







 本文详细介绍了YOLOv2中使用的Darknet-19网络结构,包括调整输入尺寸为416x416以保证奇数网格数,以及预训练、finetune和模型转换的过程。作者解释了网络结构的每一层及其功能,最后提到YOLOv2的训练策略。
本文详细介绍了YOLOv2中使用的Darknet-19网络结构,包括调整输入尺寸为416x416以保证奇数网格数,以及预训练、finetune和模型转换的过程。作者解释了网络结构的每一层及其功能,最后提到YOLOv2的训练策略。
上一篇文章主要是写了一些 YOLOv1 的原版网络结构,这篇文章一样,目标是还原论文中原版的 YOLOv2 的网络结构,而不是后续各种魔改的版本。
YOLOv2 和 YOLOv1 不一样,开始使用 Darknet-19 来作为 backbone 了。论文中给出了 Darknet-19 的网络结构细节图。但是表格中的输入甚至不是 448x448x3 的,而是 224x224x3 的,但是论文中特别提到:
We also shrink the network to operate on 416 input images instead of 448×448. We do this because we want an odd number of locations in our feature map so there is a single center cell.
就是说为了让网格为奇数,中心点只存在一个中心网格,就将输入的尺寸设定为了 416x416x3。

按照 416x416x3 的网络输入的话,backbone Darknet-19 的网络结构参数示意图如下面表格所示。
| layer | output size | module | |
|---|---|---|---|
| input | 416x416x3 | ||
| 1 | 416x416x32 | Conv 3x3x32, s-1, p-1 | backbone: Darknet-19 |
| 208x208x32 | Maxpool 2x2, s-2, p-0 | backbone: Darknet-19 | |
| 2 | 208x208x64 | Conv 3x3x64, s-1, p-1 | backbone: Darknet-19 |
| 104x104x64 | Maxpool 2x2, s-2, p-0 | backbone: Darknet-19 | |
| 3 | 104x104x128 | Conv 3x3x128, s-1, p-1 | backbone: Darknet-19 |
| 4 | 104x104x64 | Conv 1x1x64, s-1, p-0 | backbone: Darknet-19 |
| 5 | 104x104x128 | Conv 3x3x128, s-1, p-1 | backbone: Darknet-19 |
| 52x52x128 | Maxpool 2x2, s-2, p-0 | backbone: Darknet-19 | |
| 6 | 52x52x256 | Conv 3x3x256, s-1, p-1 | backbone: Darknet-19 |
| 7 | 52x52x128 | Conv 1x1x128, s-1, p-0 | backbone: Darknet-19 |
| 8 | 52x52x256 | Conv 3x3x256, s-1, p-1 | backbone: Darknet-19 |
| 26x26x256 | Maxpool 2x2, s-2, p-0 | backbone: Darknet-19 | |
| 9 | 26x26x512 | Conv 3x3x512, s-1, p-1 | backbone: Darknet-19 |
| 10 | 26x26x256 | Conv 1x1x256, s-1, p-0 | backbone: Darknet-19 |
| 11 | 26x26x512 | Conv 3x3x512, s-1, p-1 | backbone: Darknet-19 |
| 12 | 26x26x256 | Conv 1x1x256, s-1, p-0 | backbone: Darknet-19 |
| 13 | 26x26x512 | Conv 3x3x512, s-1, p-1 | backbone: Darknet-19 |
| 13x13x512 | Maxpool 2x2, s-2, p-0 | backbone: Darknet-19 | |
| 14 | 13x13x1024 | Conv 3x3x1024, s-1, p-1 | backbone: Darknet-19 |
| 15 | 13x13x512 | Conv 1x1x512, s-1, p-0 | backbone: Darknet-19 |
| 16 | 13x13x1024 | Conv 3x3x1024, s-1, p-1 | backbone: Darknet-19 |
| 17 | 13x13x512 | Conv 1x1x512, s-1, p-0 | backbone: Darknet-19 |
| 18 | 13x13x1024 | Conv 3x3x1024, s-1, p-1 | backbone: Darknet-19 |
因为要作为 YOLOv2 的 backbone,所以要将后面的一个 1x1 的卷积层(相当于 FC 层)和后续的 softmax 去掉。所以实际上 Darknet-19 作为 backbone 在 YOLOv2 里只有 18 个卷积层。

可以看到上面 YOLOv2 的 backbone 部分只有 Darknet-19 的 前 18 个卷积层。
- Pass Through 层,感觉和 YOLOv5 中出现的 Focus 模块是一样的:
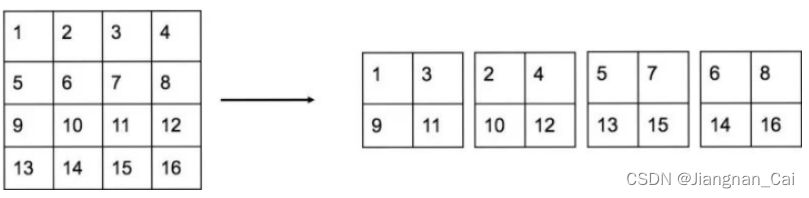
是对特征的重新排列,一种特殊的 reshape。 - 最后的 1x1 卷积层,是根据类别 class 的数量来决定的,例如,你如果有目标检测的类别有 20 类,那么,因为每个网格 grid 一般会预测 5 个 boundary box,每个 boundary box 会预测 4 个坐标值(x, y, w, h) + 1 个置信率 conf + 20 个类别。计算出来就是一个网格 grid 会预测 125 个参数。
YOLO2的训练主要包括三个阶段。
- 第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224x224 ,共训练160个epochs。
- 第二阶段将网络的输入调整为 448x448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
- 第三个阶段就是修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3x3x1024卷积层,同时增加了一个passthrough层,最后使用 1x1 卷积层输出预测结果,输出的channels数为:num_anchors(5+num_classes) 。


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









