







这是继上次分享泰坦尼克之后,继续细化我们平时在工作学习中用到的一些pandas进行数据分析的常用函数,数据也之间使用之前的训练数据。这次我将训练数据先导入到本地的mysql数据库中,利用pandas来读取mysql中的训练数据。
1、首先打开anaconda导入数据
# 目标:主要学习一下pandas常用的一些函数
import pandas as pd
import matplotlib.pyplot as plt
import mysql.connector
# 连接到MySQL数据库
cnx = mysql.connector.connect(user='root', password='123456',
host='localhost', database='test')
# 使用pandas的read_sql函数读取整个表的数据
query = "SELECT * FROM train"
df = pd.read_sql(query, con=cnx)
# 关闭数据库连接
cnx.close()
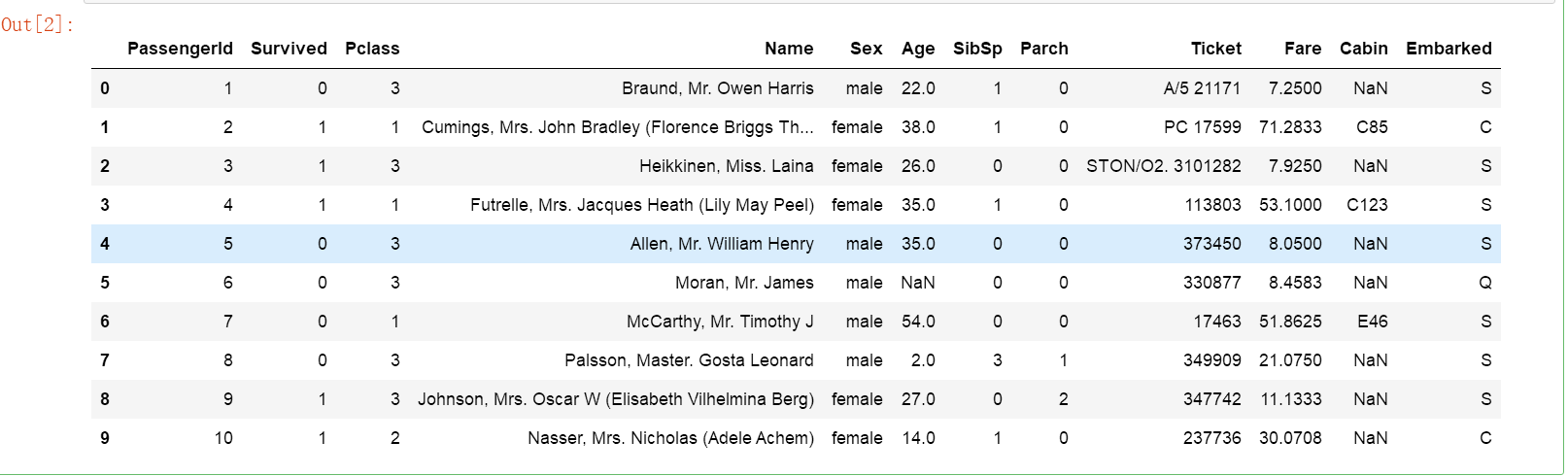
df.head(10)
# 这个数据想必都比较熟悉,下面为了方便使用还是加一个说明
# PassengerI:乘客编号
# Survive:生存状态(0代表未存活,1代表存活)
# Pclas:舱位等级
# Nam:乘客姓名
# Se:性别
# Ag:年龄
# SibS:同舱兄弟姐妹或配偶的数量
# Parc:同行父母或子女的数量
# Ticke:票号
# Far:票价
# Cabi:舱位
# Embarke:登船港口
运行结果如下:
2、还是先复习一下前面的基本语法,这些都不难就是容易忘记,所以在学习的过程中也多复习多练。因为这些虽然简单,但是以后会经常的用到,也顺便熟悉一下数据。
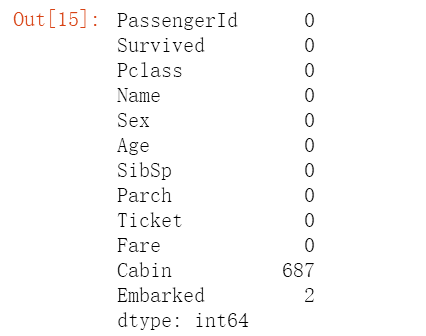
df.info()
df.isnull().sum()
df.describe()
3、下面进入到常用函数模块。
# 1、pandas常见的统计分析
# 需求:计算一下女性的存活率
# 选取性别为female的所有行,再筛选其中的一列“Survived”
woman = df.loc[df.Sex == 'female']['Survived']
woman_rate = sum(woman)/len(woman)
print(woman_rate)
结果如下:

# 2、计算一下不同仓位的平均价格
avg_fare = df.groupby("Pclass")["Fare"].mean()
print("各级别仓位的平均票价:",avg_fare)
结果如下:

# 3、缺失值填充
# 用平均年龄来填充缺失值
df["Age"] = df['Age'].fillna(df['Age'].mean())
df.isnull().sum()
结果如下:
# 4、merge()
# 合并多个DataFrame
# merged_df = pd.merge(df1,df2,on = 'id')
# 左连接
# merged_df = pd.merge(ddf1,df2,on = 'id',jow = 'left')
说明:没有合适的数据就展示一下语法,基本和sql语法类似,但是更方便
# 5、统计列中唯一值的频次
name_count = df['Name'].value_counts()
sex_count = df['Sex'].value_counts()
print(sex_count)
print(name_count)
结果如下:

# 6、删除所有包含缺失值的行
# df_clean = df.dropna()
# 7、将日期字符串转为datetime类型
# df['date'] = pd.to_datetime(df['date'])
# 8、按薪资降序排列
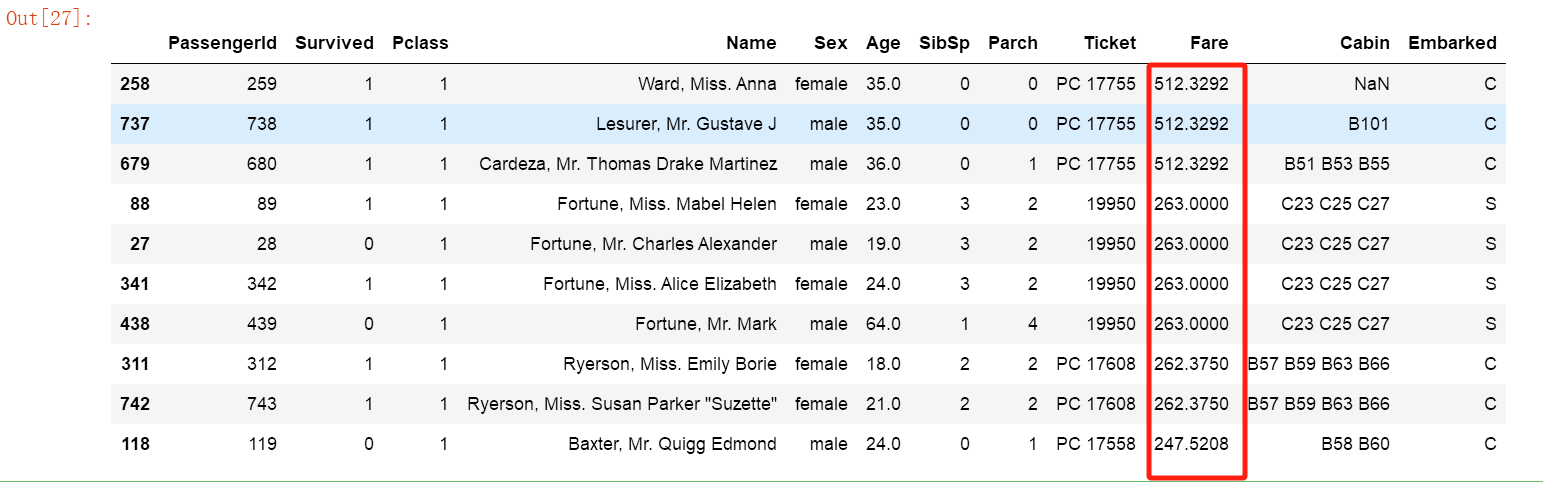
df_sorted = df.sort_values('Fare', ascending=False)
df_sorted.head(10)
结果如下:
# 9、找出70到100岁之间的乘客
fit_name = df.query('Age>70 and Age < 100')
fit_name
结果如下:

以上就是通过第一篇比较完整的泰坦尼克项目之后,我们再一次将一些用到的知识点拆分贯穿到我们日常的学习中,加强锻炼。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









