






关注公众号【1024个为什么】,及时接收最新推送文章!
|| 问题现象
技术栈:Spring 事务 + 阿里云 RDS (MySQL 5.6.16)
用了好几年且没有任何改动的一个功能,从管理后台通过文件往系统里导入 2120 条数据,代码逻辑是在一个事务里处理这批数据,结果发现丢了 1596.5 条数据。有 0.5 是因为每条数据同时有 插入 t1、更新 t2 两个动作,插入 t1 丢了,更新t2成功了,后面也会重点分析这 0.5 的真实原因。
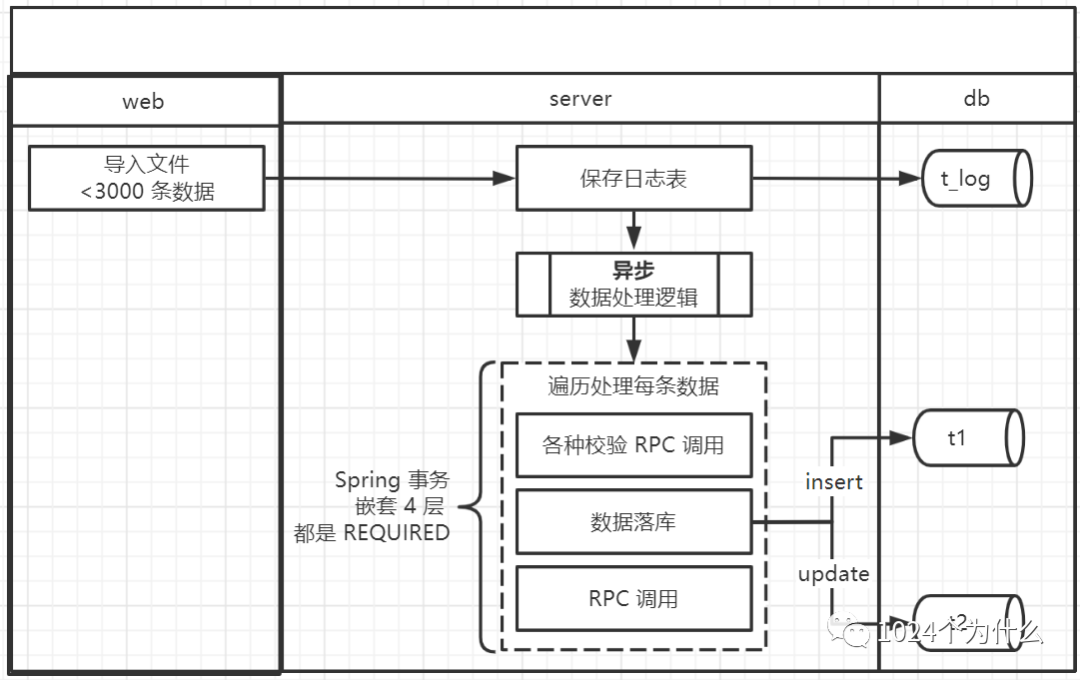
整个事务中掺杂着各种逻辑、RPC 调用,两千多条数据,处理时长 2 分钟左右。
|| 服务侧排查
| 服务是否有异常信息
看了当时所有的日志,没有发现任何错误、异常信息,每条数据操作数据库前的日志都有且正常。
| 排查代码逻辑
代码逻辑很复杂,做的事情也很多,重点排查和问题可能相关的逻辑。
问题现象是丢了一部分数据,怀疑可能是数据被拆分在多个事务中处理的,某个事务没提交,导致数据丢失。
代码使用的是 Spring 事务,整个逻辑有 4 层事务嵌套,配置都一样,如下:
propagation = Propagation.REQUIRED, rollbackFor = Exception.classfor 循环里也有子事务,猜测是不是 for 循环里使用太多,导致事务的传播属性被破坏了?
由于没找到直接获取到 Spring 事务信息的方法,只能通过下面这个方法 debug 抽查一部分数据处理时的事务信息。
TransactionAspectSupport.currentTransactionStatus()抽查结果看,每条数据所有的处理过程中都是同一个事务,并没有新事务开启,所以这个猜测可以被排除。
| 网络抖动超时?
由于有很多 RPC 调用,会不会网络抖动超时,整个处理时间太长了,导致事务失效?
根据日志计算了一下耗时,和没丢数据的导入操作对比,耗时也差不多,都是 2 分钟左右,这个猜测也可以排除。
|| 数据库侧排查
既然代码逻辑看不出任何问题,那问题会不会出在数据库上?虽然大家都知道概率很低。
找 DBA 同学看了阿里云的请求日志,丢失数据的相关 SQL 请求竟然都有。又要了 binlog 日志查看,发现日志和真实落库的数据完全一样,丢失的数据在 binlog 中一条也没找到。
看到这个结果,心里竟然有些激动,难道自己中奖了?数据库的问题被我撞上了?
请求日志有,binlog 里没有,这明显是数据库出问题了吗。
| 难道是事务刷盘策略导致丢了 1 秒的数据?
赶紧看了一下数据库的配置
>show variables like 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 2 |
+--------------------------------+-------+这个值默认是 1,强一致,完全符合 ACID。互联网场景一般追求性能和一致性的平衡,一般都配成 2,折中的策略。
=2,每次事务提交,都会把 logBuffer 中的数据写入到操作系统的缓存,默认每秒再通知操作系统把缓存中的数据刷到日志文件中(这个频率是由这个参数控制的 innodb_flush_log_at_timeout,默认 1 秒)。
> show variables like 'innodb_flush_log_at_timeout';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_flush_log_at_timeout | 1 |
+-----------------------------+-------+这时从官网又看到这句话
InnoDBcrash recovery works regardless of theinnodb_flush_log_at_trx_commitsetting. Transactions are either applied entirely or erased entirely.
意思是 InnoDB 故障恢复和事务刷盘策略配置无关,事务要么被完全应用,要么被完全删除。
两层含义:
1)不会出现事务提交一半的情况
2)就算 InnoDB 故障,也是一个事务内的数据全丢,这里也印证了为什么 redo log 保证的是逻辑层面的故障恢复
所以按照官网的说法,如果是所有数据在一个事务内提交,从 redo log 层面,肯定不会出现丢一部分的情况。
| 难道 redo log 到 binlog 的过程数据丢了?
熟悉 InnoDB 的同学应该都清楚,binlog 保证的是物理层面的故障恢复,也就是操作系统的页维度。
既然丢的数据在 binlog 中没有,redo log 又能够保证一个事务内的数据要么完全生效要么完全丢弃,那是不是从 redo log 到 binlog 这个过程中数据丢了?
想到这里,猜测可能有两种情况导致数据丢失
1)redo log 日志文件太小,一个事务内操作的数据量太多,导致事务还没提交文件就满了,数据丢了?
赶紧又看了文件大小的设置:
>show variables like 'innodb_log_file_size';
+----------------------+------------+
| Variable_name | Value |
+----------------------+------------+
| innodb_log_file_size | 1048576000 |
+----------------------+------------+1 G 的大小,足够用了,两千多条数据才几十K,这个猜想又被排除了。
这个值默认是 50 M,而且是 2 个 redo log 文件交替使用,一般的场景足够应付了。

2)文件够用,难道是写 binlog 是从操作系统内存中丢了?
此时在 MySQL 官网又看到了这段话
Caution
Many operating systems and some disk hardware fool the flush-to-disk operation. They may tell mysqld that the flush has taken place, even though it has not. In this case, the durability of transactions is not guaranteed even with the recommended settings, and in the worst case, a power outage can corrupt
InnoDBdata. Using a battery-backed disk cache in the SCSI disk controller or in the disk itself speeds up file flushes, and makes the operation safer. You can also try to disable the caching of disk writes in hardware caches.
简单来说,就是操作系统或者磁盘硬件,都可能欺骗 MySQL,告诉 MySQL 刷盘成功了,其实没成功,这种概率就极低了,有什么办法能验证一下?
于是想到了对比一下当时的 redo log 和 binlog 看看是否一致,又找到 DBA 去要 redo log 日志。
得到的答复却是没有权限,就算拿到了也无法解析查看,自己从网上也没搜到查看 redo log 的方法, 尝试了本机的 ib_logfile ,各种工具都无法查看。
况且前面也说了,redo log 是 2 个文件切换滚动记录的,当时的数据早就被覆盖了。
所以这个猜想就无法证实了。
| 求助阿里云的同学
本来都想放弃了,DBA 把问题抛给了阿里云的同学后,终于看到希望了。
阿里云给的回复是当时发生了“死锁”(后面会解释为什么加引号),导致一个事务的数据回滚了。
接下来就研究拿到的“死锁”日志
*** (1) TRANSACTION:
TRANSACTION 1131203497, ACTIVE 131.044 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 534 lock struct(s), heap size 63016, 2995 row lock(s), undo log entries 4789
LOCK BLOCKING MySQL thread id: 1743223 block 1744716
MySQL thread id 1744716, OS thread handle 0x2b5aa89cd700, query id 43504086472 *** updating
...
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 403 page no 53572 n bits 104 index `PRIMARY` of table `dbjz_zt_***`.`tb_***` trx id 1131203497 lock_mode X locks rec but not gap waiting
Record lock, heap no 32 PHYSICAL RECORD: n_fields 66; compact format; info bits 0
...
*** (2) TRANSACTION:
TRANSACTION 1131213488, ACTIVE 56.242 sec starting index read
mysql tables in use 1, locked 1
521 lock struct(s), heap size 63016, 1596 row lock(s), undo log entries 3189
MySQL thread id 1743223, OS thread handle 0x2b5a47c41700, query id 43504152822 *** updating
...
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 403 page no 53572 n bits 104 index `PRIMARY` of table `dbjz_zt_***`.`tb_***` trx id 1131213488 lock_mode X locks rec but not gap
Record lock, heap no 4 PHYSICAL RECORD: n_fields 66; compact format; info bits 0
*** WE ROLL BACK TRANSACTION (2)
------------日志很清晰的看到 事务(2) 被回滚了(这里的回滚是 MySQL 内部的处理机制,不是业务触发的回滚),条数正好是 1596。
| 继续寻找事情真相
导一份文件,一个线程,一个事务,怎么就发生死锁了???
就算发生死锁,回滚事务,也应该有异常返回各客户端吧,怎么没接收到呢???
事务回滚了,剩下的数据怎么又落库成功了???
不管有多少疑问,到这里,事情已经很清晰了,肯定是代码的问题了,还是乖乖地找 bug 吧。
再次仔细研究问题期间的日志 和 每一行代码。
通过日志发现,操作人先后导入了 2 个文件,间隔几十秒,2 个文件内有相同的一批数据,即都要更新 t2 中的同一批记录,而每个文件处理耗时 2 分钟左右,所以就发生了“死锁”。
问题的诱因找到了,继续找为什么没收到异常信息?
因为现在知道了是 t2 表发生了“死锁”,所以重点看了更新这张表前后的代码,发现代码确实有问题,异常被吞了。
之前遇到过一次吞 SQL 异常的场景,可以看这篇文章《谁吞了我的异常》,但那一次是包装后重抛出来了,这次是完完全全吞了。
代码逻辑如下:
public Result<T> execute(RetryCode retryCode) {
Result result = null;
for (int retryCount = 1; retryCount <= MAX_RETRY_COUNT; retryCount++) {
try {
result = retryCode.execute(); // 这里是实现接口方法的真实业务逻辑
if (result != null && result.isSuccess()) {
return result;
}
}catch (RetryException ex){ // 1、这里捕获自定义的重试异常
if (retryCount == MAX_RETRY_COUNT) {
logger.error("execute:result is fail!retryCount={}.RetryException:{}", retryCount,ex);
//次数到达最大次时,抛异常
throw ex;
}
}catch (Exception ex){ // 2、这里捕获其他所有异常
if (retryCount == MAX_RETRY_COUNT) {
trace[0] = ex.getStackTrace()[0];
logger.error("达到最大重试次数:className:{},fileName:{},methodName:{},lineNumber:{},cause:{}.",trace[0].getClassName(),trace[0].getFileName(),trace[0].getMethodName(),trace[0].getLineNumber(),ex);
}
throw ex; // 问题就出在这一行代码, 如果不等于最大重试次数,下次重试没有异常了,第一次的异常就被吞了
}
}
try {
Thread.sleep(MAX_SLEEP_MS);
} catch (Exception e) {
Thread.currentThread().interrupt();
return ResultUtil.fail( ErrorCodeEnum.SYSTEM_ERROR);
}
}
return result != null ? result : ResultUtil.fail(ErrorCodeEnum.SYSTEM_ERROR);
}最初排查时没发现这段代码有问题的原因是,这个重试的工具方法很多场景都在用,在线上跑了好多年了,就忽略了这块。如果不是这么极端的带事务的场景,还暴露不出来这块的问题。
找到这个原因后,复现问题,拿到异常信息如下:
### Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction
; SQL []; Lock wait timeout exceeded; try restarting transaction; nested exception is com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction.异常信息很明确的告诉我们,锁等待超时,事务重启了。所以前面一直说的“死锁”是不准确的,真实情况是发生了“锁等待”超时。
事务重启就意味着这个事务里已经提交的所有操作会被清空,也就是“死锁”日志里看到的 “*** WE ROLL BACK TRANSACTION (2)”。
|| 事情真相
现在问题现场可以清晰的还原出来了,画一张图说明一下。
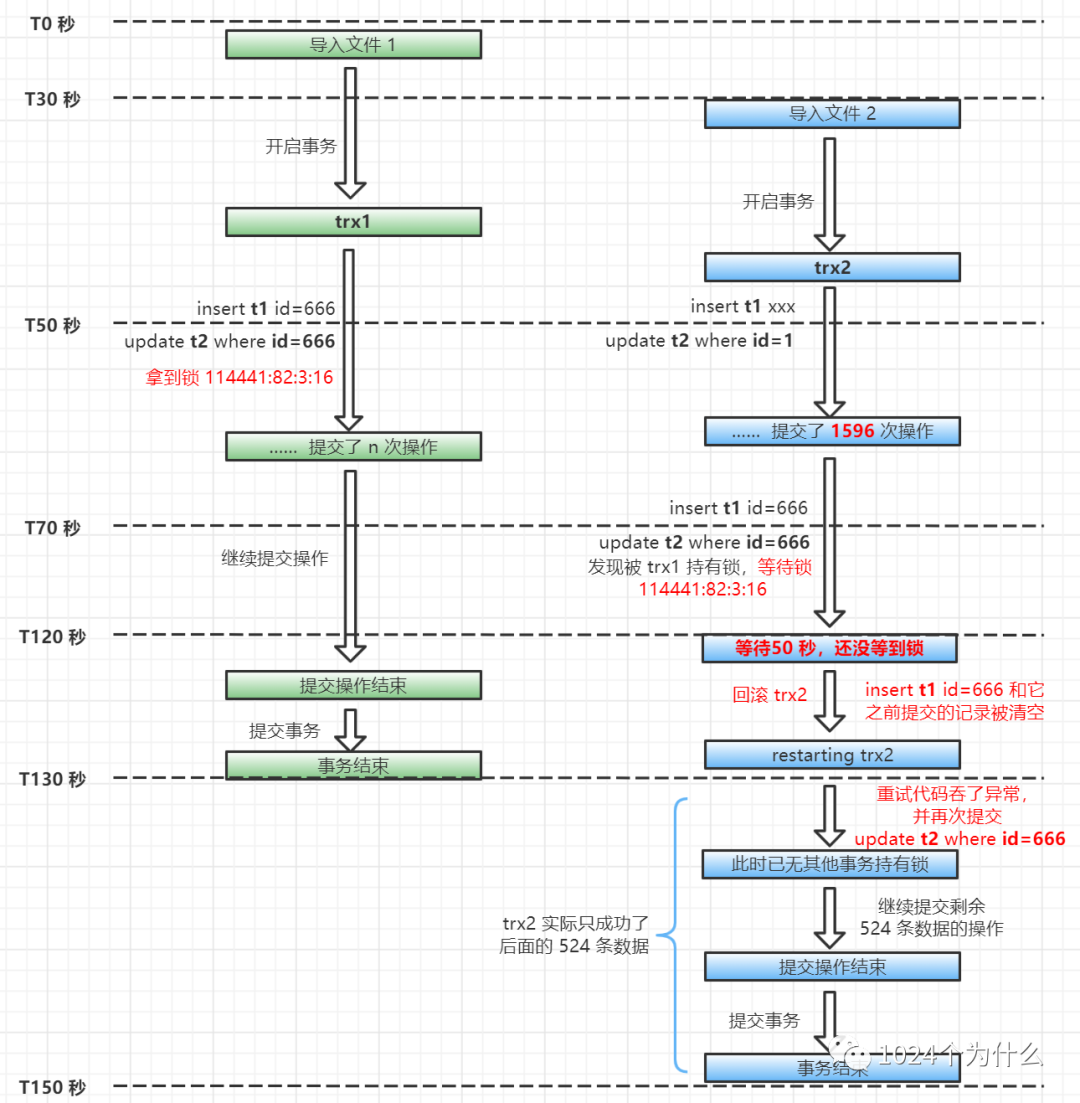
到此为止,前面的疑问就都有答案了。0.5 条也是因为代码重试的逻辑造成的。
为什么是等待 50 秒?为什么锁等待超时事务会回滚?
官方文档对系统参数 [innodb_lock_wait_timeout] 的介绍中就能找到答案。
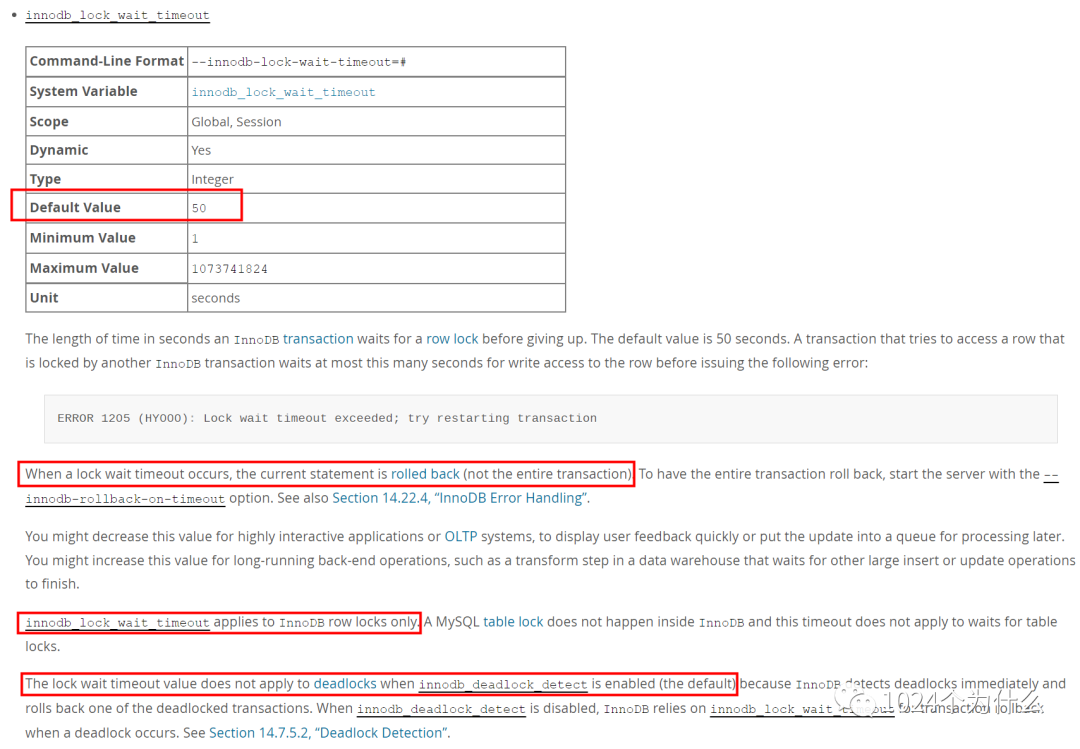
我想这应该是 MySQL 的作者综合考虑给出的解决方案吧。
既然发生了锁等待,肯定不能一直死等下去,那么等多长时间呢,50 秒应该是个经验值,一个事务 50 秒还没提交,多半是问题的。获取锁也得有个先来后到,50 秒等不到,那就回滚事务,给客户端报错,由使用方自行处理。
这里还提到了重要的几点:
1)锁等待只会发生在行锁的情况下
2)如果出现死锁,在 5.7.15 版本后,新增了死锁探测的功能,如果此功能开启(默认开启),探测到死锁后,此事务立即回滚,50 秒也不用等了;如果未开启,则还是会等待 50 秒后回滚事务。5.7.15 前没有这个功能,发生死锁立即事务回滚。
|| 解决方案
鉴于我的业务场景简单,就直接从入口做了限制,后台处理完一个文件,才允许导入下一个文件。
如果从入口不能限制,当然还有其他解决思路,就是缩小事务。
缩小事务可以从两个维度,一个是数据量,一个是时间。
可以把一个文件的数据拆分成几个小事务分批处理。
或者把校验的逻辑抽到事务外面、同步 RPC 调用改成异步,通过其他方式保证数据的最终一致性。
扯两句
不要用大事务,事务内的逻辑要精简
异常是否抛出一定要谨慎处理
不要随便质疑 MySQL,多看看自己的代码
原创不易,多多关注,一键三连,感谢支持!
参考文献:
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_lock_wait_timeout
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_deadlock_detect
https://developer.aliyun.com/article/743882















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









