






一、实验目的
1. 了解SkLearn Tensorlow使用方法
2. 了解SkLearn keras使用方法
二、实验工具:
1. SkLearn
三、实验内容 (贴上源码及结果)
使用Tensorflow对半环形数据集分
#encoding:utf-8
import numpy as np
from sklearn.datasets import make_moons
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers,Sequential,optimizers,losses, metrics
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
#产生一个半环形数据集
X,y= make_moons(200,noise=0.25,random_state=100)#划分训练集和测试集
X_train,X_test, y_train, y_test= train_test_split(X, y, test_size=0.25,random_state=2)
print(X.shape,y.shape)
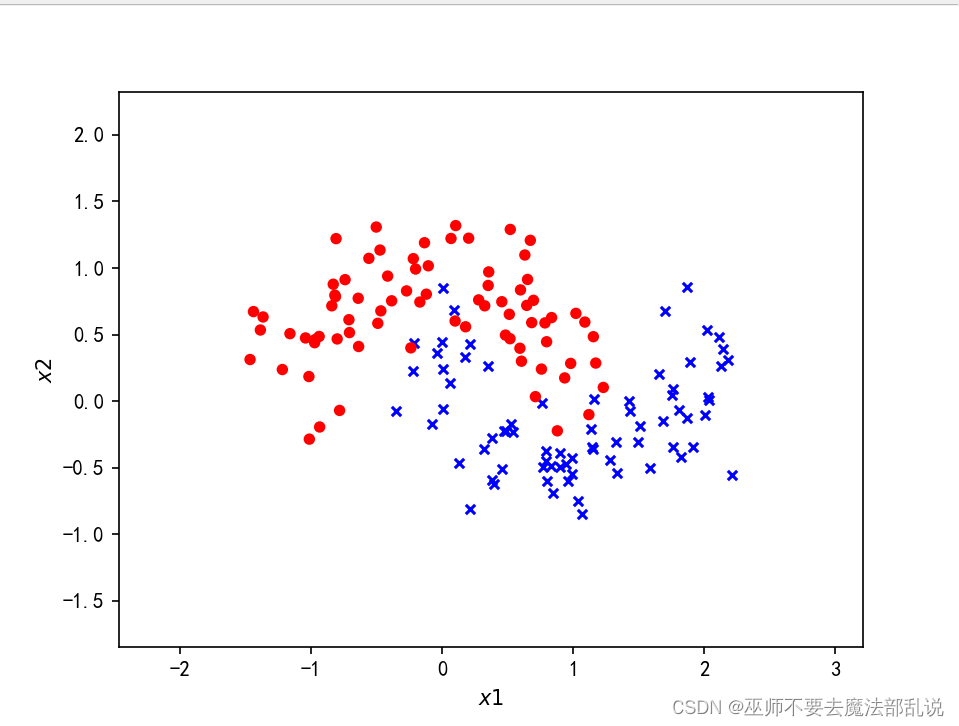
def make_plot(X,y,plot_name,XX=None, YY=None, preds=None):
plt.figure()
axes = plt.gca()
x_min=X[:,0].min()-1
x_max=X[:,0].max()+ 1
y_min=X[:,1].min()-1
y_max=X[:,1].max()+ 1
axes.set_xlim([x_min,x_max])
axes.set_ylim([y_min,y_max])
axes.set(xlabel="$x 1$",ylabel="$x 2$")
if XX is None and YY is None and preds is None:
yr = y.ravel()
for step in range(X[:,0].size):
if yr[step]== 1:plt.scatter(X[step,0],X[step,1],c='b',s=20,edgecolors='none',marker='x')
else:
plt.scatter(X[step,0],X[step,1],c='r',s=30,edgecolors='none',marker='o')
plt.show()
else:
plt.contour(XX,YY,preds,cmap=plt.cm.spring,alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 20, cmap=plt.cm.Greens, edgecolors = 'k')
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title(plot_name)
plt.show()
make_plot(X, y, None)
# 创建容器
model = Sequential()
# 创建第一层
model.add(Dense(8, input_dim = 2, activation = 'relu'))
for _ in range(3):
model.add(Dense(32, activation='relu'))
# 创建最后一层,激活
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs = 30, verbose = 1)
# 绘制决策曲线
x_min = X[:,0].min() - 1
x_max = X[:, 0].max() + 1
y_min = X[:1].min() - 1
y_max = X[:, 1].max() + 1
XX, YY = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
Z = np.argmax(model.predict(np.c_[XX.ravel(), YY.ravel()]), axis=-1)
preds =Z.reshape(XX.shape)
title = "分类结果"
make_plot(X_train, y_train, title, XX, YY, preds)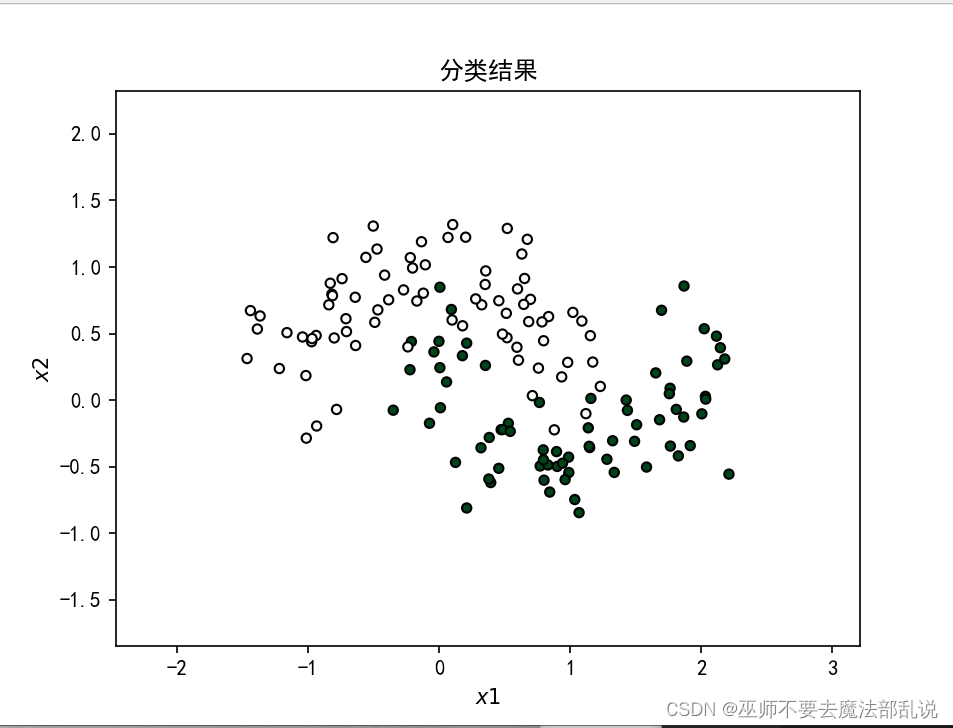
使用VGGNet 识别猫狗
from tensorflow import keras
from keras.applications.resnet import ResNet50
from keras.preprocessing import image# #手写文字识别
from keras.applications.resnet import preprocess_input,decod
import numpy as np# #载人 MNIST 数据集
from PIL import ImageFont,ImageDraw,Image# #拆分数据集
# (x_train,y_train),(x_test,y_test)= mnist.load_data()
# #将样本进行预处理,并从整数转换为浮点数
# x_train,x_test=x_train/255.0,x_test /255.0
img1=r'C:\Users\PDHuang\Downloads\ch11\dog.jpg'# #使用 tf.keras
img2=r'C:\Users\PDHuang\Downloads\ch11\cat.jpg'# model= tf.ke
img3=r'C:\Users\PDHuang\Downloads\ch11\deer.jpg'# tf.keras.la
weight_path=r'C:\Users\PDHuang\Downloads\ch11\resnet50_weight
img=image.load_img(img1,target_size=(224,224))# tf.keras.
x=image.img_to_array(img)# tf.keras.layers.Dense(10,activ
x=np.expand_dims(x,axis=0)# ])
x=preprocess_input(x)# #设置模型的优化器和损失函数
def get_model():# model.compile(optimizer='adam',loss='sparse
model=ResNet50(weights=weight_path)# #训练并验证模型
print(model.summary())# model.fit(x_train,y_train,epochs=
return model# model.evaluate(x_test,y_test,verbose=2)
model=get_model()
#预测图片
preds=model.predict(x)
#打印出top-5的结果
print('predicted',decode_predictions(preds,top=5)[0]) 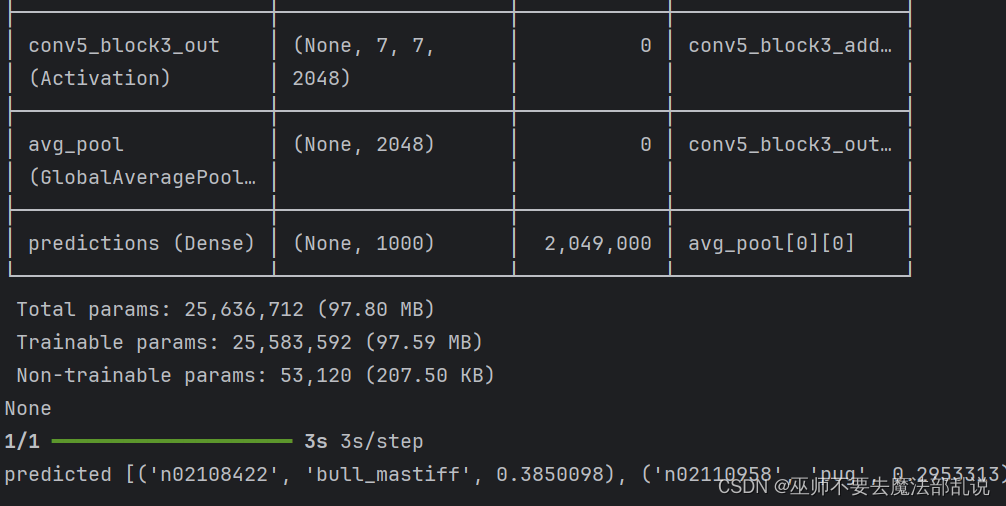
使用深度学习进行手写数字识别
#手写文字识别
import tensorflow as tf
#载人 MNIST 数据集
mnist= tf.keras.datasets.mnist
#拆分数据集
(x_train,y_train),(x_test,y_test)= mnist.lo
#将样本进行预处理,并从整数转换为浮点数
x_train,x_test=x_train/255.0,x_test /255.0
#使用 tf.keras.Sequential将模型的各层堆看,并设置参数
model= tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28
tf.keras.layers.Dense(128,activation='r
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10,activation='so
])
#设置模型的优化器和损失函数
model.compile(optimizer='adam',loss='sparse
#训练并验证模型
model.fit(x_train,y_train,epochs=5)
model.evaluate(x_test,y_test,verbose=2) 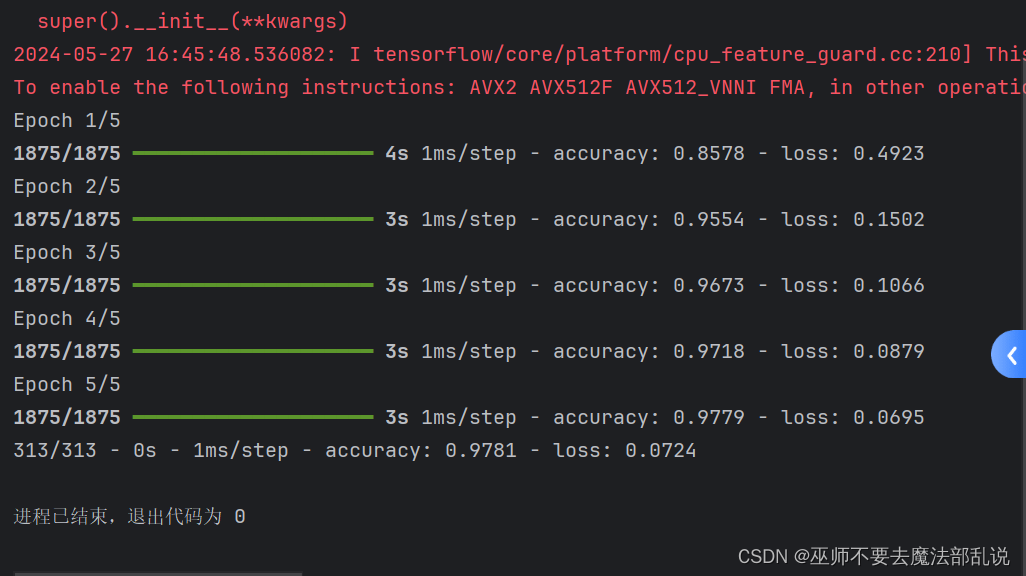
使用Tensorflow + keras 实现人脸识别
from os import listdir
import numpy as np
from PIL import Image
import cv2
from spyder.plugins.findinfiles.widgets.combobox import FILE_PATH
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense, Activation, Convolution2D,MaxPooling2D,Flatten
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.utils import np_utils
#读取人脸图片数据
def img2vector(fileNamestr):
#创建向量
returnVect=np.zeros((57,47))
image = Image.open(fileNamestr).convert('L')
img=np.asarray(image).reshape(57,47)
return img
#制作人脸数据集
def GetDataset(imgDataDir):
print('| Step1 |: Get dataset...')
imgDataDir='C:/Users/PDHuang/Downloads/ch11/faces_4/'
FileDir=listdir(imgDataDir)
m= len(FileDir)
imgarray=[]
hwLabels=[]
hwdata=[]
#逐个读取文件
for i in range(m):
#提取子目录
className=i
subdirName='C:/Users/PDHuang/Downloads/ch11/faces_4/'+str(FileDir[i])+'/'
fileNames= listdir(subdirName)
lenFiles=len(fileNames)
#提取文件名
for j in range(lenFiles):
fileNamestr=subdirName+fileNames[j]
hwLabels.append(className)
imgarray=img2vector(fileNamestr)
hwdata.append(imgarray)
hwdata= np.array(hwdata)
return hwdata,hwLabels,6
# CNN 模型类
class MyCNN(object):
FILE_PATH= 'C:/Users/PDHuang/Downloads/ch11/face_recognition.h5'
picHeight=57
picwidth=47
#模型存储/读取目录
#模型的人脸图片长47,宽57
def __init__(self):
self.model = None
#获取训练数据集
def read_trainData(self,dataset):
self.dataset=dataset
#建立 Sequential模型,并赋予参数
def build_model(self):
print('| step2 |:Init CNN model...')
self.model=Sequential()
print('self.dataset.x train.shape[1:]',self.dataset.X_train.shape[1:])
self.model.add(Convolution2D(filters=32,
kernel_size=(5,5),
padding='same',
#dim ordering='th',
input_shape=self.dataset.X_train.shape[1:]))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2,2),
strides=(2,2),
padding='same'))
self.model.add(Convolution2D(filters=64,
kernel_size=(5,5),
padding='same'))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2,2),
strides=(2,2),
padding='same'))
self.model.add(Flatten())
self.model.add(Dense(512))
self.model.add(Activation('relu'))
self.model.add(Dense(self.dataset.num_classes))
self.model.add(Activation('softmax'))
self.model.summary()
# 模型训练
def train_model(self):
print('| Step3 l: Train CNN model...')
self.model.compile(optimizer='adam', loss='categorical_crossentropy',metrics = ['accuracy'])
# epochs:训练代次;batch size:每次训练样本数
self.model.fit(self.dataset.X_train, self.dataset.Y_train, epochs=10,batch_size=20)
def evaluate_model(self):
loss, accuracy = self.model.evaluate(self.dataset.X_test, self.dataset.Y_test)
print('|Step4|:Evaluate performance...')
print('=------=---------------------=----')
print('Loss Value is:', loss)
print('Accuracy Value is :', accuracy)
def save(self, file_path = FILE_PATH):
print('| Step5 l: Save model...')
self.model.save(file_path)
print('Model',file_path, 'is successfully saved.')
def predict(self, input_data):
prediction = self.model.predict(input_data)
return prediction
#建立一个用于存储和格式化读取训练数据的类
class DataSet(object):
def __init__(self, path):
self.num_classes = None
self.X_train = None
self.X_test = None
self.Y_train = None
self.Y_test = None
self.picwidth=47
self.picHeight=57
self.makeDataSet(path)#在这个类初始化的过程中读取path下的训练数据
def makeDataSet(self, path):#根据指定路径读取出图片、标签和类别数
imgs,labels,classNum = GetDataset(path)
#将数据集打乱随机分组
X_train,X_test,y_train,y_test= train_test_split(imgs, labels, test_size=0.2,random_state=1)
#重新格式化和标准化
X_train=X_train.reshape(X_train.shape[0],1,self.picHeight, self.picwidth)/255.0
X_test=X_test.reshape(X_test.shape[0],1,self.picHeight, self.picwidth)/255.0
X_train=X_train.astype('float32')
X_test=X_test.astype('float32')
#将labels 转成 binary class matrices
Y_train=np_utils.to_categorical(y_train, num_classes=classNum)
Y_test =np_utils.to_categorical(y_test,num_classes=classNum)
#将格式化后的数据赋值给类的属性上
self.X_train=X_train
self.X_test=X_test
self.Y_train= Y_train
self.Y_test = Y_test
self.num_classes=classNum
#人脸图片目录
dataset= DataSet('C:/Users/PDHuang/Downloads/ch11/faces_4/')
model = MyCNN()
model.read_trainData(dataset)
model.build_model()
model.train_model()
model.evaluate_model()
model.save()
import os
import cv2
import numpy as np
from tensorflow.keras.models import load_model
hwdata =[]
hwLabels =[]
classNum = 0
picHeight=57
picwidth=47
#人物标签(编号 0~5)#图像高度
#图像宽度
#根据指定路径读取出图片、标签和类别数
hwdata,hwLabels,classNum= GetDataset('C:/Users/PDHuang/Downloads/ch11/faces_4/')
#加载模型
if os.path.exists('face recognition.h5'):
model= load_model('face recognition.h5')
else:
print('build model first')
#加载待判断图片
photo= cv2.imread('C:/Users/PDHuang/Downloads/ch11/who.jpg')
#待判断图片调整
resized_photo=cv2.resize(photo,(picHeight, picwidth)) #调整图像大小
recolord_photo=cv2.cvtColor(resized_photo, cv2.COLOR_BGR2GRAY)
#将图像调整成灰度图
recolord_photo= recolord_photo.reshape((1,1,picHeight,picwidth))
recolord_photo= recolord_photo/255
#人物预测
print('| Step3 |:Predicting......')
result = model.predict(recolord_photo)
max_index=np.argmax(result)
#显示结果
print('The predict result is Person',max_index+ 1)
cv2.namedWindow("testperson",0);
cv2.resizeWindow("testperson",300,350);
cv2.imshow('testperson',photo)
cv2.namedWindow("PredictResult",0);
cv2.resizeWindow("PredictResult",300,350);
cv2.imshow("predictResult",hwdata[max_index * 10])
#print(resultrile)
k= cv2.waitKey(0)
#按Esc 键直接退出
if k == 27:
cv2.destroyWindow()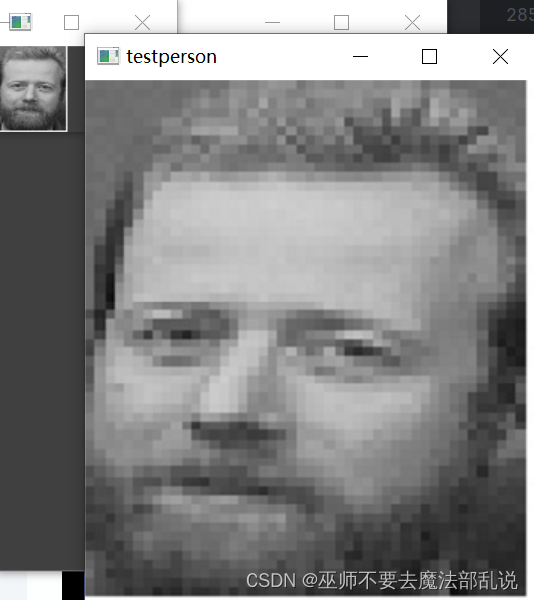
使用Tensorflow + keras 实现电影评论情感分类
# 导包
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
# 导入tf
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(keras.__version__)
# 加载数据集
# num_words:只取10000个词作为词表
imdb = keras.datasets.imdb
(train_x_all, train_y_all),(test_x, test_y)=imdb.load_data(num_words=10000)
# 查看数据样本数量
print("Train entries: {}, labels: {}".format(len(train_x_all), len(train_y_all)))
print("Train entries: {}, labels: {}".format(len(test_x), len(test_y)))
print(train_x_all[0]) # 查看第一个样本数据的内容
print(len(train_x_all[0])) # 查看第一个和第二个训练样本的长度,不一致
print(len(train_x_all[1]))
# 构建字典 两个方法,一个是id映射到字,一个是字映射到id
word_index = imdb.get_word_index()
word2id = { k:(v+3) for k, v in word_index.items()}
word2id['<PAD>'] = 0
word2id['START'] = 1
word2id['<UNK>'] = 2
word2id['UNUSED'] = 3
id2word = {v:k for k, v in word2id.items()}
def get_words(sent_ids):
return ' '.join([id2word.get(i, '?') for i in sent_ids])
sent = get_words(train_x_all[0])
print(sent)
# 句子末尾进行填充
train_x_all = keras.preprocessing.sequence.pad_sequences(
train_x_all,
value=word2id['<PAD>'],
padding='post', #pre表示在句子前面填充, post表示在句子末尾填充
maxlen=256
)
test_x = keras.preprocessing.sequence.pad_sequences(
test_x,
value=word2id['<PAD>'],
padding='post',
maxlen=256
)
print(train_x_all[0])
print(len(train_x_all[0]))
print(len(train_x_all[1]))
#模型编写
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss=keras.losses.binary_crossentropy, metrics=['accuracy'])
train_x, valid_x = train_x_all[10000:], train_x_all[:10000]
train_y, valid_y = train_y_all[10000:], train_y_all[:10000]
# callbacks Tensorboard, earlystoping, ModelCheckpoint
# 创建一个文件夹,用于放置日志文件
logdir = os.path.join("callbacks")
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir, "imdb_model.keras")
# 当训练模型到什么程度的时候,就停止执行 也可以直接不用,然后直接训练
callbacks = [
# 保存的路径(使用TensorBoard就可以用命令,tensorboard --logdir callbacks 来分析结果)
keras.callbacks.TensorBoard(logdir),
# 保存最好的模型
keras.callbacks.ModelCheckpoint(filepath=output_model_file, save_best_only=True),
# 当精度连续5次都在1乘以10的-1次方之后停止训练
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)
]
history = model.fit(
train_x, train_y,
epochs=40,
batch_size=512,
validation_data=(valid_x, valid_y),
callbacks = callbacks,
verbose=1 # 设置为1就会打印日志到控制台,0就不打印
)
def plot_learing_show(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learing_show(history)
result = model.evaluate(test_x, test_y)
print(result)
test_classes_list = model.predict_classes(test_x)
print(test_classes_list[1][0])
print(test_y[1])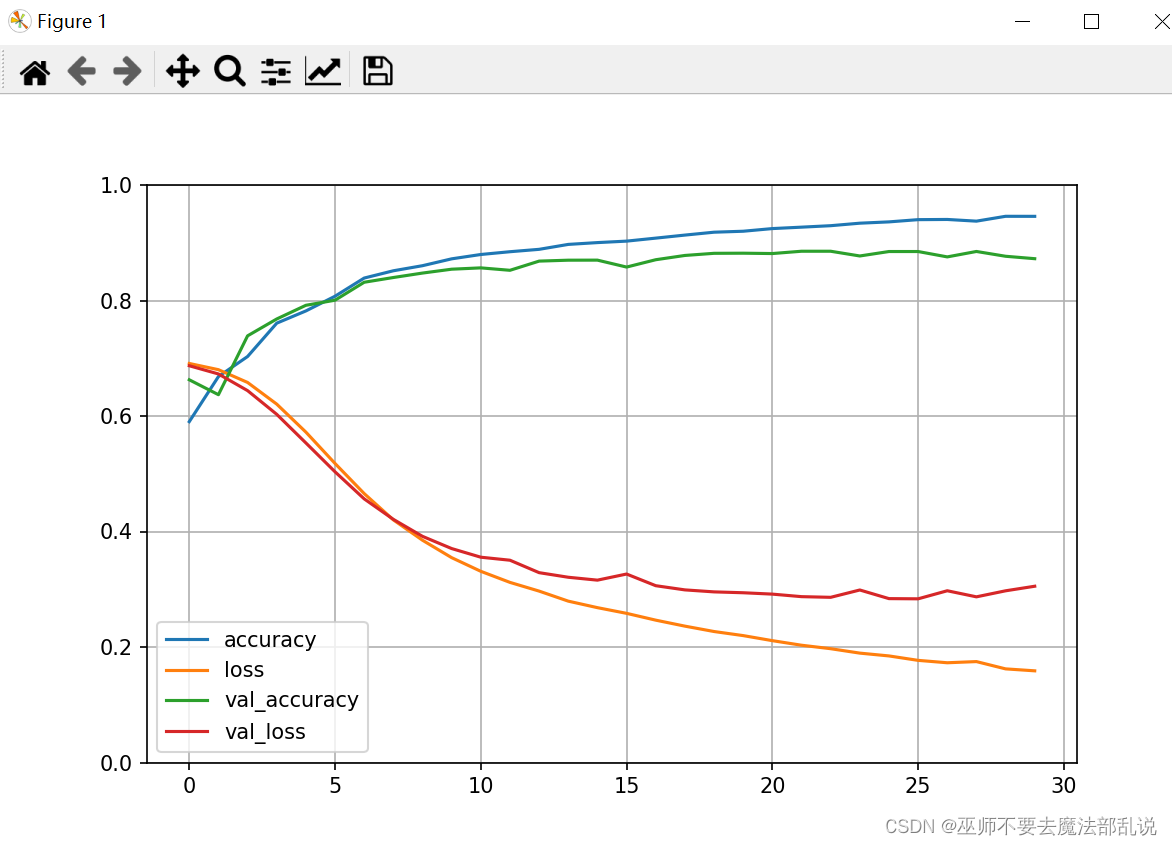
使用Tensorflow + keras 解决 回归问题预测汽车燃油效率
# 导包
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
import pathlib
import seaborn as sns
# 导入tf
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(keras.__version__)
# 加载数据集
dataset_path = keras.utils.get_file('auto-mpg.data',
"http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
print(dataset_path)
# 使用pandas导入数据集
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names, na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
print(dataset.tail())
# 数据清洗
print(dataset.isna().sum())
dataset = dataset.dropna()
print(dataset.isna().sum())
# 将origin转换成one-hot编码
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1) * 1.0
dataset['Europe'] = (origin == 2) * 1.0
dataset['Japan'] = (origin == 3) * 1.0
print(dataset.tail())
# 拆分数据集 拆分成训练集和测试集
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
# 总体数据统计
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
print(train_stats)
# 从标签中分类特征
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
print(train_labels[0])
# 数据规范化
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
norm_train_data = norm(train_dataset)
norm_test_data = norm(test_dataset)
# 构建模型
def build_model():
model = keras.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=[len(train_dataset.keys())]),
keras.layers.Dense(256, activation='relu'),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(1)
]
)
optimizer = keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
# 构建防止过拟合的模型,加入正则项L1和L2
def build_model2():
model = keras.Sequential([
keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001),
input_shape=[len(train_dataset.keys())]),
keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),
keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),
keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),
keras.layers.Dense(1)
]
)
optimizer = keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
# 构建防止过拟合的模型,加入正则项L1
def build_model3():
model = keras.Sequential([
keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001),
input_shape=[len(train_dataset.keys())]),
keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001)),
keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001)),
keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001)),
keras.layers.Dense(1)
]
)
optimizer = keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
# 构建防止过拟合的模型,加入正则项L2
def build_model4():
model = keras.Sequential([
keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001),
input_shape=[len(train_dataset.keys())]),
keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)),
keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)),
keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)),
keras.layers.Dense(1)
]
)
optimizer = keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
# 构建模型 使用dropout来防止过拟合
def build_model5():
model = keras.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=[len(train_dataset.keys())]),
keras.layers.Dropout(0.5),
keras.layers.Dense(256, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(1)
]
)
optimizer = keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
# 构建模型 使用正则化L1和L2以及dropout来预测
def build_model6():
model = keras.Sequential([
keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001),
input_shape=[len(train_dataset.keys())]),
keras.layers.Dropout(0.5),
keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),
keras.layers.Dropout(0.5),
keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),
keras.layers.Dropout(0.5),
keras.layers.Dense(1)
]
)
optimizer = keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
model = build_model()
model.summary()
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=200)
# 模型训练
history = model.fit(
norm_train_data, train_labels, epochs=1000, validation_split=0.2, verbose=0, callbacks=[early_stop]
)
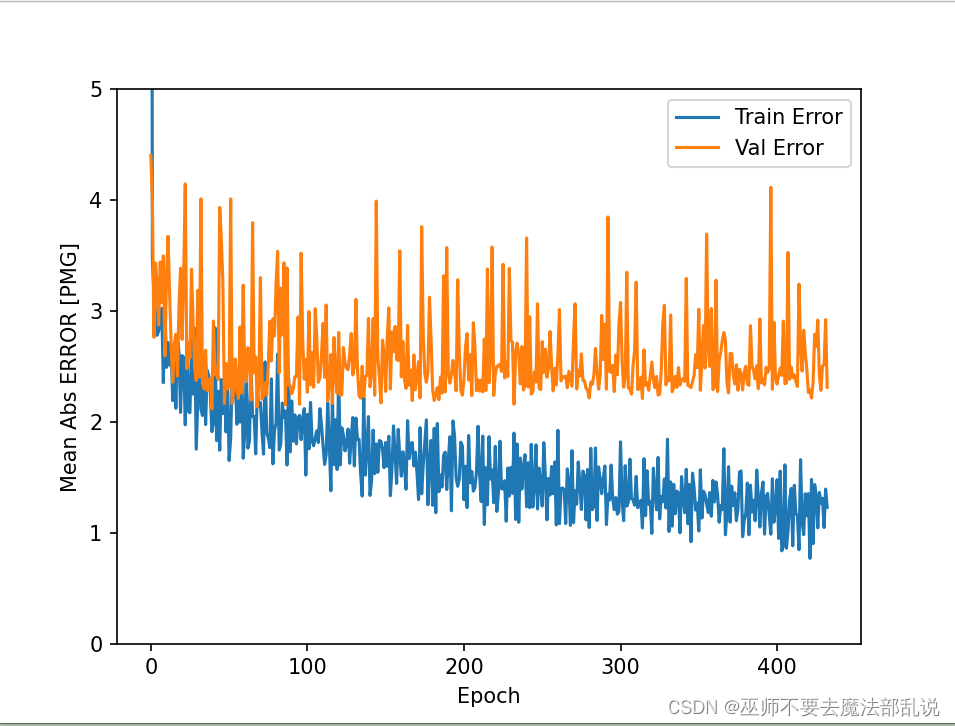
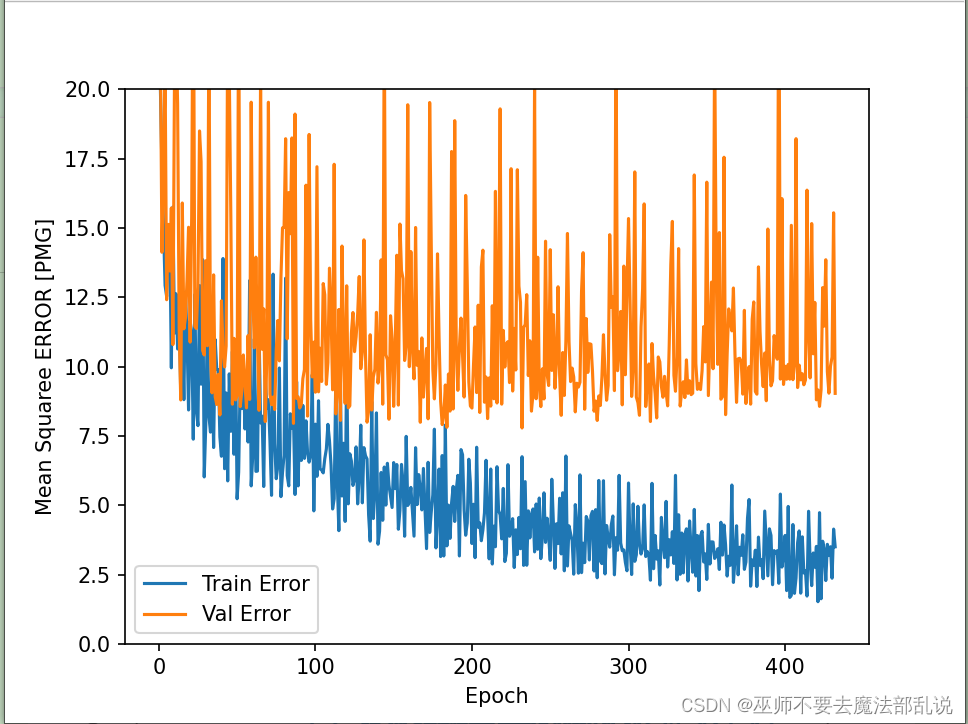
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs ERROR [PMG]')
plt.plot(hist['epoch'], hist['mae'], label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'], label='Val Error')
plt.ylim([0, 5])
plt.legend()
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Squaree ERROR [PMG]')
plt.plot(hist['epoch'], hist['mse'], label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'], label='Val Error')
plt.ylim([0, 20])
plt.legend()
plt.show()
plot_history(history)
# 看下测试集合的效果
loss, mae, mse = model.evaluate(norm_test_data, test_labels, verbose=2)
print(loss)
print(mae)
print(mse)
# 做预测
test_preditions = model.predict(norm_test_data)
test_preditions = test_preditions.flatten()
plt.scatter(test_labels, test_preditions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictios [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0, plt.xlim()[1]])
plt.ylim([0, plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
# 看一下误差分布
error = test_preditions - test_labels
plt.hist(error, bins=25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel('Count')
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









