







1 抽象内存模型
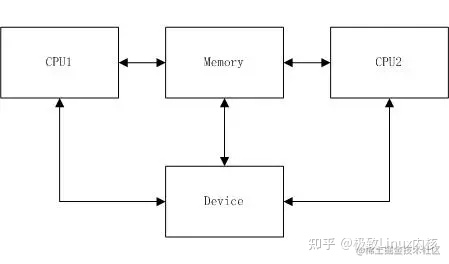
1.1 指令重排
每个 CPU 运行一个程序,程序的执行产生内存访问操作。在这个抽象 CPU 中,内存 操作的顺序是松散的,CPU 假定进程间不依靠内存直接通信,在不改变程序执行 结果 的推测下由自己方便的顺序执行内存访问操作。
例如,考虑下面的执行过程:
{ A = 1 b = 2}
CPU 1 |
CPU 2 |
A=3; |
x=B; |
B=4; |
y=A; |
这有 24 中内存访问操作的组合,每种组合都有可能出现:
STORE A=3, STORE B=4, y=LOAD A->3, x=LOAD B->4
STORE A=3, STORE B=4, x=LOAD B->4, y=LOAD A->3
STORE A=3, y=LOAD A->3, STORE B=4, x=LOAD B->4
STORE A=3, y=LOAD A->3, x=LOAD B->2, STORE B=4
STORE A=3, x=LOAD B->2, STORE B=4, y=LOAD A->3
STORE A=3, x=LOAD B->2, y=LOAD A->3, STORE B=4
STORE B=4, STORE A=3, y=LOAD A->3, x=LOAD B->4
STORE B=4, ...
...从而产生 4 种结果:
x == 2, y == 1
x == 2, y == 3
x == 4, y == 1
x == 4, y == 3更残酷的是,一个 CPU 已经提交的 store 操作,另一个 CPU 可能不会感知到,从而 load 操作取到旧的值。
比如:
{A = 1, B = 2, C = 3, P = &A, Q = &C}
CPU 1 |
CPU 2 |
B=4; |
Q=p; |
P=&B; |
D=*Q; |
可以产生 4 种结果:
(Q == &A) and (D == 1)
(Q == &B) and (D == 2)
(Q == &B) and (D == 4)1.2 设备操作
一些设备将自己的控制接口映射成一个内存地址,访问这些地址的指令顺序是极重要 的。比如一个拥有一系列内部寄存器的网卡,可以通过一个地址寄存器 (A) 和一个数 据寄存器 (D) 访问它们。如果要访问内部寄存器 5 ,则使用下面的代码:
*A = 5;
x = *D;但这个代码可能生成以下两种执行顺序:
STORE *A = 5, x = LOAD *D
x = LOAD *D, STORE *A = 51.3 合并内存访问
CPU 还可能将内存操作合并。比如
X = *A; Y = *(A + 4);可能会生成下面任何一种执行顺序:
X = LOAD *A; Y = LOAD *(A + 4);
Y = LOAD *(A + 4); X = LOAD *A;
{X, Y} = LOAD {*A, *(A + 4) };而
*A = X; *(A + 4) = Y;则可能生成下面任何一种执行:
STORE *A = X; STORE *(A + 4) = Y;
STORE *(A + 4) = Y; STORE *A = X;
STORE {*A, *(A + 4) } = {X, Y};1.4 最小保证
可以期望 CPU 提供了一些最小保证,不满足最小保证的 CPU 都是假的 CPU。
有依赖关系的内存访问操作是有顺序的。也就是说:
Q = READ_ONCE(P); smp_read_barrier_depends(); D = READ_ONCE(*Q);总是在 CPU 中以这样的顺序执行:
Q = LOAD P, D = LOAD *Qsmp_read_barrier_depends() 只在 DEC Alpha 中有用,READ_ONCE 的作用在 这里 提到。
在一个 CPU 中的覆盖 load-store 操作是有顺序的。比如
a = READ_ONCE(*X); WRITE_ONCE(*X, b);总是以这样的顺序执行:
a = LOAD *X, STORE *X = b而
WRITE_ONCE(*X, c); d = READ_ONCE(*X);总是以下面的顺序执行:
STORE *X = c, d = LOAD *X最小保证不适用于位图。假设我们有一个长度为 8 的位图,CPU 1 要将 1 位置 1, CPU 2 要将 2 位 置 1:
{ A = 0 }
CPU 1 |
CPU 2 |
A = A OR (1 << 1) |
A = A OR (1 << 2) |
可能有三种个结果:
A = 2
A = 4
A = 62 内存屏障
正如之前看到的,内存访问操作的顺序是随机的,这会造成 CPU 间通信或者 I/O 问 题。需要一种介入保证指令的顺序以获得期望结果。内存屏障就是这样一种介入。
2.1 4+2种内存屏障
写屏障
写屏障保证任何出现在写屏障之前的 STORE 操作先于出现在写屏障之后的任何 STORE 操作执行。
写屏障一般与读屏障或者数据依赖屏障配合使用。
数据依赖屏障
数据依赖屏障是一个弱的读屏障。用于两个读操作之间,且第二个读操作依赖第一个 读操作(比如第一个读操作获得第二个读操作所用的地址)。读屏障用于保证第二个读 操作的目标已经被第一个读操作获得。
数据依赖屏障只能用于确实存在数据依赖的地方。
读屏障
读屏障保证任何出现在读屏障之前的 LOAD 操作先于出现在读屏障之后的任何 LOAD 操作执行。
读屏障一般和写屏障配合使用。
一般内存屏障
一般内存屏障保证所有出现在屏障之前的内存访问 (LOAD 和 STORE) 先于出现在屏障 之后的内存访问执行。
此外还有两种不常见的内存屏障
ACQUIRE 操作
保证出现在 ACQUIRE 之后的操作确实在 ACQUIRE 之后执行。而出现在 ACQUIRE 之前 的内存操作可能执行于 ACQUIRE 之后。
ACQUIRE 和 RELEASE 配合使用。
RELEASE 操作
保证出现在 RELEASE 之前的操作确实在 RELEASE 之前执行。而出现在 RELEASE 之后 的内存操作可能执行于 RELEASE 之前。
2.2 数据依赖屏障
数据依赖屏障需要并不总是那么明显。举个例子。
{ A = 1, B = 2, C = 3, P = &A, Q = &C }
CPU 1 |
CPU 2 |
B=4 |
|
WRITE_ONCE(P, &B) |
|
Q=READ_ONCE(P) |
|
D=*Q |
这个例子中,D 要么是 &A, 要么是 &B:
(Q == &A) implies (D == 1)
(Q == &B) implies (D == 4)但是,CPU 2 察觉到的 P 的更新可能比先于 B 的更新被察觉,这导致下面的结果:
(Q == &B) and (D == 2)现实世界中有 CPU 是这么表现的,比如 DEC Alpha。要获得想要的结果,需要一个数 据依赖屏障:
CPU 1 |
CPU 2 |
B=4 |
|
WRITE_ONCE(P, &B) |
|
Q=READ_ONCE(P) |
|
D=*Q |
数据依赖凭证保证了只会出现两种可预期的结果。
数据依赖屏障也可以序列化依赖前一指令的写操作:
{ A = 1, B = 2, C = 3, P = &A, Q = &C }
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









