






Spring Data JPA系列
2、Spring Data JPA Criteria查询、部分字段查询
3、Spring Data JPA数据批量插入、批量更新真的用对了吗
4、Spring Data JPA的一对一、LazyInitializationException异常、一对多、多对多操作
5、Spring Data JPA自定义Id生成策略、复合主键配置、Auditing使用
6、【源码】Spring Data JPA原理解析之Repository的自动注入(一)
7、【源码】Spring Data JPA原理解析之Repository的自动注入(二)
8、【源码】Spring Data JPA原理解析之Repository执行过程及SimpleJpaRepository源码
9、【源码】Spring Data JPA原理解析之Repository自定义方法命名规则执行原理(一)
10、【源码】Spring Data JPA原理解析之Repository自定义方法命名规则执行原理(二)
11、【源码】Spring Data JPA原理解析之Repository自定义方法添加@Query注解的执行原理
13、【源码】Spring Data JPA原理解析之事务注册原理
14、【源码】Spring Data JPA原理解析之事务执行原理
18、【源码】Spring Data JPA原理解析之Hibernate EventListener使用及原理
19、【源码】Spring Data JPA原理解析之Auditing执行原理
前言
在前两篇文章已经介绍过,在使用Spring Data JPA时,DAO层的Respository通过继承JPARepository,自动提供了基本的CRUD接口。以下为JPARepository提供的接口。
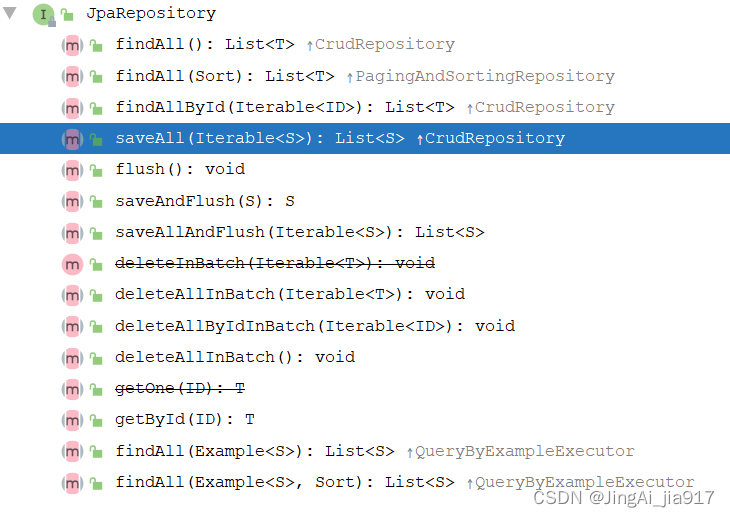
通过接口的名字能够很直观的了解到JPA提供的批量插入的接口为saveAll()。
saveAll()批量更新
saveAll()方法的使用很简单,接收一个集合对象。在Service层中调用repository.saveAll()即可。返回插入的集合。
@Override
public int batchUpdate1(List<ProductEntity> list) {
return productRepository.saveAll(list).size();
}以下为saveAll()的源码,实现在SimpleJpaRepository
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
// 遍历集合
for (S entity : entities) {
// 调用save()方法保存对象
result.add(save(entity));
}
return result;
}
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
// 如果数据的新的,则执行persist()插入数据
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
// 否则的话,执行merge(),该方法相当于hibernate中session的saveOrUpdate()方法,
// 用于实体的插入和更新操作;
return em.merge(entity);
}
}从源码可以看出,saveAll()方法不仅支持数据的批量保存,还执行批量更新。使用起来会非常方便。
但是看了这个源码,是否有些疑惑,为何是轮询集合,然后调用save()方法,这会不会有问题?理想中的批量操作,应该是一批次访问一次数据库,减少数据库的访问,提升数据更新的效率。调用上面的方法,执行10001条数据的更新后,打开druid,截图如下:

什么情况?执行了10001次事务,这说明此批量操作并非理想中的批量操作,它只是帮忙封装了一个for遍历而已。而为了解决真正的批量操作,可以使用强大的javax.persistence.EntityManager来实现,在save()方法中的persist()、merge()方法也是EntityManager中的方法。在上一篇
部分字段查询也是用的EntityManager。
EntityManager
Java Persistence API(JPA)中的EntityManager是一个接口,在JPA规范中,EntityManager扮演着执行持久化操作的关键角色。普通Java对象只有被EntityManager持久化之后,才能转变为持久化对象,保存到数据库中。它不仅可以管理和更新Entity对象,还可以基于主键查询Entity对象,通过JPQL语句进行Entity查询,甚至通过原生SQL语句进行数据库更新及查询操作。
EntityManager提供以下功能:
1)创建、更新和删除数据:EntityManager中的persist()、merge()和remove()方法分别用于插入、更新和删除数据库记录;
2)查询数据:EntityManager的find()和createQuery()方法用于查询数据;
3)管理实体的生命周期:EntityManager的flush()方法用于将持久性上下文同步到基础数据库,进行持久化操作;
4)事务管理:EntityManager的getTransaction()方法用于获取当前事务,可以对事务进行提交或回滚;
5)执行原生SQL:EntityManager的createNativeQuery()方法用于执行原生SQL。对于原生SQL,需要考虑不同数据库的各自实现;
6)创建CriteriaBuilder:EntityManager的getCriteriaBuilder()方法用于获取CriteriaBuilder。通过CriteriaBuilder实现使用Criteria API查询数据;
EntityManager提供了一种抽象的方式来管理数据库操作,使得开发者可以更多专注于业务逻辑的开发,而不需要关心底层的SQL语句。
以下将要介绍的数据库数据的批量新增以及修改使用的就是EntityManager执行原生SQL实现的。
MySQL数据批量新增及修改
使用EntityManager执行MySQL原生SQL实现时,需要先修改spring.database.url的配置:
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false&allowMultiQueries=true在url中,要加上
allowMultiQueries=true
另外,如果一次传输的数据太多,还需要在MySQL数据库中进行配置,windows修改配置文件my.ini,Linux修改配置文件my.cnf,在配置中添加group_concat_max_len的设置。该值默认值为1024个字节。
[mysqld]
group_concat_max_len = 102400
如果有使用第三方的数据库中间件,也可能需要进行配置,否则可能被当作SQL注入攻击。如使用druid,需要如下配置:
spring:
datasource:
druid:
filters: stat,wall
filter:
wall:
config: #支持单个事物多条sql语句执行
multi-statement-allow: true
none-base-statement-allow: true
enabled: true批量新增及修改代码如下:
package com.jingai.jpa.service.impl;
import com.jingai.jpa.dao.entity.ProductEntity;
import com.jingai.jpa.service.ProductService;
import org.apache.logging.log4j.util.Strings;
import org.hibernate.query.criteria.internal.OrderImpl;
import org.springframework.data.domain.*;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.transaction.interceptor.TransactionAspectSupport;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import javax.persistence.Query;
import javax.persistence.TypedQuery;
import java.util.ArrayList;
import java.util.List;
@Service
public class ProductServiceImpl implements ProductService {
@Resource
private EntityManager entityManager;
/**
* 批量插入数据
*/
@Transactional
@Override
public int batchInsert(List<ProductEntity> list) {
int batchSize = 2000;
if(list.isEmpty()) {
return 0;
}
// 单次批量插入条数
StringBuffer sb = new StringBuffer();
String insertSql = "insert into tb_product(name, delivery_no, customer, security_code, create_time, validate_num) values ";
sb.append(insertSql);
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
int index = 0;
for(ProductEntity entity : list) {
index ++;
// 拼接sql字符串
sb.append("('").append(entity.getName()).append("','").append(entity.getDeliveryNo()).append("','")
.append(entity.getCustomer()).append("','").append(entity.getSecurityCode()).append("','")
.append(format.format(entity.getCreateTime())).append("', 0),");
if(index % batchSize == 0) {
Query query = entityManager.createNativeQuery(sb.substring(0, sb.length() - 1) + ";");
int rs = query.executeUpdate();
if(rs != batchSize) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
sb = sb.replace(0, sb.length(), insertSql);
index = 0;
}
}
if(index > 0) {
Query query = entityManager.createNativeQuery(sb.substring(0, sb.length() - 1) + ";");
int rs = query.executeUpdate();
if(rs != list.size() % batchSize) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
}
return list.size();
}
/**
* 批量修改
*/
@Transactional
@Override
public int batchUpdate3(List<ProductEntity> list) {
if(list.isEmpty()) {
return 0;
}
StringBuffer sb = new StringBuffer();
String updateSql = "update tb_product set ";
for(int i = 0 ; i < list.size() ; i ++) {
ProductEntity entity = list.get(i);
sb.append(updateSql).append("name = '").append(entity.getName()).append("', customer = '")
.append(entity.getCustomer()).append("' where pid = ").append(entity.getPid()).append(";");
if(i > 0 && i % 2000 == 0) {
Query query = entityManager.createNativeQuery(sb.toString());
int rs = query.executeUpdate();
if(rs <= 0) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
sb = sb.replace(0, sb.length(), Strings.EMPTY);
}
}
if(sb.length() > 0) {
Query query = entityManager.createNativeQuery(sb.toString());
int rs = query.executeUpdate();
if(rs <= 0) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
}
return list.size();
}
}
执行上面的batchUpdate3的接口,修改10000条记录,druid中的记录如下:
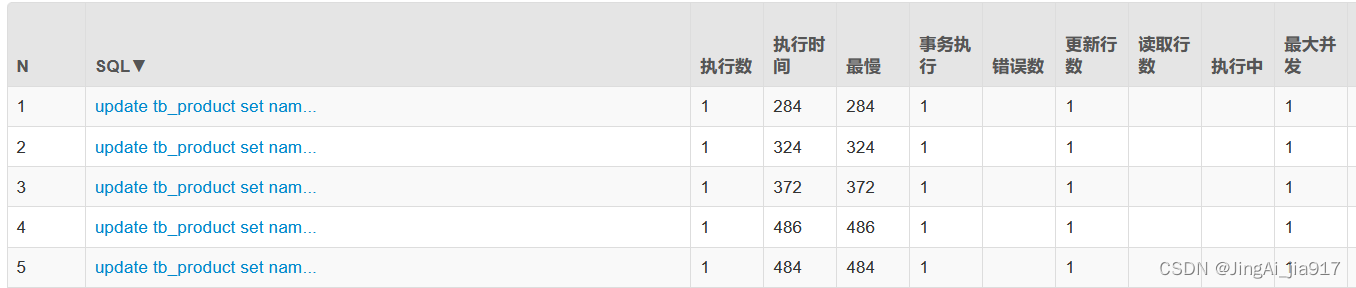
相比上面使用的saveAll()方法实现的批量修改,时间少了1900ms,而实际的访问体验,相差好几秒。因为这个执行时间只记录了在数据库中执行的时间,而saveAll()要访问10000次的数据库,而batchUpdate3()只需要访问5次数据库。
Oracle数据批量新增及修改
Oracle数据库并不支持多语句操作。在Oracle数据库中,需要使用存储过程的begin...end语句块,该语句块由一组一起执行的SQL语句组成。
/**
* 批量新增
*/
@Transactional
public int batchInsert(List<ProductEntity> list) {
if(list.isEmpty()) {
return 0;
}
// 单次批量插入条数
int batchSize = 2000;
StringBuffer sb = new StringBuffer();
String insertSql = "insert into tb_product(name, delivery_no, customer, security_code, create_time, validate_num) values ";
sb.append("begin\r\n");
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
int index = 0;
for(ProductEntity entity : list) {
index ++;
sb.append("('").append(entity.getName()).append("','").append(entity.getDeliveryNo()).append("','")
.append(entity.getCustomer()).append("','").append(entity.getSecurityCode()).append("',TO_DATE('")
.append(format.format(entity.getCreateTime())).append("', 'SYYYY-MM-DD HH24:MI:SS'), 0),");
if(index % batchSize == 0) {
sb.append("end;");
Query query = entityManager.createNativeQuery(sb.toString());
int rs = query.executeUpdate();
if(rs <= 0) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
sb = sb.replace(0, sb.length(), Strings.EMPTY);
index = 0;
sb.append("begin\r\n");
}
}
if(index > 0) {
sb.append("end;");
Query query = entityManager.createNativeQuery(sb.toString());
int rs = query.executeUpdate();
if(rs <= 0) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
}
return list.size();
}
/**
* 批量修改
*/
@Transactional
public int batchUpdateOracle(List<ProductEntity> list) {
StringBuffer sb = new StringBuffer();
sb.append("begin\r\n");
String updateSql = "update tb_product set ";
for(int i = 0 ; i < list.size() ; i ++) {
ProductEntity entity = list.get(i);
sb.append(updateSql).append("name = '").append(entity.getName()).append("', customer = '")
.append(entity.getCustomer()).append("' where pid = ").append(entity.getPid()).append(";");
if(i > 0 && i % 2000 == 0) {
sb.append("end;");
Query query = entityManager.createNativeQuery(sb.toString());
int rs = query.executeUpdate();
if(rs <= 0) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
sb = sb.replace(0, sb.length(), Strings.EMPTY);
sb.append("begin\r\n");
}
}
if(list.size() % 2000 != 0) {
sb.append("end;");
Query query = entityManager.createNativeQuery(sb.toString());
int rs = query.executeUpdate();
if(rs <= 0) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return 0;
}
}
return list.size();
}结尾
Spring Data JPA的知识点还有很多,限于篇幅,本篇先分享到这里。
关于本篇内容你有什么自己的想法或独到见解,欢迎在评论区一起交流探讨下吧。















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









