









本篇文章:
- 讲解 Inception V1 到 Inception V4,Inception-ResNet,再到 Xecption 历代的改进。
- Pytorch 实现的各网络的代码(含简单训练和推理代码)
- 涉及 ResNet 存在的不稳定性问题和 Inception-ResNet 引入 ResNet 的应对方式。
- 为了方便理解,统一风格重绘了历代 Inception 模块的结构图。并将论文中有小错的图修改了一下
- Inception v4 论文中的 Figure 3 的最后一个池化卷积并行操作,其中的卷积步长应该为 2。
- Inception v4 论文中 Figure 5 的第三个分支的非对称卷积应该是 1 × 7 1\times7 1×7 和 7 × 1 7\times1 7×1 。
- Inception v4 论文中 Figure 18 的描述文字应该是 wider Inception-ResNet-v2 而不是 wider Inception-ResNet-v1。
文中有什么错误的地方,欢迎在评论区留言。
先说结论吧:
纵观 Inception 家族整个发展的历史,从 Inception V1 的诞生,到 Xception ,再到最近的 InceptionNeXt,所有的改进都是为了卷积的解耦。
Inception V1 的多分支卷积结构某种意义上就是分组卷积,通过不同尺寸的卷积来并行获取更为丰富的特征信息。Inception V2 将 5 × 5 5\times 5 5×5 卷积分解成了 2 个 3 × 3 3\times 3 3×3 卷积,而 Inception V3 更是引入了不对称卷积,将 3 × 3 3\times 3 3×3 卷积 进一步分离成了 1 × 3 1\times 3 1×3 和 3 × 1 3\times 1 3×1 卷积。Inception V4 没有特别大的改进,只是利用池化卷积并行的 Reduction 模块对 Inception 的模块进行了简化。Inception-ResNet 也只是在 Inception 模块层面引入了残差结构。
但是 Xception 的问世又将 Inception 的卷积解耦操作带上了一个新的高峰,还是分组卷积的思想,但是如果每一个组都是单通道的话,Inception 模块就变成了名副其实的深度可分离卷积(depthwise separable convolution),论文的作者也将 Inception 模块视为普通卷积和深度可分离卷积的一种中间态。
今年推出的 InceptionNext,讲道理是利用了 ConNext 利用 Inception 思想的一种优化,作者将大尺寸的 depthwise 卷积沿 channel 维度分解为四个并行分支,即小的矩形卷积核:两个正交的带状卷积核和一个恒等映射。形成新的 Inception depthwise convolution,
文章目录
1. 前言
在 Inception 之前,人们的路径依赖就是,通过更深的卷积层级来获得更高的准确率和性能,但是这种无脑加深网络的方式导致参数量变大,随之而来 2 个显而易见的问题,第一是容易过拟合,第二是需要更多的计算资源。
与 Inception V1(GoogLeNet) 同年推出的 VggNet 是当时的集大成者,它可以提供很深的层级和很好的泛化能力,而且在多项任务中都获得了很好的效果。但是 VggNet 有一个很大的问题,因为其网络最后的几层为全连接层(Full connection layer),所以导致参数量很大。
与此同时,受到 NiN 结构的启发,使用 1 × 1 1\times1 1×1 卷积代替全连接层,使得参数量大大地减少了。通过并行执行多个卷积核池化操作,将结果叠加成一个深层的特征图,获得的特征图能更好地展示图像的不同层次的特征。
目前 Inception 家族有:
- Inception V1(GoogLeNet)& BN-Inception
- Inception V2
- Inception V3
- Inception V4
- Inception-ResNet v1 / Inception-ResNet v2
- Xception
- InceptionNeXt
其实这些名字好多在混用,搞得我一头雾水,有的人会把 Inception 家族直接叫 GoogLeNet 家族,然后后续的 Inception V2, V3, V4 版本都是用 GoogLeNet V2, V3, V4 来代替,或者是只是将 Inception V2 叫 GoogLeNet V2,搞得我以为 GoogLeNet 还有一个小改动的版本。然后 Inception-ResNet v1 和 Inception-ResNet v2,让我以为是在 Inception V1 和 V2的基础上添加的残差结构,结果是新的 Inception-ResNet 网络结构,只是有两个不同的子版本。
The Inception deep convolutional architecture was introduced as GoogLeNet in (Szegedy et al. 2015a), here named Inception-v1. Later the Inception architecture was refined in various ways, first by the introduction of batch normalization (Ioffe and Szegedy 2015) (Inception-v2). Later by additional factorization ideas in the third iteration (Szegedy et al. 2015b) which will be referred to as Inception-v3 in this report.
2. Inception V1(GoogLeNet)
2.1 Trick
2.1.1 1 × 1 1 \times 1 1×1卷积
为什么要引入
1
×
1
1\times1
1×1 卷积?

从上图可以看出,如果
C
o
u
t
p
u
t
<
C
i
n
p
u
t
C_{output} < C_{input}
Coutput<Cinput 的话,这个
1
×
1
1\times1
1×1 卷积就是能够实现降维的,也就是压缩了输出的通道(channel)数量,也就是减少了参数量。引入
1
×
1
1\times1
1×1 卷积目的就是为了减少卷积的计算量,这个目的确实达到了。但是,同时,通道的数量在某种意义上和“特征”是等价的,减少了计算量的同时,也会造成信息的缺失。
2.1.2 多尺寸卷积聚合
被检测目标的大小尺寸和位置信息未知,通过多个尺寸的卷积核,可以获得更为全面的图像特征信息。将稀疏矩阵(图片,含很多无用的冗余信息)分解成密集矩阵(特征),然后进行计算,加速收敛速度。个人感觉思路和高斯金字塔(Gaussian Pymaid)类似,通过堆叠多层不同尺寸的高斯滤波卷积,来获得不同尺度的图像信息。
2.1.3 辅助分类器(Auxiliary Classifier)
防止梯度消失(低层级引入没什么效果),起到一个正则化的作用。
2.2 Inception V1 模块
| 原始 Inception 模块(Inception V1-naive) | 带降维的 Inception 模块 |
|---|---|
 |  |
左边是最原始版本的 Inception 模块。
右边是带 1 × 1 1\times1 1×1 卷积降维的 Inception 模块,如果前面所说,是受 NiN 的启发,能够有效的减少参数量。其实这里的 1 × 1 1\times1 1×1 卷积和后面 ResNet 提出的 Bottleneck (瓶颈)结构比较类似,区别在于 Bottleneck 在最后还有一个 1 × 1 1\times1 1×1 卷积用于升维。
GoogLeNet 就是使用带降维的 Inception 模块实现的。
2.3 GoogLeNet 网络结构(Inception V1)

这就是 Inception V1(GoogLeNet)的网络结构(不含辅助分类器),如果是要进行训练的话,一般还会加入辅助分类器。
网络内的 Inception block 都是带 1 × 1 1\times1 1×1 卷积的,因为只有一种结构,只是输入输出的通道数不一样,所以还是比较好实现的。
其中使用 pytorch 实现的代码放在了 github 的仓库,欢迎大家自取。
3. Inception V2
3.1 Trick
3.1.1 非对称卷积(Asymmetric Convolution)
Inception V1 模块中因为引入
1
×
1
1\times1
1×1 卷积,存在特征信息丢失的副作用。
Inception V2 的 Inception 模块对此作出了很好的解答,通过更为优秀的卷积分解方法,让卷积的计算更加高效。
(详情见 3.2.2 的 Inception V2-B 模块)
3.1.2 批归一化(Batch Normalization)
引入 BN 可以有效的加速训练。
3.1.3 卷积池化并行
降低卷积的计算量的同时,又能很好的保留图像特征信息的结构(见3.2.4 的 Inception V2-D模块)
3.1.4 只保留一个辅助分类器
作者发现浅层的辅助分类器对网络的收敛没有什么作用,只保留了靠近输出层的辅助分类器,并增加了 BN 层,可以起到正则化的作用。
3. 2 论文中的 Inception 模块
| Inception V2 - A模块 | Inception V2 - B模块 |
|---|---|
 |  |
| Inception V2 - C模块 | Inception V2-D模块 |
 |  |
这是 Inception V2 引入的三种 Inception 模块,可以的看得出来,从 Inception V1 到 Inception V2 的各个模块,所有的改进的思路都是为了两点:减少卷积的计算量,保留更多的特征信息。
下面我们就来看一下具体是怎么操作的。
3.2.1 Inception V1 → \rightarrow → Inception V2-A
将 5 × 5 5\times5 5×5卷积分解成了 2 个 3 × 3 3\times3 3×3卷积,具体是为什么捏?
- 两者的感受野相同
- 两个
3
×
3
3\times3
3×3 卷积的参数量比一个
5
×
5
5\times5
5×5的更少:
假设输入输出的通道数一样,即 C i n p u t = C o u t p u t C_{input} = C_{output} Cinput=Coutput,则:
两个 3 × 3 3\times3 3×3 卷积的参数量为: 2 × 3 × 3 × C i n p u t × C o u t p u t = 18 × C i n p u t × C o u t p u t 2\times3\times3\times C_{input} \times C_{output} =18\times C_{input} \times C_{output} 2×3×3×Cinput×Coutput=18×Cinput×Coutput
一个 5 × 5 5\times5 5×5 卷积的参数量为: 5 × 5 × C i n p u t × C o u t p u t = 25 × C i n p u t × C o u t p u t 5\times5\times C_{input} \times C_{output} =25\times C_{input} \times C_{output} 5×5×Cinput×Coutput=25×Cinput×Coutput
也就是说一个 5 × 5 5\times5 5×5 卷积比两个 3 × 3 3\times3 3×3 卷积多了 25 18 = 1.39 \frac{25}{18}=1.39 1825=1.39 倍的参数。 - 两个卷积比一个卷积多了一个激活函数(activation),提供了更强的非线性能力。
3.2.2 Inception V2-A → \rightarrow → Inception V2-B
将 3 × 3 3\times3 3×3 卷积进行了空间分离(spatial separable convolution),分离成了 1 × 3 1\times3 1×3 卷积和 3 × 1 3\times1 3×1 卷积,因为主要是通过对卷积核进行分离,实现对图像的空间信息(宽高对应的横向和纵向信息)进行处理,同时也能有效的运算次数。比较著名的应用就是用于边缘检测的 Sobel 算子。
例如:一个 3 × 3 3\times3 3×3 卷积,一般来说我们需要进行 9 9 9 次乘法,就是 O ( n 2 ) O(n^2) O(n2)。而不管是 1 × 3 1\times3 1×3 卷积还是 3 × 1 3\times1 3×1 卷积,都只要进行 3 3 3 次乘法,合起来只要 6 6 6 次乘法,就是 O ( 2 n ) O(2n) O(2n)。
其实我看到《A Basic Introduction to Separable》这篇博客里的一段话,感觉到很疑惑:
The main issue with the spatial separable convolution is that not all kernels can be “separated” into two, smaller kernels.
- 3 × 3 3\times3 3×3 卷积是否都是空间可分离的?
- 关于这个计算,感觉问题还挺大的
- 不同的padding模式,减少的参数量是多少?
- 空间分离是否会造成信息的丢失?
3.2.3 Inception V2-B → \rightarrow → Inception V2-C
扩宽网络的宽度,减少深度,保留更多的特征信息。
3.2.4 Inception V2-D
如果想要减少特征图片的尺寸和增加特征图片的通道数,例如从 35 × 35 × 320 35\times 35 \times 320 35×35×320 变成 17 × 17 × 640 17 \times 17 \times 640 17×17×640,传统来说,有两种方式:
- 下图左一的,先池化,再升维。但是这种方式,信息丢失太多了,出现表征性瓶颈。
- 下图中间的,先升维,再池化,这种方式增大了3倍的计算量。(我们观察 GoogLeNet 的网络结构,发现就是使用这种方式的,Inception 模块中穿插着池化模块)。
因此引申出一个问题:有没有既能降低卷积的计算量,又能很好的保留图像特征信息的结构呢?
- 下图右一:卷积核池化并行,然后再合成一个,在扩充通道的同时又保证了计算效率,为此增加了一个 Inception V2-D模块。
其实 Inception V2-D 模块和下图右一是等效的,我们可以将 D 模块左边的两个分支放在一起来看,就是进行卷积操作,最右边的分支就是进行池化操作,就是等效的卷积池化并行操作。

3.3 Inception V2 网络结构

这个 Inception V2 网络结构图是我根据论文的 Table. 1 画出来的。从 Inception V2 开始,网络的输入尺寸就变成了 299 × 299 × 3 299\times299\times3 299×299×3。
当然上面只是论文中的网络结构,我在寻找代码参考来复现 Inception V2 的时候,找了好几份代码进行参考:
- tensorflow 实现的 Inception v2:这是一份 tensorflow 实现的 Inception V2 网络,里面的网络结构和论文不一样,只用到了两种 Inception 模块,一种就是 Inception V2 的模块 A, 另外一种就是少了 1 × 1 1 \times 1 1×1卷积分支的模块 A。完全没有用到卷积分离。
- pytorch 实现的 Inception v2:这个 pytorch 实现的,也包含 Auxiliary Classifier,有多个 Inception 模块,也有对卷积进行分离,但是还是没有找到 Auxiliary Classifier 应该放在哪里。而且 Stem 部分也没有进行卷积分离,直接使用一个 7 × 7 7 \times7 7×7卷积替代了,和 Inception V1 的 Stem 部分实现差不多,不过这个实现已经非常接近了。
我的复现:
- Stem 部分采用论文中的结构
- 4 种不同的 Inception 模块
- 接入了辅助分类器
不过一般来说,Inception V2 没太大意义,主要大家都是使用完全体的 Inception V3,这个权当学习了。
3.3.1 代码复现时候的 Inception 模块
首先我们来分析一下这个网络结构,和 2.3 章节的 Inception V1 网络结构相比,将在 Inception 模块之间的池化层给并行处理了。
在代码的具体实现上,会将末端的 Inception v2-A 与 Inception v2-B 替换成 Inception v2-D。变成下图的结构:

3.3.2 训练的辅助分类器接在哪里
论文中提示是接在两个 A 模块的 D 模块之后。
4. Inception V3
4.1 Trick
4.1.1 标签平滑
之后出文章详细写写
4.1.2 RMSProp
之后出文章详细写写
4.1.3 带 BN 的辅助分类器
作者在 Inception V3 中将靠近输出的辅助分类器去掉了,感觉不太受影响。剩下的一个也加上了 BN 层。虽然起不到加速收敛网络的作用,但是还是有点正则化的效果的。
4.1.4 卷积分解
将卷积进行各种分解,类似 5 × 5 5\times 5 5×5 卷积分解成两个 3 × 3 3\times3 3×3 卷积,或者进一步将 3 × 3 3\times3 3×3 卷积不对称分解成 1 × 3 1\times3 1×3 和 3 × 1 3\times1 3×1卷积。
通过各种卷积分解的措施,来降低网路的卷积运算的参数量。
4.2 代码复现中的 Inception V3 模块
其实我很疑惑,V2 和 V3 是在一篇论文里面提出来的,但是论文中只给 V2 的网络结构图,按照道理来说, V2 和 V3 的网络结构是一样的,只是加入了 Label Smoothing,RMSProp,BN-auxiliary,卷积因式分解之后的完全体 Inception V3。但是我看网络上关于两者的代码实现并不是如此,我迷茫了。
不过后来看了一下 Inception V2 的 D 模块,感觉我又起来了。其实本质 V3 的 5 种 Inception 模块的演进都是有迹可循的。

其中 Inception V3 的 A 和 C 模块是和 Inception V2 一样的,没有做任何改变。
主要改变的地方在于 B 模块,将 n × n n \times n n×n 卷积从 3 3 3 换成了 7 7 7。
Inception V3 的 D 和 E 模块也是卷积和池化并联的操作。作为 A,B,C 模块之间的连接。
这么看,主要的改变就是中间的 4 个 B 模块和一个与之适配的 E 模块。
| Inception v3-A | Inception v3-B | Inception v3-C( = Inception v2-C) |
|---|---|---|
|  |  |
| Inception v3-D(=inception v2-D) | Inception v3-E | |
 |  |
4.3 Inception V3 网络结构

这个网络结构是我参考别的文章,根据代码画出来的,里面没有画出辅助分类器的结构,但是说实话,真的不知道这个结构图哪里得到的。因为论文里就没有 V3 的结构图。V3 和 V2 相比,结构改动虽然不大,但是还是有些不一样的。
5 Inception V4
5.1 Trick
5.1.1 统一 Inception 模块的输入输出
与之前的历代 Inception 网络不一样,Inception V4 的 Inception 模块的输出输出是完全一样的,对整个网络的结构实现了某种程度的简化。因为之前的 Inception 网络的训练受限于当时的硬件资源和深度学习框架,需要进行各部分分开训练,然后组合起来。所以导致网络内部的各部分要进行一些微调来适应内存的要求。但是 TensorFlow 出来之后,和硬件的发展,已经不需要进行分区训练。之前的“复杂”结构也因此进行了相应的调整。
5.1.2 引入专用的 Reduction 模块
其实从 Inception V2 的 Inception-v2-D 模块,就是利用池化卷积并行操作,就起到了 Reduction 的功能,但是在 V4 这里是正式引入,并将其改名成了 Reduction 模块。
5.2 Inception V4 的模块(Inception 与 Reduction 模块)
其实感觉和 V3 差不多,改动不大,也是由 5 种模块组成:
- 不变的:A ,B 和 E 模块和 Inception V3 的完全一样。
- 对卷积进行分解的:C 模块在 Inception V3 的基础上对卷积进行了分解。
- 去除了一个 1 × 1 1\times1 1×1卷积:D 模块。
| Inception v4-A( = Inception v3-A) Figure 4 | Inception v4-B( = Inception v3-B) Figure 5 | Inception v4-C(
≈
\approx
≈ Inception v2-C) Figure 6 |
|---|---|---|
| |  |
| Reduction A(
≈
\approx
≈ inception v3-D) Figure 7 | Reduction B( = Inception v3-E) Figure 8 | |
 | |
5.3 Inception V4 网络结构

(在论文中图三的 Inception-4 的 Stem 结构图的最后一个池化卷积并行结构,卷积的步长应该是2,我在这里改过来了)
6 Inception-ResNet
这一节会将 Inception-ResNet-v1 和 Inception-ResNet-v2 放在一起讲。
Inception-ResNet-v1 的计算量和 Inception V3 差不多,而 Inception-ResNet-v2 的计算量和新出的 Inception V4 差不多。
6.1 Trick
6.1.1 线性的 1 × 1 1\times1 1×1 卷积层
在 inception 模块之后跟一个没有激活函数的
1
×
1
1\times1
1×1 卷积(Activation Scaling)来扩充维度,使得输出和输入的维度一致。

6.1.2 引入残差结构
通过引入残差结构,获得更深的网络,增强网络的表现能力。
6.1.3 残差衰减因子
当卷积数量超过 1000 的时候,残差结构会变得不稳定,在训练的初期就会造成网络的“死亡”,最后的参数都是 0,这种情况无法通过降低学习率或者是加 BN 层来避免。但是这里文章提出了一种解决这种因为引入残差结构而带来的不稳定星:
引入残差衰减因子,设置为 0.1 到 0.3 之间的值。
何凯明大佬也注意到了残差结构的不稳定性,他建议将训练过程分成两个阶段,第一阶段为热身,设置一个非常低的学习率。在第二阶段再设置一个高学习率。但是论文的作者觉得还是残差衰减因子比较有效果。
6.2 Inception-ResNet 模块(Inception 与 Reduction 模块)
| Inception V4 | Inception-ResNet-v1 | Inception-ResNet-v2 | |
|---|---|---|---|
| Inception A | 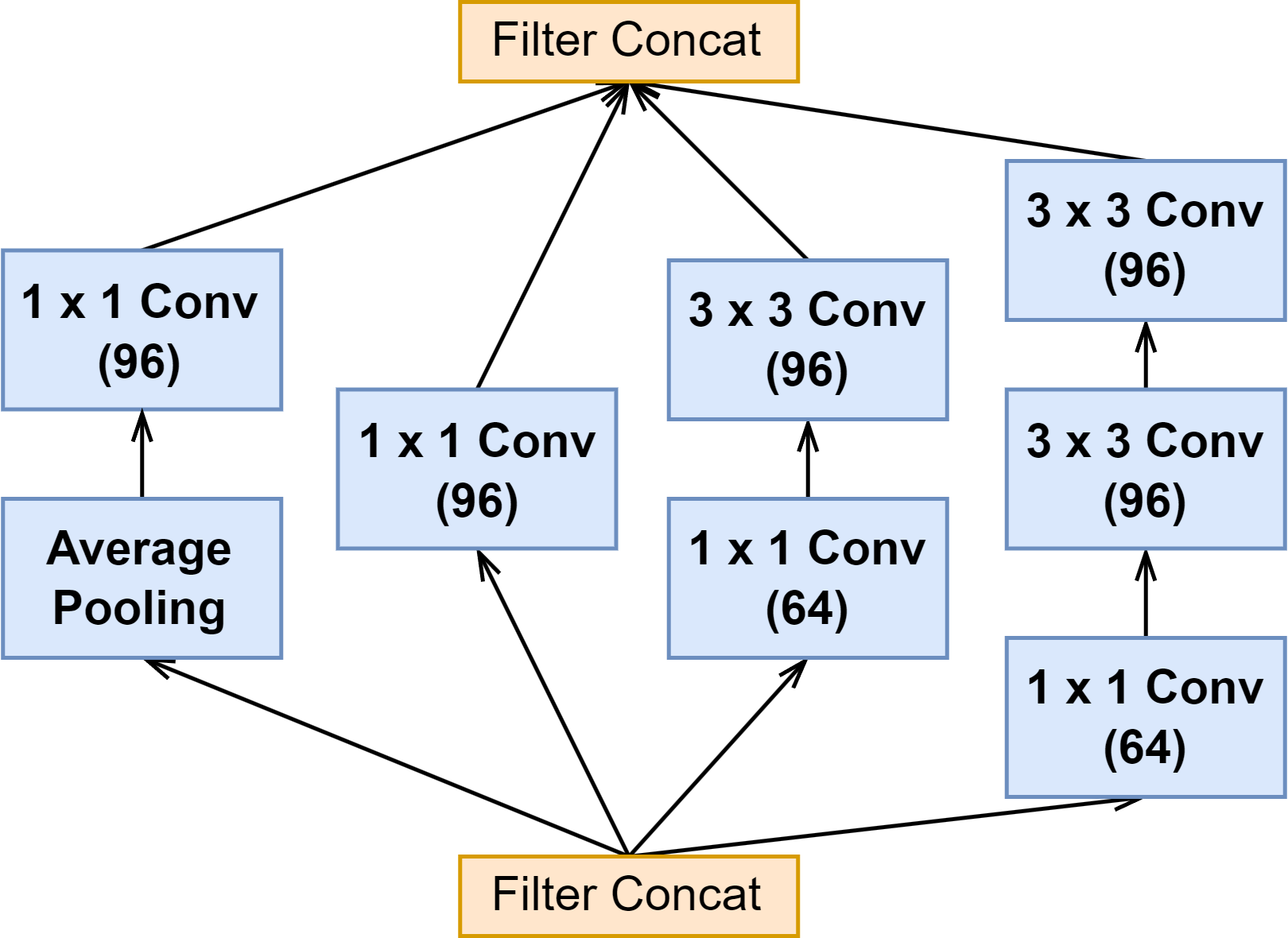 |  | 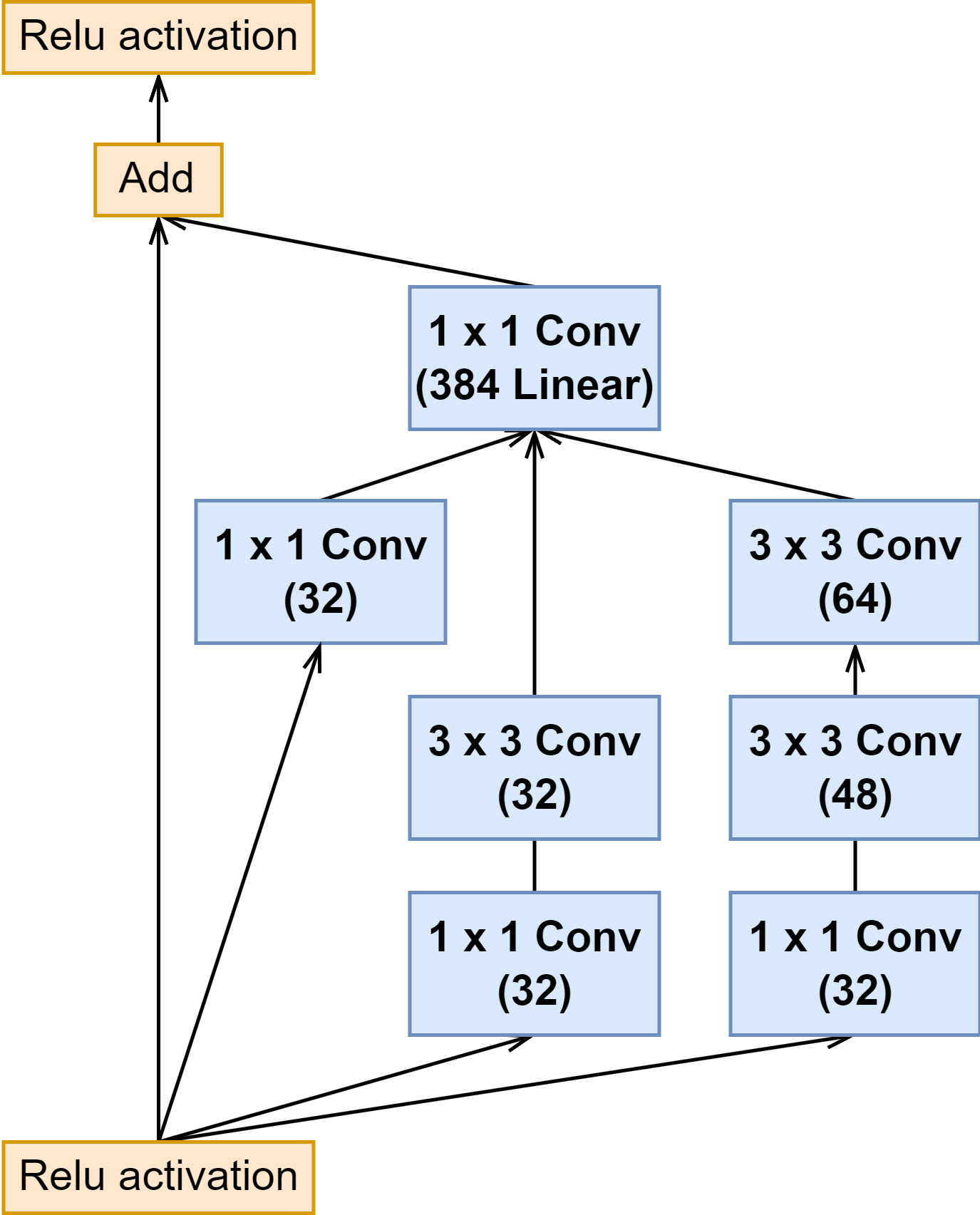 |
| Inception B | 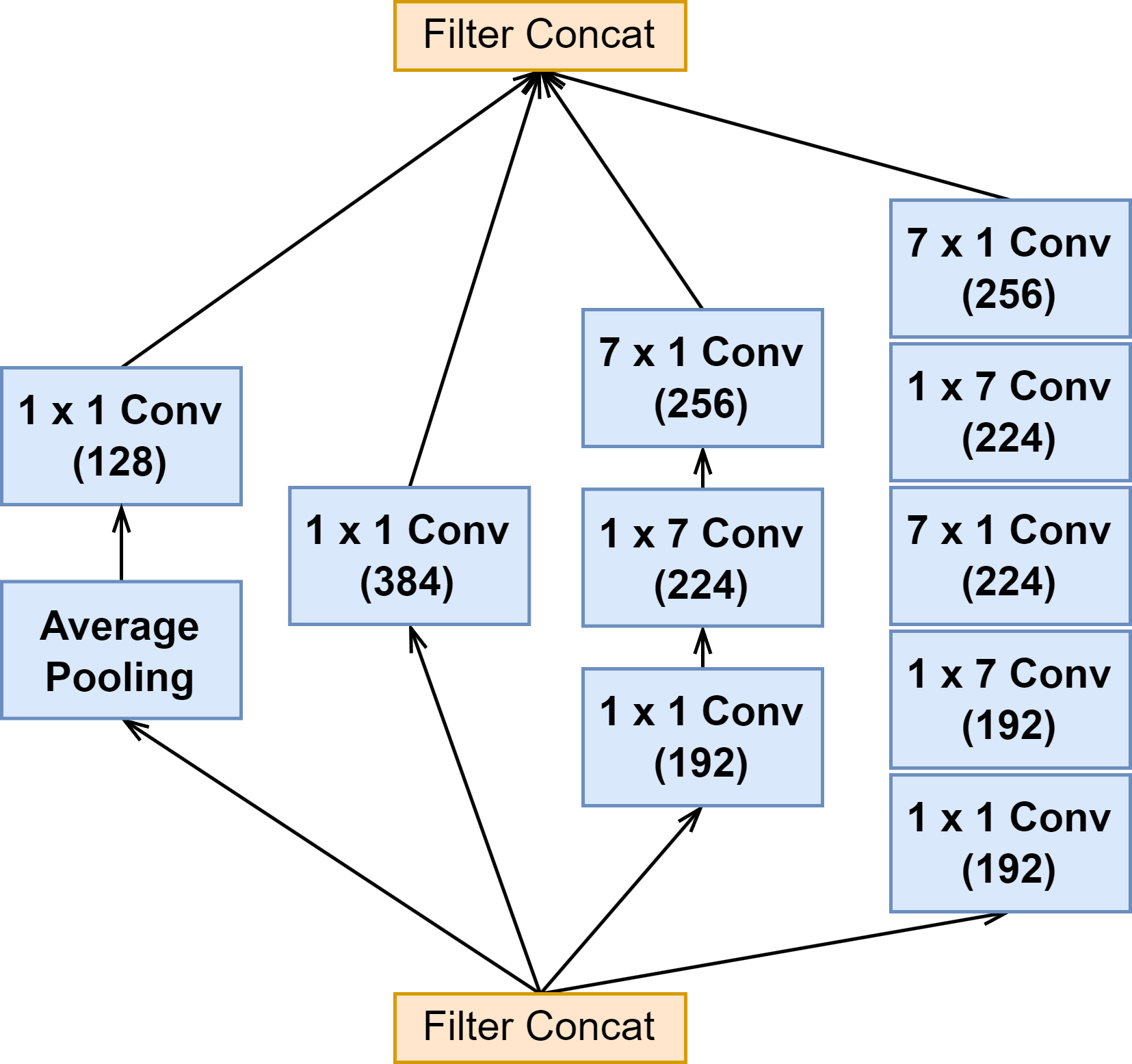 | 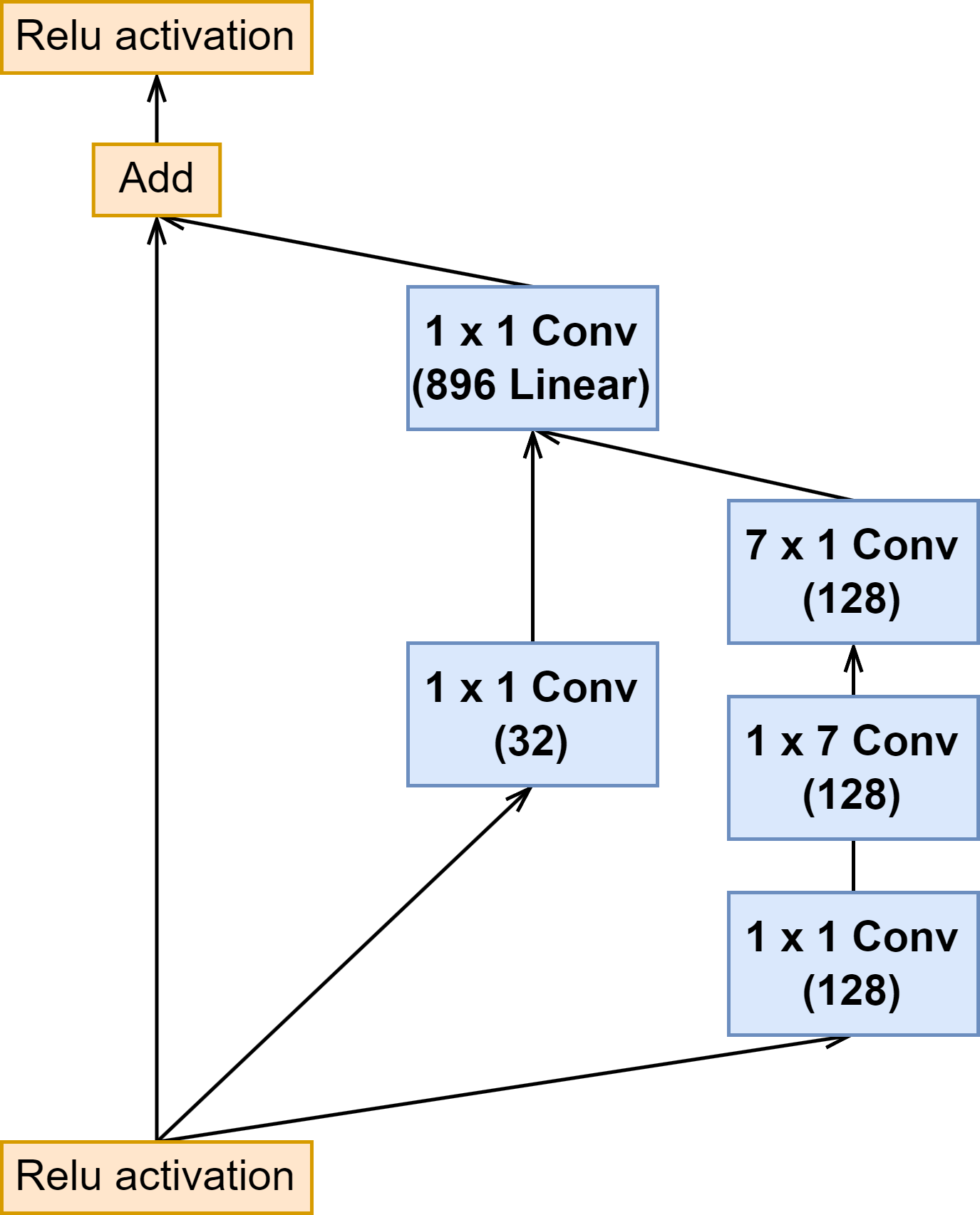 | 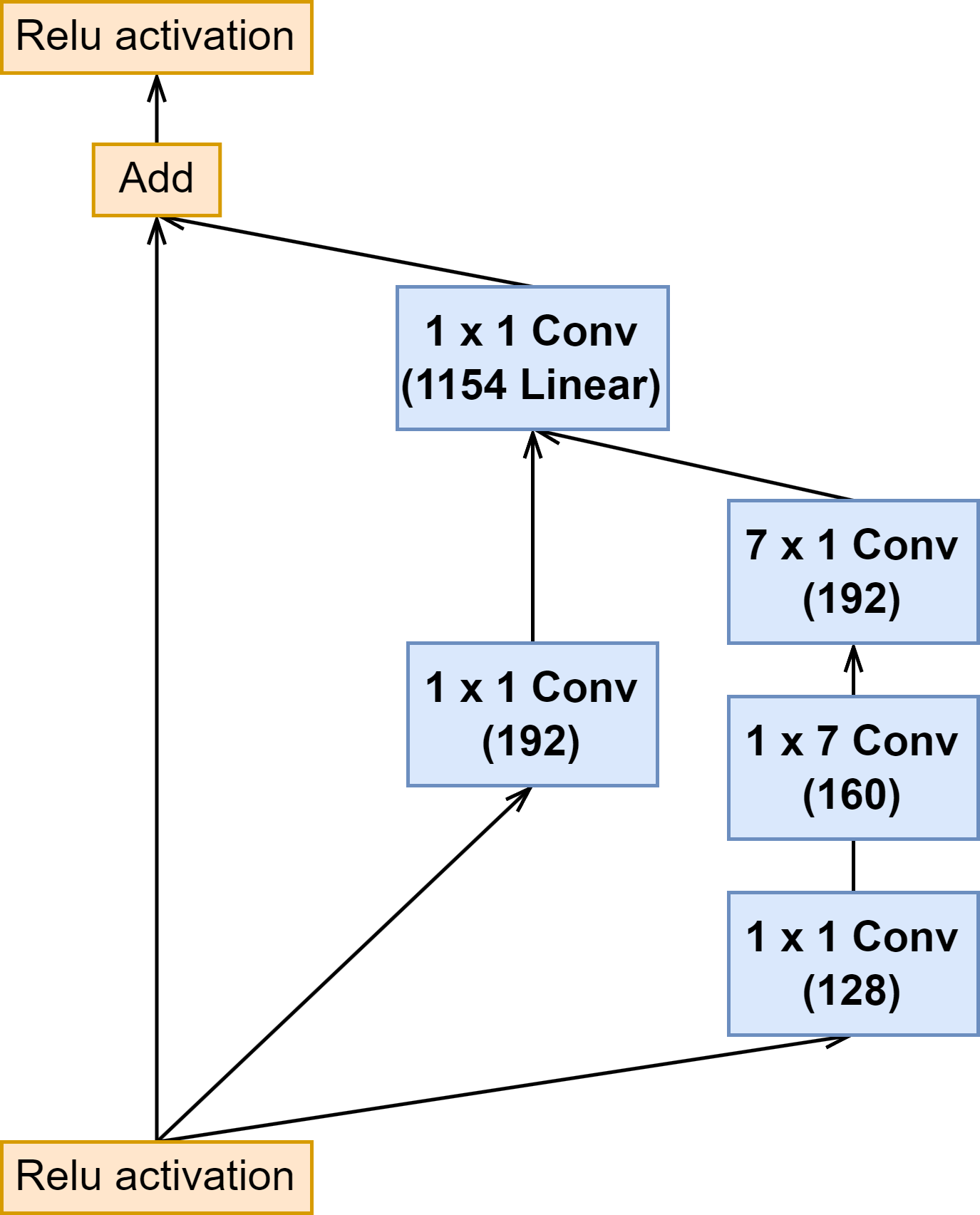 |
| Inception C | 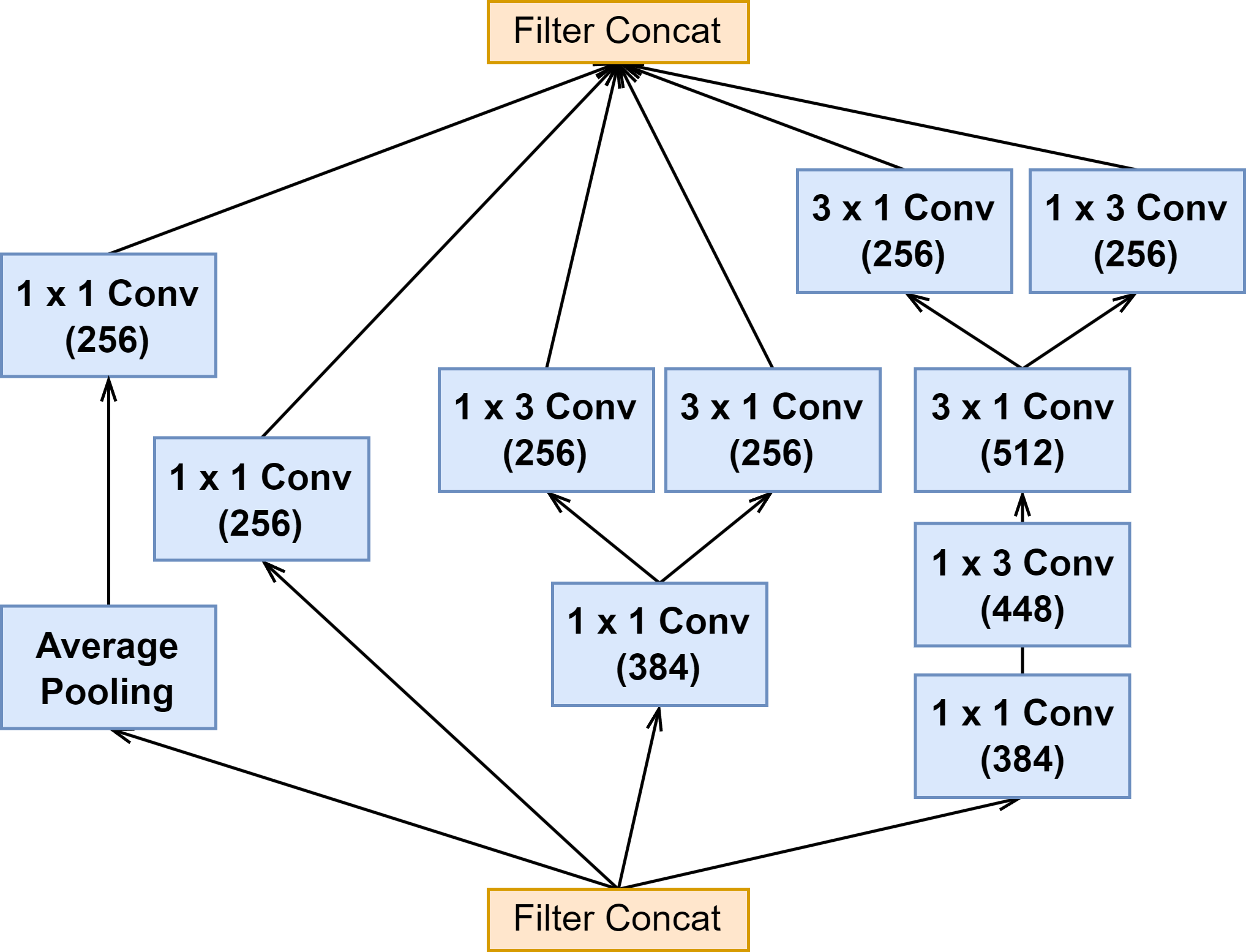 | 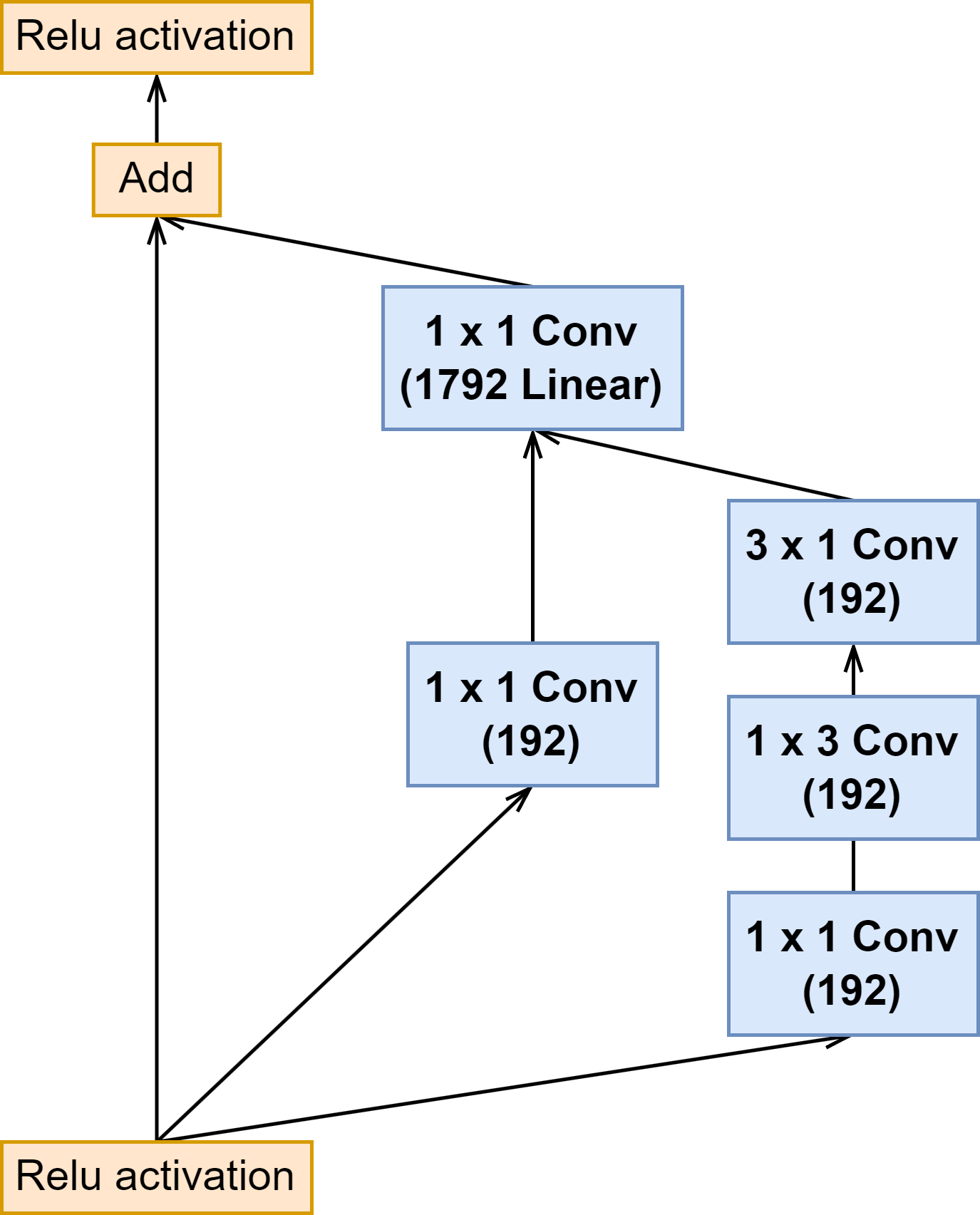 | 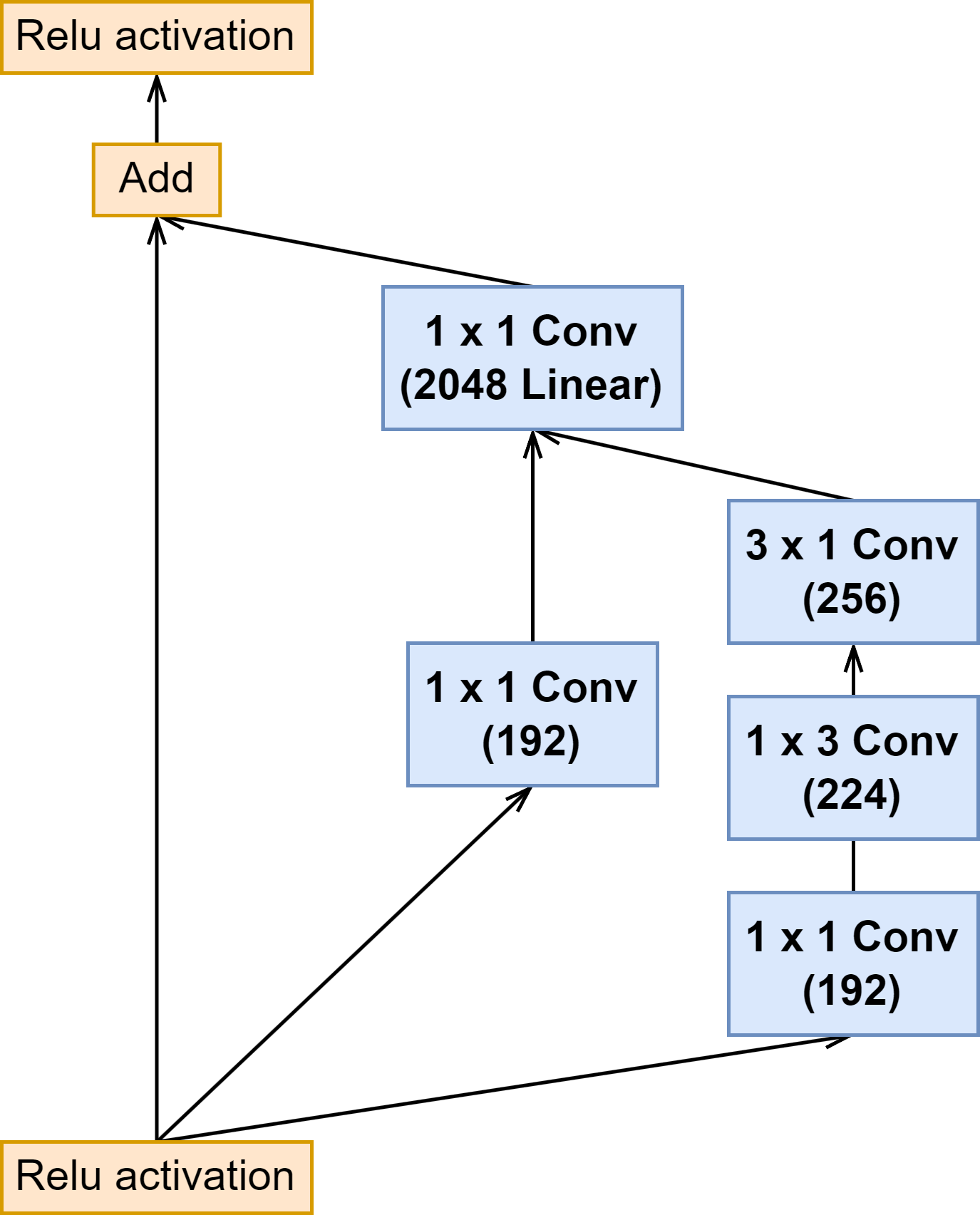 |
| Reduction-A | 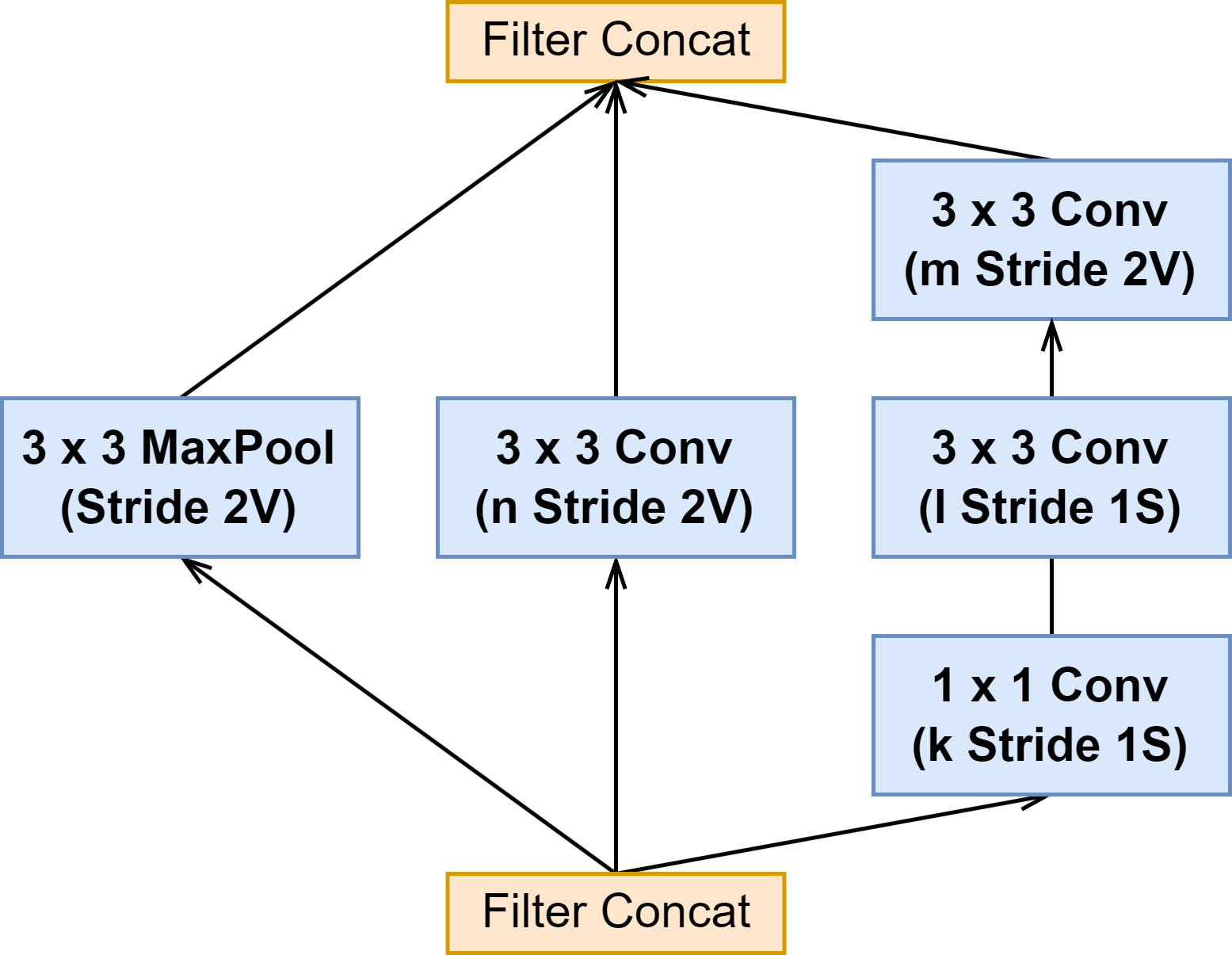 | ||
| Reduction-B |  | 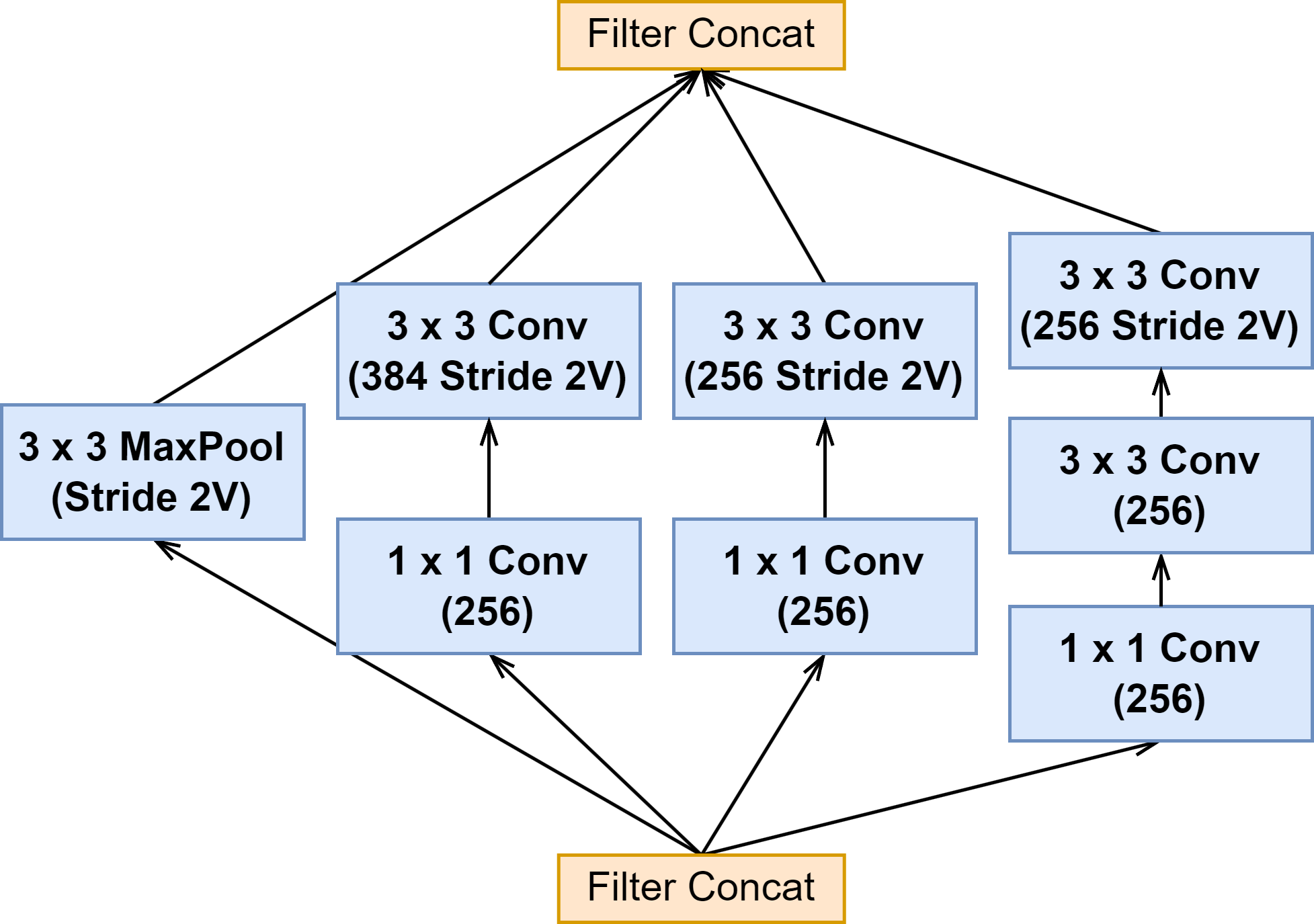 | 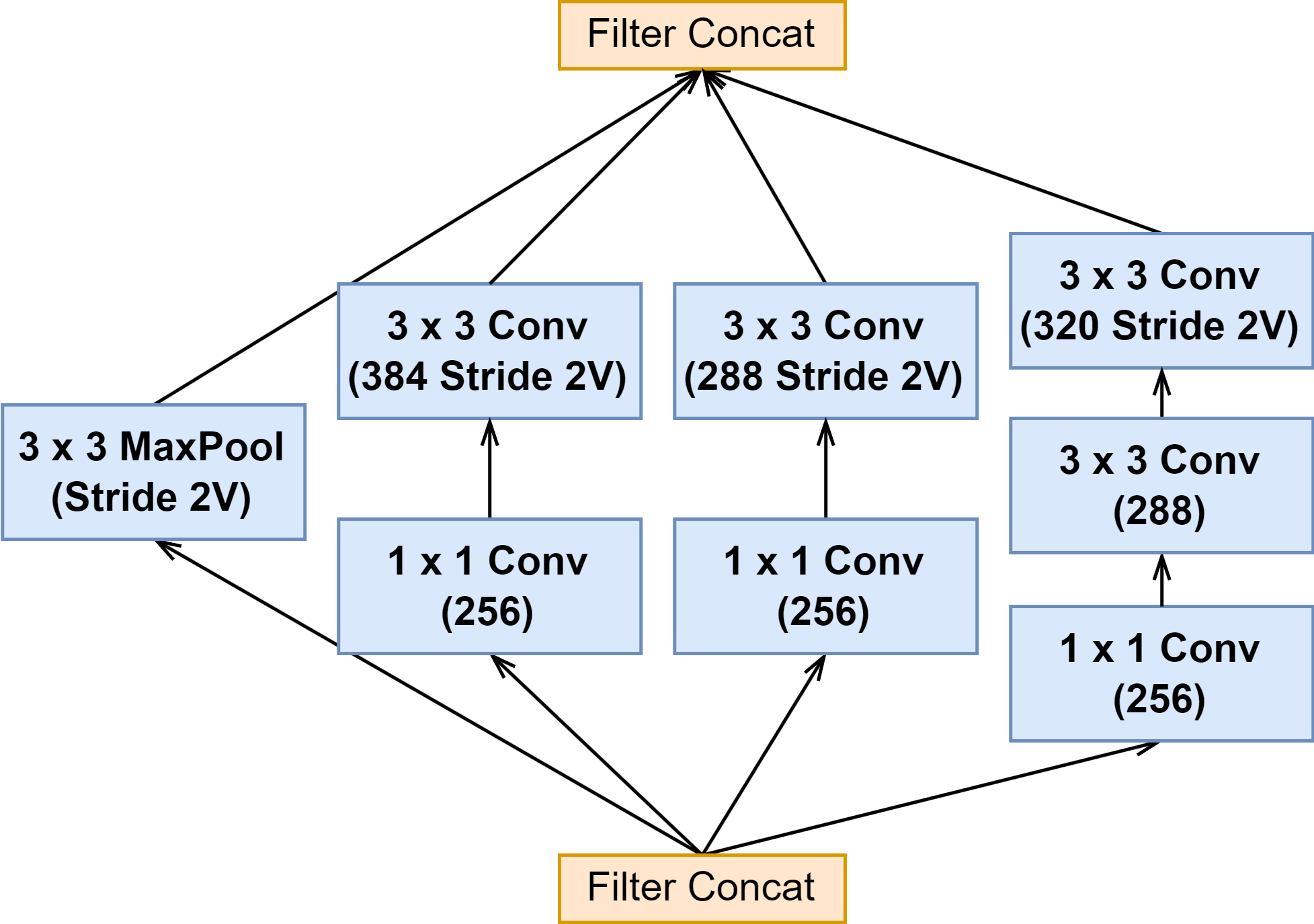 |
上面可以看出来 Inception-ResNet-v1 与 Inception-ResNet-v2 的 Inception 模块结构是一样的,只是卷积的通道大小有细微区别。
3 个网络的 Reduction-A 模块结构都是一样的,也是参数有所区别(见下图表格)
| Network | k | l | m | n |
|---|---|---|---|---|
| Inception-V4 | 192 | 224 | 256 | 384 |
| Inception-ResNet-v1 | 192 | 192 | 256 | 384 |
| Inception-ResNet-v2 | 256 | 256 | 384 | 384 |
6.4 Inception-ResNet 网络结构
6.4.1 Inception-ResNet-v1 的网络结构

6.4.2 Inception-ResNet-v2 的网络结构

Stem 的部分:Inception-ResNet-v1 的 Stem 部分和 Inception V3 的是完全一样的。Inception-ResNet-v2 的与 Inception V4一样
网络的其他部分 Inception-ResNet-v1 和 Inception-ResNet-v2 是一样的,就是网络尺寸有些许差别。
7. Xception
7.1 Trick
Xception 的文章将 Inception 模块看作是普通卷积和深度可分离卷积的一种中间状态。
7.1.1 深度可分离卷积(depthwise separable convolution)
通过对 Inception 模块的进一步改进和解构,以深度可分离卷积的思想来重构 Inception 模块,让网络的参数量进一步减少。不过 Xception 里的深度可分离卷积和原生的有一些细微区别。
- 第一是顺序不一样,Xception 的是先进行 pointwise,然后再进行 depthwise 卷积。
- 第二是激活函数,本来再 Xception 的 pointwise 和 depthwise 之间是应该要加激活函数的,但是实验表示,不加效果是最好的,所以最后和原生的深度可分离卷积一样,两种卷积之间没有激活函数。
7.2 模块的演变
| Inception-V3-A | 一 | 二 |
|---|---|---|
|  |  |
| 三 | 四 | 五 |
 |  | 4 |
- 从 Inception-V3-A 模块将池化分支的 1 × 1 1\times 1 1×1 卷积变成 3 × 3 3\times3 3×3 卷积,然后将全部第一层都设置为 1 × 1 1\times 1 1×1 卷积,第二层都设置为 3 × 3 3\times3 3×3 卷积,实现一个结构更为简单的 Inception 模块。
- 因为第一层都是 1 × 1 1\times 1 1×1,先不管各个输出的通道数是多少,先提取出来,就可以得到三,四的图,经过 1 × 1 1\times 1 1×1 卷积得到的特征图的通道数,我们可以按比例分成几份,分别送到 3 × 3 3\times 3 3×3 卷积里进行深度卷积,最后再 Concat 到一起。
- 考虑到极端的情况,如果每个 3 × 3 3\times 3 3×3 都只处理一个通道的特征图。我们就得到了等效的深度可分离卷积。
1 × 1 1\times1 1×1 卷积就是 pointwise 卷积,处理的是 cross-channel 的信息,后续解着的 n 个 3 × 3 3\times 3 3×3 卷积就是 depthwise 卷积,处理的是 spitail 空间的信息。可以看出来,这与传统原生的深度可分离卷积顺序不一样,但是无伤大雅。(在代码实现的时候,倒是和传统的深度可分离卷积一样,先 depthwise 后 pointwise。)
7.3 Xception 网络结构

可以看出来,和之前历代的 Inception 网络相比,Xception 的网络结构非常的简洁,结构和之前也有很大的改变,很多模块都是直接重复堆叠就行了,我也懒得重画了。
8 InceptionNeXt
未完待续
参考文献
论文:
- NiN: Network In Network
- Inception v1: Going deeper with convolutions
- Inception v2 & v3: Rethinking the Inception Architecture for Computer Vision
- Inception v4 & Inception-resnet: Inception-v4, Inception-ResNet and
the Impact of Residual Connections on Learning - Xception: Xception: Deep Learning with Depthwise Separable Convolutions
- InceptionNeXt:InceptionNeXt: When Inception Meets ConvNeXt
博客:
- A Simple Guide to the Versions of the Inception Network
- 详解Inception结构:从Inception v1到Xception
- A Basic Introduction to Separable
- 当卷积层后跟batch normalization层时为什么不要偏置b
- 深度学习(六)——GoogleNet+Pytorch实现
- pytorch模型之Inception V3
- 深入理解GoogLeNet结构(原创)
- [经典论文重读]Inception V2/V3
- Xception详解
问答:















 4772
4772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









