






LineMod算法
代码来源:https://github.com/meiqua/shape_based_matching
一、总体结构说明
1、Feature结构体描述了一个特征点,即(x,y)位置,以及其量化梯度的方向(在代码中,将方向量化为8个)
2、Template结构体描述了一个模板,保存了模板的缩放大小(width,height),对应的金字塔层级(pyramid_level),以及特征序列(features)。
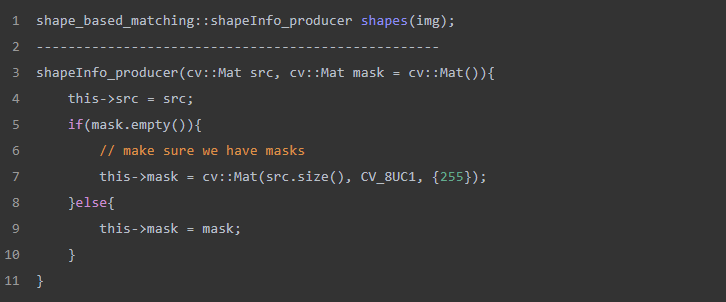
3、shapeInfo_producer类描述了模板的预处理,用于对模板图像进行旋转、缩放等操作,并记录每次操作的具体信息(旋转角度、缩放步长、类别等)。
4、ColorGradientPyramid类描述了制作模板的必要步骤,提供了“量化”接口、“提取模板”接口,“金字塔下采样”接口,特征点选择策略。该类分别被ColorGradientPyramid和DepthNormalPyramid继承,外部都不可见。
5、Match类描述了一个有效的模板匹配,包含了匹配的位置,类别(代码一般类别只有一个,暂时还没有多个类别的检测)、特征点相似度排序算法以及相应的模板信息(id)。
6、Detector类是最重要的类,包含添加模板、匹配等一系列操作。其中匹配函数现在底层金字塔进行全局匹配,后来在顶层金字塔局部细化匹配。即先低分辨率匹配,高分辨率局部相对精细匹配。
二、算法流程说明
模板特征点选取→保存信息→ 待测图片特征点选取→计算响应图→ 线性存储→ 与模板进行相似度计算
以scale_test为例
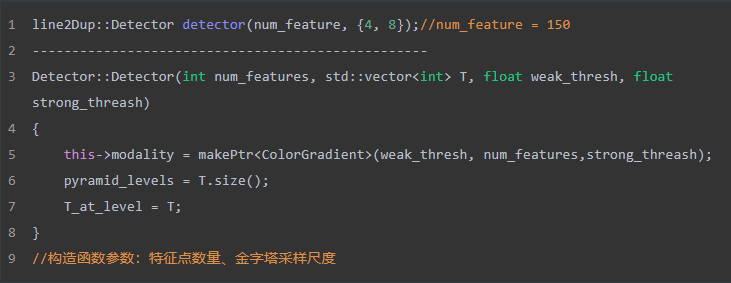
1、定义需要提取的特征点数量

2、创建Detector对象detector,输入特征点数和金字塔尺度数据,在这个例子中,只做两层

构造函数展开
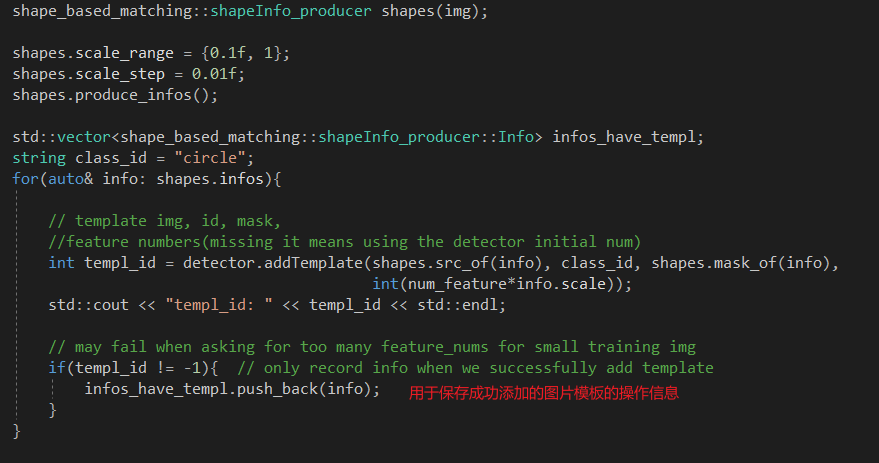
Train部分
输入模板图片后生成 shapInfo_producer对象shapes,定义好旋转和缩放的范围即尺度。
调用shapes.produce_infos()来对信息进行存储。
调用shapes.src_of()来对模板进行相应的操作,并添加到detector.addTemplate()中。
构造函数展开
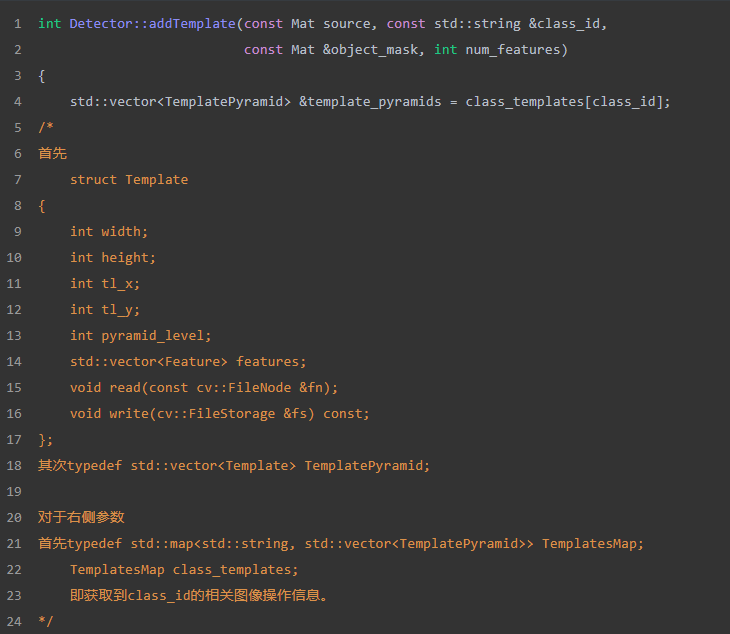
addTemplate()函数参数解释

addTemplate()函数解释:主要作用为提取模板图像的特征点,即梯度较强的点,得到 这些点的坐标和梯度方向值。
a. modality→process()构建ColorGradientPyramid对象,计算出图像的梯度信息
b. 对金字塔的每一层extractTemplate提取梯度较强的特征点
c. cropTemplate()特征点坐标调整
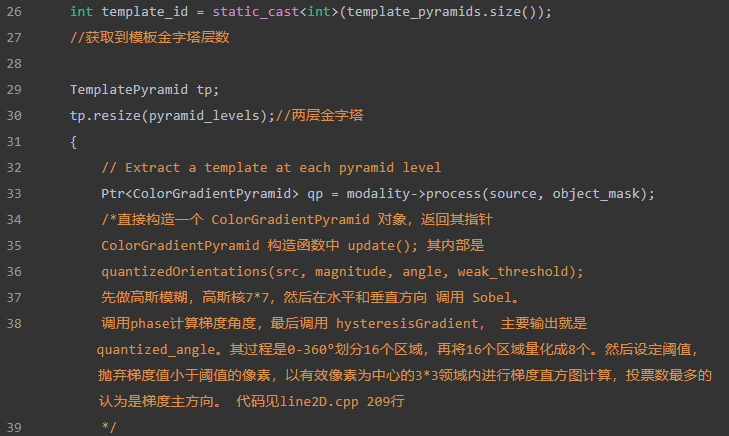
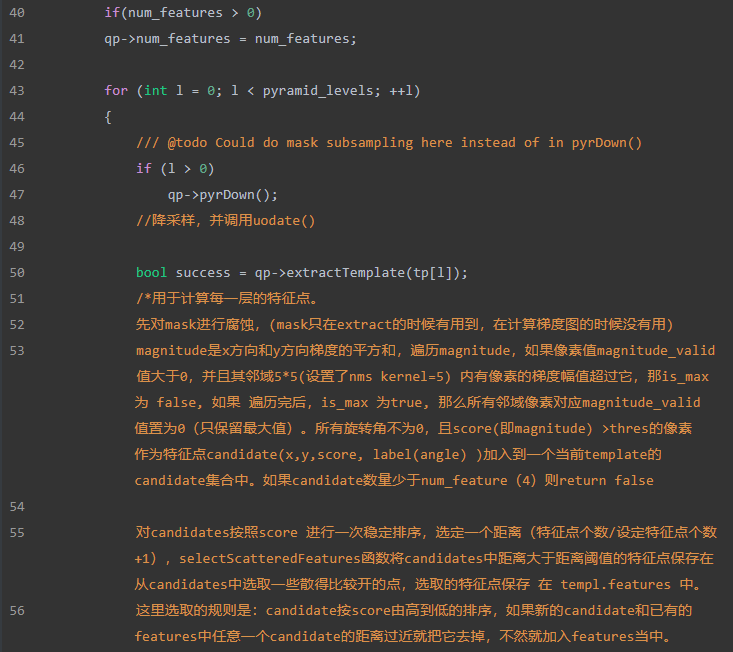
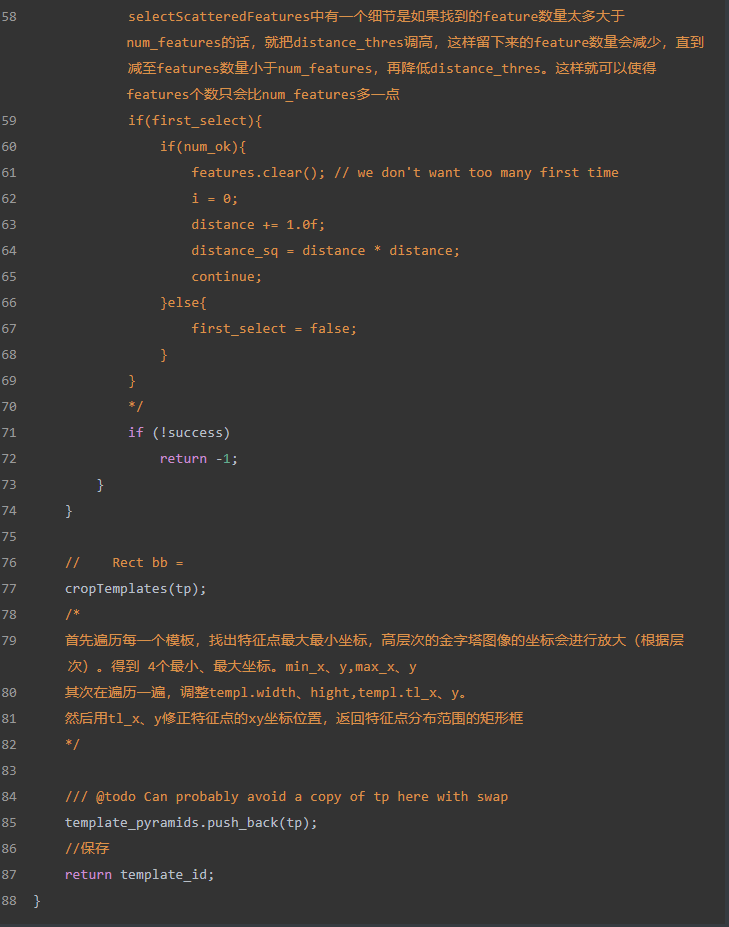
回到Train中,后续就是保存templates,将模板的信息,包括特征点的信息、图像金字塔层数、图像尺寸写在yaml格式文件中,接着保存infos(似乎没啥用,就是保存一些有效模板的旋转缩放信息),同样写在yaml中。
至此 Train结束。主要是对模板进行金字塔降采样,旋转缩放,根据策略选择特征点并保存。
Test部分
先定义标识
读取train阶段保存的模板信息。

输入待检测图像,并重新调整图像大小,应该将图像的weight和height设定为32的倍数,至少也得是16的倍数,方便做图像金字塔
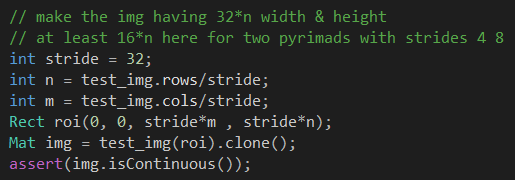
接下来开始匹配计算,注意,阈值90是相似度评分为90

detector.match()函数展开解释
a. 先调用modality→process()构造一个ColorGradientPyramid对象,对图像计算量化后的梯度信息
b. 遍历图像金字塔,构建响应图(construct resopnse map),包括梯度方向扩散spread、梯度响应计算computeResponseMaps、线性化存储linearize。最终存储在LinearMemoryPyramid结构中。
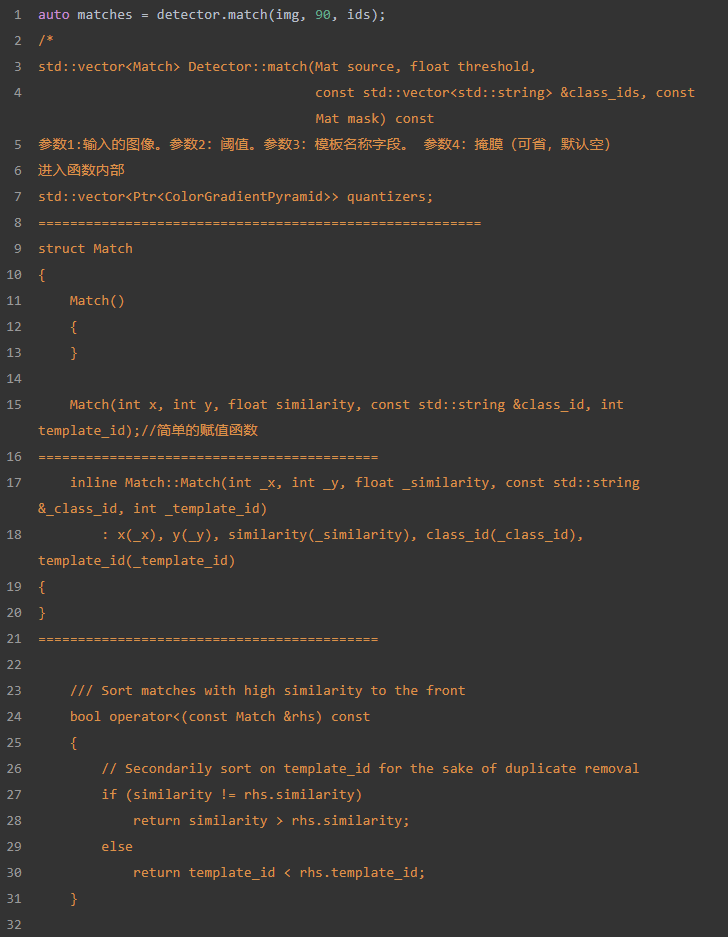

在Match类中最重要的是重载了操作符号’<’。按照相似度排序,否则按照template_id(特征点的提取顺序)排序。
回到detector.match()函数中

类似于模板的梯度计算,计算待测图像的量化梯度方向,并保存在 std::vector<Ptr> quantizers中。

定义响应图大小,需要对每一层金字塔图像都进行响应图计算,一共有8个量化方向,因此每一层都需要8张响应图
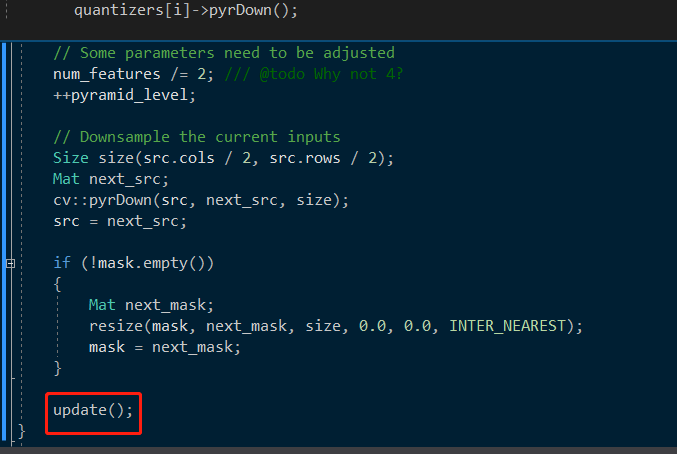
关键函数:pyrDown(),定义了每一层金字塔的图像特征个数,调用update(),和Train过程一致,见上。

接着调用spread进行方向扩散

输入参数:原始图、扩散后的存储图、金字塔缩放尺度
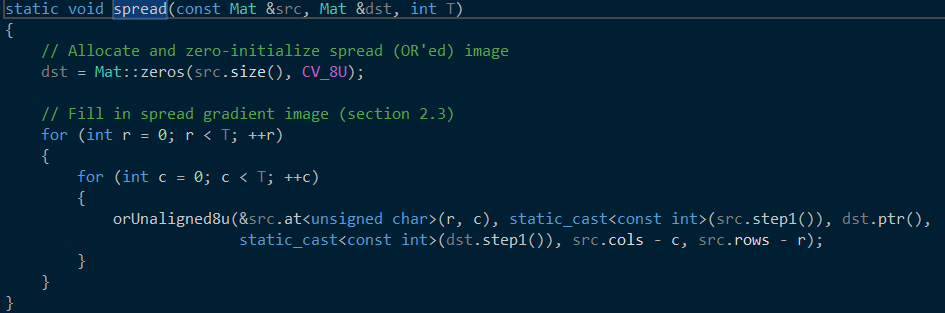
orUnaligned8U()函数展开
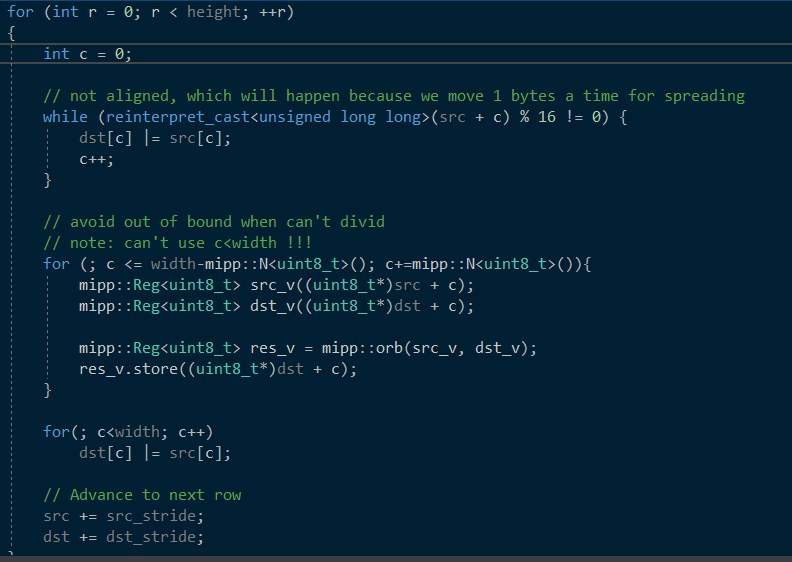
总之是一个扩散过程,虽然过程还不是很懂,但似乎不像是从中心开始扩散,更像是从左上角开始,然后mipp这个也没懂,工程中还包含了一些关于mipp的头文件,像是作者自己写的一些计算优化的东西。
接着计算响应图

同样内部也是用了mipp之类的东西,只能参考一下网上的理解
这个地方 把论文中的相似度 也给离散化了。
并且事先计算了 某个方向 和 某组方向的余弦值的最大值,并且离散化, (或者称为根据余弦值 实行打分制) 存储到一个数组SIMILARITY_LUT 中,即查找表。 这个查找表中针对某个方向的值有32个元素, 总共8个方向, 所以有 256个元素。 32个元素中 , 又分为两组, 前16个是8个方向中前4个方向的各种组合 与 当前32个元素针对的方向 的余弦值的最大值对应的得分。
————————————————
版权声明:本文为CSDN博主「haithink」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/haithink/article/details/88396670
将响应图进行线性存储

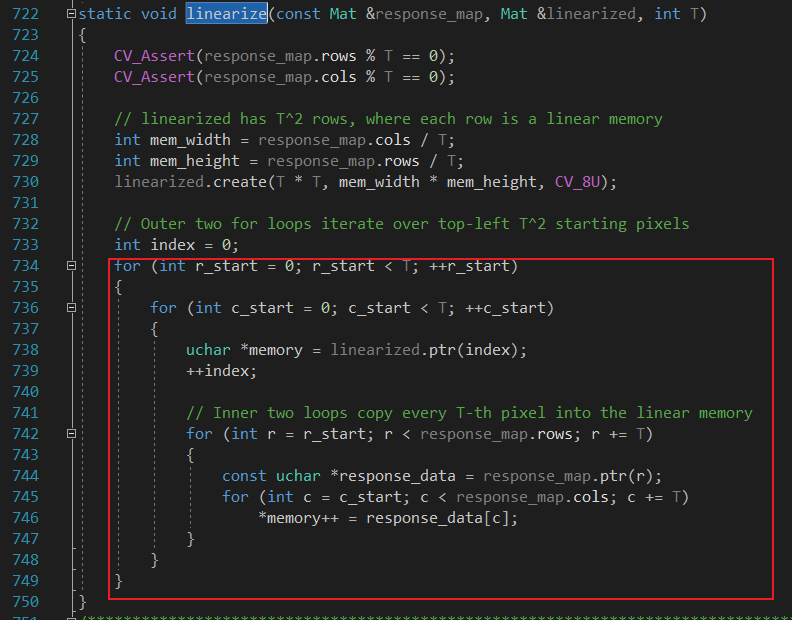
这个是改变存储方式,外部两层循环用于定位,内部两层循环用于替换值。先行后列, 间隔T读取,然后写入。
最后调用matchClass()函数完成匹配过程

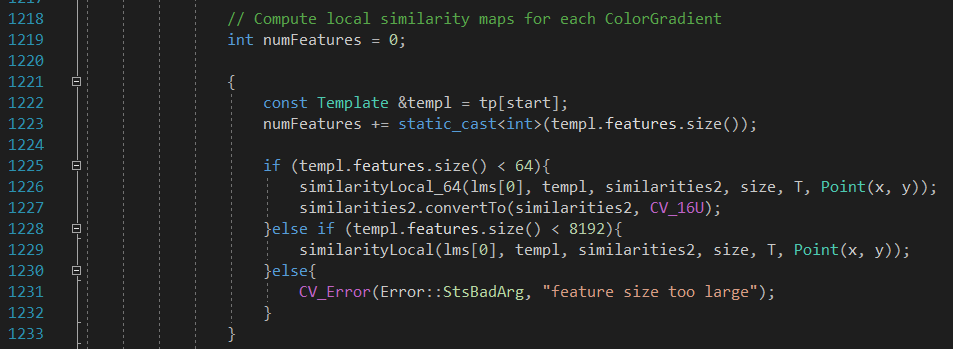
首先在金字塔底层进行粗匹配。目前是最高支持8192个特征点,关键函数similarity_64()
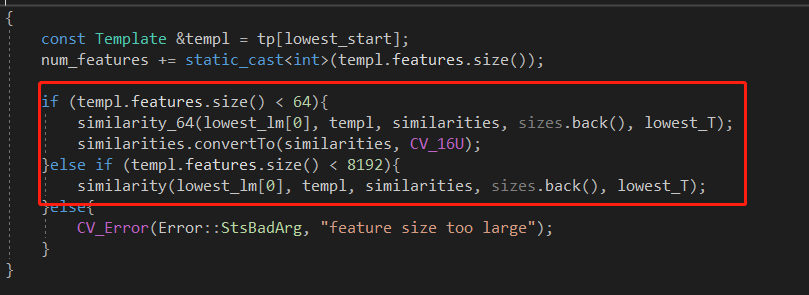
在函数similarity_64()中,对底层金字塔图像进行调整,依据搜索框大小划定搜索范围。利用模板在图像上进行覆盖滑窗,所以产生了 similarity map。 每次滑动,模板和图像产生一个相似度。模板在水平和垂直方向进行滑动, 所以 产生一个 二维的相似度矩阵。这个矩阵的宽自然就是图像的宽减去模板的宽, 也就是代码中的span_x。 高的情况类似。
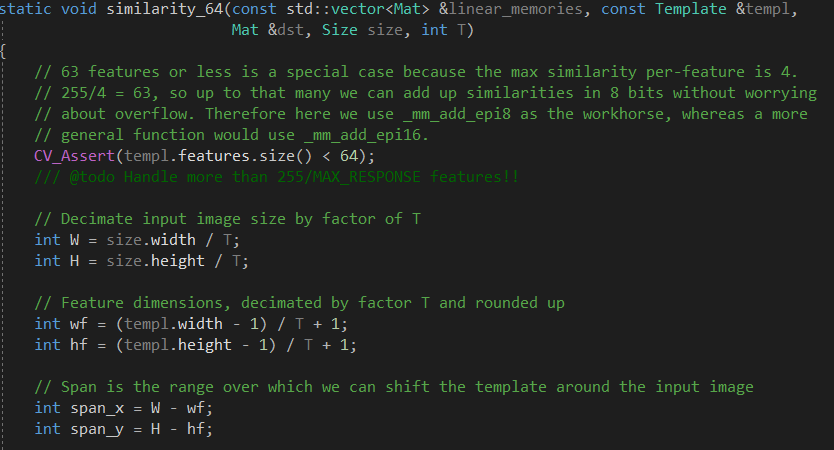
在计算时候,最好的情况是所有匹配都是最大值4,而8bit的图像最大值是255,因此只能限定63个特征点。但是现在这个版本可以支持8192个了。
但是这里并不涉及模板窗口的滑动操作,只是进行线性化寻址获得响应值。
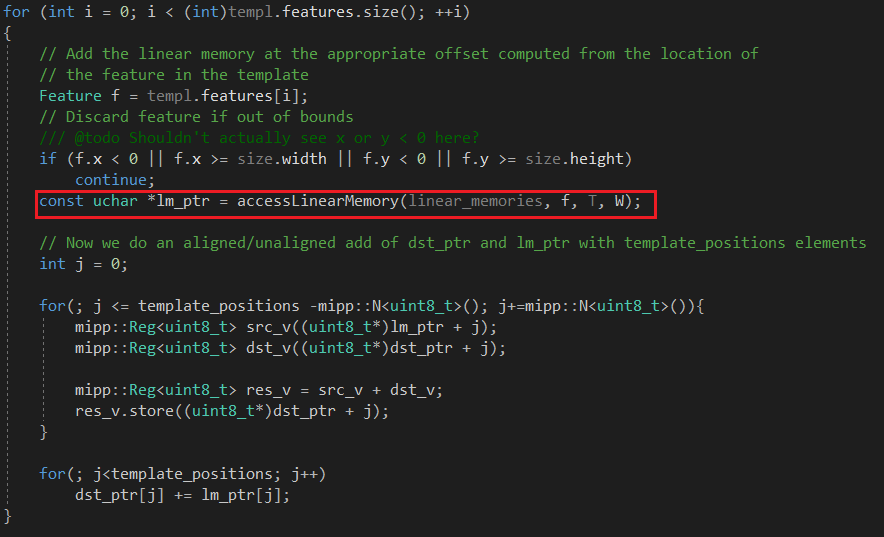
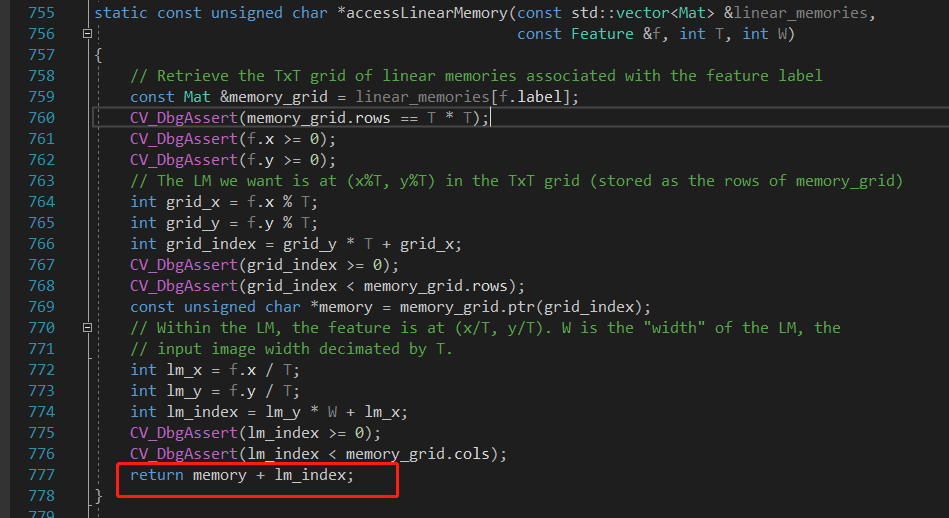
展开accessLinearMemory()函数 首先是根据标签定位到是哪个线性存储结构,根据特征点坐标直接找到线性存储的值。
accesslinearmemory 输入是输入图片的最底层 ,对于一个feature(x,y,ori),找到原input图在这个位置上对于这个方向的响应。
具体操作:response图在这里已经被重新调整大小,首先通过feature的方向确定第一个子图,然后原图片相当于被划分成立H/T * W/T 个区域,每个区域的大小是TT。首先通过对T取余数,找到在区域中的位置,然后再确定是哪一个grid(x除以T取整),因为矩阵大小实际是T^2(H/T * W/T),所以只需要行指针加上列指针,便可确定位置。
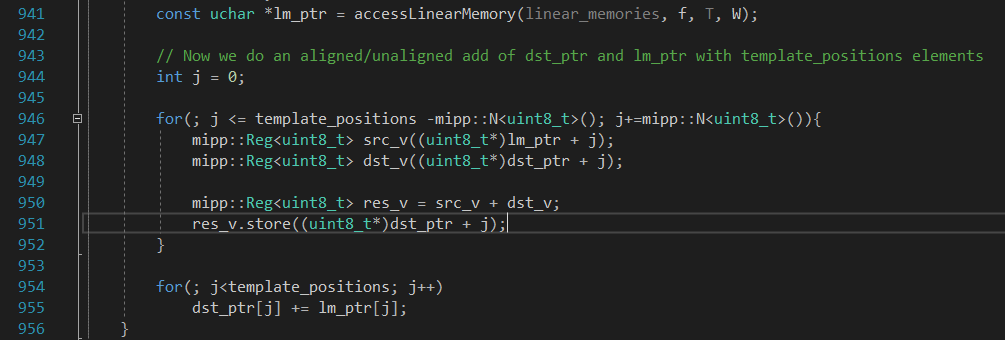
回到similarity_64()函数。将所有区域的相似度拼接在一起,即可获得相似图。
得到了最底层金字塔图像的相似图之后,需要遍历所有的像素点,确定值是否大于阈值。符合要求的则进入候选特征点。
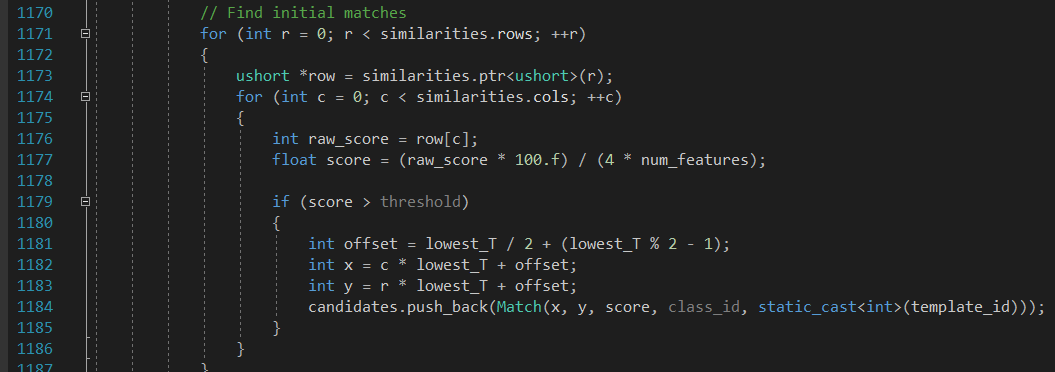
接着将提取的特征点进入上一层金字塔图像,进行进一步的定位计算。
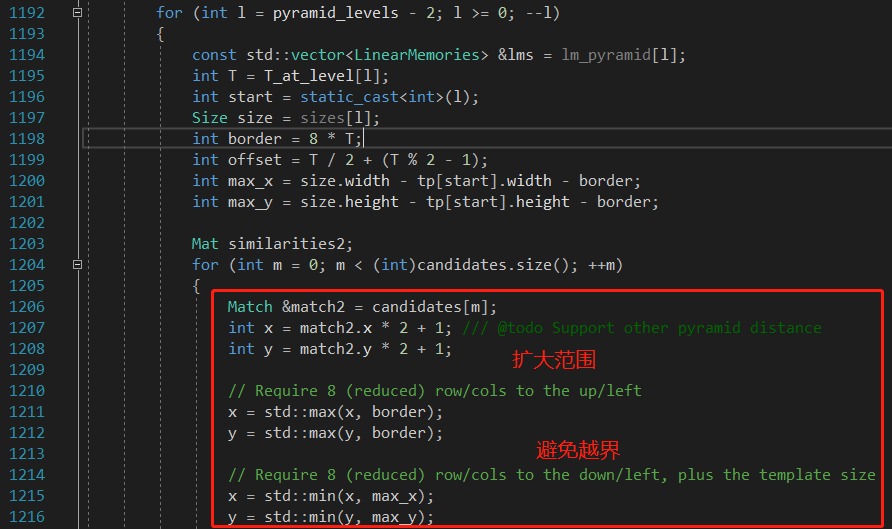
计算局部相似度,得到局部的相似度之后不再是根据阈值筛选,而是找相似度最大的点,然后加入到候选特征点中,下一层再从这个最大点周围去算similarity。

最后对候选特征点的相似度进行阈值过滤,小于阈值的直接抛弃。

至此,已获得所有的最佳特征点。
回到大的流程中。开始输出特征点的坐标信息,并在图中绘制出来。
至此结束。
总的来说,代码的思路还是比较清晰的,有些地方可能是能力有限,理解起来比较困难。比如一些SSE计算加速过程,mipp的使用什么的,可能需要进一步的阅读。这篇文章写得还是有点乱,我的想法是遇到一个核心就先展开解释一下,但往往这个函数比较大,讲完了就很难和前面的再续起来,这个也是我以后需要改进的地方。
这个源码主要将缩放、旋转和噪声的检测分成了三块。















 2363
2363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









