






 本文介绍了如何使用Python库mpi4py进行MPI并行编程,包括mpi4py的安装、基本概念、点对点通信、集体通信(广播、散射、搜集、减少)等,并给出了相关代码示例。
本文介绍了如何使用Python库mpi4py进行MPI并行编程,包括mpi4py的安装、基本概念、点对点通信、集体通信(广播、散射、搜集、减少)等,并给出了相关代码示例。
mpi4py的安装
我们将使用 MPI for Python 包mpi4py。如果您有一个干净的geo_scipy环境,如本网站上 Ryan 的 Python 安装说明所述,您应该能够使用 conda 安装它而不会出现任何问题。首先要做的是打开终端外壳并激活geo_scipy:
source activate geo_scipy(或者您可以从 Anaconda 应用程序启动它)
然后安装mpi4py:
conda install mpi4py什么是 mpi4py?
MPI for Python 为 Python 语言提供 MPI 绑定,允许程序员利用多处理器计算系统。mpi4py 是在 MPI-1/2 规范之上构建的,并提供了一个紧密遵循 MPI-2 C++ 绑定的面向对象的接口。
mpi4py 的文档
mpi4py 的文档可以在这里找到: https ://mpi4py.scipy.org/
但是,它仍在进行中,其中大部分假设您已经熟悉 MPI 标准。因此,您可能还需要查阅 MPI 标准文档:
MPI 文档仅涵盖 C 和 Fortran 实现,但 Python 语法的扩展很简单,并且在大多数情况下比等效的 C 或 Fortran 语句要简单得多。
另一个有用的寻求帮助的地方是 mpi4py 的 API 参考:
https://mpi4py.scipy.org/docs/apiref/mpi4py.MPI-module.html
特别是,Class Comm 部分列出了您可以与 communicator 对象一起使用的所有方法:
https://mpi4py.scipy.org/docs/apiref/mpi4py.MPI.Comm-class.html
## 使用 MPI 运行 Python 脚本
使用 MPI 命令的 Python 程序必须使用命令提供的 MPI 解释器运行mpirun。在某些系统上,改为调用此命令,mpiexec并且 mpi4py 似乎包括两者。
通过使用Unix comamnd 检查mpirun您的 anaconda 目录中的geo_scipy以确保您的环境正确:which
$ which mpirun
/anaconda/envs/geo_scipy/bin/mpirun您可以使用以下命令运行 MPI Python 脚本mpirun:
mpirun -n 4 python script.py这里-n 4告诉 MPI 使用四个进程,这是我笔记本电脑上的内核数。然后我们告诉 MPI 运行名为script.py.
如果您在台式计算机上运行此程序,则应将-n参数调整为系统上的内核数或作业所需的最大进程数,以较小者为准。或者在大型集群上,您可以指定程序需要的内核数或特定集群上可用的最大内核数。
沟通者和等级
我们的第一个 Python 示例的 MPI 将简单地从 mpi4py 包中导入 MPI,创建一个通信器并获取每个进程的等级:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
print('My rank is ',rank)将此保存到文件调用中comm.py,然后运行它:
mpirun -n 4 python comm.py在这里,我们使用了名为 的默认通信MPI.COMM_WORLD器,它由所有处理器组成。对于许多 MPI 代码,这是您需要的主要通信器。但是,您可以使用MPI.COMM_WORLD. 有关更多信息,请参阅文档。
点对点通信
现在我们将研究如何将数据从一个进程传递到另一个进程。这是一个非常简单的示例,我们将字典从进程 0 传递到进程 1:
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = {'a': 7, 'b': 3.14}
comm.send(data, dest=1)
elif rank == 1:
data = comm.recv(source=0)
print('On process 1, data is ',data)这里我们发送了一个字典,但你也可以发送一个带有类似代码的整数:
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
idata = 1
comm.send(idata, dest=1)
elif rank == 1:
idata = comm.recv(source=0)
print('On process 1, data is ',idata)请注意如何comm.send和comm.recv有小写s和r。
现在让我们看一个更复杂的例子,我们发送一个 numpy 数组:
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
# in real code, this section might
# read in data parameters from a file
numData = 10
comm.send(numData, dest=1)
data = np.linspace(0.0,3.14,numData)
comm.Send(data, dest=1)
elif rank == 1:
numData = comm.recv(source=0)
print('Number of data to receive: ',numData)
data = np.empty(numData, dtype='d') # allocate space to receive the array
comm.Recv(data, source=0)
print('data received: ',data)请注意用于发送和接收 numpy 数组的comm.Send和如何comm.Recv使用大写S和R.
集体沟通
广播:
广播接受一个变量并将它的精确副本发送到通信器上的所有进程。这里有些例子:
广播字典:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = {'key1' : [1,2, 3],
'key2' : ( 'abc', 'xyz')}
else:
data = None
data = comm.bcast(data, root=0)
print('Rank: ',rank,', data: ' ,data)您可以使用该方法广播一个 numpy 数组Bcast(再次注意大写B)。在这里,我们将修改上面的点对点代码,改为将数组广播data到通信器中的所有进程(而不仅仅是从进程 0 到 1):
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
# create a data array on process 0
# in real code, this section might
# read in data parameters from a file
numData = 10
data = np.linspace(0.0,3.14,numData)
else:
numData = None
# broadcast numData and allocate array on other ranks:
numData = comm.bcast(numData, root=0)
if rank != 0:
data = np.empty(numData, dtype='d')
comm.Bcast(data, root=0) # broadcast the array from rank 0 to all others
print('Rank: ',rank, ', data received: ',data)散射:
Scatter 获取一个数组并将其连续部分分布在通信器的行列中。这是来自 http://mpitutorial.com 的图片,它说明了广播和分散之间的区别:
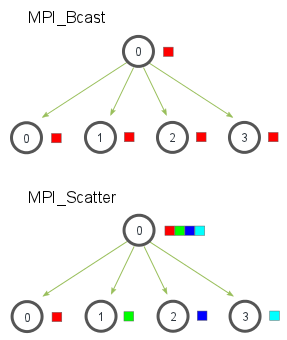
现在让我们尝试一个例子。
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
size = comm.Get_size() # new: gives number of ranks in comm
rank = comm.Get_rank()
numDataPerRank = 10
data = None
if rank == 0:
data = np.linspace(1,size*numDataPerRank,numDataPerRank*size)
# when size=4 (using -n 4), data = [1.0:40.0]
recvbuf = np.empty(numDataPerRank, dtype='d') # allocate space for recvbuf
comm.Scatter(data, recvbuf, root=0)
print('Rank: ',rank, ', recvbuf received: ',recvbuf)在此示例中,排名为 0 的进程创建了数组data。由于这只是一个玩具示例,我们制作data了一个简单的 linspace 数组,但在研究代码中,数据可能是从文件中读取的,或者是由工作流的前一部分生成的。 data然后使用 分散到所有等级(包括等级 0)comm.Scatter。请注意,我们首先必须初始化(或分配)接收缓冲区数组recvbuf。
搜集:
一个反面scatter是 一个gather,它获取分布在等级中的数组的子集,并将它们收集回完整的数组中。这是来自 http://mpitutorial.com 的图像,它以图形方式说明了这一点:
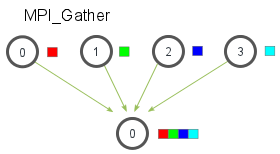
例如,这里有一个与上面的分散示例相反的代码。
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
numDataPerRank = 10
sendbuf = np.linspace(rank*numDataPerRank+1,(rank+1)*numDataPerRank,numDataPerRank)
print('Rank: ',rank, ', sendbuf: ',sendbuf)
recvbuf = None
if rank == 0:
recvbuf = np.empty(numDataPerRank*size, dtype='d')
comm.Gather(sendbuf, recvbuf, root=0)
if rank == 0:
print('Rank: ',rank, ', recvbuf received: ',recvbuf)减少:
MPreduce操作从每个进程的数组中获取值,并将它们简化为根进程上的单个结果。这本质上就像从每个进程向根进程发送一个有点复杂的命令,然后让根进程执行归约操作。值得庆幸的是,MPIreduce 用一个简洁的命令完成了所有这些工作。
对于 numpy 数组,语法是
~~~python comm.Reduce(send_data, recv_data, op=, root=0) ~~~哪里send_data是通信器上所有进程发送的数据,recv_data是根进程上将接收所有数据的数组。请注意,发送和接收数组具有相同的大小。里面的所有数据副本 send_data都会按照指定的减少<operation>。一些常用的操作是: - MPI_SUM - 对元素求和。- MPI_PROD - 将所有元素相乘。- MPI_MAX - 返回最大元素。- MPI_MIN - 返回最小元素。
以下是来自 http://mpi_thttp://mpitutorial.com 的一些更有用的图像,它们以图形方式说明了 reduce 步骤:
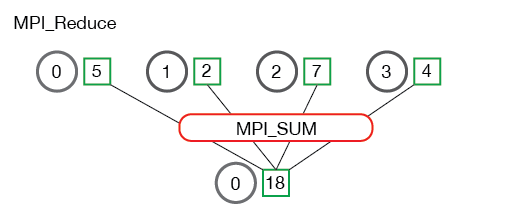
这是一个代码示例:
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# Create some np arrays on each process:
# For this demo, the arrays have only one
# entry that is assigned to be the rank of the processor
value = np.array(rank,'d')
print(' Rank: ',rank, ' value = ', value)
# initialize the np arrays that will store the results:
value_sum = np.array(0.0,'d')
value_max = np.array(0.0,'d')
# perform the reductions:
comm.Reduce(value, value_sum, op=MPI.SUM, root=0)
comm.Reduce(value, value_max, op=MPI.MAX, root=0)
if rank == 0:
print(' Rank 0: value_sum = ',value_sum)
print(' Rank 0: value_max = ',value_max)
















 4026
4026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









