normal Memory)
* 的属性(Cacheability, RWX, Domain, ...) 在表格 mem_types[] 中的默认初始值。
*/
static void __init build_mem_type_table(void)
{
...
/*
* Mark the device areas according to the CPU/architecture.
*/
if (cpu_is_xsc3() || (cpu_arch >= CPU_ARCH_ARMv6 && (cr & CR_XP))) {
if (!cpu_is_xsc3()) {
/*
* Mark device regions on ARMv6+ as execute-never
* to prevent speculative instruction fetches.
*/
mem_types[MT_DEVICE].prot_sect |= PMD_SECT_XN;
mem_types[MT_DEVICE_NONSHARED].prot_sect |= PMD_SECT_XN;
mem_types[MT_DEVICE_CACHED].prot_sect |= PMD_SECT_XN;
mem_types[MT_DEVICE_WC].prot_sect |= PMD_SECT_XN;
/* Also setup NX memory mapping */
mem_types[MT_MEMORY_RW].prot_sect |= PMD_SECT_XN;
}
if (cpu_arch >= CPU_ARCH_ARMv7 && (cr & CR_TRE)) {
/*
* For ARMv7 with TEX remapping,
* - shared device is SXCB=1100
* - nonshared device is SXCB=0100
* - write combine device mem is SXCB=0001
* (Uncached Normal memory)
*/
mem_types[MT_DEVICE].prot_sect |= PMD_SECT_TEX(1);
mem_types[MT_DEVICE_NONSHARED].prot_sect |= PMD_SECT_TEX(1);
mem_types[MT_DEVICE_WC].prot_sect |= PMD_SECT_BUFFERABLE;
} else if (cpu_is_xsc3()) {
...
} else {
...
}
} else {
...
}
/*
* Now deal with the memory-type mappings
*/
cp = &cache_policies[cachepolicy];
vecs_pgprot = kern_pgprot = user_pgprot = cp->pte;
s2_pgprot = cp->pte_s2;
hyp_device_pgprot = mem_types[MT_DEVICE].prot_pte;
s2_device_pgprot = mem_types[MT_DEVICE].prot_pte_s2;
...
/*
* ARMv6 and above have extended page tables.
*/
if (cpu_arch >= CPU_ARCH_ARMv6 && (cr & CR_XP)) {
...
/*
* If the initial page tables were created with the S bit
* set, then we need to do the same here for the same
* reasons given in early_cachepolicy().
*/
if (initial_pmd_value & PMD_SECT_S) {
user_pgprot |= L_PTE_SHARED; /* Inner Shareable */
kern_pgprot |= L_PTE_SHARED; /* Inner Shareable */
vecs_pgprot |= L_PTE_SHARED; /* Inner Shareable */
s2_pgprot |= L_PTE_SHARED; /* Inner Shareable */
mem_types[MT_DEVICE_WC].prot_sect |= PMD_SECT_S;
mem_types[MT_DEVICE_WC].prot_pte |= L_PTE_SHARED; /* Inner Shareable */
mem_types[MT_DEVICE_CACHED].prot_sect |= PMD_SECT_S;
mem_types[MT_DEVICE_CACHED].prot_pte |= L_PTE_SHARED; /* Inner Shareable */
mem_types[MT_MEMORY_RWX].prot_sect |= PMD_SECT_S;
mem_types[MT_MEMORY_RWX].prot_pte |= L_PTE_SHARED; /* Inner Shareable */
mem_types[MT_MEMORY_RW].prot_sect |= PMD_SECT_S;
mem_types[MT_MEMORY_RW].prot_pte |= L_PTE_SHARED; /* Inner Shareable */
mem_types[MT_MEMORY_DMA_READY].prot_pte |= L_PTE_SHARED;
mem_types[MT_MEMORY_RWX_NONCACHED].prot_sect |= PMD_SECT_S;
mem_types[MT_MEMORY_RWX_NONCACHED].prot_pte |= L_PTE_SHARED; /* Inner Shareable */
}
}
...
for (i = 0; i < 16; i++) {
pteval_t v = pgprot_val(protection_map[i]);
protection_map[i] = __pgprot(v | user_pgprot);
}
/* 中断向量表内存页面属性 */
mem_types[MT_LOW_VECTORS].prot_pte |= vecs_pgprot;
mem_types[MT_HIGH_VECTORS].prot_pte |= vecs_pgprot;
pgprot_user = __pgprot(L_PTE_PRESENT | L_PTE_YOUNG | user_pgprot);
pgprot_kernel = __pgprot(L_PTE_PRESENT | L_PTE_YOUNG |
L_PTE_DIRTY | kern_pgprot);
pgprot_s2 = __pgprot(L_PTE_PRESENT | L_PTE_YOUNG | s2_pgprot);
pgprot_s2_device = __pgprot(s2_device_pgprot);
pgprot_hyp_device = __pgprot(hyp_device_pgprot);
...
}4.2.3 ARM 建立内存映射时 页面属性 的 设定
前面从 ARM 架构硬件 和 ARM Linux 的角度,简单说明了 ARM 内存页面初始属性以及其初始设定过程。下面举几个简单的例子,来说明在 ARM 内存页面映射建立过程中,是怎样使用这些页面初始属性值的。
start_kernel()
setup_arch()
setup_processor()
...
#ifdef CONFIG_MMU
early_mm_init()
#endif
...
paging_init()
map_lowmem()4.2.3.1 ARM Linux 内核镜像映射
/* arch/arm/mm/mmu.c */
static void __init map_lowmem(void)
{
struct memblock_region *reg;
phys_addr_t kernel_x_start = round_down(__pa(KERNEL_START), SECTION_SIZE);
phys_addr_t kernel_x_end = round_up(__pa(__init_end), SECTION_SIZE);
/* Map all the lowmem memory banks. */
for_each_memblock(memory, reg) {
phys_addr_t start = reg->base;
phys_addr_t end = start + reg->size;
struct map_desc map;
...
if (end < kernel_x_start) {
...
} else if (start >= kernel_x_end) {
...
} else {
...
map.pfn = __phys_to_pfn(kernel_x_start);
map.virtual = __phys_to_virt(kernel_x_start);
map.length = kernel_x_end - kernel_x_start;
map.type = MT_MEMORY_RWX; /* 内存类型: Normal Memory, RWX */
create_mapping(&map);
...
}
}
}
create_mapping()
__create_mapping(&init_mm, md, early_alloc, false);
static void __init __create_mapping(struct mm_struct *mm, struct map_desc *md,
void *(*alloc)(unsigned long sz),
bool ng)
{
...
const struct mem_type *type;
...
type = &mem_types[md->type];
...
do {
...
alloc_init_pud(pgd, addr, next, phys, type, alloc, ng);
...
} while (pgd++, addr != end);
}
alloc_init_pud(pgd, addr, next, phys, type, alloc, ng);
alloc_init_pmd(pud, addr, next, phys, type, alloc, ng);
__map_init_section(pmd, addr, next, phys, type, ng);
static void __init __map_init_section(pmd_t *pmd, unsigned long addr,
unsigned long end, phys_addr_t phys,
const struct mem_type *type, bool ng)
{
pmd_t *p = pmd;
do {
/* 更新 PMD 页表项(包括 section 内存属性) */
*pmd = __pmd(phys | type->prot_sect | (ng ? PMD_SECT_nG : 0));
phys += SECTION_SIZE;
} while (pmd++, addr += SECTION_SIZE, addr != end);
...
}上面内核镜像的映射过程,从 mem_types[MT_MEMORY_RW] 获取经 build_mem_type_table() 修正的属性,包括 L_PTE_SHARED 标记,所以在采用 3 级分页的时候,内核镜像 映射的内存区页面是 Inner Shareable ,如何确定 Shareability 属性的更多细节需要参考 ARM 手册对页表项 SH 等标志位的说明。
4.2.3.2 IO 映射
/* arch/arm/include/asm/io.h */
/*
* ioremap() and friends.
*
* ioremap() takes a resource address, and size. Due to the ARM memory
* types, it is important to use the correct ioremap() function as each
* mapping has specific properties.
*
* Function Memory type Cacheability Cache hint
* ioremap() Device n/a n/a
* ioremap_nocache() Device n/a n/a
* ioremap_cache() Normal Writeback Read allocate
* ioremap_wc() Normal Non-cacheable n/a
* ioremap_wt() Normal Non-cacheable n/a
*
* All device mappings have the following properties:
* - no access speculation
* - no repetition (eg, on return from an exception)
* - number, order and size of accesses are maintained
* - unaligned accesses are "unpredictable"
* - writes may be delayed before they hit the endpoint device
*
* ......
*/
void __iomem *ioremap(resource_size_t res_cookie, size_t size);
#define ioremap ioremap
#define ioremap_nocache ioremapioremap() 这详尽的注释了各类型内存经其映射后 Cacheability 属性,下面来看看 Shareability 相关的细节:
/* arch/arm/mm/ioremap.c */
ioremap()
arch_ioremap_caller(res_cookie, size, MT_DEVICE, __builtin_return_address(0)) = __arm_ioremap_caller()
__arm_ioremap_pfn_caller()
static void __iomem * __arm_ioremap_pfn_caller(unsigned long pfn,
unsigned long offset, size_t size, unsigned int mtype, void *caller)
{
const struct mem_type *type;
...
type = get_mem_type(mtype);
...
#if !defined(CONFIG_SMP) && !defined(CONFIG_ARM_LPAE)
...
#endif
/* 只看这一种情形,其它情形类似,@type->prot_pte 设为 IO 映射的页面属性 */
err = ioremap_page_range(addr, addr + size, paddr,
__pgprot(type->prot_pte));
...
}看 get_mem_type(mtype) 是怎么拿取要映射的内存页面属性,前面的 arch_ioremap_caller(..., MT_DEVICE, ...) 给定了内存类型为 Device Memory(MT_DEVICE):
const struct mem_type *get_mem_type(unsigned int type)
{
return type < ARRAY_SIZE(mem_types) ? &mem_types[type] : NULL;
}
EXPORT_SYMBOL(get_mem_type);所以 mem_types[MT_DEVICE] 的值确定了 ioremap() 映射内存页面的属性,从其 L_PTE_SHARED 标志位可以看出,其 Shareability 为 Inner Shareable 。
4.2.3.3 DMA 一致性映射
DMA 使用的内存空间,有两种映射方式:第一种是一致性映射,这种方式映射的内存禁用了 Cacheability 属性,即数据不会经过 CPU cache;第二种是流式映射,即允许映射的内存的 Cacheability 属性,即数据会经过 CPU cache,这时候需要显式地调用 dma_sync_*_for_cpu(DMA_FROM_DEVICE) 或 dma_sync_*_for_device(DMA_TO_DEVICE) 系列接口来维护 cache 一致性。在这里,我们来看一下 DMA 内存 一致性映射 方式下的内存属性的指定过程:
/* include/linux/dma-mapping.h */
static inline void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag)
{
return dma_alloc_attrs(dev, size, dma_handle, flag, 0);
}
static inline void *dma_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
void *cpu_addr;
...
/* arm_dma_alloc() */
cpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs);
return cpu_addr;
}/* arch/arm/include/asm/pgtable.h */
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE)
#define pgprot_dmacoherent(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE | L_PTE_XN)
/* arch/arm/mm/dma-mapping.c */
static inline pgprot_t __get_dma_pgprot(unsigned long attrs, pgprot_t prot)
{
prot = (attrs & DMA_ATTR_WRITE_COMBINE) ?
pgprot_writecombine(prot) :
pgprot_dmacoherent(prot);
return prot;
}
void *arm_dma_alloc(struct device *dev, size_t size, dma_addr_t *handle,
gfp_t gfp, unsigned long attrs)
{
pgprot_t prot = __get_dma_pgprot(attrs, PAGE_KERNEL); /* 获取 DMA 映射内存属性,当前 @attr == 0 */
return __dma_alloc(dev, size, handle, gfp, prot, false,
attrs, __builtin_return_address(0));
}从上面 DMA 内存 一致性映射 过程中看到,映射的内存禁用了 Cacheability 属性。注意,L_PTE_MT_BUFFERABLE 属性和 cache 没有关系。
4.3 ARM 内存屏障
前面用了较长的篇幅,分别从硬件(ARM 架构)和软件(ARM Linux)的角度,描述了会导致存储乱序的各种因素。接下来,进入本文的正题:内存屏障,具体来讲 ARM 架构下的内存屏障。
4.3.1 内存屏障基础和概念
内存屏障,带有“内存”二字,带来的影响自然就是和内存操作相关的。笔者将内存屏障的基本要素归结为 3 点:
1. 内存屏障干预的存储相关因素
2. 内存屏障影响的存储操作序列类型
3. 内存屏障的影响对哪些范围的 Observers 可见4.3.1.1 内存屏障干预的存储相关因素
下面列举了内存屏障可能会影响的存储相关因素:
1. CPU Cache: Data/Instruction cache(L1 Cache, L2 Cache, L3 Cache, ...)
2. TLB(Translation Look-aside Buffer) Cache: 页表地址翻译缓存
3. CPU 指令流水线(pipeline)、乱序执行、分支预测、预取(Prefetch) 等
4. 编译乱序硬件内存屏障干预前 4 种因素,在运行时产生的影响;编译器软件内存屏障干预第 5 种因素,是编译时产生的影响。
4.3.1.2 内存屏障影响的存储操作序列类型
内存屏障影响如下列举的存储操作序列顺序:
Load-Load
Load-Store
Store-Load
Store-Store内存屏障影响存储操作序列顺序,这是什么意思呢?就拿第一个 Load-Load 来说,假设有两个 Load 操作,在编程顺序上,第一个是 Load 1,第二个是 Load 2,如果在 Load 1 和 2 之间插入一个某类型的内存屏障,能够保证对某范围(如前面例子中的 Inner)内的 Observers(观察者) 来说,Load 1 一定在 Load 2 之前发生,这就是一种对 Load-Load 存储操作在一定观察范围内、对属于该范围内的 Observers(观察者) 保序。
4.3.1.3 内存屏障的影响对哪些范围的 Observers 可见
内存屏障产生的影响,最终可归结为影响的Observers(观察者)范围,即产生的影响能被哪些Observers(观察者)观察到。Observers(观察者) 通常包括 CPU 核(及其 MMU)、(访问存储空间的)外设控制器 等,ARM 手册对于 Observers 也给出定义:

Observers(观察者)所处的范围,是由硬件架构和硬件实现共同决定的。不同的硬件架构和硬件实现,定义的Observers(观察者)范围类型存在差异。如 ARMv7-A 定义了如下一些影响 Observers 范围:Non-shareable、Inner Shareable、Outer Shareable、Full System 。

Non-shareable 通常是单个 CPU 核所在的区域;Inner Shareable 典型的情形是系统内所有 CPU 核所在的区域;Outer Shareable 典型的情形系统内所有 CPU 核 和 其它外设(如 GPU) 所在的区域,一个 Outer Shareable 区域可以包含多个 Inner Shareable 区域;Full system 通常指系统种所有存储访问者所在的区域,包括所有的 CPU 核 和 外设存储访问接口等。来张示例图直观感受一下:
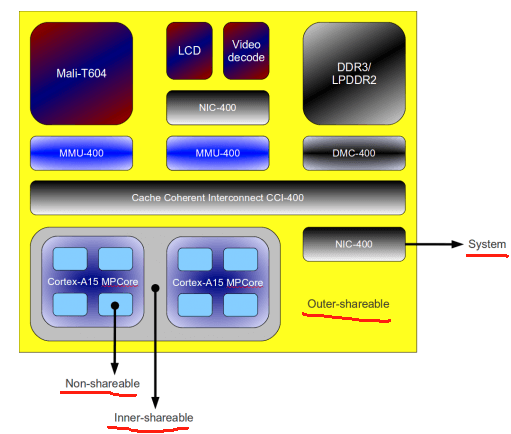
注意,上图仅仅是一种设计上的可能,不同的硬件架构和系统,对这些范围的划分可能存在差异。
4.3.2 ARM 内存屏障
ARM 架构提供如下内存屏障指令支持内存屏障,来帮助系统程序员来解决存储乱序的问题:
DMB: Data Memory Barrier
DSB: Data Synchronization Barrier
ISB: Instruction Synchronization Barrier
LDAR/STLR: Load-Acquire/Store-Release4.3.2.1 DSB (Data Synchronization Barrier)
先看下 ARM 官方手册对 DSB 的解释:

从上面的描述看到,以下 2 个条件同时满足时,标志 DSB 指令的执行完成:
1. DSB 指令之前的存储操作完成。
这意味着,DSB 之前存储操作,比其之后的存储操作先完成。
2. DSB 指令之前的 Cache、分支预测、TLB 维护操作 完成。
这意味着,在一定观察范围内,维护了 Cache 等的一致性。另外:
3. 在 DSB 指令执行完成前,即前面提到的 2 点完成前,其后的任何指令也不会被执行。我们按 4.3.1 开始处提到的 3 要素来解释这条指令:
1. DSB 干预的存储相关因素
Cache,也就是维护 observers 间的 Cache 一致性。
2. 内存屏障影响的存储操作序列类型
由传递给 DSB 指令的 <option> 决定,后面会进行介绍。
3. 内存屏障的影响对哪些范围的 Observers 可见
由传递给 DSB 指令的 <option> 决定,后面会进行介绍。接下来详细介绍 DSB 指令,看如何通过参数指定其影响的存储操作序列和可见范围:
A8.8.45 DSB
...
Assembler syntax
DSB{<c>}{<q>} {<option>}
...
where:
<c>, <q> ...
<option> Specifies an optional limitation on the DSB operation. Values are:
SY Full system is the required shareability domain, reads and
writes are the required access types. Can be omitted.
ST Full system is the required shareability domain, writes are
the required access type. SYST is a synonym for ST.
ISH Inner Shareable is the required shareability domain, reads
and writes are the required access types.
ISHST Inner Shareable is the required shareability domain, writes
are the required access type.
NSH Non-shareable is the required shareability domain, reads
and writes are the required access types.
NSHST Non-shareable is the required shareability domain, writes
are the required access type.
OSH Outer Shareable is the required shareability domain, reads
and writes are the required access types.
OSHST Outer Shareable is the required shareability domain, writes
are the required access type.解释下 <option> 的含义:
SY: DSB 指令 <option> 的缺省值,可省略。
DSB 保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
DSB 的效果对 Full system 范围内的 Observers 可见。
ST: DSB 保证其前后的 [写操作组合: Store-Store] 不会跨越它,
DSB 的效果对 Full system 范围内的 Observers 可见。
SYST 和 ST 有相同的含义。
ISH: DSB 保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
DSB 的效果对 Inner Shareable 范围内的 Observers 可见。
ISHST: DSB 保证其前后的 [写操作组合: Store-Store] 不会跨越它,
DSB 的效果对 Inner Shareable 范围内的 Observers 可见。
NSH: DSB 保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
DSB 的效果对 Non-shareable 范围内的 Observers 可见。
这通常是保证单个 CPU 核上的 [读写操作] 不乱序。
NSHST: DSB 保证其前后的 [写操作组合: Store-Store] 不会跨越它,
DSB 的效果对 Non-shareable 范围内的 Observers 可见。
这通常是保证单个 CPU 核上的 [写操作] 不乱序。
OSH: DSB 保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
DSB 的效果对 Outer Shareable 范围内的 Observers 可见。
OSHST: DSB 保证其前后的 [写操作组合: Store-Store] 不会跨越它,
DSB 的效果对 Outer Shareable 范围内的 Observers 可见。从上面的 <option> 可以看到,带 ST 后缀的 <option> 影响 Store-Store 的操作顺序序列,其它的 <option> 影响除 Store-Store 外其它存储操作序列(Load-Load、Load-Store、Store-Load)的顺序,ARMv7 架构下没有更进一步的细致划分,在一些场合下会带来性能损失。在 ARMv8 架构下,引入了更多的 <option>,进一步对这些存储操作序列进行了更细致的划分:

内存屏障位于 Group A 和 Group B 内的存储操作序列之间。从上面的表格可以看出,绿色标记的那一行,增加了在各观察范围(Full system、Outer-shareable、Inner Shareable、Non-shareable)内对 Load-Load、Load-Store 存储操作序列的保序支持:
LD : 对存储操作 Load-Load, Load-Store 保序,
效果对 Full system 范围内的 Observers 可见。
OSHLD: 对存储操作 Load-Load, Load-Store 保序,
效果对 Outer Shareable 范围内的 Observers 可见。
ISHLD: 对存储操作 Load-Load, Load-Store 保序,
效果对 Inner Shareable 范围内的 Observers 可见。
NSHLD: 对存储操作 Load-Load, Load-Store 保序,
效果对 Non-shareable 范围内的 Observers 可见。4.3.2.2 DMB (Data Memory Barrier)

从上面的描述看到,DMB 指令有如下功能特征:
1. 在 DMB 指令之前的存储操作,比其之后的存储操作,在一定范围内先被观察者观察到。
这里体现了 DMB 和 DSB 的差别,DSB 保证存储操作的完成,而 DMB 只是保证了顺序,
这两者是不同的。
2. DMB 只影响存储操作指令(Load/Store),而对其它非存储操作指令没有影响。从以上 2 点来看,DSB 是 DMB 的超集:DMB 指令仅仅保证存储操作序列之间的顺序,而 DSB 除此之外给予了更多的保证。
DMB 指令的语法和 DSB 一样:
A8.8.44 DMB
...
Assembler syntax
DSB{<c>}{<q>} {<option>}其 <option> 同 DSB 指令,在此不再赘述。
4.3.2.3 ISB (Instruction Synchronization Barrier)

从上面的描述看到,ISB 指令有如下功能特征:
1. ISB 刷新 CPU 的 pipeline(指令流水线),只有在 ISB 执行完成后,才会从 Cache 或
内存 中读取编程顺序上在 ISB 之后的指令。
2. ISB 确保 在其前的 上下文变更效果,在 ISB 指令执行玩抽,对 ISB 之后的 指令可见。 其中的 上下文变更效果,可能 cache、TLB、分支预测 维护操作,系统寄存器的修改(如修改 CP15 协处理器、GIC 中断芯片的寄存器) 等。ISB 指令的语法如下:
A8.8.54 ISB
...
Assembler syntax
ISB{<c>}{<q>} {<option>}
where:
<c>, <q> ...
<option> Specifies an optional limitation on the ISB operation. Values are:
SY Full system ISB operation, encoded as option = 0b1111. Can be omitted.ISB 指令同样也有影响的范围,只不过它的 <option> 只有一个值 SY,也即 ISB 指令产生的效果对系统中所有 Observers 可见。
4.3.2.4 LDAR/STLR (Load-Acquire/Store-Release)
这两条指令实现单边屏障(One-way barriers),就是说它们的屏障都只针对一个方向的起作用。对 ARM 平台而言,这两条指令在 ARMv8 架构下引入,先看一下 ARMv8 手册对它们的说明:

简单解释一下:
LDAR: 让其后的存储操作,不会跑到它前面去执行,
其效果的可见范围由其引用地址的内存属性决定。
STLR: 让其前的存储操作,不会跑到它后面去执行,
其效果的可见范围由其引用地址的内存属性决定。LDAR 和 STLR 配对试用,形成如下图的效果(图片来自 DEN0024A_v8_architecture_PG.pdf,13.2.1 One-way barriers):
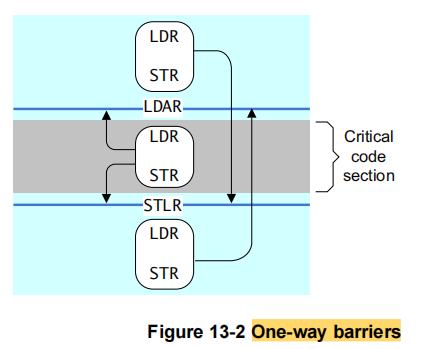
从这张图可以看出它们为什么叫做单边屏障(One-way barriers):它们各自保证一个方向上的顺序,LDAR 和 STLR 一起,保证夹在它们中间的存储操作序列的顺序。
5. 内存屏障的使用
前面讲到了内存屏障的硬件实现和基本原理,以及 ARM 架构下的一些 Linux 相关初始化过程,接下来,我们根据前面的内容来给出一些典型示例,来说明如何试用内存屏障。
5.1 Linux 内存屏障接口
硬件内存屏障接口是和具体硬件架构相关的,经由 include/asm-generic/barrier.h 头文件导出,但具体实现由具体架构代码实现,如 ARM 架构实现在 arch/arm/include/asm/barrier.h 中。这样的组织结构,屏蔽了硬件架构内存屏障接口实现的差异性,可以让屏障 接口用户编写架构无关的代码。当然,有时候为了更好的性能,可能需要直接调用硬件架构屏障指令,后面会给出这样的示例。
Linux 系统的内存屏障接口及它们的变体较多,本文只列举典型的几个接口,而不会列举所有它们的变体。
5.1.1 编译屏障
5.1.1.1 编译器屏障: barrier()
这里只列举 GCC 编译器屏障,其它编译器的实现可能有所不同。
/* include/linux/compiler-gcc.h */
#define barrier() __asm__ __volatile__("": : :"memory")5.1.1.2 READ_ONCE(), WRITE_ONCE(), ACCESS_ONCE()
/* include/linux/compiler.h */
/*
* Prevent the compiler from merging or refetching reads or writes. The
* compiler is also forbidden from reordering successive instances of
* READ_ONCE, WRITE_ONCE and ACCESS_ONCE (see below), but only when the
* compiler is aware of some particular ordering. One way to make the
* compiler aware of ordering is to put the two invocations of READ_ONCE,
* WRITE_ONCE or ACCESS_ONCE() in different C statements.
*
* In contrast to ACCESS_ONCE these two macros will also work on aggregate
* data types like structs or unions. If the size of the accessed data
* type exceeds the word size of the machine (e.g., 32 bits or 64 bits)
* READ_ONCE() and WRITE_ONCE() will fall back to memcpy(). There's at
* least two memcpy()s: one for the __builtin_memcpy() and then one for
* the macro doing the copy of variable - '__u' allocated on the stack.
*
* Their two major use cases are: (1) Mediating communication between
* process-level code and irq/NMI handlers, all running on the same CPU,
* and (2) Ensuring that the compiler does not fold, spindle, or otherwise
* mutilate accesses that either do not require ordering or that interact
* with an explicit memory barrier or atomic instruction that provides the
* required ordering.
*/
#include <asm/barrier.h>
#define __READ_ONCE_SIZE \
({ \
switch (size) { \
case 1: *(__u8 *)res = *(volatile __u8 *)p; break; \
case 2: *(__u16 *)res = *(volatile __u16 *)p; break; \
case 4: *(__u32 *)res = *(volatile __u32 *)p; break; \
case 8: *(__u64 *)res = *(volatile __u64 *)p; break; \
default: \
barrier(); \
__builtin_memcpy((void *)res, (const void *)p, size); \
barrier(); \
} \
})
static __always_inline
void __read_once_size(const volatile void *p, void *res, int size)
{
__READ_ONCE_SIZE;
}
static __always_inline void __write_once_size(volatile void *p, void *res, int size)
{
switch (size) {
case 1: *(volatile __u8 *)p = *(__u8 *)res; break;
case 2: *(volatile __u16 *)p = *(__u16 *)res; break;
case 4: *(volatile __u32 *)p = *(__u32 *)res; break;
case 8: *(volatile __u64 *)p = *(__u64 *)res; break;
default:
barrier();
__builtin_memcpy((void *)p, (const void *)res, size);
barrier();
}
}
#define __READ_ONCE(x, check) \
({ \
union { typeof(x) __val; char __c[1]; } __u; \
if (check) \
__read_once_size(&(x), __u.__c, sizeof(x)); \
else \
__read_once_size_nocheck(&(x), __u.__c, sizeof(x)); \
smp_read_barrier_depends(); /* Enforce dependency ordering from x */ \
__u.__val; \
})
#define READ_ONCE(x) __READ_ONCE(x, 1)
#define WRITE_ONCE(x, val) \
({ \
union { typeof(x) __val; char __c[1]; } __u = \
{ .__val = (__force typeof(x)) (val) }; \
__write_once_size(&(x), __u.__c, sizeof(x)); \
__u.__val; \
})
/*
* Prevent the compiler from merging or refetching accesses. The compiler
* is also forbidden from reordering successive instances of ACCESS_ONCE(),
* but only when the compiler is aware of some particular ordering. One way
* to make the compiler aware of ordering is to put the two invocations of
* ACCESS_ONCE() in different C statements.
*
* ACCESS_ONCE will only work on scalar types. For union types, ACCESS_ONCE
* on a union member will work as long as the size of the member matches the
* size of the union and the size is smaller than word size.
*
* The major use cases of ACCESS_ONCE used to be (1) Mediating communication
* between process-level code and irq/NMI handlers, all running on the same CPU,
* and (2) Ensuring that the compiler does not fold, spindle, or otherwise
* mutilate accesses that either do not require ordering or that interact
* with an explicit memory barrier or atomic instruction that provides the
* required ordering.
*
* If possible use READ_ONCE()/WRITE_ONCE() instead.
*/
#define __ACCESS_ONCE(x) ({ \
__maybe_unused typeof(x) __var = (__force typeof(x)) 0; \
(volatile typeof(x) *)&(x); })
#define ACCESS_ONCE(x) (*__ACCESS_ONCE(x))ACCESS_ONCE() 本质是一个编译屏障,可以参考文章 Linux 编译屏障之 ACCESS_ONCE() 了解关于 ACCESS_ONCE() 的更多细节。
从上面 READ_ONCE()、WRITE_ONCE()、ACCESS_ONCE() 实现看到,它们通过 volatile 关键字 和 编译器屏障 barrier() 来排除编译时的存储访问乱序。 READ_ONCE() 定义中的 smp_read_barrier_depends(),仅 DEC Alpha 架构有实现,其作用是清除变量的 cache 缓存,以保证读操作有序(从 4.1 的表格看到,Alpha 架构存在依赖的读操作可以被 CPU 重排序[Dependent loads can be reordered]),更多细节可参考 https://lkml.org/lkml/2012/2/1/521 。
对这 3 个宏,由于它们每一个都保证和前面的存储访问在编译时保序,所以我们再稍连续多个的组合,保证了最后一个之前一系列存储访问在编译时保序。如:
// ACCESS_ONCE() 之前的存储访问 和 ACCESS_ONCE() 到 WRITE_ONCE()
// 的存储操作不会编译时乱序。
ACCESS_ONCE();
...
READ_ONCE();
...
// ACCESS_ONCE() 前、及 ACCESS_ONCE() 到 WRITE_ONCE() 的存储访问,
// 都不会编译时乱序。
WRITE_ONCE();5.1.1.3 编译屏障小结
barrier()、READ_ONCE()、WRITE_ONCE()、ACCESS_ONCE(),这些编译器屏障(包括它们的变体)是为了防止编译乱序,是一种软件屏障,它们无法阻止硬件实现上带来的乱序。
5.1.2 硬件屏障接口
我们以 ARMv7 和 ARMv8 架构代码为例来进行说明:
/* arch/arm/include/asm/barrier.h */
/* ARMv7 / ARMv8 各自实现的各 内存屏障 接口 */
...
#include <asm-generic/barrier.h>5.1.2.1 mb(), rmb(), wmb()
先来说明下 Linux 内核内存模型对这 3 个接口定义的语义:
mb(): 保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
其产生效果对 Full system 范围内的 Observers 可见。
rmb(): 保证其前后的 [读操作组合: Load-Load] 不会跨越它,
其产生效果对 Full system 范围内的 Observers 可见。
wmb(): 保证其前后的 [写操作组合: Store-Store] 不会跨越它,
其产生效果对 Full system 范围内的 Observers 可见。所谓语义就是Linux 内核内存模型,对这些接口实现提出的必须满足的要求。由于硬件架构的限制,最终实现的不必和Linux 内核内存模型对接口提出的要求完全一样:实现可以是要求的一个超集。
先看 ARMv7 架构下的这 3 个内存屏障接口实现:
/* arch/arm/include/asm/barrier.h */
#if __LINUX_ARM_ARCH__ >= 7
#define isb(option) __asm__ __volatile__ ("isb " #option : : : "memory")
#define dsb(option) __asm__ __volatile__ ("dsb " #option : : : "memory")
#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
...
#elif defined(CONFIG_CPU_XSC3) || __LINUX_ARM_ARCH__ == 6
...
#endif
#ifdef CONFIG_ARM_HEAVY_MB
extern void (*soc_mb)(void);
extern void arm_heavy_mb(void);
#define __arm_heavy_mb(x...) do { dsb(x); arm_heavy_mb(); } while (0)
#else
#define __arm_heavy_mb(x...) dsb(x)
#endif
#if defined(CONFIG_ARM_DMA_MEM_BUFFERABLE) || defined(CONFIG_SMP)
#define mb() __arm_heavy_mb()
#define rmb() dsb()
#define wmb() __arm_heavy_mb(st)
...
#else
...
#endif从 ARMv7 架构的实现我们了解到:
mb(): 实现为 DSB 或者说 DSB SY。
保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
其产生效果对 Full system 范围内的 Observers 可见。
rmb(): 实现为 DSB 或者说 DSB SY。
保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
其产生效果对 Full system 范围内的 Observers 可见。
wmb(): 实现为 DSB ST。
保证其前后的 [写操作组合: Store-Store] 不会跨越它,
其产生效果对 Full system 范围内的 Observers 可见。从上面看到,ARMv7 架构的 mb() 和 rmb() 实现相同,但都满足了 Linux 内核内存模型提出的语义要求,其中 rmb() 是要求的一个超集,这是因为 ARMv7 架构不支持 Load-Load 保序,只能用一个实现为更大的范围。相反,对于 ARMv8 架构,由于它增加了针对 Load 的屏障,所以它的实现就更加精准的匹配 Linux 内核内存模型提出的语义要求:
/* arch/arm64/include/asm/barrier.h */
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
...
#define mb() dsb(sy)
#define rmb() dsb(ld)
#define wmb() dsb(st)从上面看到,ARMv8 架构下,mb() 实现为 DSB SY,rmb() 实现为 DSB LD,wmb() 实现为 DSB ST。
5.1.2.2 smp_mb(), smp_rmb(), smp_wmb()
先来说明下 Linux 内核内存模型对这三个接口定义的语义:
smp_mb(): 保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
其产生的效果对 系统中所有 CPU 核可见,具体范围是 Inner 还是 Outer 由硬件决定。
smp_rmb(): 保证其前后的 [读操作组合: Load-Load] 不会跨越它,
其产生的效果对 系统中所有 CPU 核可见,具体范围是 Inner 还是 Outer 由硬件决定。
smp_wmb(): 保证其前后的 [写操作组合: Store-Store] 不会跨越它,
其产生的效果对 系统中所有 CPU 核可见,具体范围是 Inner 还是 Outer 由硬件决定。这 3 个接口都带有 smp 前缀,这告诉我们,这些接口是针对 SMP 多核架构下 CPU 核之间的。作为系统编程者,如果不编写设备驱动,大多时候就是和它们打交道了。
先看 ARMv7 架构下对这 3 个接口的实现:
/* include/asm-generic/barrier.h */
#ifdef CONFIG_SMP
#ifndef smp_mb
#define smp_mb() __smp_mb()
#endif
#ifndef smp_rmb
#define smp_rmb() __smp_rmb()
#endif
#ifndef smp_wmb
#define smp_wmb() __smp_wmb()
#endif
...
#else
...
#endif/* arch/arm/include/asm/barrier.h */
#define __smp_mb() dmb(ish)
#define __smp_rmb() __smp_mb()
#define __smp_wmb() dmb(ishst)从 ARMv7 架构的实现我们了解到:
smp_mb(): 实现为 DMB ISH。
保证其前后的 [读写操作任意组合: Any-Any] 不会跨越它,
其产生的对 Inner Shareable 范围内的 Observers 可见。
smp_rmb():实现为 DMB ISH。同 smp_mb() 。
smp_wmb():实现为 DMB ISHST。
保证其前后的 [写操作组合: Store-Store] 不会跨越它,
其产生的对 Inner Shareable 范围内的 Observers 可见。由于 Linux 内核内存模型对 smp_mb()、smp_rmb()、smp_wmb() 定义的语义,即产生的效果对系统中所有 CPU 核可见,所以可以推定 ARMv7 架构下所有的 CPU 核位于 Inner Shareable 区域范围。同样,相比 ARMv7,ARMv8 架构下的实现相同接口实现更加精准:
/* arch/arm64/include/asm/barrier.h */
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
...
#define __smp_mb() dmb(ish)
#define __smp_rmb() dmb(ishld)
#define __smp_wmb() dmb(ishst)从上面看到,ARMv8 架构下,smp_mb() 实现为 DMB ISH,smp_rmb() 实现为 DMB ISHLD,smp_wmb() 实现为 DMB ISHST。由此可见,ARMv8 架构下,所有的 CPU 核位于 Inner Shareable 区域范围。
5.1.2.3 smp_load_acquire()/smp_store_release()
/* include/asm-generic/barrier.h */
#ifndef smp_store_release
#define smp_store_release(p, v) __smp_store_release(p, v)
#endif
#ifndef smp_load_acquire
#define smp_load_acquire(p) __smp_load_acquire(p)
#endif先看下 ARMv7 架构下的实现:
/* arch/arm/include/asm/barrier.h */
#ifndef __smp_load_acquire
#define __smp_load_acquire(p) \
({ \
typeof(*p) ___p1 = READ_ONCE(*p); \
compiletime_assert_atomic_type(*p); \
__smp_mb(); \
___p1; \
})
#endif5.2 内存屏障模型示例
接下来,我们简单宽泛的讨论几个常见的内存屏障模型示例。
X = Y = 0;
CPU 1 | CPU 2
-----------|------------------
X = 100; | while (Y == 0);
smp_wmb(); | smp_rmb();
Y = 1; | assert(X == 100);上面 CPU 1 上执行的 smp_wmb() 保证了,从 CPU 2 的角度观察,X = 100; 在 Y = 1; 之前完成。既然如此,那 CPU 2 的执行序列,为什么还要 smp_rmb() 呢?这是因为,CPU 2 有可能因为某些原因(预取、推测执行、乱序执行),导致先执行 X 的读取操作,这样可能读到 X 的初始值 0。在 CPU 2 上加入 smp_rmb() 后,保证了在 CPU 2 上,X 的读取必定是在 Y 变为非 0 值后才执行,这时候由于同时在 CPU 1 上通过 smp_wmb() 保证了,从 CPU 2 的角度观察,Y 变为非 0 值后,X 必定已经变为了 100,有了这些前提,当 CPU 2 读到 Y 变为非 0 值后,CPU 2 上的 X == 100 就必定成立了。
从上面我们可以得出一个简单的结论:对于执行写操作的 CPU,加入写内存屏障是为了向系统中的其它 CPU 保证写操作顺序;对于执行读操作的 CPU,加入读内存屏障是为了在该 CPU 自身上保证读操作的顺序。同时,内存屏障是用在两个或以上有依赖关系的存储操作之间,因为只有多个存储操作之间才存在操作顺序,单独一个在多个 CPU 核上共享的存储空间读写操作,用不上内存屏障操作。
上面的例子,是在一个 CPU 上保证写入顺序,在另一个 CPU 上保证读顺序,下面来看一个在两个 CPU 上要同时保证读、写顺序的例子。
/* 执行序列 1 */
X = Y = 0;
CPU 1 | CPU 2
------------------|------------------
X = 99; |
| Y = 100;
| print(X);
print(Y); |
/* 结果 */
Y == 100, X == 99/* 执行序列 1 */
X = Y = 0;
CPU 1 | CPU 2
------------------|------------------
X = 99; |
print(Y); |
| Y = 100;
| print(X);
/* 结果 */
Y == 0, X == 99/* 执行序列 1 */
X = Y = 0;
CPU 1 | CPU 2
------------------|------------------
| Y = 100;
| print(X);
X = 99; |
print(Y); |
/* 结果 */
Y == 100, X == 0从上面的 3 个执行序列,我们得到了 Y == 100, X == 99、Y == 0, X == 99、Y == 100, X == 0 这 3 个不同的结果。那么,还可能出现其它结果吗?当然是可能的:
/* 执行序列 1 */
X = Y = 0;
CPU 1 | CPU 2
------------------|------------------
print(Y); |
| print(X);
X = 99; |
| Y = 100;
/* 结果 */
Y == 0, X == 0上面的代码,单就某个 CPU 而言,X 和 Y 不存在逻辑上的存储关联依赖,在现在的硬件上,可能出现这种存取顺序,因为它没有违背 3.7 中描述的基本规则:乱序不影响单线程上执行结果。为了对 CPU 1,2 上的读写保序,需要加入内存屏障。
更多关于 Linux 下内存模型,可查看内核文档 Linux kernel memory barriers 。
5.3 Linux 内存屏障实例
5.3.1 编译屏障使用实例
最弱的内存屏障是编译屏障 barrier() ,用来防止编译乱序。主要用于单个 CPU ,保证单个 CPU 上中断代码 和 非中断代码 之间的有序竞争,如 spinlock 的实现代码片段:
/* kernel/locking/qspinlock.c */
/*
* Per-CPU queue node structures; we can never have more than 4 nested
* contexts: task, softirq, hardirq, nmi.
*
* Exactly fits one 64-byte cacheline on a 64-bit architecture.
*
* PV doubles the storage and uses the second cacheline for PV state.
*/
/* per-cpu 的数组 mcs_nodes[MAX_NODES] */
static DEFINE_PER_CPU_ALIGNED(struct mcs_spinlock, mcs_nodes[MAX_NODES]);
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
...
queue:
node = this_cpu_ptr(&mcs_nodes[0]); // node 指向当前 CPU 的 mcs_nodes[MAX_NODES] 数组
idx = node->count++; // count 最大值为 MAX_NODES
tail = encode_tail(smp_processor_id(), idx);
node += idx; // 使用当前 CPU mcs_nodes[MAX_NODES] 的 &mcs_nodes[idx]
/*
* Ensure that we increment the head node->count before initialising
* the actual node. If the compiler is kind enough to reorder these
* stores, then an IRQ could overwrite our assignments.
*/
barrier();
node->locked = 0;
node->next = NULL;
pv_init_node(node); // (1) 修改 node 指向的结构体成员变量值
...
}在这里,由于变量 mcs_nodes[MAX_NODES] 是 per-cpu 的,每个 CPU 只会访问自己的变量空间,所以不用考虑多个 CPU 并行、并发访问 mcs_nodes[MAX_NODES] 的情形。在当前上下文,由于 spin_lock() 已经禁用了当前 CPU 上抢占,唯一的并发场景是在中断中也使用同一 spinlock 的情形,所以这里只要保障 node->count++ 操作在对 node 的初始化操作序列 node->locked = 0; node->next = NULL; pv_init_node(node); 之前完成,那么就不会出现中断中对当前 CPU 数据 mcs_nodes[idx] 的覆写,因为 mcs_nodes[MAX_NODES] 是每 CPU 的数据,所以不会有多个 CPU 对它的并行访问,对它的访问相当于单核场景。所以这里要做的,就是简单的插入一个编译屏障 barrier() 就可以了。如果读者难以能理解这里的场景,那么可以反过来思考:如果对 node 的初始化操作序列 node->locked = 0; 和 node->next = NULL; pv_init_node(node); 先于 node->count++ 发生,会变成怎样?譬如某个线程刚好执行完了 pv_init_node(node); 修改了 node 的值,在 node->count++ 执行前,中断进来了,也使用和线程相同的 spinlock,然后因为线程中 node->count++ 还没执行,所以中断和线程使用同一个 node,然后修改 node 的值,这时候前面线程对 node 的修改值就会被中断中的写操作覆写。如果 保证 node->count++ 执行在前,那么线程和中断修改的将会是不同的 node ,也就不会出现覆写的情况。
5.3.2 硬件内存屏障实例
5.3.2.1 smp_wmb() 实例
/* drivers/irqchip/irq-bcm2836.c */
#ifdef CONFIG_SMP
static void bcm2836_arm_irqchip_send_ipi(const struct cpumask *mask,
unsigned int ipi)
{
int cpu;
void __iomem *mailbox0_base = intc.base + LOCAL_MAILBOX0_SET0;
/*
* Ensure that stores to normal memory are visible to the
* other CPUs before issuing the IPI.
*/
smp_wmb(); /* (1) */
for_each_cpu(cpu, mask) {
writel(1 << ipi, mailbox0_base + 16 * cpu); /* (2) */
}
}
...
#endif上面代码 (1) 处贴出的注释表明,这里的意图是:在当前 CPU 向系统中其它 CPU 发送 IPI 中断信号前,让对内存的写操作被系统中其它 CPU 观察到。我们可以通过两种方法来判定这里应该使用哪个内存屏障接口:
1. 通过 Linux 内核内存屏障模型接口语义
显然 smp_wmb() 的语义满足代码 (1) 处注释的意图。
2. 通过前面总结的内存屏障 3 要素
. 干预的存储相关因素
让存储操作按编程顺序执行,不需要其它保序,所以 DMB 已经足够
. 影响的存储操作序列类型
保证 [写 IPI 寄存器] 和 [之前存储操作] 之间的顺序,也即对 Store-Store 保序,
所以匹配的 <option> 是 ST。
. 影响对哪些范围的 Observers 可见
影响所有的 CPU 可见,从前面知道,ARMv7/ARMv8 的所有 CPU 位于 Inner Shareable
区域范围,所以匹配的 <option> 是 ISH 。
综合起来,应该使用指令 DMB ISHST,这在 ARMv7/ARMv8 下都精确匹配 smp_wmb() 接口。5.3.2.2 smp_rmb() 实例
/* net/netlink/af_netlink.c */
static int netlink_bind(struct socket *sock, struct sockaddr *addr,
int addr_len)
{
bool bound;
...
bound = nlk->bound;
/*
* (1)
* 已经绑定了端口号 nlk->portid,这里是二次绑定,则必须保证两次绑定的端口一致。
* 这里的 smp_rmb() 有什么作用?我们假定有两个 CPU 同时发起了对同一个 netlink
* 套接字的 bind() 调用,CPU 1 已经执行完了 netlink_insert() 中 (2) 处的语句
* nlk_sk(sk)->bound = portid;
* 然后 CPU 2 执行到此处读到 nlk->bound 为非 0 值,意味着的 CPU 1 已经在后面
* netlink_insert() 中 (2) 处设置 nlk->portid 的新值,这里的 smp_rmb() 保证,
* 读 nlk->bound 要在 读 nlk->portid 之前执行,这样才能确保 CPU 2 读到 nlk->bound
* 新值的同时,读到的不是 nlk->portid 缓存的旧值,这与 5.2 小节中示例模型一样。
* 这里的 smp_rmb() 与后面 (2) 处的 smp_wmb() 相呼应。
*/
if (bound) {
/* Ensure nlk->portid is up-to-date. */
smp_rmb();
if (nladdr->nl_pid != nlk->portid)
return -EINVAL;
}
...
/* No need for barriers here as we return to user-space without
* using any of the bound attributes.
*/
/*
* 还没有对 netlink 套接字进行过绑定,首次对端口号 nlk->portid 进行绑定:
* 在 netlink_insert() 中绑定端口号 nlk->portid 后,再通过 nlk->bound 进
* 行标记。
*/
if (!bound) {
err = nladdr->nl_pid ?
netlink_insert(sk, nladdr->nl_pid) :
netlink_autobind(sock);
...
}
}
static int netlink_insert(struct sock *sk, u32 portid)
{
...
lock_sock(sk);
...
nlk_sk(sk)->portid = portid; /* 绑定端口号 */
...
/* We need to ensure that the socket is hashed and visible. */
/*
* (2)
* 确保让其它 CPU 看到:
* 端口号 nlk_sk(sk)->portid 的写 在 标记 nlk_sk(sk)->bound 写之前发生。
*/
smp_wmb();
nlk_sk(sk)->bound = portid; /* 标记 netlink socket 已经绑定端口号 */
err:
release_sock(sk);
...
}这个来自 netlink 的实例,是考虑了多个 CPU 并行调用 bind() 对同一 netlink 套接字绑定的场景。虽然在编程这是一个逻辑错误,但内核必须保证在这种场景下能正确反应。这个实例和 5.2 小节中示例模型一样:
| CPU 1 | CPU 2 |
|---|---|
| STORE nlk->portid | LOAD nlk->bound |
| smp_wmb(); | smp_rmb(); |
| STORE nlk->bound | LOAD nlk->portid |
netlink_insert() 中的 smp_wmb() 对所有 CPU 保证:对 nlk->portid 的写入,先于对 nlk->bound 写入发生;而 netlink_bind() 去观察(通过读操作)这两个变量,要按照相反的顺序:先读 nlk->bound 后读 nlk->portid,这样一旦读到 nlk->bound 为非 0 值,就可以认为 nlk->portid 已经被写入了,这是 smp_wmb() 保证的。可能有读者存在疑问,既然 smp_wmb() 保证了所有 CPU 观察到先 nlk->portid 后 nlk->bound 的写入顺序,为什么还需要在读的时候加入 smp_rmb() ?假设 CPU 2 在执行 netlink_bind() 代码的时候,对 nlk->bound 和 nlk->portid 读操作乱序了,先读 nlk->portid 后读 nlk->bound,而且刚好在读 nlk->portid 的时候,CPU 1 上netlink_insert() 中对 nlk->portid 写入操作还没发生,这样在如果 CPU 2 读到 nlk->bound 为非 0 值,语句 if (nladdr->nl_pid != nlk->portid) 中的 nlk->portid 使用的预先读取的旧值,就会出现逻辑错误。
用通俗的话来讲,smp_wmb() 是做给别人看的,smp_rmb() 是去看别人怎么做的。所谓观察?其实就是去读。观察(读操作)要以正确的顺序去观察(读):先观察(读)谁,后观察(读)谁,这个就靠 smp_rmb() 来保障了。
观察内核代码中更多的 smp_rmb() 的使用场景,会发现一个规律:smp_rmb() 的总是对应一个 smp_wmb(),一如上面的例子。这是为什么?试想一下,假设两个存在逻辑关系的变量(如上面的 nlk->portid 和 nlk->bound),如果没有任何地方对它们进行修改,那意味着它们的值用于不会变化,那么,这时候不管读到的是寄存器里面缓存的值,还是 cache 中的值,以及它们谁先被读取,那又有什么影响呢?毕竟它们的值一直都维持不变。不同于 smp_rmb(),smp_wmb() 是可以单独存在的。
另外,我们还发现一点,上面的 netlink 例子,smp_wmb() 出现在锁操作 lock_sock() 和 release_sock() 之间,前面提到锁会带有内存屏障,那么为什么处于临界区内的代码还要使用内存屏障保序?因为锁只保证了临界区内代码的存储访问和其前后内存访问之间不会出现乱序,而不保证临界区内内存访问彼此之间的乱序。但话说回来,如果 netlink_bind() 也和 netlink_insert() 一样,对 nlk->portid 和 nlk->bound 的访问也持锁操作,那这个示例场景下的两个内存屏障 smp_rmb() 和 smp_wmb() 都不需要了。
5.3.2.3 其它类型实例
后续笔者有时间再补充(待续)。
6. 结语
虽然本文用了很长的篇幅,试图展示内存屏障硬件基础、工作原理、使用方法的方方面面,但限于笔者的能力和水平,错漏之处在所难免。内存屏障一直是系统编程里面的难点,在很多场景下,不使用或不能正确使用内存屏障,难以编写出正确工作的代码。在系统编程里,我们应该学会并正确使用它。
笔者认为,学习内存屏障,任何时候,硬件架构官方文档仍然是第一手最应该首先去学习的资料。另外,Linux 内核文档 Linux kernel memory barriers 也是必须去学习的。硬件架构官方文档揭示内存屏障的底层支持和实现,而 Linux 内核内存屏障文档给出了内存屏障的接口和其语义,二者缺一不可。建议先学习硬件架构内存屏障相关知识,再去学习 Linux 内核文档内存屏障部分,否则可能会看的一头雾水,甚至打击你学些的信心。《计算器体系结构:量化研究方法》和 《perfbook.2018.12.08a.pdf》 也是不错的学习资料。
7. 参考资料
[1] 《ARM Architecture Reference Manual.pdf》
[2] 《DDI0406C_d_armv7ar_arm.pdf》
[3] 《DDI0487A_j_armv8_arm.pdf》
[4] 《DEN0024A_v8_architecture_PG.pdf》
[5] Memory access ordering - an introduction
[6] Memory access ordering part 2: Barriers and the Linux kernel
[7] Memory access ordering part 3: Memory access ordering in the Arm Architecture
[8] https://developer.arm.com/documentation/100941/0101/Barriers
[9] https://developer.arm.com/documentation/den0024/a/Memory-Ordering/Barriers/One-way-barriers
[10] Linux kernel memory barriers
[11] Who’s afraid of a big bad optimizing compiler?
[12] https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0124r5.html
[13] https://en.wikipedia.org/wiki/Consistency_model#Types
[14] https://en.wikipedia.org/wiki/Memory_ordering#Runtime_memory_ordering
[15] Memory Barriers Are Like Source Control Operations
[16] https://tinylab.org/memory-ordering-part2/
[17] 原理和实战解析Linux中如何正确地使用内存屏障
[18] 一、barrier指令DSB,DMB,ISB,fence——内存屏障,指令屏障
[19] I/O ordering 學習紀錄















 4462
4462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









