







什么是Ceph?
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式的存储系统。Ceph 独一无二地用统一的系统提供了对象、块、和文件存储功能,它可靠性高、管理简便、并且是开源软件。 Ceph 的强大足以改变贵公司的 IT 基础架构、和管理海量数据的能力。Ceph 可提供极大的伸缩性——供成千用户访问 PB 乃至 EB 级的数据。 Ceph 节点以普通硬件和智能守护进程作为支撑点, Ceph 存储集群组织起了大量节点,它们之间靠相互通讯来复制数据、并动态地重分布数据。
1.ceph的组件和功能
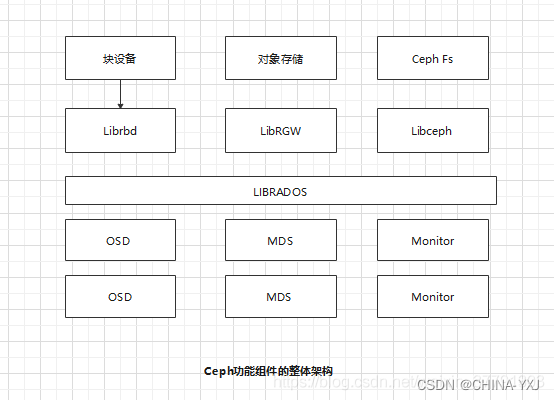
(1)Ceph的核心组件
Ceph的核心组件包括Ceph OSD、Ceph Monitor和Ceph MDS三大组件。
Ceph OSD:OSD的英文全称是Object Storage Device,它的主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor。一般情况下一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,当然一个分区也可以成为一个OSD。
Ceph Monitor:由该英文名字我们可以知道它是一个监视器,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。
Ceph MDS:全称是Ceph MetaData Server,主要保存的文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
查看各种Map的信息可以通过如下命令:ceph osd(mon、pg) dump
(2)Ceph功能特性
Ceph可以同时提供对象存储RADOSGW(Reliable、Autonomic、Distributed、Object Storage Gateway)、块存储RBD(Rados Block Device)、文件系统存储Ceph FS(Ceph File System)3种功能,由此产生了对应的实际场景,本节简单介绍如下。
RADOSGW功能特性基于LIBRADOS之上,提供当前流行的RESTful协议的网关,并且兼容S3和Swift接口,作为对象存储,可以对接网盘类应用以及HLS流媒体应用等。
RBD(Rados Block Device)功能特性也是基于LIBRADOS之上,通过LIBRBD创建一个块设备,通过QEMU/KVM附加到VM上,作为传统的块设备来用。目前OpenStack、CloudStack等都是采用这种方式来为VM提供块设备,同时也支持快照、COW(Copy On Write)等功能。
Ceph FS(Ceph File System)功能特性是基于RADOS来实现分布式的文件系统,引入了MDS(Metadata Server),主要为兼容POSIX文件系统提供元数据。一般都是当做文件系统来挂载。
2.ceph的数据读写流程
Ceph的读/写操作采用Primary-Replica模型,客户端只向Object所对应OSD set的Primary OSD发起读/写请求,这保证了数据的强一致性。当Primary OSD收到Object的写请求时,它负责把数据发送给其他副本,只有这个数据被保存在所有的OSD上时,Primary OSD才应答Object的写请求,这保证了副本的一致性。
写入数据
这里以Object写入为例,假定一个PG被映射到3个OSD上。Object写入流程如图所示。
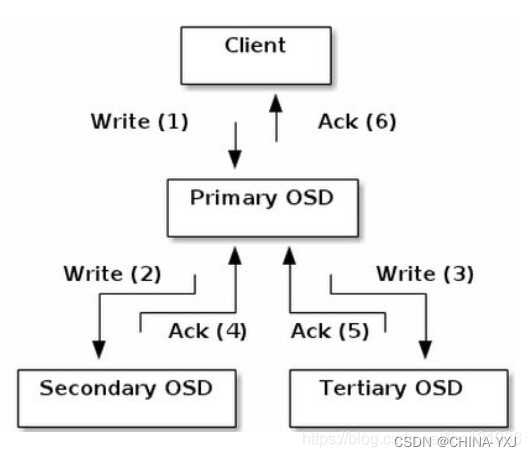
当某个客户端需要向Ceph集群写入一个File时,首先需要在本地完成前面所述的寻址流程,将File变为一个Object,然后找出存储该Object的一组共3个OSD,这3个OSD具有各自不同的序号,序号最靠前的那个OSD就是这一组中的Primary OSD,而后两个则依次Secondary OSD和Tertiary OSD。
找出3个OSD后,客户端将直接和Primary OSD进行通信,发起写入操作(步骤1)。 Primary OSD收到请求后,分别向Secondary OSD和Tertiary OSD发起写人操作(步骤2和步骤3)。当Secondary OSD和Tertiary OSD各自完成写入操作后,将分别向Primary OSD发送确认信息(步骤4和步骤5)。当Primary OSD确认其他两个OSD的写入完成后,则自己也完成数据写入,并向客户端确认Object写入操作完成(步骤6)。
之所以采用这样的写入流程,本质上是为了保证写入过程中的可靠性,尽可能避免出现数据丢失的情况。同时,由于客户端只需要向Primary OSD发送数据,因此在互联网使用场景下的外网带宽和整体访问延迟又得到了一定程度的优化。
当然,这种可靠性机制必然导致较长的延迟,特别是,如果等到所有的OSD都将数据写入磁盘后再向客户端发送确认信号,则整体延迟可能难以忍受。因此, Ceph可以分两次向客户端进行确认。当各个OSD都将数据写入内存缓冲区后,就先向客户端发送一次确认,此时客户端即可以向下执行。待各个OSD都将数据写入磁盘后,会向客户端发送一个最终确认信号,此时客户端可以根据需要删除本地数据。
读取数据
如果需要读取数据,客户端只需完成同样的寻址过程,并直接和Primary OSD联系。在目前的Ceph设计中,被读取的数据默认由Primary OSD提供,但也可以设置允许从其他OSD中获取,以分散读取压力从而提高性能。
3.使用ceph-deploy安装一个最少三个节点的ceph集群 推荐3个或以上的磁盘作为专用osd
首先准备基础环境,我的三台虚拟机全部使用最小安装
ceph1:192.168.6.145 每台主机准备四块磁盘,sda作为系统盘,其它三块作为ceph的OSD服务磁盘使用
ceph2:192.168.6.146
ceph3:192.168.6.147
systemctl stop firewalld
systemctl disable firewalld //关闭防火墙并设置开机不启动
vim /etc/selimux/config
selinux=disabled //更改selinux的模式
hostnamectl set-hostname ceph1 //三台主机名分别设置为ceph1-3,注意这里使用短主机名
然后准备安装ceph集群的环境变量
以下配置三台机器都需要设置
vim /openrc //编辑一个文本
export username="ceph-admin" //安装时使用ceph-admin一般用户安装,这里设置一个变量方便后面调用
export passwd="ceph-admin"
export node1="ceph1" //设置主机名的环境变量
export node2="ceph2"
export node3="ceph3"
export node1_ip="192.168.6.145" //设置主机ip地址的环境变量
export node2_ip="192.168.6.146"
export node3_ip="192.168.6.147"
下载ceph的rpm源
wget -O /etc/yum.repos.d/ceph.repo https://raw.githubusercontent.com/aishangwei/ceph-
demo/master/ceph-deploy/ceph.repo
配置ntp
yum install -y ntp ntpdate
ntpdate cn.ntp.org.cn
systemctl restart ntpd
systemctl enable ntpd
systemctl enable ntpdate
创建部署用户
useradd ${username} //创建ceph-admin用户,用于集群部署
echo "${passwd}" | passwd --stdin ${username}
echo "${username} ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph-admin //设置ceph-admin执 行特殊命令时的sudo权限
chmod 0440 /etc/sudoers.d/ceph-admin 更该文件权限
配置三台主机的主机名解析
vim /etc/hosts
192.168.6.145 ceph1
192.168.6.146 ceph2
192.168.6.147 ceph3
配置三台主机的ssh免密钥登录
su - ceph-admin
ssh-keygen
ssh-copy-id ceph-admin@ceph1
ssh-copy-id ceph-admin@ceph2
ssh-copy-id ceph-admin@ceph3
使用ceph-deploy部署集群
安装ceph-deploy
sudo yum install -y ceph-deploy python-pip //注意python-pip需要使用epel源,提前将epel源配置好
mkdir my-cluster //创建安装目录
cd my-cluster
进行节点部署
ceph-deploy new ceph1 ceph2 ceph3 //这里务必要保证三台主机的网络是互通的
安装完之后my-cluster目录下面会生成三个文件
ceph.conf
ceph-deploy-ceph.log
ceph.mon.keyring
编辑ceph.conf配置文件,在最后添加一下信息
sudo vim ~/my-cluster/ceph.conf
public network = 192.168.6.0/24
cluster network = 192.168.6.0/24
安装ceph包
sudo yum install -y ceph ceph-radosgw //三个节点上都要安装,这两个包需要使用epel源,
如果出现“RuntimeError: Failed to execute command: ceph
–version”报错,是因为服务器网络问题导致,下载ceph安装包速度太慢,达到5分钟导致超时,可以重复执行,或者单独在所有节点执行yum -y install ceph即可
两外两个节点需要配置好epel源
注意事项:
这里的yum源是确定了ceph的版本,在源中的baseurl项中rpm-nautilus即代表着是ceph的nautilus版本的rpm包(nautilus是ceph的14.x版本)如果需要安装其他版本,还需要替换为其他版本号,12.x版本是luminous,13.x版本是rpm-mimic。详情可以去ceph官方源中查看:https://download.ceph.com/
配置初始的monitor并收集所有密钥:
ceph-deploy mon create-initial
把配置信息拷贝到各节点
ceph-deploy admin ceph1 ceph2 ceph3
配置osd
使用for循环语句执行(也可以写到文本中做成脚本执行)
for dev in /dev/sdb /dev/sdc /dev/sdd //注意磁盘名称,可以使用lsblk命令进行查看
do
ceph-deploy disk zap ceph1 $dev
ceph-deploy osd create ceph1 --data $dev
ceph-deploy disk zap ceph2 $dev
ceph-deploy osd create ceph2 --data $dev
ceph-deploy disk zap ceph3 $dev
ceph-deploy osd create ceph3 --data $dev
done
配置完OSD之后,部署mgr用于监控整个集群
ceph-deploy mgr create ceph1 ceph2 ceph3
开启dashboard模块,启用浏览器界面
在开启dashboard模块之前要注意,因为我们是使用ceph-admin一般用户进行安装,所有无法调用/etc/ceph/下面的文件,将/etc/ceph目录下面的文件属主属组全部更改为ceph-admin
sudo chown -R ceph-admin /etc/ceph
然后加载dashboard模块
ceph mgr module enable dashboard
加载完模块之后查看7000号端口号是否正常监听
ss -ntl
如果查看集群状态为“HEALTH_WARN mon is allowing insecure global_id
reclaim”,是因为开启了不安全的模式,将之禁用掉即可:
打开浏览器输入192.168.6.145:7000查看ceph存储集群整体状况
















 7461
7461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









